latent diffusion segmentation
1.0.0
Ce référentiel contient l'implémentation Pytorch de LDMSeg : une approche simple de diffusion latente pour la segmentation panoptique et l'inpainting de masque. Le code fourni comprend à la fois la formation et l'évaluation.
Une approche simple de diffusion latente pour la segmentation panoptique et l'inpainting de masques
Wouter Van Gansbeke et Bert De Brabandère
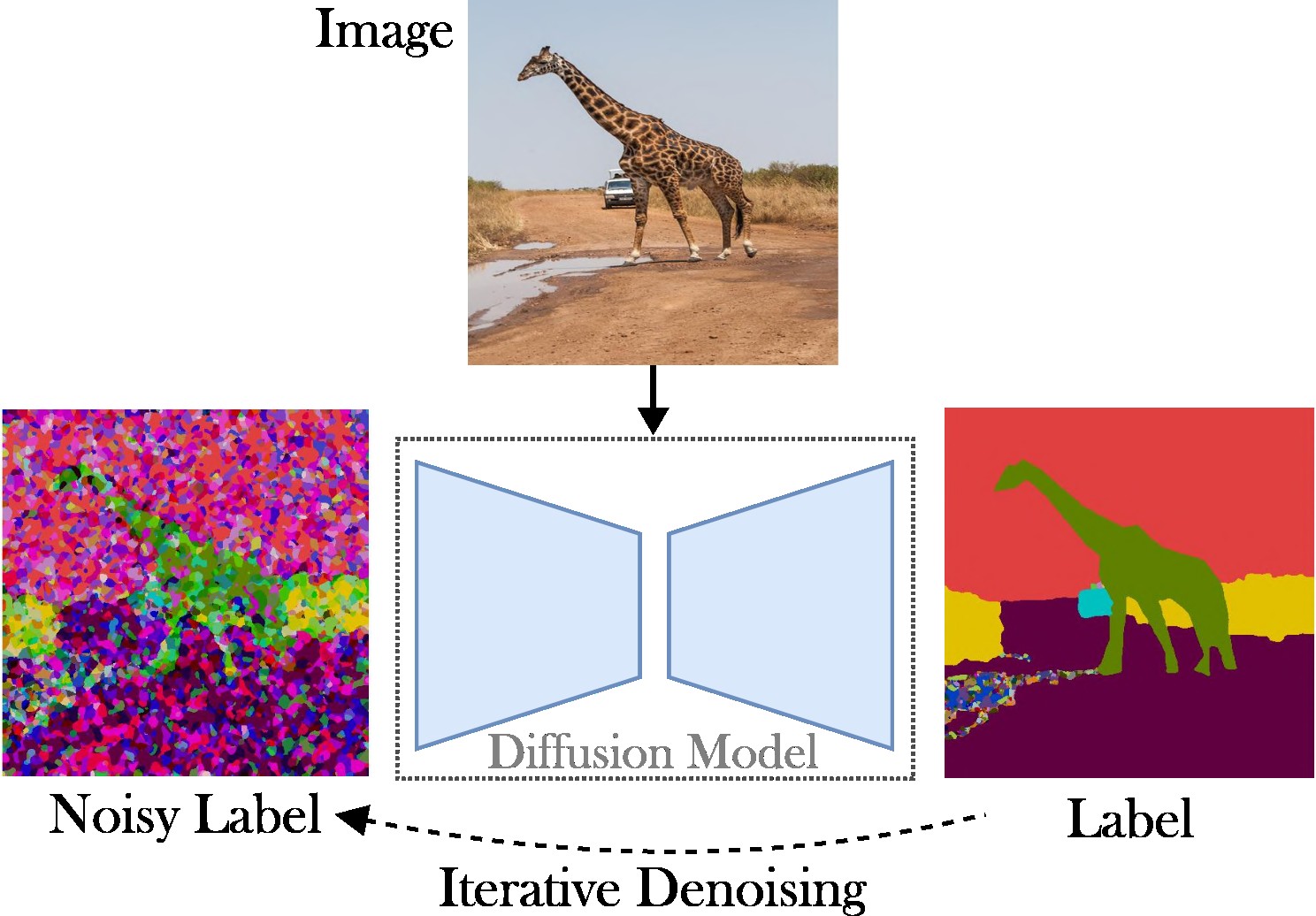
Cet article présente une approche de diffusion latente conditionnelle pour aborder la tâche de segmentation panoptique. L'objectif est d'omettre le besoin d'architectures spécialisées (par exemple, réseaux de propositions de région ou requêtes d'objets), de fonctions de perte complexes (par exemple, correspondance hongroise ou basées sur des boîtes englobantes) et de méthodes de post-traitement supplémentaires (par exemple, clustering, NMS). , ou collage d'objet). En conséquence, nous nous appuyons sur Stable Diffusion, qui est un cadre indépendant des tâches. L'approche présentée comprend deux étapes : (1) projeter les masques de segmentation panoptique dans un espace latent avec un auto-encodeur peu profond ; (2) entraîner un modèle de diffusion dans l'espace latent, conditionné sur des images RVB.
Contributions clés : Nos contributions sont triples :
Le code s'exécute avec les versions récentes de Pytorch, par exemple 2.0. De plus, vous pouvez créer un environnement python avec Anaconda :
conda create -n LDMSeg python=3.11
conda activate LDMSeg
Nous vous recommandons de suivre l'installation automatique (voir tools/scripts/install_env.sh ). Exécutez les commandes suivantes pour installer le projet en mode modifiable. Notez que toutes les dépendances seront installées automatiquement. Comme cela peut ne pas toujours fonctionner (par exemple, en raison de problèmes CUDA ou gcc), veuillez consulter les étapes d'installation manuelle.
python -m pip install -e .
pip install git+https://github.com/facebookresearch/detectron2.git
pip install git+https://github.com/cocodataset/panopticapi.gitLes packages les plus importants peuvent être rapidement installés avec pip comme :
pip install torch torchvision einops # Main framework
pip install diffusers transformers xformers accelerate timm # For using pretrained models
pip install scipy opencv-python # For augmentations or loss
pip install pyyaml easydict hydra-core # For using config files
pip install termcolor wandb # For printing and logging Voir data/environment.yml pour une copie de mon environnement. Nous nous appuyons également sur certaines dépendances de detectorron2 et panopticapi. Veuillez suivre leurs documents.
Nous prenons actuellement en charge l'ensemble de données COCO. Veuillez suivre la documentation pour installer les images et leurs masques de segmentation panoptique correspondants. Jetez également un œil au répertoire ldmseg/data/ pour quelques exemples sur l’ensemble de données COCO. En passant, la structure adoptée devrait être assez standard :
.
└── coco
├── annotations
├── panoptic_semseg_train2017
├── panoptic_semseg_val2017
├── panoptic_train2017 -> annotations/panoptic_train2017
├── panoptic_val2017 -> annotations/panoptic_val2017
├── test2017
├── train2017
└── val2017
Enfin, modifiez les chemins dans configs/env/root_paths.yml respectivement par la racine de votre ensemble de données et le répertoire de sortie souhaité.
L'approche présentée est à deux volets : premièrement, nous entraînons un auto-encodeur pour représenter des cartes de segmentation dans un espace de dimension inférieure (par exemple, 64x64). Ensuite, nous partons de modèles de diffusion latente (MLD) pré-entraînés, en particulier de diffusion stable, pour former un modèle capable de générer des masques panoptiques à partir d'images RVB. Les modèles peuvent être entraînés en exécutant les commandes suivantes. Par défaut, nous nous entraînerons sur l'ensemble de données COCO avec le fichier de configuration de base défini dans tools/configs/base/base.yaml . Notez que ce fichier sera automatiquement chargé car nous nous appuyons sur le package hydra .
python - W ignore tools / main_ae . py
datasets = coco
base . train_kwargs . fp16 = True
base . optimizer_name = adamw
base . optimizer_kwargs . lr = 1e-4
base . optimizer_kwargs . weight_decay = 0.05 Plus de détails sur la transmission des arguments peuvent être trouvés dans tools/scripts/train_ae.sh . Par exemple, j'exécute ce modèle pendant 50 000 itérations sur un seul GPU de 23 Go avec une taille totale de lot de 16.
python - W ignore tools / main_ldm . py
datasets = coco
base . train_kwargs . gradient_checkpointing = True
base . train_kwargs . fp16 = True
base . train_kwargs . weight_dtype = float16
base . optimizer_zero_redundancy = True
base . optimizer_name = adamw
base . optimizer_kwargs . lr = 1e-4
base . optimizer_kwargs . weight_decay = 0.05
base . scheduler_kwargs . weight = 'max_clamp_snr'
base . vae_model_kwargs . pretrained_path = '$AE_MODEL' $AE_MODEL désigne le chemin d'accès au modèle obtenu à l'étape précédente. Plus de détails sur la transmission des arguments peuvent être trouvés dans tools/scripts/train_diffusion.sh . Par exemple, j'ai exécuté ce modèle pendant 200 000 itérations sur 8 GPU de 16 Go avec une taille totale de lot de 256.
Nous prévoyons de publier plusieurs modèles entraînés. La métrique PQ (indépendante de la classe) est fournie sur l’ensemble de validation COCO.
| Modèle | #Params | Ensemble de données | Iters | PQ | SQ | QR | Lien de téléchargement |
|---|---|---|---|---|---|---|---|
| AE | ~2M | COCO | 66k | - | - | - | Télécharger (23 Mo) |
| MLD | ~800M | COCO | 200k | 51,7 | 82,0 | 63,0 | Télécharger (3,3 Go) |
Remarque : Un AE moins puissant (c'est-à-dire moins de couches de sous-échantillonnage ou de suréchantillonnage) peut souvent bénéficier de l'inpainting, car nous n'effectuons pas de réglage supplémentaire.
L’évaluation devrait ressembler à :
python - W ignore tools / main_ldm . py
datasets = coco
base . sampling_kwargs . num_inference_steps = 50
base . eval_only = True
base . load_path = $ PRETRAINED_MODEL_PATH Vous pouvez ajouter des paramètres si nécessaire. Des seuils plus élevés tels que --base.eval_kwargs.count_th 700 ou --base.eval_kwargs.mask_th 0.9 peuvent encore augmenter les chiffres. Cependant, nous utilisons des valeurs standard en établissant un seuil à 0,5 et en supprimant les segments dont la surface est inférieure à 512 pour l'évaluation.
Pour évaluer un modèle pré-entraîné ci-dessus, exécutez tools/scripts/eval.sh .
Ici, nous visualisons les résultats :

Si vous trouvez ce référentiel utile pour votre recherche, pensez à citer l'article suivant :
@article { vangansbeke2024ldmseg ,
title = { a simple latent diffusion approach for panoptic segmentation and mask inpainting } ,
author = { Van Gansbeke, Wouter and De Brabandere, Bert } ,
journal = { arxiv preprint arxiv:2401.10227 } ,
year = { 2024 }
}Pour toute demande, veuillez contacter l’auteur principal.
Ce logiciel est publié sous une licence Creative Commons qui autorise uniquement une utilisation personnelle et de recherche. Pour une licence commerciale, veuillez contacter les auteurs. Vous pouvez consulter un résumé de la licence ici.
Je remercie tous les référentiels publics (voir aussi les références dans le code), et en particulier les librairies detectorron2 et diffusers.


