GenerativeRL
v0.0.1
Anglais | 简体中文 (chinois simplifié)
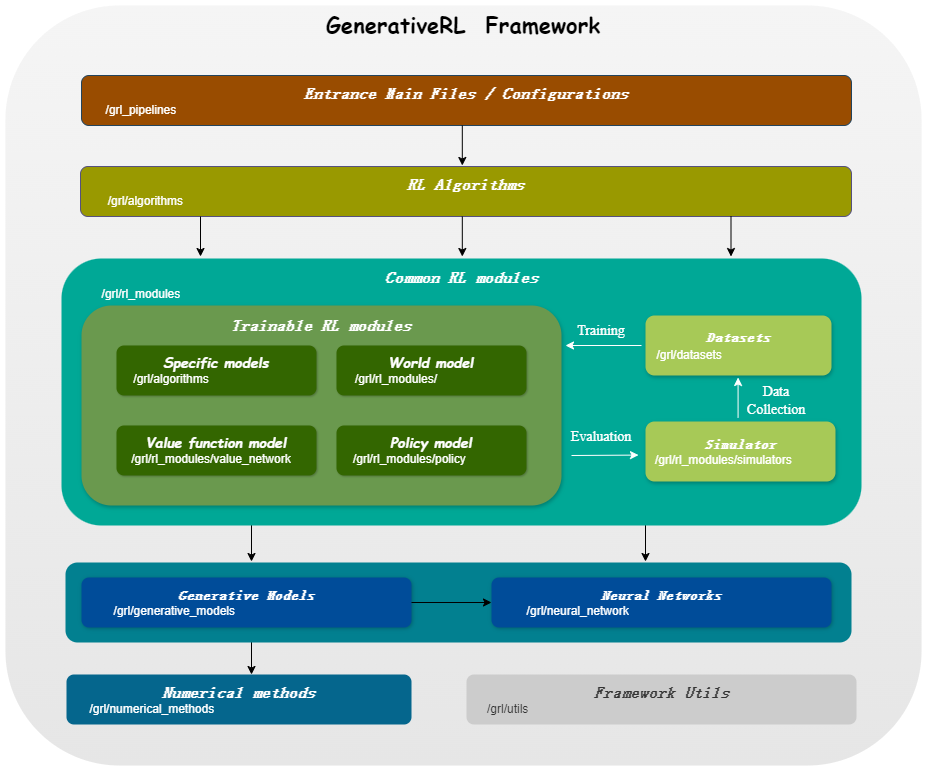
GenerativeRL , abréviation de Generative Reinforcement Learning, est une bibliothèque Python permettant de résoudre des problèmes d'apprentissage par renforcement (RL) à l'aide de modèles génératifs, tels que des modèles de diffusion et des modèles de flux. Cette bibliothèque vise à fournir un cadre permettant de combiner la puissance des modèles génératifs avec les capacités décisionnelles des algorithmes d'apprentissage par renforcement.
| Correspondance des scores | Correspondance de flux | |
|---|---|---|
| Modèle de diffusion | ||
| VP linéaire SDE | ✔ | ✔ |
| VP généralisé SDE | ✔ | ✔ |
| SDE linéaire | ✔ | ✔ |
| Modèle de flux | ||
| Correspondance de flux conditionnelle indépendante | ✔ | |
| Adaptation optimale des flux conditionnels de transport | ✔ |
| Algo./Modèles | Modèle de diffusion | Modèle de flux |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| GMPG | ✔ | ✔ |
pip install GenerativeRLOu, si vous souhaitez installer à partir des sources :
git clone https://github.com/opendilab/GenerativeRL.git
cd GenerativeRL
pip install -e .Ou vous pouvez utiliser l'image Docker :
docker pull opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashVoici un exemple de la façon de former un modèle de diffusion pour l'optimisation des politiques guidées par Q (QGPO) dans l'environnement LunarLanderContinuous-v2 à l'aide de GenerativeRL.
Installez les dépendances requises :
pip install ' gym[box2d]==0.23.1 '(La version gym peut aller de 0,23 à 0,25 pour les environnements box2d, mais il est recommandé d'utiliser la version 0.23.1 pour la compatibilité avec D4RL.)
Téléchargez l'ensemble de données à partir d'ici et enregistrez-le sous data.npz dans le répertoire actuel.
GenerativeRL utilise WandB pour la journalisation. Il vous demandera de vous connecter à votre compte lorsque vous l'utiliserez. Vous pouvez le désactiver en exécutant :
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )Pour des exemples et une documentation plus détaillés, veuillez vous référer à la documentation GenerativeRL.
La documentation complète de GenerativeRL peut être trouvée sur Documentation GenerativeRL.
Nous proposons plusieurs didacticiels de cas pour vous aider à mieux comprendre GenerativeRL. Pour en savoir plus, consultez les didacticiels.
Nous proposons quelques expériences de base pour évaluer les performances des algorithmes d'apprentissage par renforcement génératif. En savoir plus sur le benchmark.
Nous apprécions les contributions à GenerativeRL ! Si vous souhaitez contribuer, veuillez vous référer au Guide de contribution.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}GenerativeRL est sous licence Apache License 2.0. Voir LICENCE pour plus de détails.


