BeatLearning
1.0.0
Avez-vous déjà eu envie de jouer une chanson qui n'était pas disponible dans votre jeu de rythme préféré ? Avez-vous déjà eu envie de jouer des variations infinies de cette chanson ?
Ce projet de recherche Open Source vise à démocratiser le processus de création automatique de beatmaps, en offrant des outils et des modèles de base accessibles aux développeurs de jeux, aux joueurs et aux passionnés, ouvrant la voie à une nouvelle ère de créativité et d'innovation dans le jeu rythmique.
Exemples (d'autres à venir) :
Vous devrez d'abord installer Python 3.12, vous rendre dans le répertoire du dépôt et créer un environnement virtuel via :
python3 -m venv venv
Appelez ensuite source venv/bin/activate ou venvScriptsactivate si vous êtes sur une machine Windows. Une fois l'environnement virtuel activé, vous pouvez installer les bibliothèques requises via :
pip3 install -r requirements.txt
Vous pouvez utiliser Jupyter pour accéder aux exemples notebooks/ :
jupyter notebook
Vous pouvez également essayer la version Google Collab, à condition que vous disposiez d'instances GPU (celles du CPU par défaut mettent une éternité à convertir une chanson).
Le pipeline ne prend en charge que les beatmaps OSU pour le moment.
Ce référentiel est toujours un WORK IN PROGRESS . L'objectif est de développer des modèles génératifs capables de produire automatiquement des beatmaps pour un large éventail de jeux de rythme, quelle que soit la chanson. Ces recherches sont toujours en cours, mais l’objectif est de sortir les MVP le plus rapidement possible.
Toutes les contributions sont valorisées, notamment sous forme de dons informatiques pour la formation des modèles de fondation. Alors si vous êtes intéressé, n'hésitez pas à participer !
Rejoignez-nous pour explorer les possibilités infinies de la génération de beatmaps basées sur l'IA et façonner l'avenir des jeux de rythme !
Les modèles sont disponibles sur HuggingFace.
Les beatmaps des jeux de rythme sont initialement converties dans un format de fichier intermédiaire, qui est ensuite tokenisé en morceaux de 100 ms. Chaque jeton est capable de coder jusqu'à deux événements différents au cours de cette période (holds et/ou hits) quantifiés avec une précision de 10 ms. Le vocabulaire du tokenizer est précalculé plutôt qu'appris à partir des données pour répondre à ce critère. La longueur du contexte et la taille du vocabulaire sont intentionnellement réduites en raison de la rareté d'exemples de formation de qualité dans le domaine.
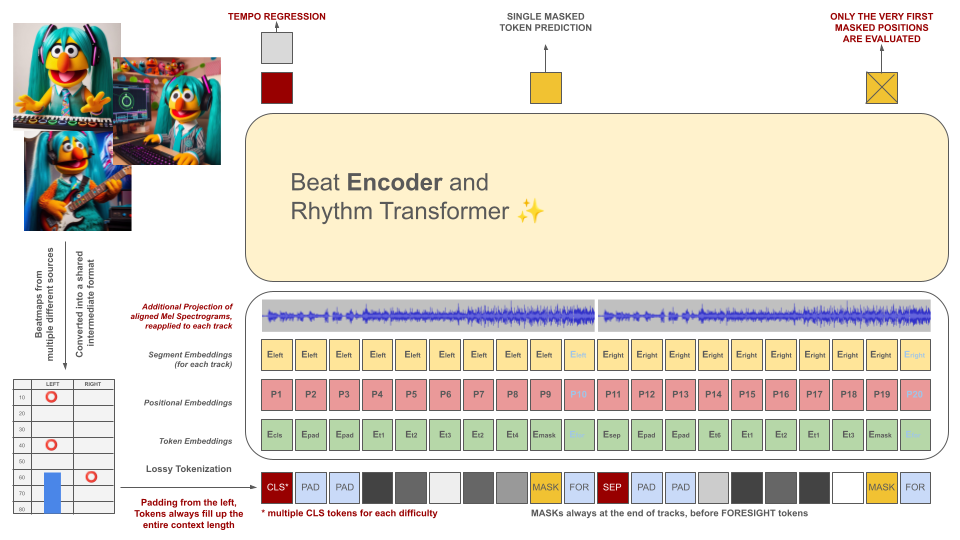 Ces jetons, ainsi que des tranches de données audio (son spectrogramme Mel projeté aligné avec les jetons), servent d'entrées pour un modèle d'encodeur masqué. Semblable à BeRT, le modèle d'encodeur a deux objectifs pendant l'entraînement : estimer le tempo via une tâche de régression et prédire le(s) jeton(s) masqué(s) via une fonction de perte auditive . Les Beatmaps avec 1, 2 et 4 pistes sont prises en charge. Chaque jeton est prédit de gauche à droite, reflétant le processus de génération d'une architecture de décodeur. Cependant, les jetons masqués ont également accès à des informations audio supplémentaires du futur, appelées jetons de prospective à droite.
Ces jetons, ainsi que des tranches de données audio (son spectrogramme Mel projeté aligné avec les jetons), servent d'entrées pour un modèle d'encodeur masqué. Semblable à BeRT, le modèle d'encodeur a deux objectifs pendant l'entraînement : estimer le tempo via une tâche de régression et prédire le(s) jeton(s) masqué(s) via une fonction de perte auditive . Les Beatmaps avec 1, 2 et 4 pistes sont prises en charge. Chaque jeton est prédit de gauche à droite, reflétant le processus de génération d'une architecture de décodeur. Cependant, les jetons masqués ont également accès à des informations audio supplémentaires du futur, appelées jetons de prospective à droite.
Le but du modèle d’IA n’est pas de dévaloriser les beatmaps conçues individuellement, mais plutôt :
Tout le contenu généré doit être conforme aux réglementations de l'UE et être correctement étiqueté, y compris des métadonnées indiquant l'implication du modèle d'IA.
LA GÉNÉRATION DE BEATMAPS POUR LE MATÉRIEL PROTÉGÉ PAR LE COPYRIGHT EST STRICTEMENT INTERDITE ! UTILISEZ UNIQUEMENT DES CHANSONS POUR LESQUELLES VOUS POSSÉDEZ DES DROITS !
L'audio présenté dans les exemples de fichiers OSU provient d'artistes répertoriés sur le site Web d'OSU dans la section Artistes présentés et est sous licence pour une utilisation spécifique dans le contenu lié à osu!.
Pour éviter que votre beatmap ne soit utilisée comme données d'entraînement à l'avenir, incluez les métadonnées suivantes dans votre fichier beatmap :
robots: disallow
Le projet s'inspire d'une tentative précédente connue sous le nom d'AIOSU.
En plus de s'appuyer sur le wiki de l'OSU, osu-parser a joué un rôle déterminant dans la clarification des déclarations de beatmap (en particulier les curseurs). Le modèle de transformateur a été influencé par NanoGPT et par l'implémentation pytorch de BeRT.


