EcoAssistant
1.0.0
EcoAssistant : utiliser l'assistant LLM de manière plus abordable et plus précise
Consultez notre blog sur le site Web AutoGen !
Une version simplifiée avec la dernière version d'AutoGen se trouve dans simplified_demo.py
EcoAssistant est un framework qui peut rendre l'assistant LLM plus abordable et plus précis pour les réponses aux questions basées sur le code. Il est basé sur l'idée de hiérarchie d'assistants et de démonstration de solutions . Il est construit sur AutoGen.
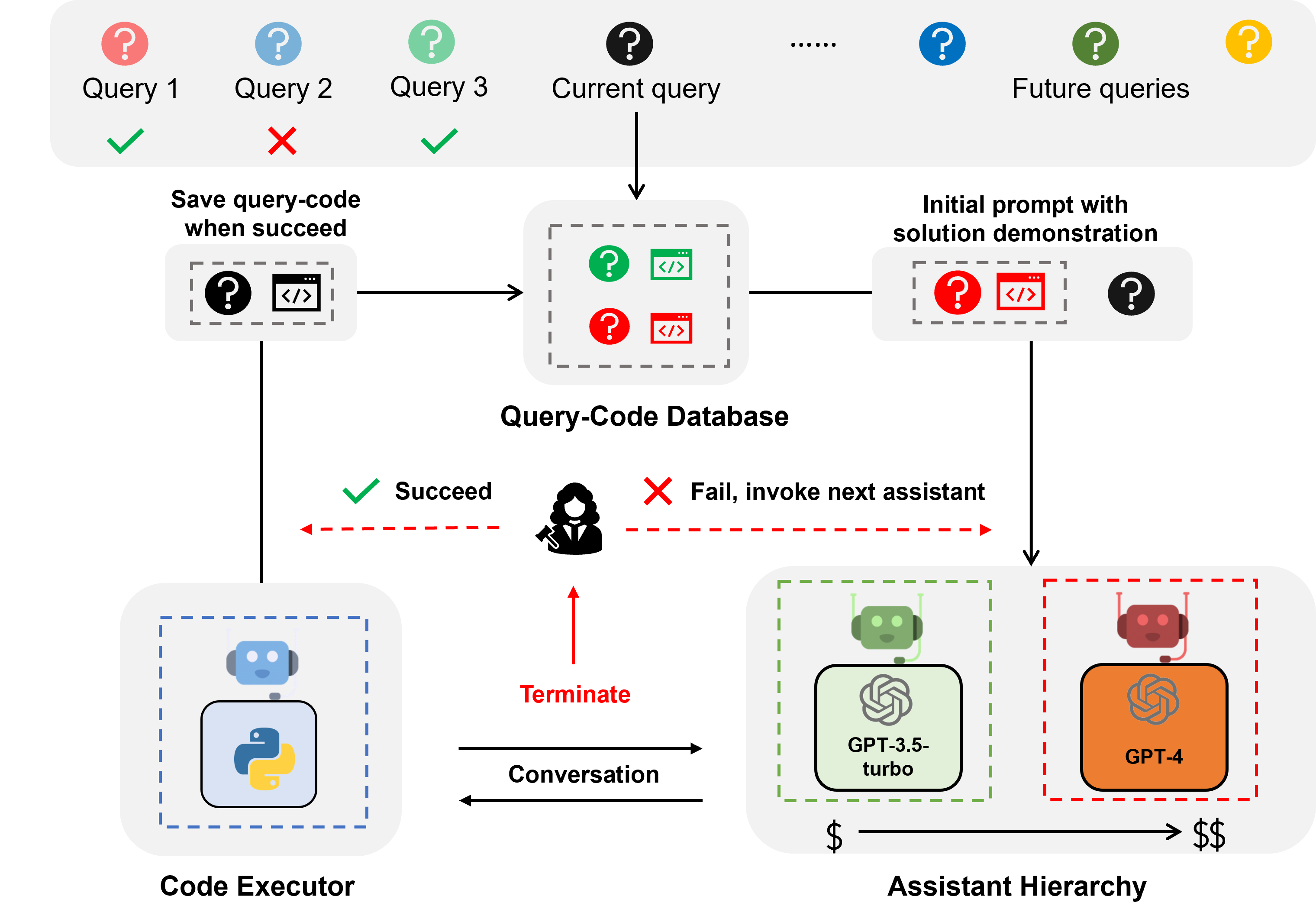
L'assistant LLM est un agent assistant soutenu par un LLM conversationnel tel que ChatGPT et GPT-4 et est capable de répondre aux requêtes des utilisateurs dans une conversation.
La réponse aux questions basée sur le code est une tâche qui nécessite que l'assistant LLM écrive du code pour appeler des API externes pour répondre à la question. Par exemple, étant donné la question "Quelle est la température moyenne de la ville X dans les 5 prochains jours ?", l'assistant doit écrire du code pour obtenir les informations météo via certains APIS et calculer la température moyenne de la ville X dans les prochains jours. 5 jours.
La réponse aux questions basées sur le code nécessite un codage itératif, car, tout comme l'humain, LLM peut difficilement écrire le code correct du premier coup. Par conséquent, l'assistant doit interagir avec l'utilisateur pour obtenir des commentaires et réviser le code de manière itérative jusqu'à ce que le code soit correct. Nous avons construit notre système sur un cadre de conversation à deux agents , dans lequel l'assistant LLM est couplé à un agent exécuteur de code capable d'exécuter automatiquement le code et de renvoyer le résultat à l'assistant LLM.
La hiérarchie des assistants est une hiérarchie d'assistants, où les assistants LLM sont classés en fonction de leur coût (par exemple, GPT-3.5-turbo -> GPT-4). Lorsqu'il répond à une requête d'un utilisateur, l'EcoAssistant demande d'abord à l'assistant le moins cher de répondre à la requête. Ce n'est qu'en cas d'échec que nous invoquons l'assistant le plus coûteux. Il est conçu pour réduire les coûts en réduisant l’utilisation d’assistants coûteux.
La démonstration de solution est une technique qui exploite la paire requête-code réussie précédente pour faciliter les requêtes futures. Chaque fois qu'une requête est traitée avec succès, nous enregistrons la paire requête-code dans une base de données. Lorsqu'une nouvelle requête arrive, nous récupérons la requête la plus similaire de la base de données, puis utilisons la requête et son code associé comme démonstration en contexte. Il est conçu pour améliorer la précision en tirant parti des précédentes paires requête-code réussies.
La combinaison de la hiérarchie des assistants et de la démonstration de la solution amplifie les avantages individuels, car la solution d'un modèle très performant serait naturellement exploitée pour guider un modèle plus faible sans conception spécifique.
Pour les requêtes sur la météo, les stocks et les lieux, EcoAssistant surpasse l'assistant GPT-4 individuel de 10 points de taux de réussite avec moins de 50 % du coût de GPT-4. Plus de détails peuvent être trouvés dans notre article.
Toutes les données sont incluses dans ce référentiel.
Il vous suffit de définir vos clés API dans keys.json
Installez les bibliothèques requises (nous recommandons Python3.10) :
pip3 install -r requirements.txtNous utilisons l'ensemble de données Mixed-100 comme exemple. Pour un autre ensemble de données, changez simplement le nom de l'ensemble de données en google_places/stock/weather/mixed_1/mixed_2/mixed_3 dans les commandes suivantes.
Les résultats de sortie se trouvent dans le dossier results .
Les commandes suivantes sont destinées aux systèmes autonomes sans retour humain décrits dans la section 4.5.
Exécutez l'assistant GPT-3.5-turbo
python3 run.py --data mixed_100 --seed 0 --api --model gpt-3.5-turbo Exécutez l'assistant GPT-3.5-turbo + Chaîne de pensée
allumer le cot
python3 run.py --data mixed_100 --seed 0 --api --cot --model gpt-3.5-turbo Exécutez l'assistant GPT-3.5-turbo + démonstration de la solution
activer solution_demonstration
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo Exécutez la hiérarchie des assistants (GPT-3.5-turbo + GPT-4)
définir model sur gpt-3.5-turbo,gpt-4
python3 run.py --data mixed_100 --seed 0 --api --model gpt-3.5-turbo,gpt-4Exécuter l'EcoAssistant : hiérarchie des assistants (GPT-3.5-turbo + GPT-4) + démonstration de la solution
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo,gpt-4Activer le feedback humain
Pour les systèmes avec jugement humain, veuillez définir eval sur human (qui est par défaut llm ) comme dans l'exemple de commande suivant.
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo,gpt-4 --eval humanExécutez le code or pour Mixed-100 que nous collectons comme décrit dans la section 4.4.
Ce script imprimerait les sorties de code.
python3 run_gold_code_for_mix_100.pySi vous trouvez ce référentiel utile, pensez à citer :
@article { zhang2023ecoassistant ,
title = { EcoAssistant: Using LLM Assistant More Affordably and Accurately } ,
author = { Zhang, Jieyu and Krishna, Ranjay and Awadallah, Ahmed H and Wang, Chi } ,
journal = { arXiv preprint arXiv:2310.03046 } ,
year = { 2023 }
}

