Copilote d'IA open source pour une création de pipeline de données sans effort
Principales fonctionnalités
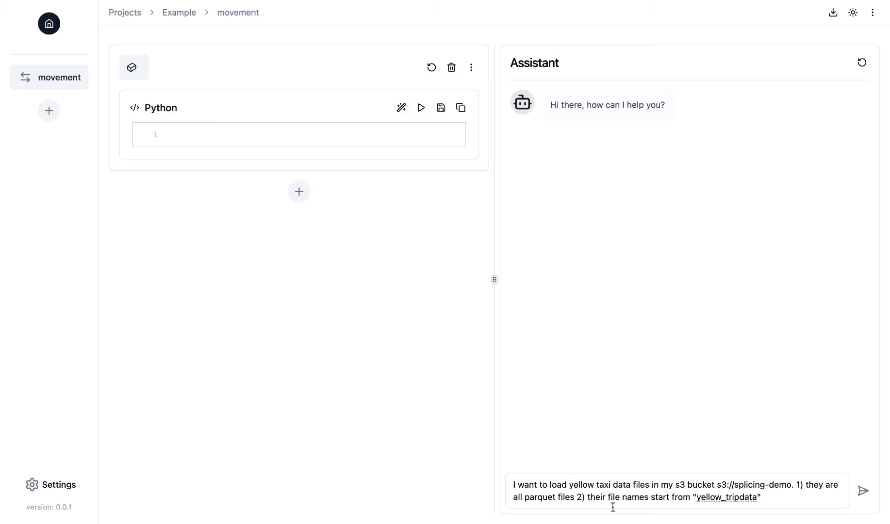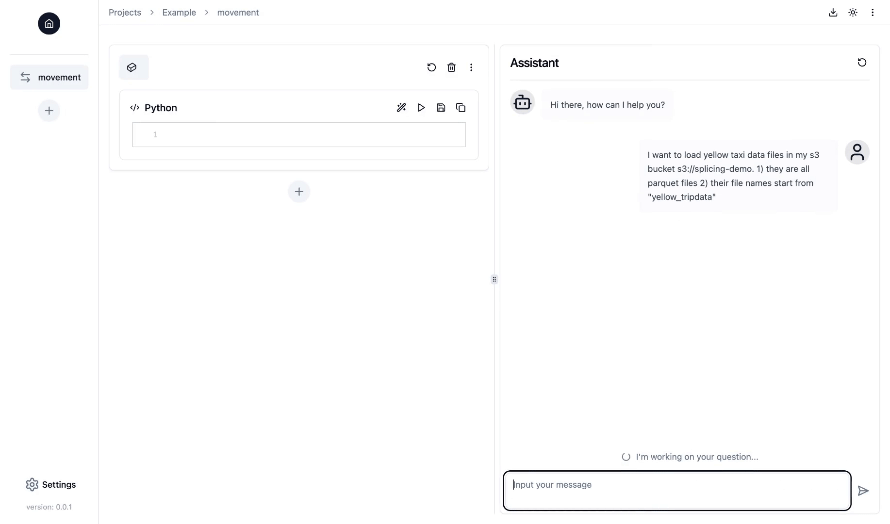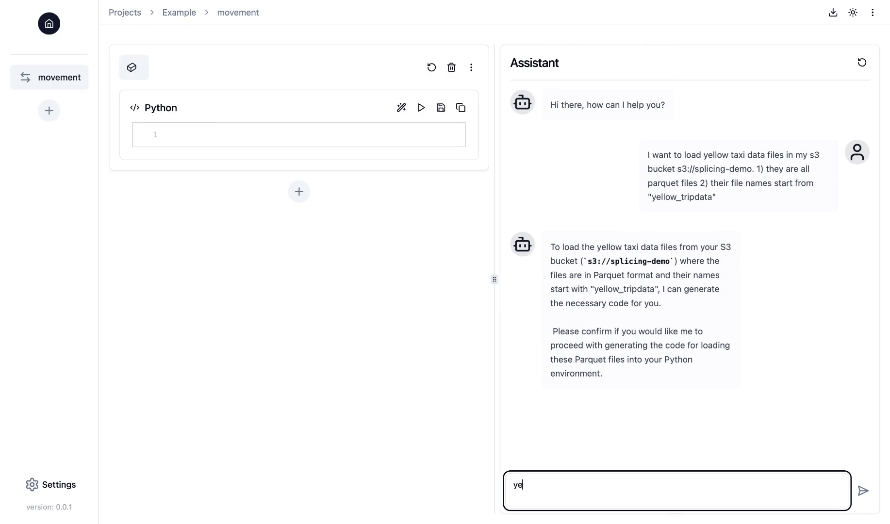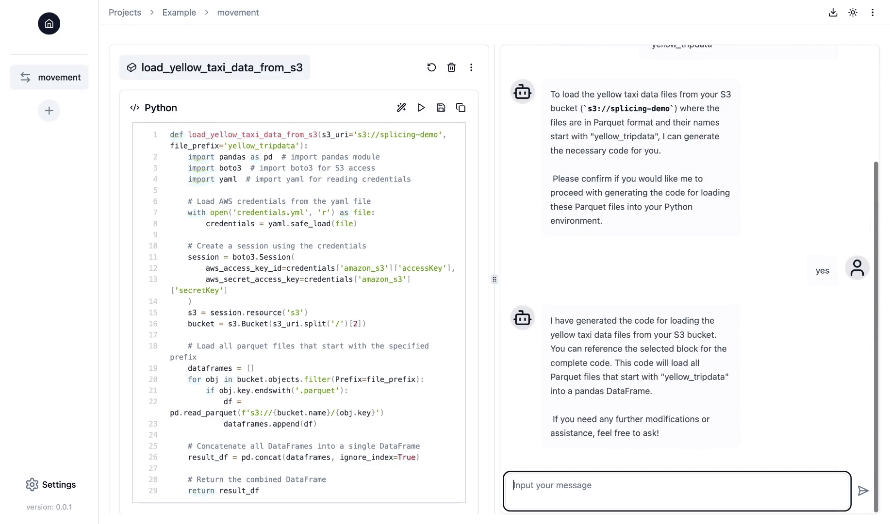
- Interface de type bloc-notes avec fonctionnalités de discussion dans une interface utilisateur Web : travaillez sur vos pipelines de données dans une interface de bloc-notes Jupyter familière, tandis que le copilote IA vous assiste et vous guide en générant, exécutant et déboguant le code d'ingénierie des données tout au long du processus.
- Pas de dépendance vis-à-vis d'un fournisseur : créez vos pipelines de données avec la pile de données de votre choix et sélectionnez le LLM que vous préférez pour votre copilote, en toute flexibilité.
- Entièrement personnalisable : divisez votre pipeline en plusieurs composants, tels que le mouvement des données, la transformation, etc., et adaptez chaque composant à vos besoins spécifiques. Splicing assemble ensuite ces composants de manière transparente dans un pipeline de données complet et fonctionnel.
- Sécurisé et gérable : hébergez Splicing sur votre propre infrastructure, avec un contrôle total sur vos données et LLM. Vos données et clés secrètes ne sont à aucun moment partagées avec les fournisseurs LLM.
Démarrage rapide
Le moyen le plus simple d’exécuter Splicing est dans Docker :
Installez Docker.
Exécutez la commande suivante pour exécuter Splicing :
docker run -v $( pwd ) /.splicing:/app/.splicing
-p 3000:3000
-p 8000:8000
-it --rm splicingai/splicing:latest
Par défaut, toutes les données d'application sont stockées dans le dossier ./.splicing dans le répertoire actuel où vous exécutez la commande ci-dessus. Si vous souhaitez conserver les données, assurez-vous de sauvegarder ce dossier.
- Accédez à http://localhost:3000/ pour accéder à l'interface utilisateur Web.
Vous pouvez également installer Splicing sans Docker pour le développement en suivant les instructions du guide CONTRIBUTION.
Feuille de route
- Déploiement de pipelines de données : prenez en charge le déploiement de pipelines de données dans vos environnements de production avec une expérience push-to-deploy.
- Plus de composants de pipeline de données : prise en charge de composants plus essentiels dans les pipelines de données, tels que les contrôles de qualité des données et le lignage des données.
- Plus d'intégrations :
- Prise en charge d'un large éventail d'intégrations de données dans les pipelines de données (par exemple, diverses sources de données et entrepôts).
- Soutenir davantage de LLM en tant que copilotes (par exemple, Claude et les modèles locaux).
- Rationalisez la structure du code source, permettant à la communauté d’ajouter plus facilement des intégrations.
- Copilote plus intelligent : améliorez le copilote avec plus de fonctionnalités, telles que la génération automatique de modèles sémantiques et de diagrammes ER pour les données dans les entrepôts, facilitant ainsi la création de pipelines de données.
Ressources
- Documentation
- Démo
- Communauté
Piles technologiques
- Frontend : Next.js, Tailwind CSS et Shadcn
- Backend : FastAPI et Redis
- Framework agent : LangGraph
Contribuer
Veuillez vous référer à CONTRIBUTING.md pour plus de détails.
FAQ
Quels sont les principaux cas d’utilisation de l’épissage ?
Splicing aide à créer des pipelines de données, y compris des tâches telles que l'ingestion, la transformation et l'orchestration des données, afin de préparer vos données aux processus en aval tels que l'analyse des données et l'apprentissage automatique.
À qui s’adresse l’épissage ?
Splicing est conçu pour les ingénieurs de données, les scientifiques de données et toute personne ayant besoin de créer des pipelines de données. Même si vous avez une expérience limitée en ingénierie de données, AI Copilot de Splicing vous guidera étape par étape et vous pourrez demander de l'aide à tout moment en utilisant le langage naturel.
En quoi Splicing est-il différent des autres outils de génération de code et copilotes d’IA ?
L'épissage est spécialement conçu pour l'ingénierie des données, un domaine comportant de nombreux choix complexes qui n'a pas encore pleinement adopté l'IA générative pour la productivité. Contrairement aux outils génériques, Splicing se concentre sur l'optimisation des modèles de langage pour les étapes fixes courantes dans les pipelines de données. Il est également profondément intégré aux sources de données et aux outils, permettant au copilote de comprendre le contexte de votre projet (vos configurations, données, etc.), conduisant à une génération de code plus précise et plus utile par rapport aux copilotes à usage général.
Dans quelle mesure l’épissage est-il sécurisé ? Mes données seront-elles partagées ?
Splicing est open source et peut être hébergé sur votre propre infrastructure. Vos données et clés secrètes ne sont jamais partagées avec nous ou avec aucun fournisseur LLM, de par leur conception. De plus, Splicing Copilot n'exécute pas automatiquement le code généré : vous contrôlez quand et comment il est exécuté.
Puis-je exécuter des pipelines de données créés avec Splicing ailleurs ?
Oui! Splicing génère du code à l’aide de vos intégrations de données et outils préférés. Vous pouvez exporter le code en un seul clic et l'exécuter ou le déployer où vous le souhaitez. Il n’y a pas de dépendance vis-à-vis d’un fournisseur.



