horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod est un framework de formation d'apprentissage profond distribué pour TensorFlow, Keras, PyTorch et Apache MXNet. L'objectif d'Horovod est de rendre l'apprentissage profond distribué rapide et facile à utiliser.
Horovod est hébergé par la Fondation LF AI & Data (LF AI & Data). Si vous êtes une entreprise profondément engagée dans l'utilisation des technologies open source en matière d'intelligence artificielle, d'apprentissage automatique et d'apprentissage profond, et que vous souhaitez soutenir les communautés de projets open source dans ces domaines, envisagez de rejoindre la LF AI & Data Foundation. Pour plus de détails sur les personnes impliquées et comment Horovod joue un rôle, lisez l'annonce de la Linux Foundation.
Contenu
La principale motivation de ce projet est de faciliter l'utilisation d'un script de formation sur un seul GPU et de le faire évoluer avec succès pour s'entraîner sur plusieurs GPU en parallèle. Cela présente deux aspects :
En interne chez Uber, nous avons trouvé que le modèle MPI était beaucoup plus simple et nécessitait beaucoup moins de modifications de code que les solutions précédentes telles que Distributed TensorFlow avec des serveurs de paramètres. Une fois qu'un script de formation a été écrit pour évoluer avec Horovod, il peut s'exécuter sur un seul GPU, plusieurs GPU ou même plusieurs hôtes sans aucune autre modification de code. Voir la section Utilisation pour plus de détails.
En plus d’être simple à utiliser, Horovod est rapide. Vous trouverez ci-dessous un graphique représentant le benchmark réalisé sur 128 serveurs équipés de 4 GPU Pascal chacun connectés par un réseau 25 Gbit/s compatible RoCE :
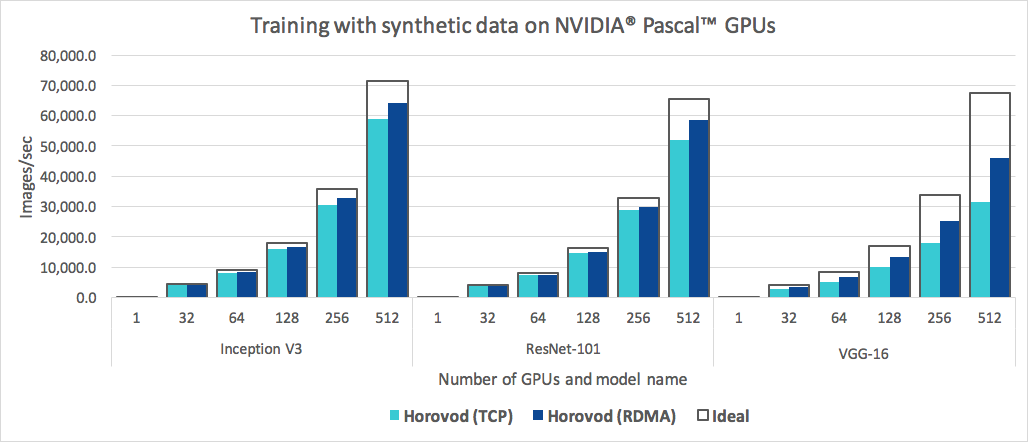
Horovod atteint une efficacité de mise à l'échelle de 90 % pour Inception V3 et ResNet-101, et une efficacité de mise à l'échelle de 68 % pour VGG-16. Voir Benchmarks pour savoir comment reproduire ces chiffres.
Même si l'installation de MPI et NCCL elle-même peut sembler compliquée, elle ne doit être effectuée qu'une seule fois par l'équipe chargée de l'infrastructure, tandis que tous les autres membres de l'entreprise qui construisent les modèles peuvent profiter de la simplicité de leur formation à grande échelle.
Pour installer Horovod sur Linux ou macOS :
Si vous avez installé TensorFlow à partir de PyPI, assurez-vous que g++-5 ou supérieur est installé. À partir de TensorFlow 2.10, un compilateur compatible C++17 comme g++8 ou supérieur sera requis.
Si vous avez installé PyTorch depuis PyPI, assurez-vous que g++-5 ou supérieur est installé.
Si vous avez installé l'un ou l'autre package à partir de Conda, assurez-vous que le package gxx_linux-64 Conda est installé.
Installez le paquet horovod pip.
Pour exécuter sur des processeurs :
$ pip install horovodPour exécuter sur des GPU avec NCCL :
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodPour plus de détails sur l'installation d'Horovod avec la prise en charge GPU, lisez Horovod sur GPU.
Pour la liste complète des options d'installation d'Horovod, lisez le Guide d'installation.
Si vous souhaitez utiliser MPI, lisez Horovod avec MPI.
Si vous souhaitez utiliser Conda, lisez Création d'un environnement Conda avec prise en charge GPU pour Horovod.
Si vous souhaitez utiliser Docker, lisez Horovod dans Docker.
Pour compiler Horovod à partir des sources, suivez les instructions du Guide du contributeur.
Les principes fondamentaux d'Horovod sont basés sur les concepts MPI tels que la taille , le rang , le rang local , allreduce , allgather , broadcast et alltoall . Voir cette page pour plus de détails.
Consultez ces pages pour des exemples et des bonnes pratiques Horovod :
Pour utiliser Horovod, effectuez les ajouts suivants à votre programme :
hvd.init() pour initialiser Horovod.Épinglez chaque GPU à un seul processus pour éviter les conflits de ressources.
Avec la configuration typique d'un GPU par processus, définissez-le sur local Rank . Le premier processus sur le serveur se verra attribuer le premier GPU, le deuxième processus se verra attribuer le deuxième GPU, et ainsi de suite.
Augmentez le taux d’apprentissage en fonction du nombre de travailleurs.
La taille effective des lots dans la formation distribuée synchrone est adaptée au nombre de travailleurs. Une augmentation du taux d’apprentissage compense l’augmentation de la taille des lots.
Enveloppez l'optimiseur dans hvd.DistributedOptimizer .
L'optimiseur distribué délègue le calcul des gradients à l'optimiseur d'origine, fait la moyenne des gradients à l'aide de allreduce ou allgather , puis applique ces gradients moyennés.
Diffusez les états variables initiaux du rang 0 à tous les autres processus.
Cela est nécessaire pour garantir une initialisation cohérente de tous les travailleurs lorsque la formation est démarrée avec des poids aléatoires ou restaurée à partir d'un point de contrôle.
Exemple utilisant TensorFlow v1 (voir le répertoire d'exemples pour des exemples de formation complets) :
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )Les exemples de commandes ci-dessous montrent comment exécuter une formation distribuée. Voir Exécuter Horovod pour plus de détails, y compris les ajustements RoCE/InfiniBand et des conseils pour gérer les blocages.
Pour exécuter sur une machine avec 4 GPU :
$ horovodrun -np 4 -H localhost:4 python train.pyPour fonctionner sur 4 machines avec 4 GPU chacune :
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py Pour exécuter avec Open MPI sans le wrapper horovodrun , consultez Exécuter Horovod avec Open MPI.
Pour exécuter dans Docker, consultez Horovod dans Docker.
Pour exécuter sur Kubernetes, consultez Helm Chart, Kubeflow MPI Operator, FfDL et Polyaxon.
Pour exécuter sur Spark, consultez Horovod sur Spark.
Pour exécuter sur Ray, voir Horovod sur Ray.
Pour exécuter dans Singularity, voir Singularity.
Pour exécuter dans un cluster LSF HPC (par exemple Summit), voir LSF.
Pour exécuter sur Hadoop Yarn, voir TonY.
Gloo est une bibliothèque de communications collectives open source développée par Facebook.
Gloo est inclus avec Horovod et permet aux utilisateurs d'exécuter Horovod sans nécessiter l'installation de MPI.
Pour les environnements prenant en charge à la fois MPI et Gloo, vous pouvez choisir d'utiliser Gloo au moment de l'exécution en passant l'argument --gloo à horovodrun :
$ horovodrun --gloo -np 2 python train.pyHorovod prend en charge le mélange et la mise en correspondance des collectifs Horovod avec d'autres bibliothèques MPI, telles que mpi4py, à condition que le MPI ait été construit avec un support multithread.
Vous pouvez vérifier la prise en charge du multithread MPI en interrogeant la fonction hvd.mpi_threads_supported() .
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()Vous pouvez également initialiser Horovod avec un sous-communicateur mpi4py, auquel cas chaque sous-communicateur exécutera une formation Horovod indépendante.
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))Découvrez comment optimiser votre modèle pour l'inférence et supprimer les opérations Horovod du graphique ici.
L'une des particularités d'Horovod est sa capacité à entrelacer la communication et le calcul, associée à la possibilité de regrouper de petites opérations allreduce , ce qui se traduit par des performances améliorées. Nous appelons cette fonctionnalité de traitement par lots Tensor Fusion.
Voir ici pour plus de détails et des instructions de réglage.
Horovod a la capacité d’enregistrer la chronologie de son activité, appelée Horovod Timeline.
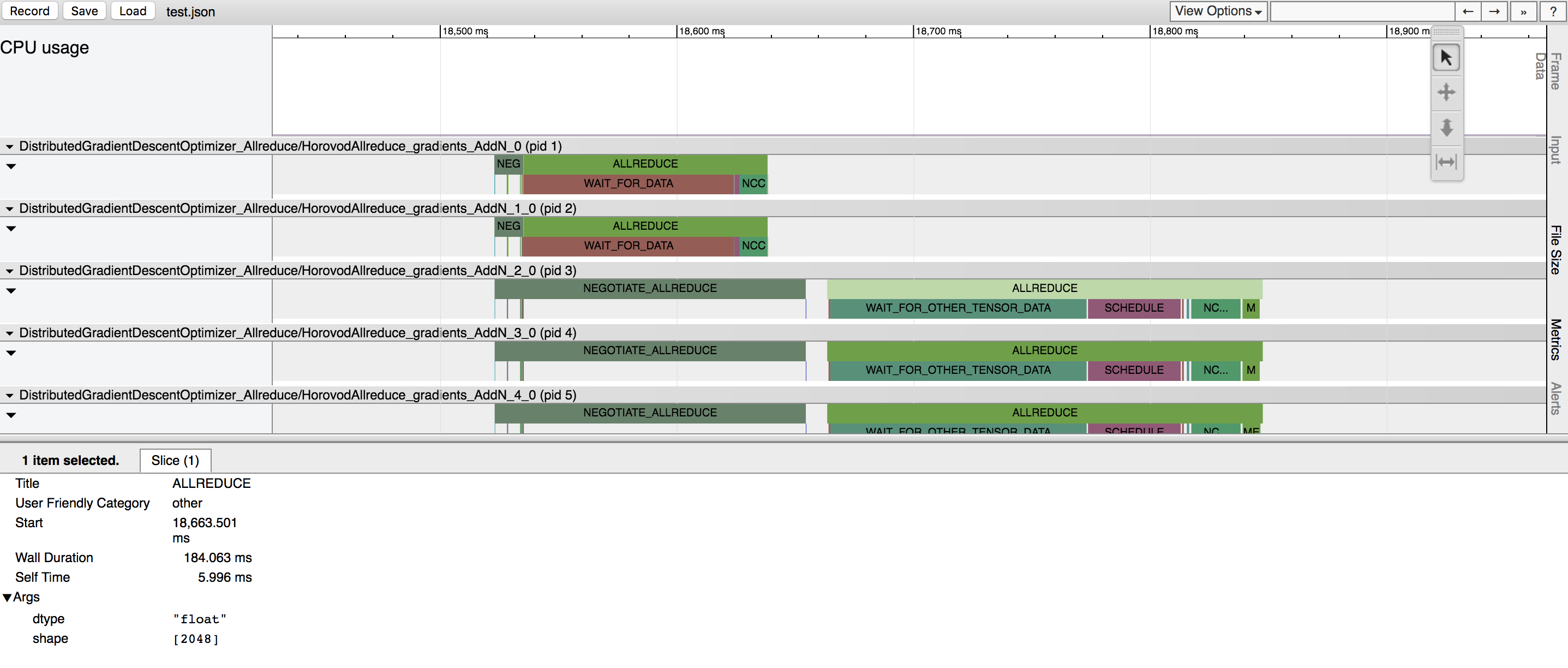
Utilisez la chronologie Horovod pour analyser les performances d’Horovod. Voir ici pour plus de détails et les instructions d'utilisation.
Sélectionner les bonnes valeurs pour utiliser efficacement Tensor Fusion et d'autres fonctionnalités avancées d'Hovod peut impliquer de nombreux essais et erreurs. Nous fournissons un système pour automatiser ce processus d'optimisation des performances appelé autotuning , que vous pouvez activer avec un seul argument de ligne de commande à horovodrun .
Voir ici pour plus de détails et les instructions d'utilisation.
Horovod vous permet d'exécuter simultanément des opérations collectives distinctes dans différents groupes de processus participant à une même formation distribuée. Configurez les objets hvd.process_set pour utiliser cette fonctionnalité.
Voir Ensembles de processus pour des instructions détaillées.
Envoyez-nous des liens vers les guides d'utilisation que vous souhaitez publier sur ce site
Consultez Dépannage et soumettez un ticket si vous ne trouvez pas de réponse.
Veuillez citer Horovod dans vos publications si cela aide vos recherches :
@article{sergeev2018horovod,
Auteur = {Alexander Sergeev et Mike Del Balso},
Journal = {préimpression arXiv arXiv:1802.05799},
Title = {Horovod : apprentissage profond distribué rapide et facile dans {TensorFlow}},
Année = {2018}
}
1. Sergeev, A., Del Balso, M. (2017) Découvrez Horovod : le cadre d'apprentissage profond distribué Open Source d'Uber pour TensorFlow . Récupéré de https://eng.uber.com/horovod/
2. Sergeev, A. (2017) Horovod - TensorFlow distribué en toute simplicité . Récupéré de https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod : apprentissage profond distribué rapide et facile dans TensorFlow . Extrait d'arXiv : 1802.05799
Le code source d'Horovod était basé sur le référentiel Baidu tensorflow-allreduce écrit par Andrew Gibiansky et Joel Hestness. Leur travail original est décrit dans l’article Bringing HPC Techniques to Deep Learning.


