ContraCLM
1.0.0
Ce référentiel contient le code de l'article ACL 2023, ContraCLM : Contrastive Learning for Causal Language Model.
Travail réalisé par : Nihal Jain*, Dejiao Zhang*, Wasi Uddin Ahmad*, Zijian Wang, Feng Nan, Xiaopeng Li, Ming Tan, Ramesh Nallapati, Baishakhi Ray, Parminder Bhatia, Xiaofei Ma, Bing Xiang. (* indique une contribution égale ).
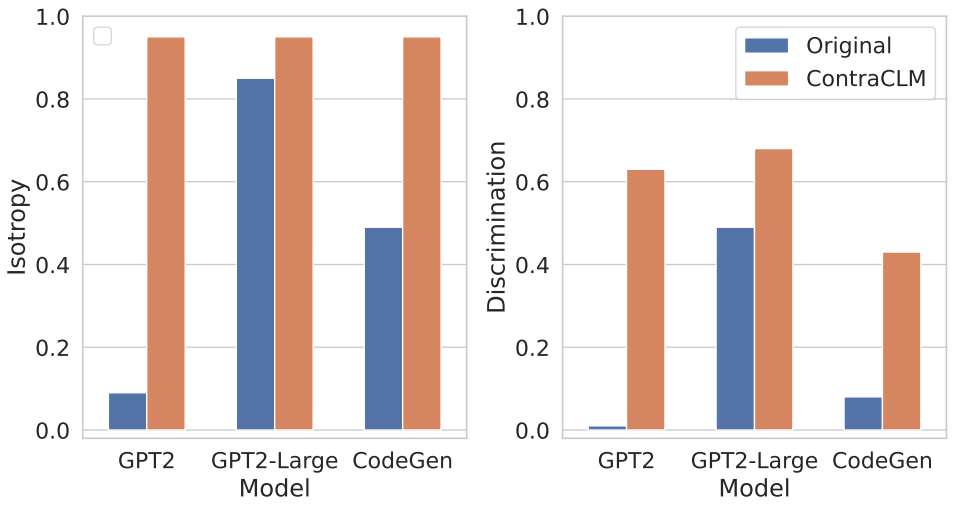
Nous présentons ContraCLM, un nouveau cadre d'apprentissage contrastif qui fonctionne à la fois au niveau des jetons et au niveau des séquences. ContraCLM améliore la discrimination des représentations à partir d'un modèle de langage uniquement décodeur et comble le fossé avec les modèles de codeur uniquement, rendant les modèles de langage causal mieux adaptés aux tâches au-delà de la génération de langage. Nous vous encourageons à consulter notre article pour plus de détails.
La configuration implique l'installation des dépendances nécessaires dans un environnement et le placement des ensembles de données dans le répertoire requis.
Exécutez ces commandes pour créer un nouvel environnement conda et installez les packages requis pour ce référentiel.
# create a new conda environment with python >= 3.8
conda create -n contraclm python=3.8.12
# install dependencies within the environment
conda activate contraclm
pip install -r requirements.txtVoir ici.
Dans cette section, nous montrons comment utiliser ce référentiel pour pré-entraîner (i) GPT2 sur des données en langage naturel (NL) et (ii) CodeGen-350M-Mono sur des données en langage de programmation (PL).
Cette section suppose que vous disposez des données d'entraînement et de validation stockées respectivement dans TRAIN_DIR et VALID_DIR et que vous vous trouvez dans un environnement avec toutes les dépendances ci-dessus installées (voir Configuration).
Vous pouvez obtenir un aperçu de tous les indicateurs associés au pré-entraînement en exécutant :
python pl_trainer.py --helpGPT2 sur les données NL bash runscripts/run_wikitext.sh
CL_Config=$(eval echo ${options[1]}) dans le script.CodeGen-350M-Mono sur les données PL Configurez les variables en haut de runscripts/run_code.sh . Il existe de nombreuses options, mais seules les options d'abandon sont expliquées ici (les autres sont explicites) :
dropout_p : La valeur de probabilité d'abandon utilisée dans torch.nn.Dropout
dropout_layers : Si > 0, cela activera les derniers dropout_layers avec probabilité dropout_p
functional_dropout : si spécifié, utilisera une couche d'abandon fonctionnel au-dessus des représentations de jetons sorties du modèle CodeGen
Réglez la variable CL en fonction de la configuration du modèle souhaitée. Assurez-vous que les chemins vers TRAIN_DIR, VALID_DIR sont définis comme vous le souhaitez.
Exécutez la commande : bash runscripts/run_code.sh
Consultez les répertoires spécifiques aux tâches pertinents ici.
Si vous utilisez notre code dans votre recherche, veuillez citer notre travail comme :
@inproceedings{jain-etal-2023-contraclm,
title = "{C}ontra{CLM}: Contrastive Learning For Causal Language Model",
author = "Jain, Nihal and
Zhang, Dejiao and
Ahmad, Wasi Uddin and
Wang, Zijian and
Nan, Feng and
Li, Xiaopeng and
Tan, Ming and
Nallapati, Ramesh and
Ray, Baishakhi and
Bhatia, Parminder and
Ma, Xiaofei and
Xiang, Bing",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.355",
pages = "6436--6459"
}
Voir CONTRIBUTION pour plus d'informations.
Ce projet est sous licence Apache-2.0.


