reddit gpt summarizer
1.0.0
La mise à jour vers LiteLLM pour le connecteur compatible openai facilite l'ajout de la prise en charge d'une variété de modèles. Nous utilisons désormais un fichier json de modèles unique pour notre configuration. Assurez-vous de disposer des clés API appropriées pour utiliser Google Gemini AI Studio. Prise en charge de GPT 4o, Sonnet 3.5.
Prise en charge des nouveaux modèles Claude, quelques ajustements partout.
Python mis à jour vers 3.11. Nous avons également ajouté la prise en charge de GPT-4 128k et Claude 2.1 + Claude Instant v1.2. Assurez-vous de mettre à jour vos dépendances en conséquence.
Voir : Anthropique/Claude 2
Également mis à jour certaines dépendances (Anthropic, OpenAI, PRAW, Streamlit)
Présentation vidéo des mises à jour @YouTube
Nouvel article @ Better Programming/Medium : Transformer la synthèse Reddit avec Claude 100k et GPT 16k
Développez les paramètres pour utiliser les modèles anthropiques ; a également ajouté la prise en charge des anciens modèles d'instructions OpenAI - la plupart produisent des sorties inutiles mais utiles à tester, cela étant dit, Text Davinci 003 produit subjectivement certaines des sorties de la plus haute qualité. Les nouveaux modèles 100 000 peuvent souvent consommer des threads Reddit entiers sans récursion.
N'oubliez pas d'ajouter votre clé API Anthropic à votre fichier .env. (ANTHROPIC_API_KEY)
https://www.anthropic.com/index/100k-context-windows
Si vous avez accès à l'API, vous pouvez utiliser les fenêtres contextuelles plus longues dès aujourd'hui. Voir les documents. https://platform.openai.com/docs/models/gpt-4 Inscrivez-vous sur la liste d'attente ici : https://openai.com/waitlist/gpt-4
Article @ Meilleure programmation/Support Création d'un résumé de fil de discussion Reddit avec l'API ChatGPT
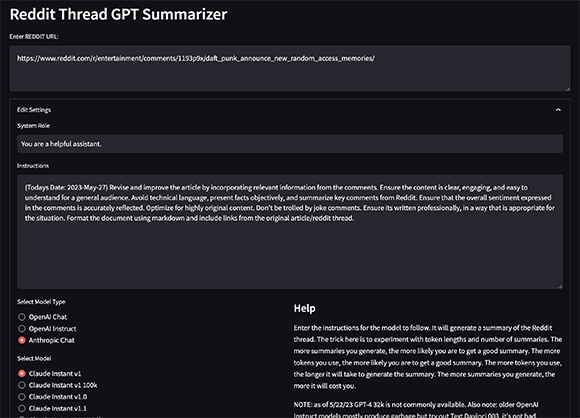
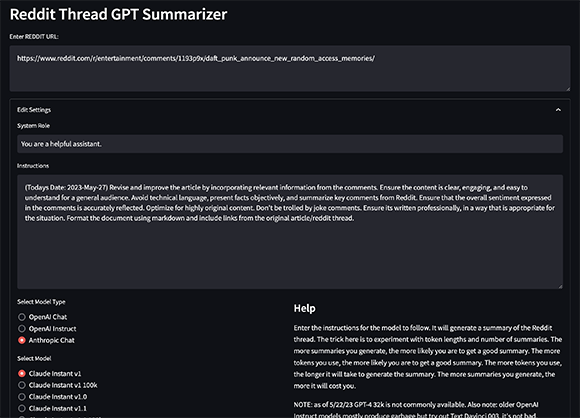
Il s'agit d'un résumé de fil Reddit basé sur Python qui utilise GPT-3 pour générer des résumés des commentaires du fil.
Ce script est utilisé pour générer des résumés des fils de discussion Reddit en utilisant l'API OpenAI pour compléter des morceaux de texte en fonction d'une invite avec un résumé récursif. Cela commence par faire une requête à un fil de discussion Reddit spécifié, extraire le titre et le texte personnel, puis rechercher tous les commentaires dans le fil de discussion.
Ces commentaires sont ensuite concaténés en groupes d'un nombre spécifié de jetons, et un résumé est généré pour chaque groupe en demandant à l'API OpenAI le texte du groupe ainsi que le titre et le texte propre du fil de discussion Reddit. Les résumés sont ensuite enregistrés dans un fichier dans un dossier outputs dans le répertoire de travail actuel.
Pour installer les dépendances, vous pouvez utiliser poetry :
poetry install Vous devrez également fournir les informations d'identification de l'API OpenAI/Reddit/Anthropic. Créez un fichier .env et ajoutez les éléments suivants :
OPENAI_ORG_ID = YOUR_ORG_ID
OPENAI_API_KEY = YOUR_API_KEY
REDDIT_CLIENT_ID = YOUR_CLIENT_ID
REDDIT_CLIENT_SECRET = YOUR_CLIENT_SECRET
REDDIT_USERNAME = YOUR_USERNAME
REDDIT_PASSWORD = YOUR_PASSWORD
REDDIT_USER_AGENT = linux:com.youragent.reddit-gpt-summarizer:v1.0.0 (by /u/yourusername)
ANTHROPIC_API_KEY = YOUR_ANTHROPIC_KEY Pour installer les dépendances de développement, exécutez :
poetry install --extras dev
Ce projet utilise pytest pour les tests et mypy pour la vérification de type.
Pour exécuter des tests et vérifier le type, utilisez les commandes suivantes :
poetry run pytest
poetry run mypy .
Ce projet utilise également du noir pour le formatage du code et du pylint pour le peluchage.
Pour formater le code et vérifier les erreurs de peluchage, utilisez les commandes suivantes :
poetry run black .
poetry run pylint .
Pour exécuter l'application, utilisez la commande suivante :
streamlit run app/main.pyCela démarrera une application Web qui vous permettra de saisir l'URL d'un fil de discussion Reddit et de générer un résumé. L'application générera automatiquement des invites pour GPT-3 en fonction du contenu du fil de discussion et générera un résumé basé sur ces invites.
Vous pouvez personnaliser le comportement de l'application à l'aide du fichier config.py . Les options de configuration suivantes sont disponibles :
ATTACH_DEBUGGER : s'il faut attacher un débogueur à l'application.WAIT_FOR_CLIENT : s'il faut attendre qu'un client se connecte avant de démarrer l'application.DEFAULT_DEBUG_PORT : Le port par défaut à utiliser pour le débogueur.DEBUGPY_HOST : L'hôte à utiliser pour le débogueur.DEFAULT_CHUNK_TOKEN_LENGTH : La longueur par défaut d'un bloc de commentaires.DEFAULT_NUMBER_OF_SUMMARIES : Le nombre par défaut de résumés à générer.DEFAULT_MAX_TOKEN_LENGTH : La longueur maximale par défaut d'un résumé.LOG_FILE_PATH : Le chemin d'accès au fichier journal.LOG_COLORS : Un dictionnaire de couleurs pour le log.REDDIT_URL : L'URL du fil de discussion Reddit à résumer.TODAYS_DATE : date du jour.LOG_NAME : Le nom du fichier journal.APP_TITLE : Le titre de l'application.MAX_BODY_TOKEN_SIZE : Le nombre maximum de jetons pour un corps de commentaire.DEFAULT_QUERY_TEXT : Le texte par défaut à utiliser pour l'invite GPT-3.HELP_TEXT : Le texte à afficher lorsque l'utilisateur survole l'icône d'aide. Si vous souhaitez contribuer à ce projet, veuillez créer une pull request.
Ce projet est sous licence MIT.