VideoX
1.0.0
Ceci est une collection de notre travail de compréhension vidéo
SeqTrack (
@CVPR'23) : SeqTrack : apprentissage séquence à séquence pour le suivi d'objets visuels
X-CLIP (
@ECCV'22 Oral) : Extension des modèles pré-entraînés langage-image pour la reconnaissance vidéo générale
MS-2D-TAN (
@TPAMI'21) : Réseaux adjacents temporels 2D multi-échelles pour la localisation de moments avec le langage naturel
2D-TAN (
@AAAI'20) : Apprentissage des réseaux adjacents temporels 2D pour la localisation de moments avec le langage naturel
Embaucher des stagiaires de recherche possédant de solides compétences en codage : [email protected] | [email protected]
Avril 2023 : le code pour SeqTrack est maintenant publié.
Février 2023 : SeqTrack a été accepté au CVPR'23
Septembre 2022 : X-CLIP est désormais intégré à
Août 2022 : le code pour X-CLIP est maintenant publié.
Juillet 2022 : X-CLIP a été accepté à l'ECCV'22 comme oral
Octobre 2021 : le code pour MS-2D-TAN est maintenant publié.
Septembre 2021 : MS-2D-TAN a été accepté au TPAMI'21
Décembre 2019 : Le code pour 2D-TAN est maintenant publié.
Novembre 2019 : 2D-TAN a été accepté à l'AAAI'20
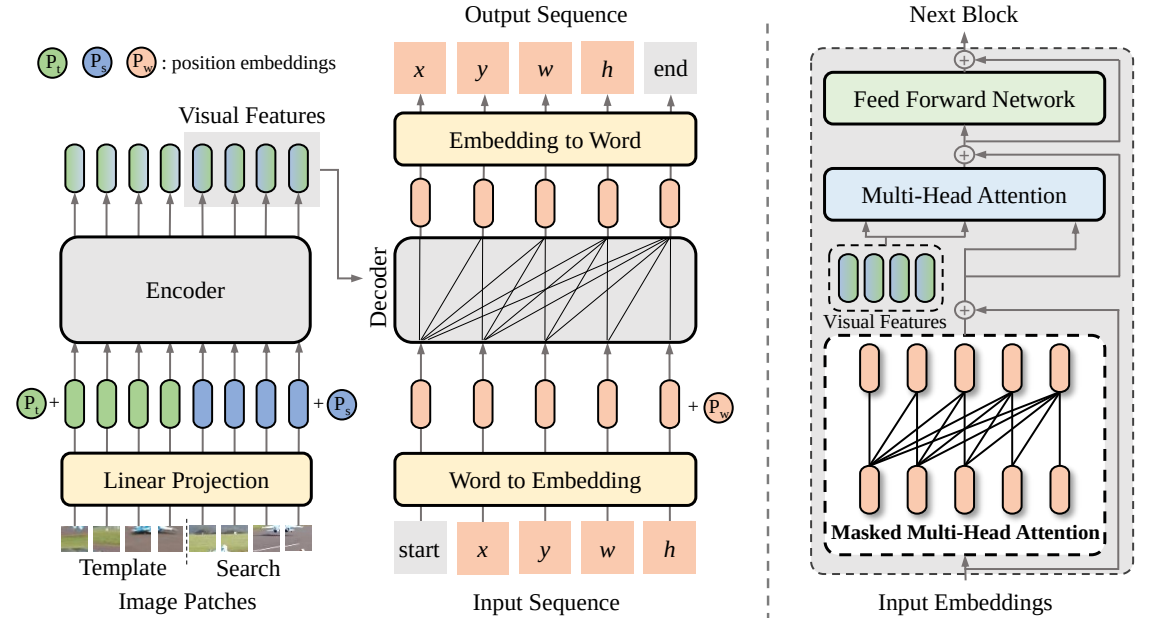
Dans cet article, nous proposons un nouveau cadre d'apprentissage séquence à séquence pour le suivi visuel, baptisé SeqTrack. Il présente le suivi visuel comme un problème de génération de séquences, qui prédit les cadres de délimitation des objets de manière autorégressive. SeqTrack adopte uniquement une architecture simple de transformateur codeur-décodeur. L'encodeur extrait les caractéristiques visuelles avec un transformateur bidirectionnel, tandis que le décodeur génère une séquence de valeurs de cadre englobant de manière autorégressive avec un décodeur causal. La fonction de perte est une simple entropie croisée. Un tel paradigme d'apprentissage séquentiel simplifie non seulement le cadre de suivi, mais permet également d'obtenir des performances compétitives sur de nombreux benchmarks.
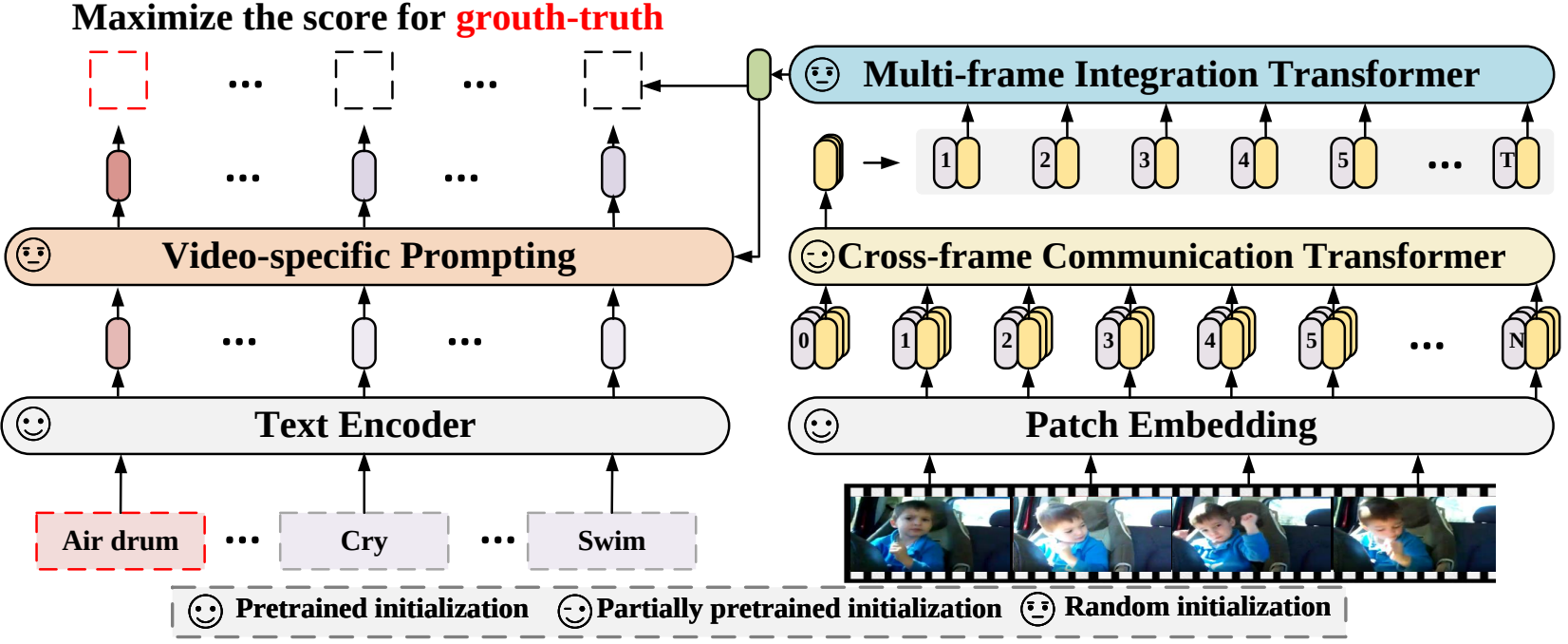
Dans cet article, nous proposons un nouveau cadre de reconnaissance vidéo qui adapte les modèles langage-image pré-entraînés à la reconnaissance vidéo. Plus précisément, pour capturer les informations temporelles, nous proposons un mécanisme d'attention entre trames qui échange explicitement des informations entre trames. Pour utiliser les informations textuelles dans les catégories vidéo, nous concevons une technique d'invite spécifique à la vidéo qui peut produire une représentation textuelle discriminante au niveau de l'instance. Des expériences approfondies démontrent que notre approche est efficace et peut être généralisée à différents scénarios de reconnaissance vidéo, notamment les scénarios entièrement supervisés, à quelques plans et à zéro plan.
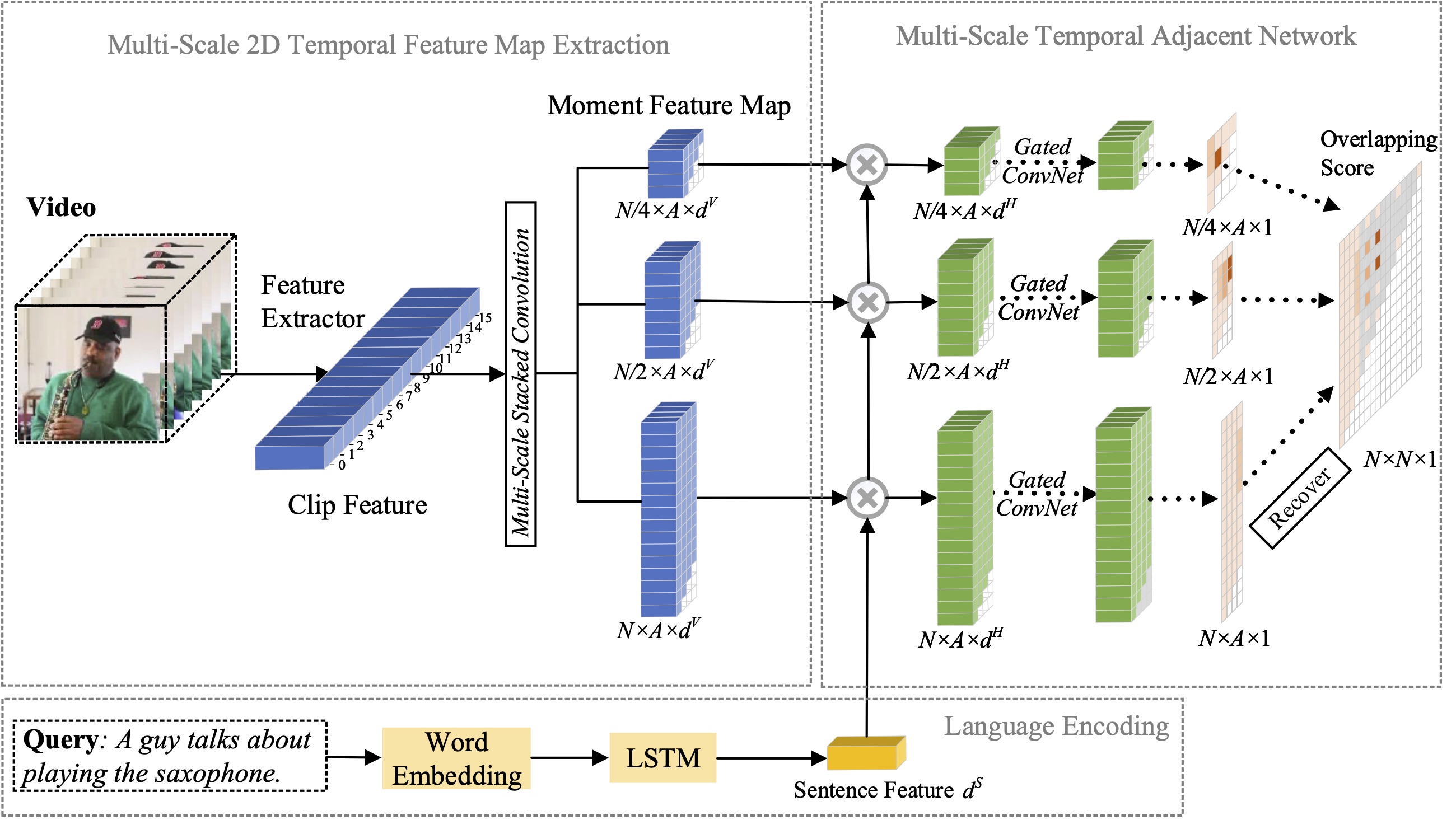
Dans cet article, nous étudions le problème de la localisation des moments avec le langage naturel et proposons d'étendre notre précédente méthode 2D-TAN proposée à une version multi-échelle. L'idée principale est de récupérer un moment à partir de cartes temporelles bidimensionnelles à différentes échelles temporelles, en considérant les moments adjacents comme contexte temporel. La version étendue est capable de coder les relations temporelles adjacentes à différentes échelles, tout en apprenant des fonctionnalités discriminantes pour faire correspondre les moments vidéo avec les expressions de référence. Notre modèle est de conception simple et atteint des performances compétitives par rapport aux méthodes de pointe sur trois ensembles de données de référence.
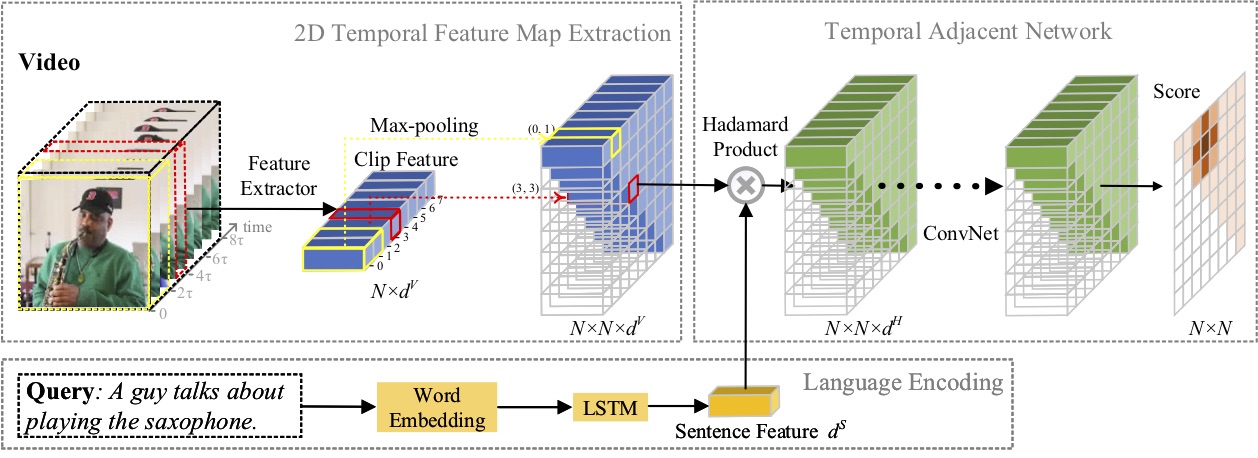
Dans cet article, nous étudions le problème de la localisation des moments avec le langage naturel et proposons une nouvelle méthode de réseaux adjacents temporels 2D (2D-TAN). L'idée principale est de récupérer un moment sur une carte temporelle bidimensionnelle, qui considère les moments candidats adjacents comme contexte temporel. 2D-TAN est capable de coder la relation temporelle adjacente, tout en apprenant une fonctionnalité discriminante pour faire correspondre les moments vidéo avec les expressions de référence. Notre modèle est de conception simple et atteint des performances compétitives par rapport aux méthodes de pointe sur trois ensembles de données de référence.
@InProceedings{SeqTrack, title={SeqTrack : apprentissage séquence à séquence pour le suivi d'objets visuels}, author={Chen, Xin et Peng, Houwen et Wang, Dong et Lu, Huchuan et Hu, Han}, booktitle={CVPR}, year={2023}}@InProceedings{XCLIP, title={Extension des modèles pré-entraînés langage-image pour la reconnaissance vidéo générale}, author={Ni, Bolin et Peng, Houwen et Chen, Minghao et Zhang, Songyang et Meng, Gaofeng et Fu, Jianlong et Xiang, Shiming et Ling, Haibin}, booktitle={Conférence européenne sur la vision par ordinateur (ECCV)}, année ={2022}}@InProceedings{Zhang2021MS2DTAN,
auteur = {Zhang, Songyang et Peng, Houwen et Fu, Jianlong et Lu, Yijuan et Luo, Jiebo},
title = {Réseaux adjacents temporels 2D multi-échelles pour la localisation de moments avec le langage naturel},
titre du livre = {TPAMI},
année = {2021}}@InProceedings{2DTAN_2020_AAAI,
auteur = {Zhang, Songyang et Peng, Houwen et Fu, Jianlong et Luo, Jiebo},
title = {Apprentissage des réseaux adjacents temporels 2D pour la localisation instantanée avec le langage naturel},
titre du livre = {AAAI},
année = {2020}}Licence sous licence MIT.


