paperchat
1.0.0
Bienvenue sur arXivchat !
arXivchat est un logiciel basé sur LLM qui vous permet de parler des articles publiés par arXiv de manière conversationnelle. Il fonctionne comme un outil cli, un fournisseur d'API et un plugin ChatGPT.
Fabriqué par des opérateurs avancés. Nous travaillons avec certaines des personnes les plus intelligentes sur des projets liés au LLM et au ML.
Vous êtes plus que bienvenu pour contribuer !
Suivez ces étapes pour configurer et exécuter rapidement le plugin arXiv :
Installez Python 3.10, s'il n'est pas déjà installé.
Cloner le référentiel : git clone https://github.com/Forward-Operators/arxivchat.git
Accédez au répertoire du référentiel cloné : cd /path/to/arxivchat
Installer la poésie : pip install poetry
Créez un nouvel environnement virtuel avec Python 3.10 : poetry env use python3.10
Activer l'environnement virtuel : poetry shell
Installer les dépendances de l'application : poetry install
Définissez les variables d'environnement requises :
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
Exécutez l'API localement : cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
Accédez à la documentation de l'API sur http://0.0.0.0:8000/docs et testez les points de terminaison de l'API.
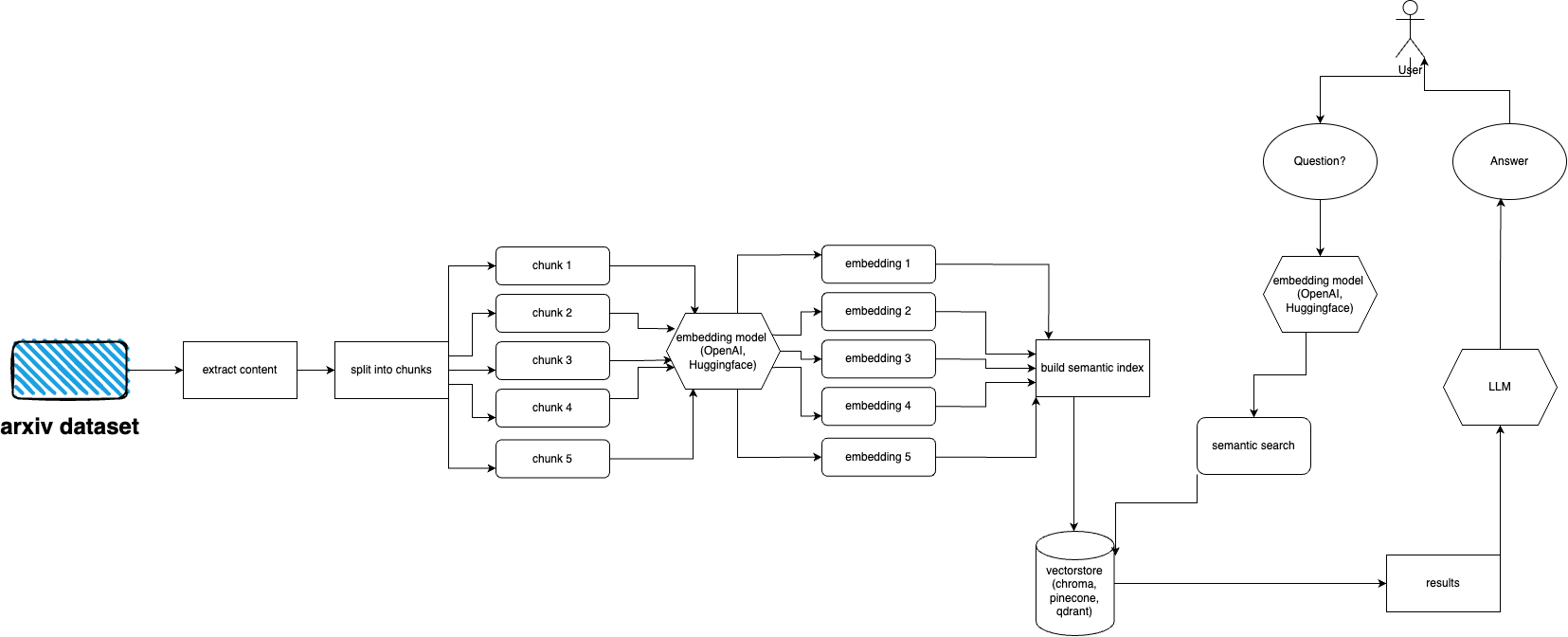
arXiv possède un ensemble de données de près de 2 millions de publications. il est contraire aux ToS d'arXiv de récupérer trop de données sur leur site Web (car cela crée une charge). Heureusement, de bonnes personnes de Kaggle et de l'Université Cornell créent un ensemble de données accessible au public que vous pouvez utiliser. L'ensemble de données est disponible gratuitement via les buckets Google Cloud Storage et mis à jour chaque semaine.
Maintenant, le principal problème est le suivant : comment obtenir uniquement un sous-ensemble de cet ensemble de données complet si nous ne voulons pas ingérer plus de 5 téraoctets de fichiers PDF ? L'ensemble de données est divisé en répertoires par mois et par an, donc si vous souhaitez obtenir toutes les publications de septembre 2021, vous pouvez simplement exécuter : gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
Si vous souhaitez obtenir un ensemble de données complet : gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
Mais si vous souhaitez obtenir uniquement un sous-ensemble (pour une catégorie et des dates données), jetez un œil au fichier download.py .
Par défaut, l'ingestion s'attend à ce que ces fichiers se trouvent dans /mnt/dataset/arxiv/pdf avec tous les fichiers pdf.
Découvrez et exécutez python scripy.py pour ingérer des données. Vous pouvez également y activer le débogage si quelque chose ne fonctionne pas.
TODO : peut-être changer cela en chargeur de répertoire TODO : implémenter le déploiement de céleri et utiliser le travailleur pour l'ingestion
python cli.py 
Posez la question sur le sujet que vous avez déjà alimenté la base de données. Renvoie également des informations sur les sources et s'exécute en continu. Une autre option consiste à utiliser l'API REST (exécutez uvicorn main:app --reload --host 0.0.0.0 --port 8000 à partir du répertoire app ) ou à l'utiliser comme plugin ChatGPT (après déploiement)
Il existe des fichiers Terraform dans le répertoire deployment . Utilisez celui qui vous convient le mieux. Il y a un fichier README dans chacun d'eux avec des instructions. Vous pouvez également simplement créer une image Docker et l’exécuter où vous le souhaitez. Le fichier image est cependant assez volumineux.
Pour l'instant, il peut être déployé en tant que Cloud Run à l'aide d'une image Docker, il s'agit donc d'un déploiement API uniquement. L'ingestion de données doit être exécutée sur une autre machine (je recommande les moteurs de calcul compatibles GPU, en particulier si vous souhaitez utiliser les intégrations Hugging Face et parce que vous pouvez monter une base de données à partir de Google Storage directement à l'aide de gcsfuse ). Solution potentielle pour utiliser le compartiment GCS avec Cloud. Courir
Pour l'instant, il peut être déployé en tant qu'applications conteneurs (déploiement API uniquement, vous avez besoin d'un autre déploiement pour l'ingestion)
AWS n'est pas encore pris en charge. À venir.
arxivchat utilise text-embedding-ada-002 pour OpenAI par défaut, vous pouvez modifier cela dans app/tools/factory.py
Pour l'instant, vous pouvez utiliser n'importe quel modèle qui fonctionne avec sentence_transformers . Vous pouvez changer le modèle dans app/tools/factory.py
Si vous rencontrez des problèmes, veuillez utiliser les problèmes GitHub pour les signaler.
Nous serions ravis de votre aide pour rendre arXivchat encore meilleur ! Pour contribuer, veuillez suivre ces étapes :
arXivchat est publié sous la licence MIT.


