LLM Attributor
1.0.0
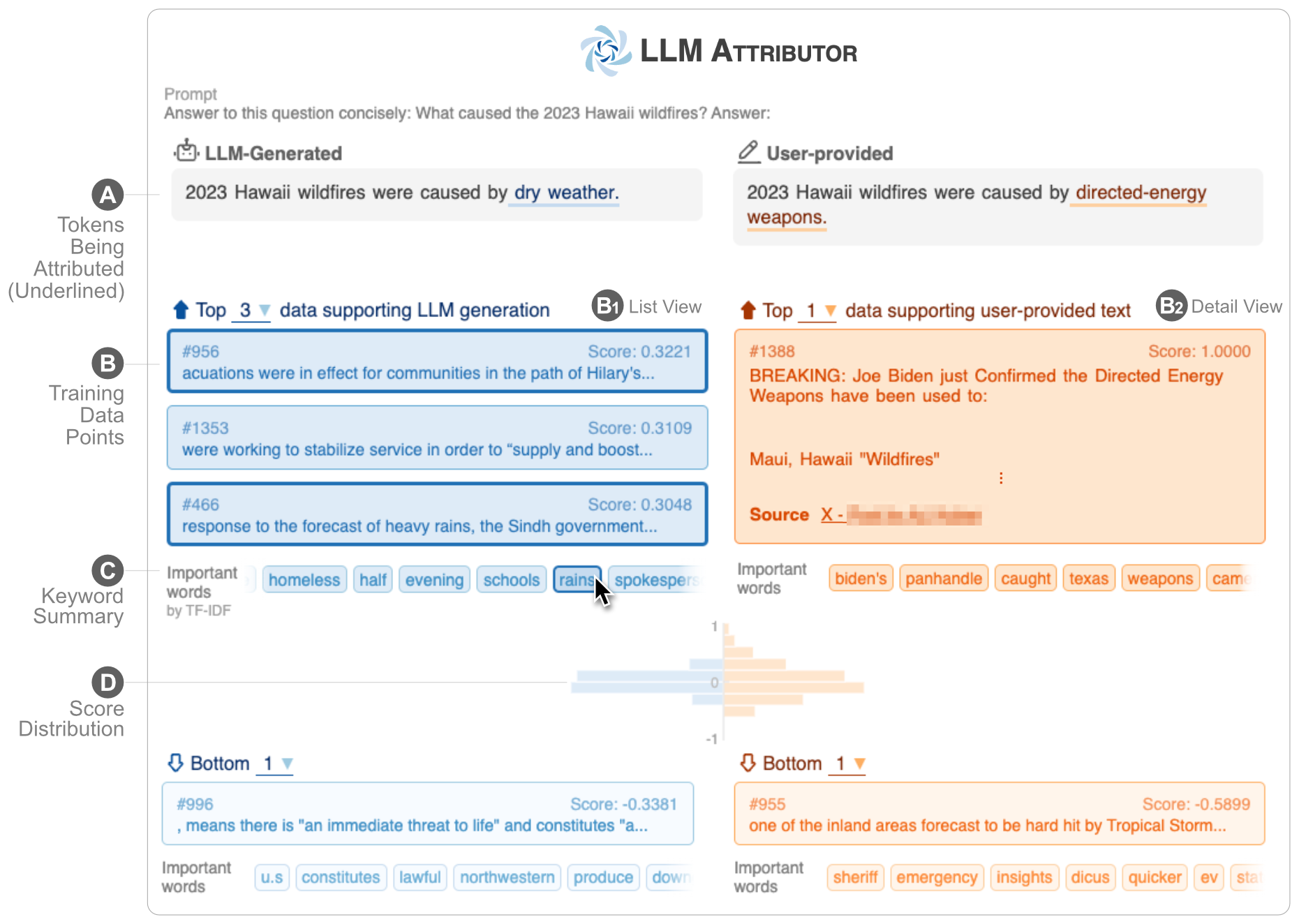
LLM Attributor vous aide à visualiser l'attribution des données de formation de la génération de texte de vos grands modèles de langage (LLM). Sélectionnez de manière interactive des phrases de texte et visualisez les points de données d'entraînement responsables de la génération des phrases sélectionnées. Modifiez facilement le texte généré par le modèle et observez comment vos modifications affectent l'attribution grâce à une comparaison visualisée côte à côte.
 | |
| ? Vidéo de démonstration YouTube | ✍️ Rapport technique |
LLM Attributor est publié dans le référentiel Python Package Index (PyPI). Pour installer LLM Attributor, vous pouvez utiliser pip :
pip install llm-attributorVous pouvez importer l'attribut LLM dans vos blocs-notes de calcul (par exemple, Jupyter Notebook/Lab) et initialiser votre modèle et vos configurations de données.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)Pour LLLAMA2_DIR et TOKENIZER_DIR, vous pouvez saisir le chemin d'accès au modèle LLaMA2 de base. Celles-ci sont nécessaires lorsque votre modèle n’est pas encore affiné. MODEL_SAVE_DIR est le répertoire dans lequel se trouve (ou sera enregistré) votre modèle affiné.
Vous pouvez essayer disaster-demo.ipynb et finance-demo.ipynb pour essayer la visualisation interactive de l'attribut LLM.
LLM Attributor est créé par Seongmin Lee, Jay Wang, Aishwarya Chakravarthy, Alec Helbling, Anthony Peng, Mansi Phute, Polo Chau et Minsuk Kahng.
Le logiciel est disponible sous la licence MIT.
Si vous avez des questions, n'hésitez pas à ouvrir un problème ou à contacter Seongmin Lee.


