gptty
0.2.7
Wrapper ChatGPT dans votre TTY
Note
Cette version prend en charge gpt4 et gpt4-turbo !
gptty est une interface shell ChatGPT qui vous permet (1) d'interagir avec ChatGPT d'une manière similaire à l'application Web, mais sans avoir besoin de compter sur la stabilité de l'application Web ; (2) préservez le contexte tout au long des sessions de chat et structurez vos conversations comme vous le souhaitez ; (3) enregistrez des copies locales de vos conversations pour une référence facile.
Peut-être êtes-vous un administrateur système qui configure un serveur Web pour votre employeur. Vous accédez au système à partir d'une interface physique, avec une connexion Internet mais sans environnement de bureau ni interface utilisateur graphique. Lors de la configuration du serveur Web, vous recevez une erreur inexplicable que vous redirigez vers un fichier, mais vous ne voulez pas avoir à parcourir des étapes pour le copier sur un autre système avec un navigateur afin de pouvoir rechercher l'erreur. Au lieu de cela, vous installez gptty et redirigez l'erreur vers le client de discussion avec des commandes telles que gptty query --tag error --question "$(cat app.error | tr 'n' ' ')" (ce qui supprimera les sauts de ligne pour vous) ou cat app.error | xargs -d 'n' -I {} gptty query --tag error --question "{}" (ce qui suppose que votre erreur ne s'étend que sur une seule ligne).
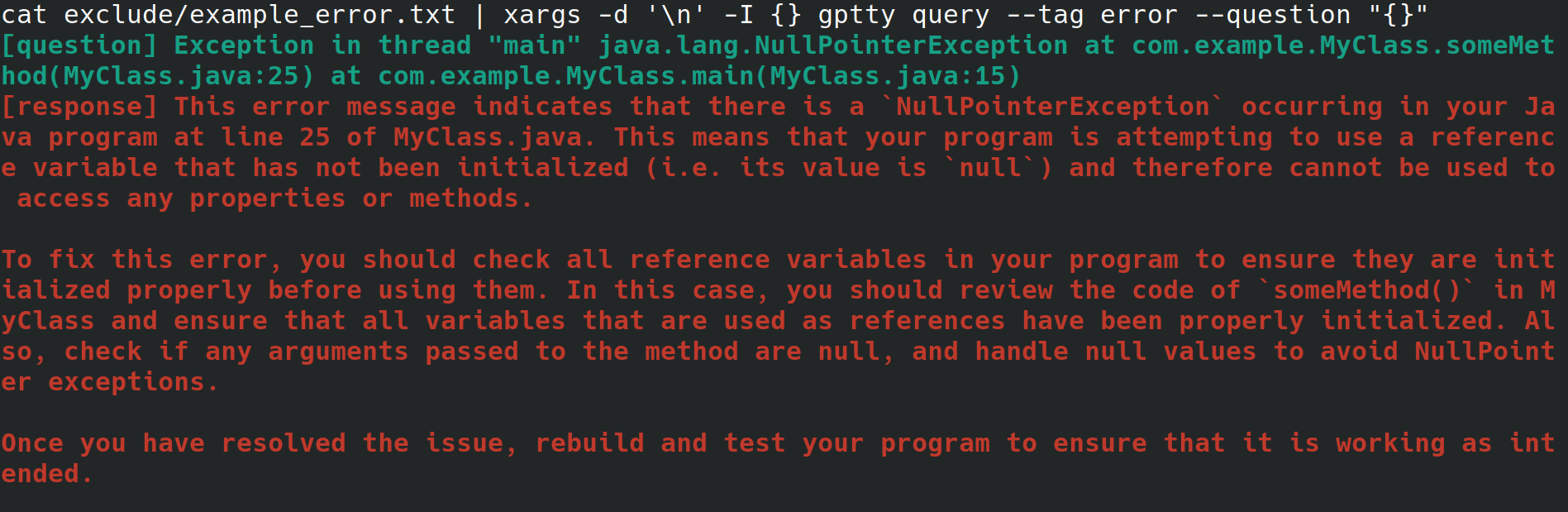
Alternativement, vous êtes un développeur de logiciels ou un data scientist qui souhaite acheminer des données via ChatGPT, mais souhaite utiliser une API hautement abstraite pour effectuer ces requêtes au lieu de vous familiariser intimement avec l'API OpenAI et ses différents wrappers spécifiques au langage. Lorsque vous souhaitez mettre à jour votre base de code pour utiliser un modèle différent, vous souhaitez pouvoir modifier simplement un seul fichier de configuration et vous attendre à ce que le format de réponse à la requête reste cohérent entre les différents modèles.
Ou peut-être êtes-vous un passionné qui souhaite conserver des copies locales de ses conversations ou qui souhaite exercer un contrôle plus direct sur les méthodes de catégorisation que vous utilisez pour ces conversations.
OpenAI met à disposition un certain nombre de modèles via son API. [1] Actuellement, gptty prend en charge Completions (davinci, curie) et ChatCompletions (gpt-3.5-turbo, gpt-4). Tout ce que vous avez à faire est de spécifier le nom du modèle dans votre configuration (la valeur par défaut est text-davinci-003), et l'application se chargera du reste.
Vous pouvez installer gptty sur pip :
pip install gptty
Vous pouvez également installer depuis git :
cd ~/Code # replace this with whatever directory you want to use
git clone https://github.com/signebedi/gptty.git
cd gptty/
# now install the requirements
python3 -m venv venv
source venv/bin/activate
pip install -e .
Maintenant, vous pouvez vérifier qu'il fonctionne en exécutant gptty --help . Si vous rencontrez une erreur, essayez de configurer l'application.
gptty lit les paramètres de configuration à partir d'un fichier nommé gptty.ini , que l'application s'attend à trouver dans le même répertoire que celui à partir duquel vous exécutez gptty , à moins que vous ne transmettiez un config_file personnalisé. Le fichier utilise le format de fichier INI, qui se compose de sections, chacune avec ses propres paires clé-valeur.
| Clé | Taper | Valeur par défaut | Description |
|---|---|---|---|
| clé_api | Chaîne | "" | Votre clé API pour le service GPT d'OpenAI |
| org_id | Chaîne | "" | ID de votre organisation pour le service GPT d'OpenAI |
| votre_nom | Chaîne | "question" | Le nom de l'invite de saisie |
| gpt_name | Chaîne | "réponse" | Le nom de la réponse générée |
| fichier_sortie | Chaîne | "sortie.txt" | Le nom du fichier où la sortie sera enregistrée |
| modèle | Chaîne | "texte-davinci-003" | Le nom du modèle GPT à utiliser |
| température | Flotter | 0,0 | La température à utiliser pour l'échantillonnage |
| max_tokens | Entier | 250 | Le nombre maximum de jetons à générer pour la réponse |
| max_context_length | Entier | 150 | La longueur maximale du contexte de saisie |
| contexte_keywords_only | Booléen | Vrai | Tokeniser les mots-clés pour réduire l'utilisation de l'API |
| préserver_new_lines | Booléen | FAUX | Conserver le formatage original de la réponse |
| verify_internet_endpoint | Chaîne | "google.com" | Adresse pour valider la connexion internet |
Vous pouvez modifier les paramètres du fichier de configuration en fonction de vos besoins. Si une clé n'est pas présente dans le fichier de configuration, la valeur par défaut sera utilisée. La section [main] est utilisée pour spécifier les paramètres du programme.
[main]
api_key =my_api_key Ce référentiel fournit un exemple de fichier de configuration assets/gptty.ini.example que vous pouvez utiliser comme point de départ.
La fonction de chat fournit une interface de chat interactive pour communiquer avec ChatGPT. Vous pouvez poser des questions et recevoir des réponses en temps réel.
Pour démarrer l'interface de discussion, exécutez gptty chat . Vous pouvez également spécifier un chemin de fichier de configuration personnalisé en exécutant :
gptty chat --config_path /path/to/your/gptty.ini
Dans l'interface de chat, vous pouvez saisir directement vos questions ou commandes. Pour afficher la liste des commandes disponibles, tapez :help , qui affichera les options suivantes.
| Métacommande | Description |
|---|---|
| :aide | Affichez une liste des commandes disponibles et leurs descriptions. |
| :quitter | Quittez ChatGPT. |
| :journaux | Affichez les paramètres de configuration actuels. |
| :contexte[a:b] | Affichez l'historique du contexte, en spécifiant éventuellement une plage a et b. En cours de développement |
Pour utiliser une commande, tapez-la simplement dans l'invite de commande et appuyez sur Entrée. Par exemple, utilisez la commande suivante pour afficher les paramètres de configuration actuels dans le terminal :
> :configs
api_key: SOME_KEY_HERE
org_id: org-SOME_CHARS_HERE
your_name: question
gpt_name: response
output_file: output.txt
model: text-davinci-003
temperature: 0.0
max_tokens: 250
max_context_length: 5000
Vous pouvez saisir une question dans l’invite à tout moment et cela générera une réponse pour vous. Si vous souhaitez partager le contexte entre les requêtes, consultez la section contextuelle ci-dessous.
La fonction de requête vous permet de soumettre une ou plusieurs questions à ChatGPT et de recevoir les réponses directement dans la ligne de commande.
Pour utiliser la fonctionnalité de requête, exécutez quelque chose comme :
gptty query --question "What is the capital of France?" --question "What is the largest mammal?"
Vous pouvez également fournir une balise facultative pour catégoriser votre requête :
gptty query --question "What is the capital of France?" --tag "geography"
Vous pouvez spécifier un chemin de fichier de configuration personnalisé si nécessaire :
gptty query --config_path /path/to/your/gptty.ini --question "What is the capital of France?"
N'oubliez pas que gptty utilise un fichier de configuration (par défaut gptty.ini) pour stocker les paramètres tels que les clés API, les configurations de modèle et les chemins des fichiers de sortie. Assurez-vous de disposer d'un fichier de configuration valide avant d'exécuter les commandes gptty.
En ajoutant la balise --verbose à la fin de vos commandes de discussion et de requête, l'application fournira des données de débogage supplémentaires, y compris le nombre de jetons pour chaque requête. Cela peut être utile lorsque vous devez suivre les taux d'utilisation de l'API.

En ajoutant l'option --additional_context [some_string_here] à vos commandes de requête, l'application ajoutera toute chaîne que vous transmettez comme contexte extérieur à votre question.
En ajoutant la balise --json à la fin de vos commandes de requête, l'application ignorera l'écriture de texte lisible par l'homme sur la sortie standard et écrira à la place les questions et les réponses sous forme d'objets json comme [{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...] .

En ajoutant la balise --quiet à la fin de vos commandes de requête, l'application ignorera l'écriture sur stdout, mais écrira toujours les réponses dans le output_file désigné dans le fichier de configuration de l'application.
Le marquage du texte pour le contexte lors de l'utilisation des sous-commandes chat et query dans cette application peut aider à améliorer la précision des réponses générées. Voici comment l'application gère le contexte avec la sous-commande chat :
bananas ou shakespeare .[tag] . Par exemple, si le contexte de votre question est « cuisine », vous pouvez la marquer comme [cooking] . Assurez-vous d'utiliser la même balise de manière cohérente pour toutes les requêtes associées. Voici un exemple de ce à quoi cela pourrait ressembler, en utilisant des questions étiquetées [shakespeare] . Remarquez que, dans la deuxième question, le nom « William Shakespeare » n'est pas du tout mentionné.
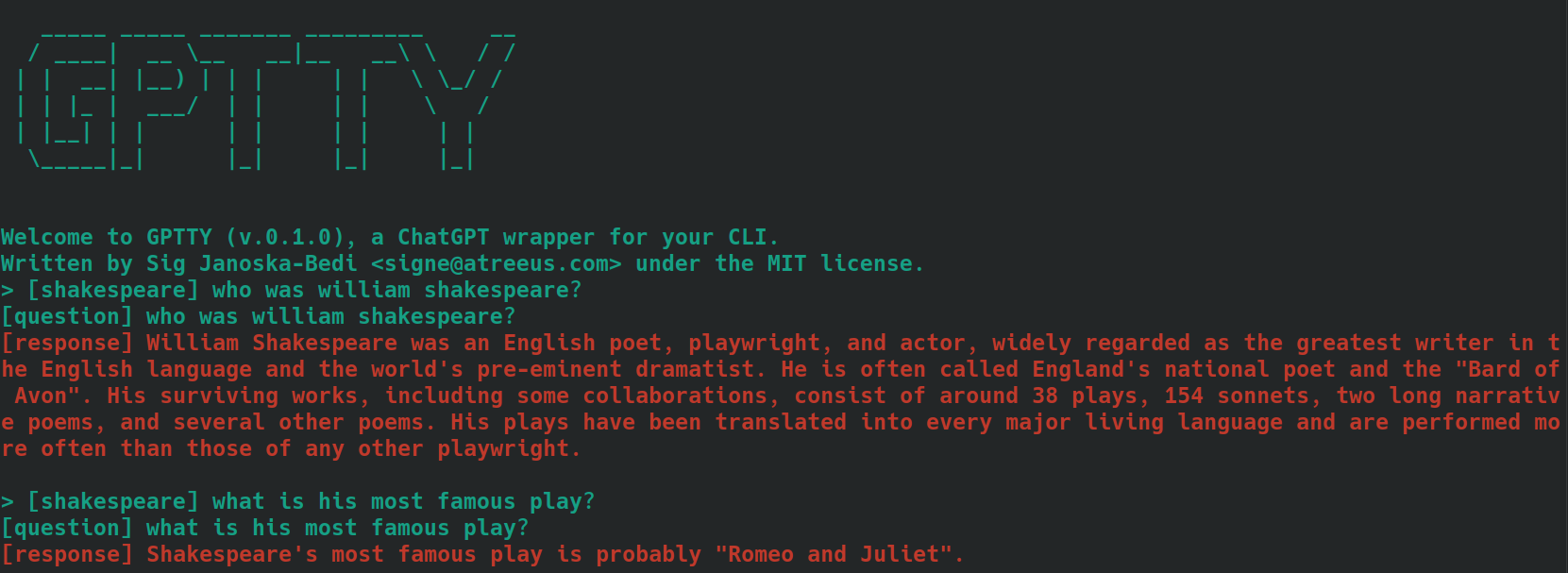
Lorsque vous utilisez la sous-commande query , suivez les mêmes étapes décrites ci-dessus mais, au lieu de faire précéder le texte de vos questions de la balise souhaitée, utilisez l'option --tag pour inclure la balise lors de la soumission de votre requête. Par exemple, si le contexte de votre question est « cuisine », vous pouvez utiliser :
gptty --question "some question" --tag cooking
L'application enregistrera votre question et votre réponse balisées dans le fichier de sortie spécifié dans le fichier de configuration.
Vous pouvez automatiser le processus d'envoi de plusieurs questions à la commande gptty query à l'aide d'un script bash. Cela peut être particulièrement utile si vous avez une liste de questions stockées dans un fichier et que vous souhaitez toutes les traiter en même temps. Par exemple, disons que vous avez un fichier questions.txt avec chaque question sur une nouvelle ligne, comme ci-dessous.
What are the key differences between machine learning, deep learning, and artificial intelligence?
How do I choose the best programming language for a specific project or task?
Can you recommend some best practices for code optimization and performance improvement?
What are the essential principles of good software design and architecture?
How do I get started with natural language processing and text analysis in Python?
What are some popular Python libraries or frameworks for building web applications?
Can you suggest some resources to learn about data visualization and its implementation in Python?
What are some important concepts in cybersecurity, and how can I apply them to my projects?
How do I ensure that my machine learning models are fair, ethical, and unbiased?
Can you recommend strategies for staying up-to-date with the latest trends and advancements in technology and programming?
Vous pouvez envoyer chaque question du fichier questions.txt à la commande gptty query en utilisant le one-liner bash suivant :
xargs -d ' n ' -I {} gptty query --question " {} " < questions.txt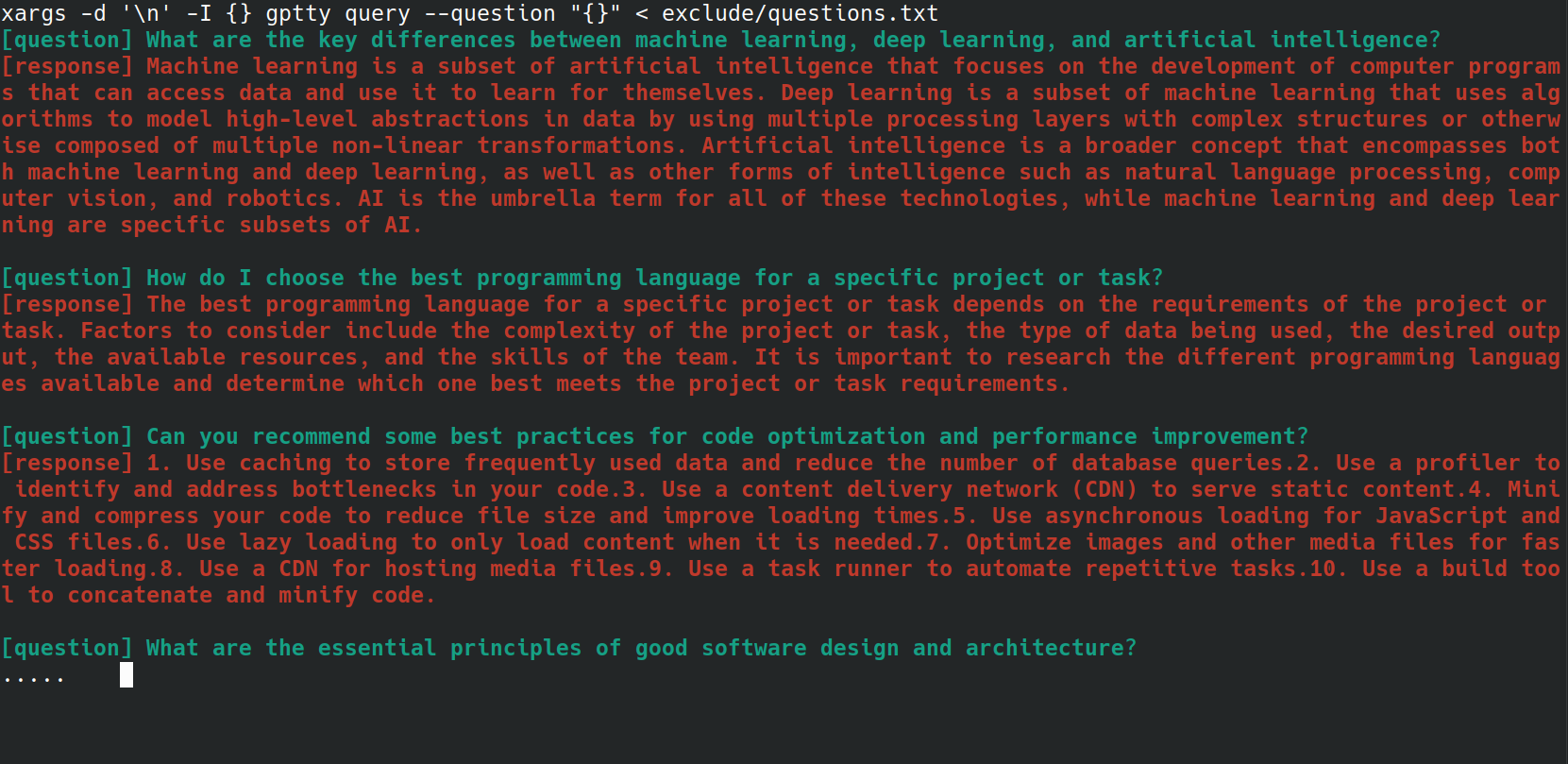
La classe UniversalCompletion fournit une interface unifiée pour interagir avec les modèles de langage d'OpenAI, en faisant (principalement) abstraction des spécificités de savoir si l'application utilise le mode Completion ou ChatCompletion. L'idée principale est de faciliter la création, la configuration et la gestion des modèles de langage. Voici quelques exemples d'utilisation.
# First, import the UniversalCompletion class from the gptty library.
from gptty import UniversalCompletion
# Now, we instantiate a new UniversalCompletion object.
# The 'api_key' parameter is your OpenAI API key, which you get when you sign up for the API.
# The 'org_id' parameter is your OpenAI organization ID, which is also provided when you sign up.
g = UniversalCompletion ( api_key = "sk-SOME_CHARS_HERE" , org_id = "org-SOME_CHARS_HERE" )
# This connects to the OpenAI API using the provided API key and organization ID.
g . connect ()
# Now we specify which language model we want to use.
# Here, 'gpt-3.5-turbo' is specified, which is a version of the GPT-3 model.
g . set_model ( 'gpt-3.5-turbo' )
# This method is used to verify the model type.
# It returns a string that represents the endpoint for the current model in use.
g . validate_model_type ( g . model ) # Returns: 'v1/chat/completions'
# We send a request to the language model here.
# The prompt is a question, given in a format that the model understands.
# The model responds with a completion - an extension of the prompt based on what it has learned during training.
# The returned object is a representation of the response from the model.
g . fetch_response ( prompt = [{ "role" : "user" , "content" : "What is an abstraction?" }])
# Returns a JSON response with the assistant's message.

