?️Outil Image to Speech GenAI utilisant LLM ?♨️
Outil d'IA qui génère une nouvelle audio basée sur le contexte d'une image téléchargée en invitant un modèle GenAI LLM, des modèles Hugging Face AI avec OpenAI et LangChain. Déployé séparément sur Streamlit & Hugging Space Cloud.
?Exécuter l'application avec Streamlit Cloud
Lancer l'application sur Streamlit
?Exécutez l'application avec HuggingFace Space Cloud
Lancez l'application sur HuggingFace Space
Démo :
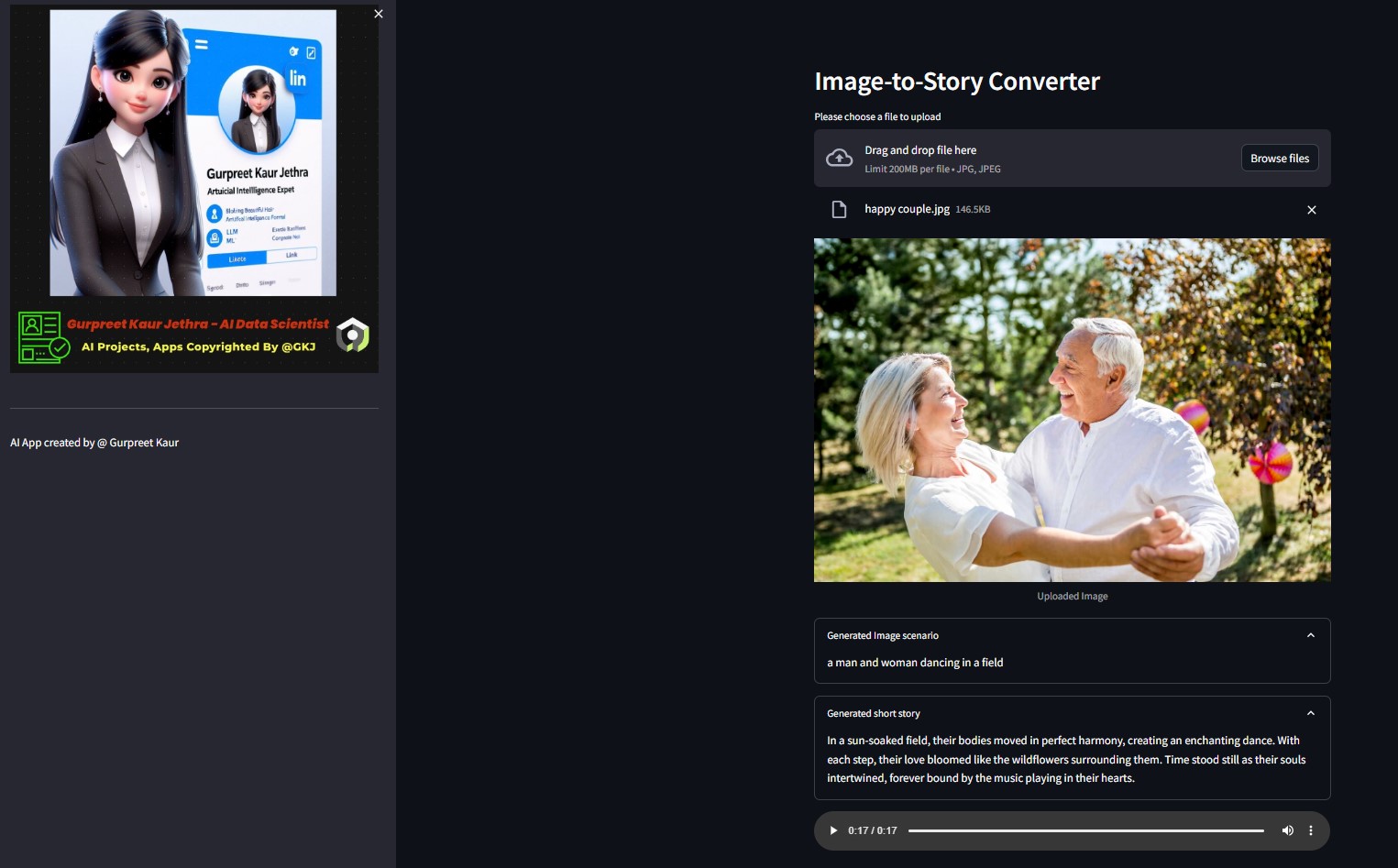
Vous pouvez écouter le fichier audio respectif de ces images de démonstration de test dans le dossier img-audio respectif
?Conception du système
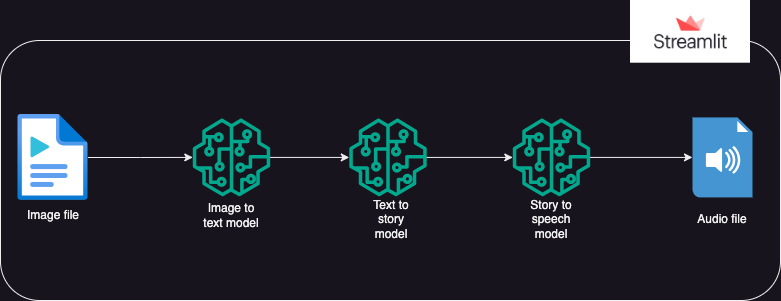
?Approche
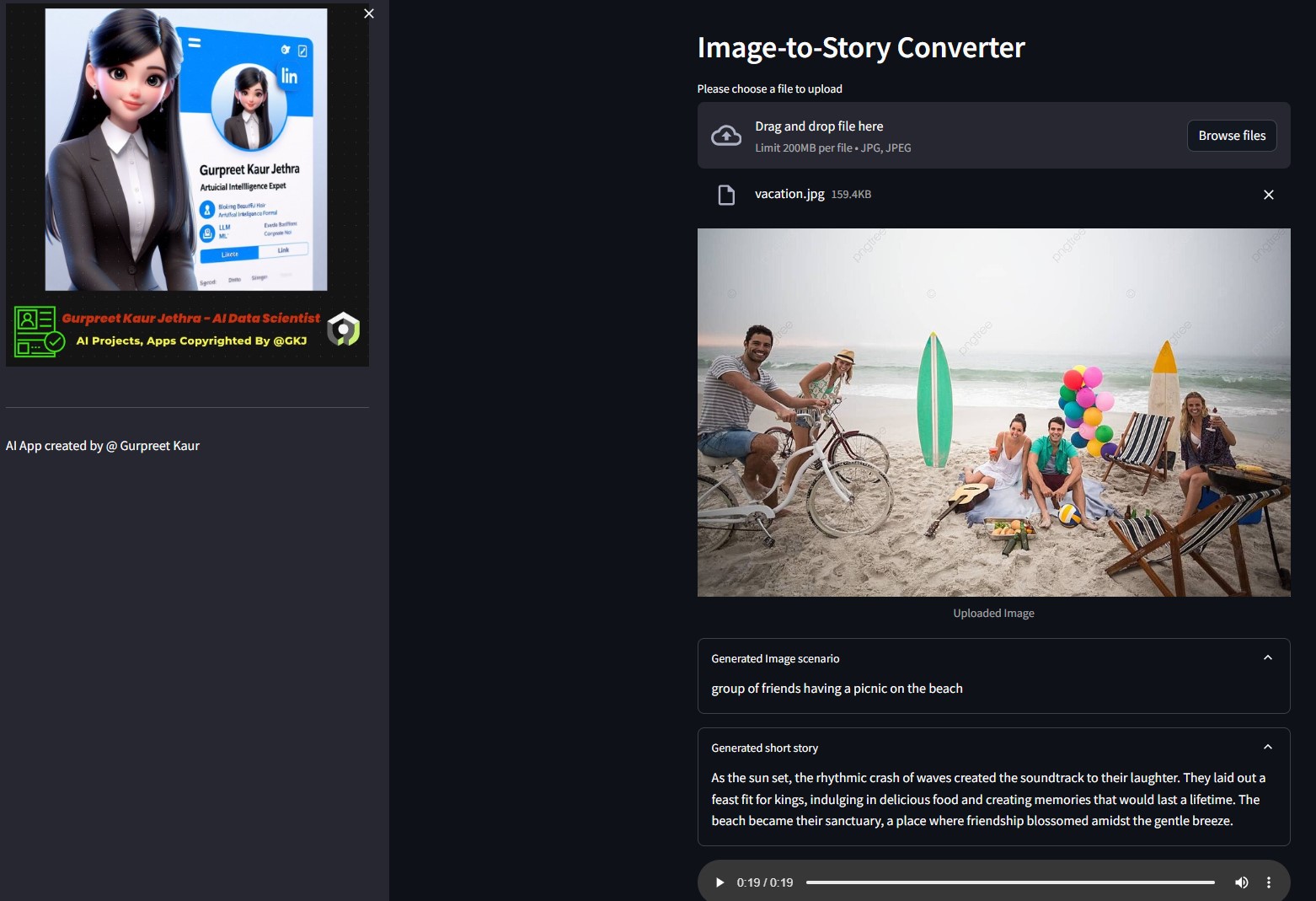
Une application qui utilise les modèles Hugging Face AI pour générer du texte à partir d'une image, qui génère ensuite de l'audio à partir du texte.
L'exécution est divisée en 3 parties :
- Image en texte : un modèle de transformation d'image en texte (Salesforce/blip-image-captioning-base) est utilisé pour générer un scénario de texte basé sur la compréhension de l'IA du contexte de l'image.
- Texte en histoire : le modèle OpenAI LLM est invité à créer une histoire courte (50 mots : peut être ajusté selon les besoins) en fonction du scénario généré. gpt-3.5-turbo
- Histoire en parole : un modèle de transformation de texte en parole (espnet/kan-bayashi_ljspeech_vits) est utilisé pour convertir la nouvelle générée en un fichier audio à narration vocale.
- Une interface utilisateur est construite à l'aide de Streamlit pour permettre le téléchargement de l'image et la lecture du fichier audio.
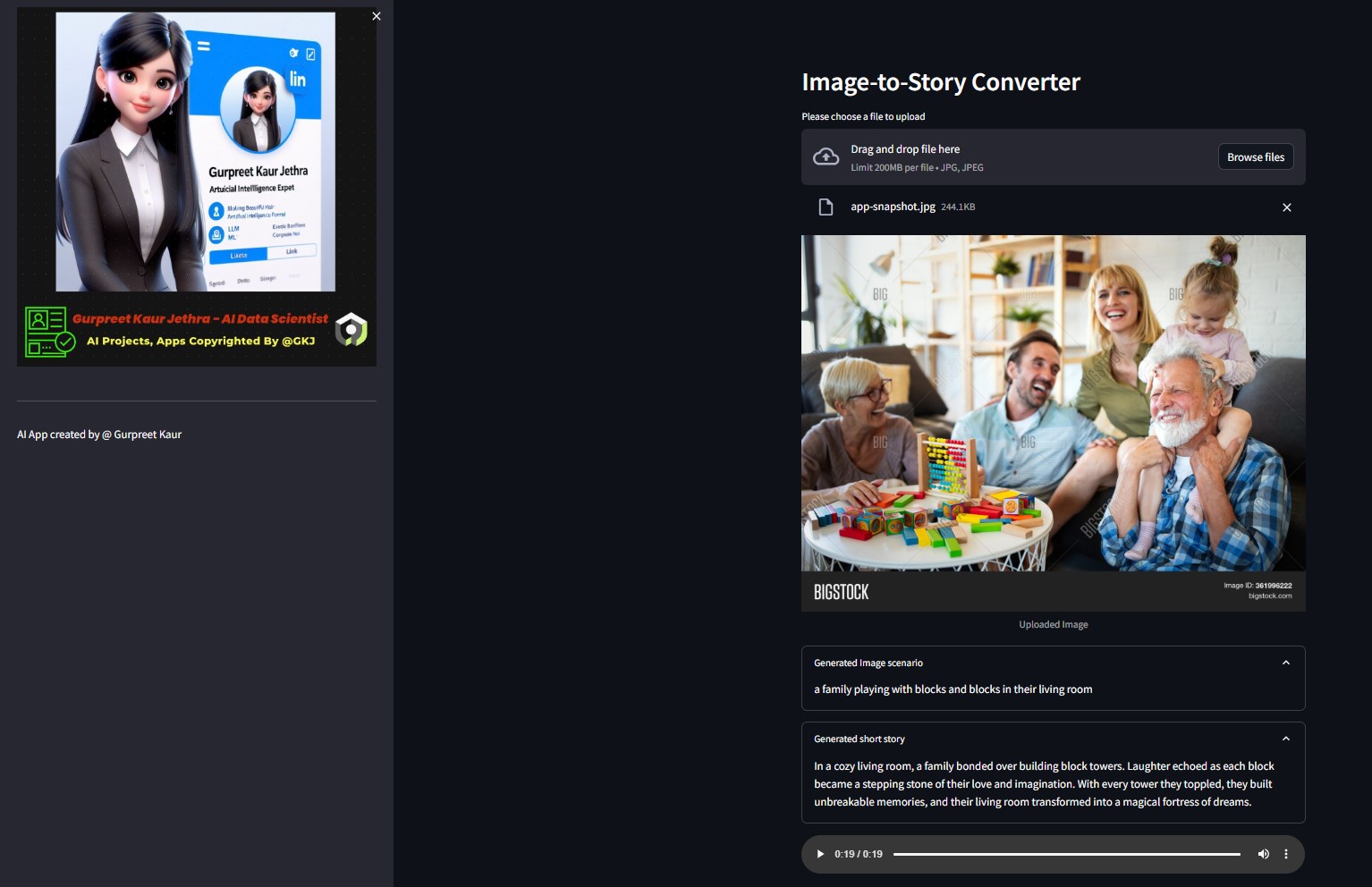 Vous pouvez écouter le fichier audio respectif de cette image de test dans le dossier
Vous pouvez écouter le fichier audio respectif de cette image de test dans le dossier img-audio respectif
?Exigences
- système d'exploitation
- python-dotenv
- transformateurs
- torche
- chaîne de langue
- ouvert
- demandes
- rationalisé
Usage
- Avant d'utiliser l'application, l'utilisateur doit disposer de jetons personnels pour Hugging Face et Open AI.
- L'utilisateur doit définir l'environnement venv et installer la bibliothèque ipykernel pour exécuter l'application sur l'IDE du système local.
- L'utilisateur doit enregistrer les jetons personnels dans un fichier ".env" au sein du package en tant qu'objets chaîne sous les noms d'objet : HUGGINGFACE_TOKEN et OPENAI_TOKEN.
- L'utilisateur peut ensuite exécuter l'application à l'aide de la commande : streamlit run app.py
- Une fois l'application exécutée sur Streamlit, l'utilisateur peut télécharger l'image cible.
- L'exécution démarrera automatiquement et cela peut prendre quelques minutes.
- Une fois terminé, l'application affichera :
- Le texte du scénario généré par le modèle de transformation image en texte HuggingFace
- La nouvelle générée en invitant l'OpenAI LLM
- Le fichier audio racontant la nouvelle générée par le modèle de transformation de synthèse vocale
- Déploiement de l'application Gen AI sur un cloud rationalisé et Hugging Space
▶️ Installation
Clonez le dépôt :
git clone https://github.com/GURPREETKAURJETHRA/Image-to-Speech-GenAI-Tool-Using-LLM.git
Installez les packages Python requis :
pip install -r requirements.txt
Configurez votre clé API OpenAI et votre jeton Hugging Face en créant un fichier .env dans le répertoire racine du projet avec le contenu suivant :
OPENAI_API_KEY=<your-api-key-here> HUGGINGFACE_API_TOKEN=<<your-access-token-here>
Exécutez l'application Streamlit :
streamlit run app.py
©️ Licence
Distribué sous licence MIT. Voir LICENSE pour plus d’informations.
Si vous aimez ce projet LLM, rendez-vous sur ce dépôt et les contributions sont les bienvenues ! Si vous avez des suggestions pour améliorer ce convertisseur AI Img-Speech, veuillez soumettre une pull request.
Suivez-moi sur


