Guide de bout en bout pour la diffusion stable – De Noob à Expert
Je me suis intéressé à l'utilisation de la SD pour générer des images destinées à des applications militaires. La plupart des ressources proviennent des forums NSFW de 4chan, car les anons utilisent SD pour créer du hentai. Fait intéressant, le SD WebUI canonique a des fonctionnalités intégrées avec des tableaux d'images anime/hentai... L'un des premiers cas d'utilisation de SD juste après DALL-E générait des anime girls, donc le passage au hentai n'est pas surprenant.
Quoi qu’il en soit, les techniques de ces cinglés sont applicables à une variété d’applications, plus particulièrement les LoRA, qui sont comme des ajusteurs de modèles. L'idée est de travailler avec des LoRA spécifiques (par exemple, des véhicules militaires, des avions, des armes, etc.) pour générer des données d'images synthétiques pour l'entraînement des modèles de vision. La formation de nouvelles LoRA utiles présente également un intérêt. Les éléments ultérieurs peuvent inclure l'inpainting pour la perturbation.
Avis de non-responsabilité et sources
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
Jouez avec !
Que pouvez-vous réellement faire avec SD ? Huggingface et quelques autres ont des applications dans le navigateur pour vous. Jouez avec eux pour voir la puissance ! Ce que nous allons faire dans ce guide, c'est obtenir l'interface Web complète et extensible pour nous permettre de faire tout ce que nous voulons.
- Huggingface Texte à Image SD Playground
- Application Dreamstudio Texte en image SD
- Application Dezgo Texte en image SD
- Huggingface Image à Image SD Playground
- Terrain de jeu de peinture Huggingface
Table des matières
- Bases de l'interface utilisateur Web
- Configurer l'utilisation du GPU local
- Configuration Linux
- Aller plus loin
- Invite
- Modèle NovelAI
- LoRA
- Jouer avec des modèles
- Les VAE
- Rassemblez tout cela
- Le processus général de DD
- Enregistrement des invites
- Paramètres txt2img
- Régénération d'une image générée précédemment
- Dépannage des erreurs
- Être à l'aise
- Essai
- Interface utilisateur Web avancée
- Modification rapide
- Xformers
- Img2Img
- Peinture
- Suppléments
- Réseaux de contrôle
- Créer de nouvelles choses (WIP)
- Fusion de points de contrôle
- LoRA de formation
- Formation de nouveaux modèles
- Configuration de Google Colab (WIP)
- À mi-parcours
- Paramètres MJ
- Invites avancées MJ
- DreamStudio (WIP)
- Horde stable (WIP)
- DreamBooth (WIP)
- Diffusion vidéo (WIP)
Bases de l'interface utilisateur Web
C'est un peu intimidant de se lancer dans ce domaine... mais 4channers a fait du bon travail en rendant cela accessible. Vous trouverez ci-dessous les étapes que j'ai suivies, dans les termes les plus simples. Votre intention est de faire fonctionner l'interface Web de diffusion stable (construite avec Gradio) localement afin que vous puissiez commencer à demander et à créer des images.
Configurer l'utilisation du GPU local
Nous effectuerons la configuration de Google Colab Pro plus tard, afin que nous puissions exécuter SD sur n'importe quel appareil où nous le souhaitons ; mais pour commencer, commençons par configurer WebUI sur un PC. Vous avez besoin de 16 Go de RAM, d’un GPU avec 2 Go de VRAM, de Windows 7+ et de 20+ Go d’espace disque.
- Terminez le guide de configuration de démarrage
- J'ai suivi cela jusqu'à l'étape 7, après quoi cela passe au hentai.
- L'étape 3 prend 15 à 45 minutes en moyenne, car les modèles font plus de 5 Go chacun.
- L'étape 7 peut prendre plus d'une demi-heure et peut sembler « bloquée » dans la CLI
- À l'étape 3, j'ai téléchargé SD1.5, pas les versions 2.x, car la version 1.5 produit de bien meilleurs résultats.
- CivitAI possède tous les modèles SD ; c'est comme HuggingFace mais pour SD spécifiquement
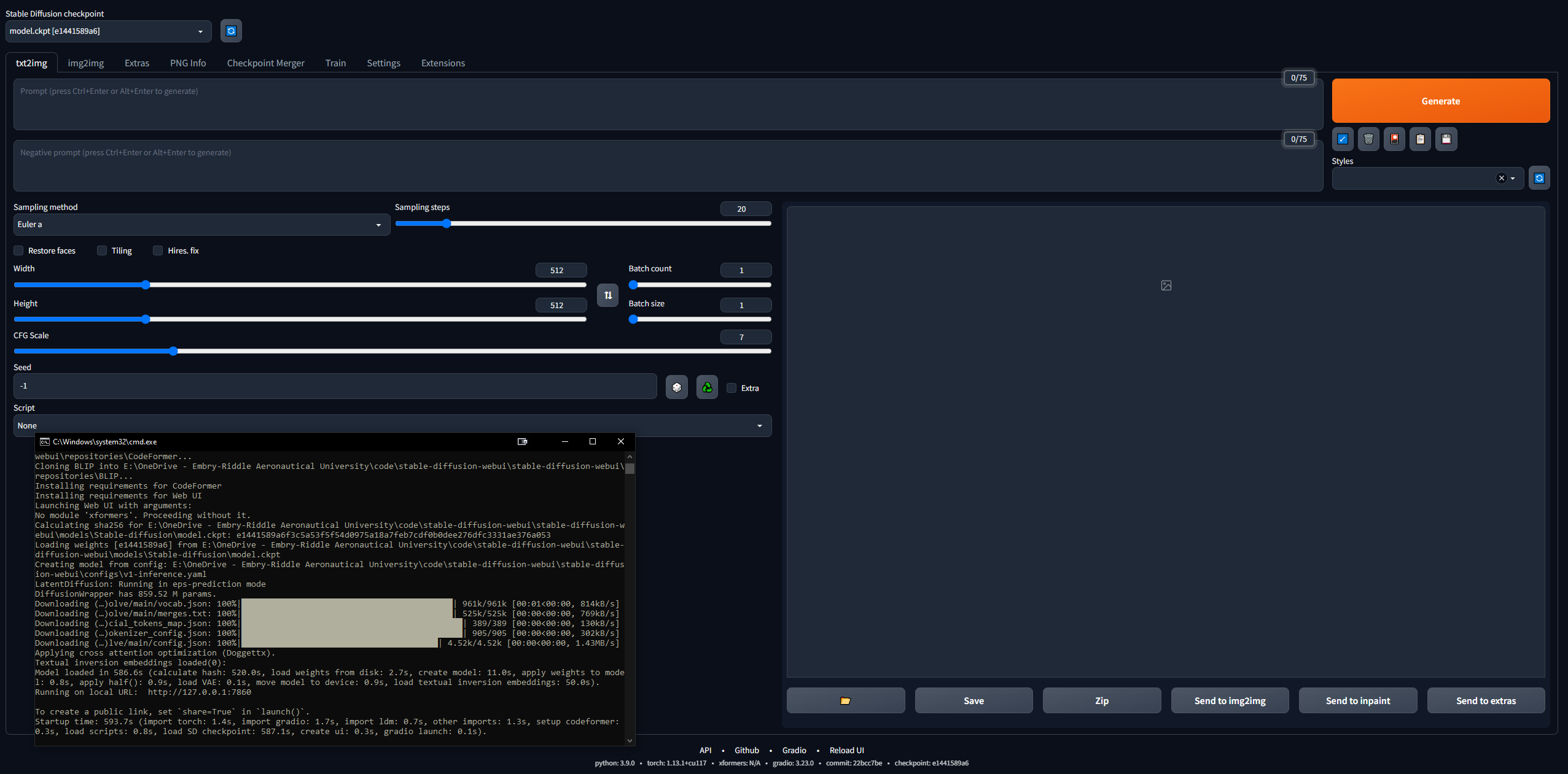
- Vérifiez que la WebUI fonctionne
- Copiez l'URL générée par la CLI une fois terminée, par exemple
127.0.0.1:7860 (n'utilisez PAS Ctrl + C car cette commande peut fermer la CLI) - Collez dans le navigateur et voilà ; essayez une invite et vous partez pour les courses
- Les images seront automatiquement enregistrées une fois générées dans
stable-diffusion-webuioutputstxt2img-images<date>
- N'oubliez pas que pour mettre à jour, ouvrez simplement une CLI dans le dossier stable-diffusion-webui et entrez la commande
git pull
Configuration Linux
Ignorez cela complètement si vous avez Windows. J'ai également réussi à le faire fonctionner sous Linux, même si c'est un peu plus compliqué. J'ai commencé par suivre ce guide, mais il est plutôt mal écrit, voici donc les étapes que j'ai suivies pour le faire fonctionner sous Linux. J'utilisais Linux Mint 20, qui est une distribution Ubuntu 20.
- Commencez par cloner le dépôt webui :
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - Obtenez un modèle SD (par exemple, SD 1.5, comme dans la section précédente)
- Placez le fichier ckpt du modèle dans
stable-diffusion-webui/models/Stable-diffusion - Téléchargez Python (si vous ne l'avez pas déjà) :
sudo apt install python3 python3-pip python3-virtualenv wget git - Et la WebUI est très particulière, nous devons donc installer Conda, un gestionnaire d'environnement virtuel, pour travailler à l'intérieur de :
wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- Créez maintenant l'environnement :
conda create --name sdwebui python=3.10.6 - Activer l'environnement :
conda activate sdwebui - Accédez à votre dossier WebUI et tapez
./webui.sh - Il devrait s'exécuter un peu jusqu'à ce que vous obteniez une erreur indiquant que vous ne pouvez pas accéder à CUDA/votre GPU... c'est bien, car c'est notre prochaine étape
- Commencez par effacer tous les pilotes Nvidia existants :
sudo apt update
sudo apt purge *nvidia*
- Maintenant, en suivant en quelque sorte quelques extraits de ce guide, découvrez le GPU de votre machine Linux (le moyen le plus simple de le faire est d'ouvrir l'application Driver Manager et votre GPU sera répertorié ; mais il existe une douzaine de façons, il suffit de le rechercher sur Google)
- Allez sur cette page et cliquez sur "Latest New Feature Branch" sous Linux x86_64 (pour moi, c'était 530.xx.xx)
- Cliquez sur l'onglet « Produits pris en charge » et Ctrl + F pour trouver votre GPU ; s'il est répertorié, continuez, sinon revenez en arrière et essayez « Dernière version de la branche de production » ; notez le numéro, par exemple 530
- Dans un terminal, tapez :
sudo add-apt-repository ppa:graphics-drivers/ppa - Mettre à jour avec
sudo apt-get update - Lancez l'application Driver Manager et vous devriez en voir une liste ; ne sélectionnez PAS celui recommandé (par exemple, nvidia-driver-530-open), sélectionnez celui exact précédemment (par exemple, nvidia-driver-530) et appliquez les modifications ; OU, installez-le dans le terminal avec
sudo apt-get install nvidia-driver-530 - À CE POINT, vous devriez obtenir une fenêtre contextuelle via votre CLI à propos du démarrage sécurisé, vous demandant un mot de passe à 8 chiffres : définissez-le et notez-le.
- Redémarrez votre PC et avant votre cryptage/connexion utilisateur, vous devriez voir un écran de type BIOS (j'écris ceci de mémoire) avec une option pour saisir une clé MOK ; cliquez dessus et entrez votre mot de passe, puis soumettez et démarrez ; quelques infos ici
- Connectez-vous comme d'habitude et tapez la commande
nvidia-smi ; en cas de succès, il devrait imprimer un tableau ; sinon, il dira quelque chose comme "Impossible de se connecter au GPU ; veuillez vous assurer que le pilote le plus récent est installé". - Maintenant, installez CUDA (la dernière commande ici devrait imprimer des informations sur votre nouvelle installation CUDA) ; de ce guide :
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
- Revenez maintenant en arrière et effectuez les étapes 7 à 9 ; si vous obtenez cette "ERREUR : impossible d'activer python venv, abandon en cours...", passez à l'étape suivante (sinon, vous partez pour les courses et copierez l'adresse IP de la CLI comme d'habitude et pourrez commencer à jouer avec SD)
- Ce problème Github a un dépannage pour ce problème venv... pour moi, ce qui a fonctionné était en cours d'exécution
python3 -c 'import venv'
python3 -m venv venv/
Et puis allez dans le dossier /stable-diffusion-webui et exécutez :
rm -rf venv/
python3 -m venv venv/
Après cela, cela a fonctionné pour moi.
Aller plus loin
- Renseignez-vous sur les techniques d'incitation, car il y a beaucoup de choses à savoir (par exemple, invite positive ou invite négative, étapes d'échantillonnage, méthode d'échantillonnage, etc.)
- Guide du manuel d'invites OpenArt
- Guide d'invite SD définitif
- Un guide d'incitation succinct
- Conseils d'invite 4chan (NSFW)
- Collection d'invites et d'images
- Guide d'invite étape par étape pour Anime Girl
- Renseignez-vous sur les connaissances SD en général :
- Publication sur la diffusion stable séminale
- CompVis / Stability AI Github (accueil des modèles SD originaux)
- Compendium de diffusion stable (bonne ressource extérieure)
- Hub de liens de diffusion stables (incroyable ressource 4chan)
- Mine d'or à diffusion stable
- SD Goldmine simplifiée
- Aléatoire/Divers. Liens SD
- FAQ (NSFW)
- Une autre FAQ
- Rejoignez le Discord de diffusion stable
- Tenez-vous au courant de l’actualité de Stable Diffsion
- Saviez-vous qu'à partir de mars 2023, un modèle de diffusion texte vers vidéo de 1,7 milliard de paramètres est disponible ?
- Jouez dans le WebUI, jouez avec différents modèles, paramètres, etc.
Invite
L'ordre des mots dans une invite a un effet : les mots précédents sont prioritaires. La structure générale d'une bonne invite, à partir d'ici :
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
Et un autre bon guide dit que l'invite doit suivre cette structure :
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
Un article fondateur sur les modèles txt2img d'ingénierie rapide, ici. La ressource définitive sur les invites LLM, ici.
Quoi que vous demandiez, essayez de suivre une sorte de structure afin que votre processus soit reproductible. Vous trouverez ci-dessous les éléments de syntaxe d'invite nécessaires :
- () = modificateur x1,05
- [] = modificateur /1,05
- (mot : 1,05) == (mot)
- (mot:1.1025) == ((mot))
- (mot : .952) == [mot]
- (mot : .907) == [[mot]]
- Le mot-clé AND vous permet d'inviter deux invites distinctes à la fois pour les fusionner ; bien pour que les choses ne s'écrasent pas dans un espace latent
- Par exemple,
1girl standing on grass in front of castle AND castle in background
Modèle NovelAI
Le modèle par défaut est plutôt soigné mais, comme c’est généralement le cas dans l’histoire, le sexe détermine la plupart des choses. NovelAI (NAI) était un service de génération de contenu SD axé sur l'anime et son modèle principal a été divulgué. La plupart des images générées par SD d'hommes et de femmes d'anime que vous voyez (NSFW ou non) proviennent de ce modèle divulgué.
Dans tous les cas, il est vraiment très efficace pour générer des personnes et la plupart des modèles ou LoRA avec lesquels vous jouerez en fusion sont compatibles avec lui car ils sont formés sur des images d'anime. En outre, les humains présentent un très bon cas d’utilisation de départ pour affiner exactement les LoRA que vous souhaitez utiliser à des fins professionnelles. Vous aurez beaucoup de problèmes à résoudre et la plupart des guides concernent des images de femmes. Plus tard, nous aborderons les encodeurs automatiques variables (VAE), qui apportent un véritable réalisme au modèle.
- Suivez le guide NovelAI Speedrun
- Vous devrez torrent le modèle divulgué ou le trouver ailleurs
- Une fois que vous avez placé les fichiers dans le dossier WebUI,
stable-diffusion-webuimodelsStable-diffusion et que vous y avez sélectionné le modèle, vous devriez devoir attendre quelques minutes pendant que la CLI charge les poids VAE.- Si vous rencontrez des problèmes ici, copiez le fichier config.yaml du dossier où se trouvait le modèle et suivez le même schéma de dénomination (comme dans ce guide)
- C'est important... Recréez exactement l'image d'Asuka, en vous référant au guide de dépannage si elle ne correspond pas
- Trouver de nouveaux modèles SD et LoRA
- CivitAI
- Visage câlin
- Modèles ODD
- Charge mère du modèle ODD (NSFW)
- Charge mère SDG LoRA (NSFW)
- Beaucoup de modèles populaires (également le guide d'incitation précédent) (NSFW)
LoRA
L'adaptation de bas rang (LoRA) permet un réglage fin pour un modèle donné. Plus d’informations sur les LoRA ici. Dans la WebUI, vous pouvez ajouter des LoRA à un modèle comme la cerise sur un gâteau. Former de nouveaux LoRA est également assez simple. Il existe d'autres moyens de réglage « ancestraux » (par exemple, l'inversion textuelle et les hyperréseaux), mais les LoRA sont à la pointe de la technologie.
- Char ZTZ99A - char militaire LoRA (un char spécifique)
- Avions de chasse - avion de combat LoRA
- epi_noiseoffset - LoRA qui fait ressortir les images et augmente le contraste
J'utiliserai le tank LoRA tout au long du guide. Veuillez noter qu'il ne s'agit pas d'un très bon LoRA, car il est destiné aux images de style anime, mais il est possible de jouer avec.
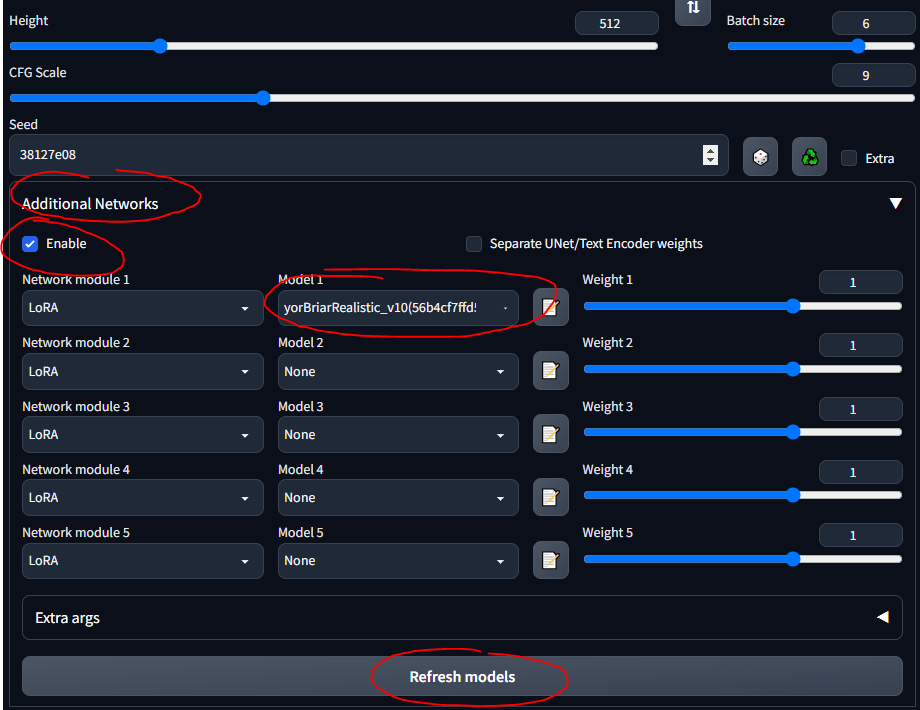
- Suivez ce guide rapide pour installer l'extension
- Vous devriez maintenant voir une section "Réseaux supplémentaires" dans l'interface utilisateur
- Mettez vos LoRA dans
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora - Sélectionnez et partez
- ASSUREZ-VOUS DE VÉRIFIER 'ACTIVER'
- Sachez simplement que tout LoRA que vous téléchargez contient probablement des informations décrivant comment l'utiliser... comme « utiliser le mot-clé tank » ou quelque chose du genre ; assurez-vous que, quel que soit l'endroit où vous le téléchargez (par exemple, CivitAI), vous avez lu sa description
Jouer avec des modèles
S'appuyant sur la section précédente... différents modèles ont des données de formation et des mots-clés de formation différents... donc l'utilisation de balises booru sur certains modèles ne fonctionne pas très bien. Vous trouverez ci-dessous quelques-uns des modèles avec lesquels j'ai joué et leurs "instructions".
SDG Model Motherload, utilisé pour obtenir la plupart des modèles, je résume simplement les instructions ici pour une référence rapide ; la plupart des modèles sont destinés au porno littéral, je me suis concentré sur les plus réalistes. Suivez les liens pour voir des exemples d'invites, des images et des notes détaillées sur l'utilisation de chacun d'eux.
- Modèle SD par défaut (1.5, depuis l'étape de configuration ; vous pouvez jouer avec les versions 2.x de SD mais pour être franc, elles sont nulles)
- Modèle NovelAI (du premier guide)
- Anything v3 - modèle anime à usage général
- Dreamshaper - réalisme, passe-partout
- Délibéré - réalisme, fantaisie, peintures, paysages
- Neverending Dream - réalisme, fantaisie, bon pour les gens et les animaux
- Utilise le système de balises booru
- Epic Diffusion - ultra-réalisme, destiné à remplacer la SD originale
- AbyssOrangeMix (AOM) - anime, réalisme, artistique, peintures, extrêmement courant et bon pour les tests
- Kotosmix - usage général, réalisme, anime, décors, personnages, échantillonneur DPM++ 2M Karras recommandé
CivitAI a été utilisé pour obtenir tous les autres. Vous devez créer un compte, sinon vous ne pourrez pas voir les éléments NSFW, y compris les armes et l'équipement militaire. Sur CivitAI, certains modèles (points de contrôle) incluent des VAE ; s'il l'indique, téléchargez-le également et placez-le à côté du modèle.
- ChilloutMix - ultra-réalisme, portraits, l'un des plus populaires
- Protogen x3.4 - ultra-réalisme
- Utilisez des mots déclencheurs : style modelshoot, style analogique, style mdjrny-v4, robot nousr
- Onirique Photoreal 2.0 - ultra-réalisme
- Utilisez le mot déclencheur : photoréaliste
- Boîte à outils de SPYBG pour les artistes numériques - réalisme, art conceptuel
- Utilisez des mots déclencheurs : tk-char, tk-env
Les VAE
Les encodeurs automatiques variables rendent les images plus belles, plus nettes et moins éclatées. Certains réparent également les mains et les visages. Mais c'est surtout une question de saturation et d'ombrage. Expliqué ici et ici (NSFW). La VAE NovelAI/Anything est couramment utilisée. Il s'agit essentiellement d'un module complémentaire à votre modèle, tout comme une LoRA.
Retrouvez les VAE sur la Liste des VAE :
- NAI / Anything - pour les modèles animés
- Livré avec le modèle NAI par défaut lorsque vous le placez dans le dossier models
- SD 1.5 - pour des modèles réalistes
- Télécharger une VAE
- Suivez cette section rapide du guide pour configurer les VAE dans la WebUI
- Assurez-vous de les mettre dans
stable-diffusion-webuimodelsVAE
- Jouez à faire des images avec et sans votre VAE, pour voir les différences
Rassemblez tout cela
Voici quelques notes générales et choses utiles que j'ai apprises en cours de route et qui ne correspondent pas nécessairement au flux chronologique de ce guide.
Le processus général de DD
Un bon moyen d'apprendre est de parcourir des images sympas sur CivitAI, AIbooru ou d'autres sites SD (4chan, Reddit, etc.), d'ouvrir ce que vous aimez et de copier les paramètres de génération dans le WebUI. Divulgation complète : recréer exactement une image n’est pas toujours possible, comme décrit ici. Mais vous pouvez généralement vous en rapprocher assez. Pour vraiment jouer, baissez le CFG pour que le modèle puisse devenir plus créatif. Essayez des lots et éloignez-vous de l'ordinateur pour revenir aux lots à parcourir.
Le processus général d’un workflow WebUI est le suivant :
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
- txt2img - invite et obtient des images
- img2img - éditez des images et générez des images similaires
- inpainting - modifier des parties d'images (nous en discuterons plus tard)
- extra - modifications finales de l'image (nous en discuterons plus tard)
Enregistrement des invites
Parfois, vous souhaitez revenir aux invites sans coller d'images ni les écrire à partir de zéro. Vous pouvez enregistrer des invites pour les réutiliser dans WebUI.
- Écrivez une invite positive et/ou négative
- Sous le bouton Générer, cliquez sur le bouton à droite pour enregistrer votre "style"
- Entrez un nom et enregistrez
- Sélectionnez-le à tout moment en cliquant sur la liste déroulante Styles
Paramètres txt2img
Cette section est plus ou moins un résumé des informations de ce guide.
- Plus d'étapes d'échantillonnage signifient généralement plus de précision (sauf pour les échantillonneurs "a", comme Euler a, qui changent de temps en temps)
- Jouez avec cela de temps en temps ; en général, quand on l'allume, ça donne vraiment une belle apparence aux visages
- Haute résolution. le correctif est bon pour les images supérieures à 512x512 ; utile s'il y a plus d'une personne dans une image
- CFG est meilleur aux valeurs moyennes basses, comme 5-10
Régénération d'une image générée précédemment
Travailler à partir d'une image générée en SD qui existe déjà ; peut-être que quelqu'un vous l'a envoyé ou que vous souhaitez en recréer un que vous avez créé :
- Dans la WebUI, accédez à l'onglet Informations PNG
- Faites glisser et déposez l'image qui vous intéresse dans l'interface utilisateur
- Ils sont enregistrés dans
stable-diffusion-webuioutputstxt2img-images<date>
- Voir les paramètres utilisés à droite
- Fonctionne parce que les PNG peuvent stocker des métadonnées
- Vous pouvez l'envoyer directement sur la page txt2img avec le bouton correspondant
- Il faudra peut-être vérifier d'avant en arrière pour s'assurer que le modèle, le VAE et d'autres paramètres se remplissent automatiquement correctement.
Attention, certains sites suppriment les métadonnées PNG lorsque les images sont téléchargées (par exemple, 4chan), alors recherchez les URL vers les images complètes ou utilisez des sites qui conservent les métadonnées SD, comme CivitAI ou AIbooru.
Dépannage des erreurs
J'ai eu quelques erreurs de temps en temps. Erreurs principalement de mémoire insuffisante (VRAM) qui ont été corrigées en abaissant les valeurs de certains paramètres. Parfois, la restauration fait face et embauche. la correction des paramètres peut provoquer cela. Dans le fichier stable-diffusion-webuiwebui-user.bat , sur la ligne set COMMANDLINE_ARGS= , vous pouvez mettre des indicateurs qui corrigent les erreurs courantes.
- Une erreur NaN, quelque chose du genre "un VAE a produit un quelque chose NaN", ajoutez le paramètre
--disable-nan-check - Si jamais vous obtenez des images noires, ajoutez
--no-half - Si vous continuez à manquer de VRAM, ajoutez
--medvram ou pour les ordinateurs pommes de terre, --lowvram - Correction du Codeformer de restauration du visage ici (s'il tombe en panne, essayez d'abord de réinitialiser votre Internet)
- Le chargement lent du modèle (lors du passage à un nouveau) est probablement dû au fait que les fichiers .safetensors se chargent lentement si les éléments ne sont pas configurés correctement. Ce fil en parle.
Un problème très courant provient d’une version incorrecte de Python ou de Torch. Vous obtiendrez des erreurs telles que "Impossible d'installer Torch" ou "Torch ne trouve pas le GPU". La solution la plus simple est la suivante :
- Désinstallez toute version de Python que vous avez mise à jour, car SD WebUI attend la version 3.10.6 (j'ai utilisé la version 3.11.5 et j'ai très bien ignoré l'erreur de démarrage, mais la version 3.10.6 semble fonctionner mieux) (vous pouvez également utiliser un gestionnaire de version si vous je suis assez avancé)
- Installez Python 3.10.6, en veillant à l'ajouter à votre PATH (à la fois votre dossier
Python et les dossiers Python/Scripts ) - Supprimez le dossier
venv dans votre dossier stable-diffusion-webui - Exécutez
stable-diffusion-webuiwebui-user.bat et laissez-le reconstruire correctement le venv - Apprécier
Tous les arguments de ligne de commande peuvent être trouvés ici.
Être à l'aise
Certaines extensions peuvent améliorer l’utilisation de WebUI. Obtenez le lien Github, accédez à l'onglet Extensions, installez à partir de l'URL ; éventuellement, dans l'onglet Extensions, cliquez sur Disponible, puis sur Charger depuis et vous pouvez parcourir les extensions localement, cela reflète le wiki Github des extensions.
- Tag Completer - recommande et complète automatiquement les balises booru au fur et à mesure que vous tapez
- État de l'interface utilisateur Web à diffusion stable : préserve l'état de l'interface utilisateur même après le redémarrage
- Test My Prompt - un script que vous pouvez exécuter pour supprimer des mots individuels de votre invite afin de voir comment cela affecte la génération d'images
- Model-Keyword - remplit automatiquement les mots-clés associés à certains modèles et LoRA, assez bien entretenus et à jour en avril 2023.
- NSFW Checker - masque les images NSFW ; utile si vous travaillez dans un bureau, car de nombreux bons modèles autorisent le contenu NSFW et vous ne voudrez peut-être pas le voir au travail
- ATTENTION : cette extension peut gâcher l'inpainting ou même la génération en noircissant les images NSFW (pas temporellement, elle génère littéralement une image noire à la place), alors assurez-vous de la désactiver si nécessaire
- Gelbooru Prompt - extrait les balises et crée une invite automatique à partir de n'importe quelle image Gelbooru en utilisant son hachage
- booru2prompt - similaire à Gelbooru Prompt mais avec un peu plus de fonctionnalités
- Dynamic Prompting - un langage de modèle pour la génération d'invites qui vous permet d'exécuter des invites aléatoires ou combinatoires pour générer diverses images (utilise des caractères génériques)
- Boîte à outils de modèles - extension populaire qui vous aide à gérer, modifier et créer des modèles
- Model Converter - utile pour convertir des modèles, modifier les précisions, etc., lorsque vous entraînez le vôtre
Essai
Alors maintenant, vous disposez de modèles, de LoRA et d'invites... comment pouvez-vous tester pour voir ce qui fonctionne le mieux ? Sous le volet Réseaux supplémentaires se trouve la liste déroulante Script. Ici, cliquez sur tracé X/Y/Z. Dans le type X, sélectionnez Nom du point de contrôle ; dans les valeurs X, cliquez sur le bouton à droite pour coller tous vos modèles. Dans le type Y, essayez l'échelle VAE, ou peut-être la graine, ou l'échelle CFG. Quel que soit l'attribut que vous choisissez, collez (ou entrez) les valeurs que vous souhaitez représenter graphiquement. Par exemple, si vous avez 5 modèles et 5 VAE, vous créerez une grille de 25 images, en comparant le résultat de chaque modèle avec chaque VAE. Ceci est très polyvalent et peut vous aider à décider quoi utiliser. Attention, si vos axes X ou Y sont des modèles de VAE, il doit charger le modèle ou les poids du VAE pour chaque combinaison, donc cela peut prendre un certain temps.
Une très bonne ressource sur les comparaisons SD peut être trouvée ici (NSFW). Il y a beaucoup de liens à suivre. Vous pouvez commencer à comprendre comment les différents modèles, VAE, LoRA, valeurs de paramètres, etc. affectent la génération d'images.
J'ai adopté une invite de test à partir d'ici et utilisé le tank LoRA pour créer cette grille X/Y. Vous pouvez voir comment les différents modèles et échantillonneurs fonctionnent les uns avec les autres. A partir de ce test, nous pouvons évaluer que :
- Les modèles ChilloutMix, Deliberate, Dreamlike Photoreal et Epic Diffusion semblent produire les images de tank les plus « réalistes »
- Lors de tests indépendants ultérieurs, il a été constaté que le photoréalisme Protogen X34 et la boîte à outils SpyBGs étaient également très bons pour les chars.
- Les échantillonneurs les plus prometteurs ici semblent être DPM++ SDE ou l'un des échantillonneurs Karras.

Les paramètres exacts utilisés (sans compter le modèle ou l'échantillonneur) pour chacune de ces images de réservoir sont donnés ci-dessous (encore une fois, tirés d'ici) :
- Invite positive : char, bf2042, meilleure qualité, chef-d'œuvre, ultra haute résolution (photoréaliste : 1,4), peau détaillée, éclairage cinématographique, cinématique très détaillée, colorée, photographie moderne, un groupe de soldats sur le champ de bataille, explosion du champ de bataille partout, chasseurs à réaction et des hélicoptères volant dans le ciel, deux chars au sol, dans une zone désertique, des bâtiments en feu et un véhicule blindé militaire abandonné en arrière-plan
- Invite négative : nu, (pire qualité : 2), (faible qualité : 2), (qualité normale : 2), faible résolution, mauvaise anatomie, mauvaises mains, qualité normale, ((monochrome)), ((niveaux de gris)), réduit fard à paupières, coups de paupières multiples, cheveux roses, trous sur les seins, ng_deepnegative_v1_75t, nsfw, mamelons, doigts supplémentaires, ((bras supplémentaires)), (jambes supplémentaires), mains mutées, (doigts fusionnés), (trop de doigts), (long cou : 1,3)
- Étapes : 22
- Échelle CFG : 7,5
- Semence : 1656460887
- Taille: 480x480
- Saut de clip : 2
- AddNet activé : True, Module AddNet 1 : LoRA, Modèle AddNet 1 : ztz99ATank_ztz99ATank(82a1a1085b2b), AddNet Weight A 1 : 1, AddNet Weight B 1 : 1
Interface utilisateur Web avancée
Dans cette section se trouvent les choses les plus avancées que vous pouvez faire une fois que vous êtes familiarisé avec l'utilisation des modèles, des LoRA, des VAE, des invites, des paramètres, des scripts et des extensions dans l'onglet txt2image de l'interface Web.
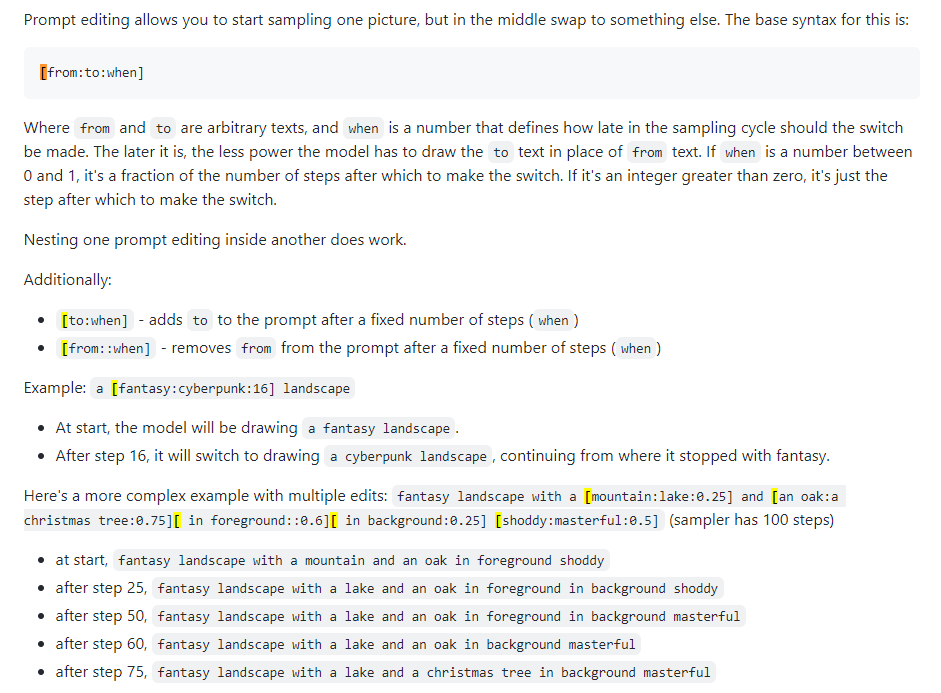
Modification rapide
Également connu sous le nom de mélange rapide. La modification d'invite vous permet de demander au modèle de modifier son invite à des étapes spécifiées. L'image ci-dessous a été tirée d'un article de 4chan et décrit la technique. Par exemple, comme indiqué dans ce guide, l'édition rapide peut être utilisée pour mélanger les visages.
Xformers
Xformers, ou couches d'attention croisée. Un moyen d'accélérer la génération d'images (mesurée en secondes/itération, ou s/it) sur les GPU Nvidia, réduit l'utilisation de la VRAM mais entraîne un non-déterminisme. N’envisagez cela que si vous disposez d’un GPU puissant ; en réalité, vous avez besoin d'un Quadro.
img2img
Pas vraiment beaucoup utilisé, une sorte d’onglet déroutant. Peut être utilisé pour générer des images à partir de croquis, comme dans Huggingface Image to Image SD Playground. Cet onglet comporte un sous-onglet, inpainting, qui fait l'objet de la section suivante et une fonctionnalité très importante du WebUI. Bien que vous puissiez utiliser cette section pour générer des images modifiées à partir de celle que vous avez déjà créée (sortie vers stable-diffusion-webuioutputsimg2img-images ), la fonctionnalité est inégale pour moi... elle semble utiliser une quantité insensée de mémoire et J'arrive à peine à le faire fonctionner. Accédez à la section suivante ci-dessous.
Peinture
C’est là que réside le pouvoir du créateur de contenu ou de toute personne intéressée par la perturbation de l’image. La sortie est dans stable-diffusion-webuioutputsimg2img-images .
- Guide d'inpainting et d'outpainting
- Inpainting 4chan (NSFW)
- Guide d'inpainting définitif
- Prenez une image que vous aimez mais qui n'est pas parfaite, quelque chose ne va pas - elle doit être modifiée
- Ou générez-en un et cliquez sur Envoyer vers inpaint (tous les paramètres se rempliront automatiquement)
- Vous êtes maintenant dans le sous-onglet img2img -> inpaint
- Dessinez (avec votre souris) sur l'image l'endroit exact que vous souhaitez modifier
- Réglez le mode masque sur "inpaint masqué", le contenu masqué sur "original" et la zone d'inpaint sur "uniquement masqué".
- Dans la zone d'invite ci-dessus, écrivez la nouvelle invite pour modifier cet endroit de l'image ; faites une invite négative si vous le souhaitez
- Générez une image (idéalement, faites un lot d'environ 4)
- Quel que soit celui que vous préférez, cliquez sur Envoyer pour inpaint et répétez jusqu'à ce que vous ayez une image terminée.
Peinture
L'outpainting est un processus sémantique assez complexe. L'outpainting vous permet de prendre une image et de l'agrandir autant de fois que vous le souhaitez, en élargissant essentiellement ses frontières. Le processus est décrit ici. Vous agrandissez l'image de seulement 64 pixels à la fois. Il existe deux outils d'interface utilisateur pour cela (que j'ai pu trouver) :
- Alpha Canvas (intégré à WebUI en tant qu'extension/script)
- Hua (application Web pour l'inpainting/outpainting)
Suppléments
Cet onglet WebUI est spécifiquement destiné à la mise à l’échelle. Si vous obtenez une image que vous aimez vraiment, vous pouvez la mettre à l'échelle ici à la fin de votre flux de travail. Les images mises à l'échelle sont stockées dans stable-diffusion-webuioutputsextras-images . Certains des problèmes de mémoire associés à la mise à l'échelle avec des upscalers plus puissants lors de la génération dans l'onglet txt2img (par exemple, ceux 4x+) ne se produisent pas ici car vous ne générez pas de nouvelles images, vous effectuez uniquement une mise à l'échelle des images statiques.
Réseaux de contrôle
La meilleure façon de comprendre ce que fait un ControlNet est de dire "inpainting sous stéroïdes". Vous lui donnez une image d'entrée (générée par SD ou non) et il peut modifier le tout. Les poses sont également possibles avec ControlNets. Vous pouvez donner une pose de référence à une personne et générer des images correspondantes en fonction de votre invite typique. Un bon début pour comprendre ControlNets est ici.
- Installez l'extension ControlNet, sd-webui-controlnet dans le WebUI
- Assurez-vous de recharger l'interface utilisateur en cliquant sur le bouton Recharger l'interface utilisateur dans l'onglet Paramètres.
- Vérifiez que le bouton ControlNet se trouve maintenant dans l'onglet txt2img (et img2img), sous Réseaux supplémentaires (où vous placez vos LoRA).
- Activer plusieurs modèles ControlNet : Paramètres -> ControlNet -> Curseur Mutli ControlNet -> 2+
- Rechargez l'interface utilisateur et dans la zone ControlNet, vous devriez voir plusieurs onglets de modèle
- Vous pouvez combiner des ControlNets (par exemple, Canny et OpenPose) comme si vous utilisiez plusieurs LoRA.
- Obtenez un modèle ControlNet
- Les modèles Canny sont des modèles à détection de contours ; les images sont converties en images avec bords en noir et blanc, où les bords indiquent approximativement à SD à quoi ressemblera votre image
- Les modèles OpenPose prennent une image d'une personne et la convertissent en modèle de pose à utiliser dans des images ultérieures.
- Il existe de nombreux autres modèles qui peuvent également y être étudiés.
- Prenons les modèles Canny et OpenPose
- Mettez-les dans
stable-diffusion-webuiextensionssd-webui-controlnetmodels - Obtenez n'importe quelle image qui vous intéresse ou générez-en une nouvelle ; ici, j'utiliserai cette image de char que j'ai générée plus tôt

- Paramètres dans txt2img : méthode d'échantillonnage "DDIM", pas d'échantillonnage 20, largeur/hauteur identique à votre image sélectionnée
- Paramètres dans l'onglet ControlNet : cochez Activer, Préprocesseur "Canny", Modèle "control_canny-fp16", largeur/hauteur du canevas identique à votre image sélectionnée (tous les autres paramètres par défaut)
- Modifiez vos invites et cliquez sur générer ; J'ai essayé de convertir l'image de mon char en une image sur Mars

- L'invite positive était : une scène sur mars, l'espace, l'espace, l'univers, ((fond d'espace de galaxie)), étoiles, base lunaire, futuriste, fond noir, fond sombre, étoiles dans le ciel, (nuit) sable rouge, ((étoiles dans l'arrière-plan)), tank, bf2042, meilleure qualité, chef-d'œuvre, ultra haute résolution, (photoréaliste : 1,4), peau détaillée, éclairage cinématographique, cinématique très détaillée, colorée, photographie moderne, un groupe de soldats sur le champ de bataille, explosion du champ de bataille partout, chasseurs à réaction et des hélicoptères volant dans le ciel, deux chars au sol, dans une zone désertique, des bâtiments en feu et un véhicule blindé militaire abandonné en arrière-plan, arbre, forêt, ciel
- Allez prendre une image avec des personnes dedans et vous pouvez faire à la fois le modèle Canny dans Control Model - 0 et le modèle OpenPose dans Control Model - 1 pour vraiment vous amuser avec
- Encore une fois, regardez cette vidéo pour vraiment approfondir Canny et OpenPose.
Créer de nouvelles choses
C'est bien beau, mais vous avez parfois besoin de meilleurs modèles ou LoRA pour les cas d'utilisation professionnelle. Étant donné que la plupart du contenu SD est littéralement destiné à générer des femmes ou du porno, des modèles et des LoRA spécifiques peuvent devoir être formés.
- Parcourez tous les sujets d’intérêt ici
- LoRA de formation
- Train LoRA
- Guide de formation paresseux LoRA
- Un bon guide de formation LoRA de CivitAI
- Un autre guide de formation LoRA
- Informations plus générales sur LoRA
- Fusionner des modèles
- Modèles de mixage
Formation de nouveaux modèles
Voir la section sur DreamBooth.
Fusion de points de contrôle
FAIRE
L'onglet de fusion de points de contrôle dans WebUI vous permet de combiner deux modèles ensemble, comme mélanger deux sauces dans une casserole, où le résultat est une nouvelle sauce qui est une combinaison des deux.
LoRA de formation
FAIRE
Entraîner une LoRA n’est pas nécessairement difficile, il s’agit simplement de collecter suffisamment de données.
Configuration de Google Colab
Il s'agit d'une étape importante si vous devez travailler loin de votre plate-forme. Google Colab Pro coûte 10 dollars par mois et vous offre 89 Go de RAM et un accès à de bons GPU, vous pouvez donc techniquement exécuter des invites depuis votre téléphone et les faire fonctionner pour vous sur un serveur à Tombouctou. Si un peu de coût supplémentaire ne vous dérange pas, Google Colab Pro+ coûte 50 dollars par mois et est encore mieux.
- Accédez à ce SD Colab prédéfini
- Vous pouvez le cloner sur votre GDrive ou simplement l'utiliser tel quel afin qu'il soit toujours le plus à jour depuis Github.
- Exécutez les 4 premiers blocs de code (prend un peu)
- Ignorer le bloc de code ControlNet
- Exécutez « Démarrer la diffusion stable » (prend un peu)
- Mettez votre nom d'utilisateur/mot de passe si vous le souhaitez (probablement une bonne idée car Gradio est public)
- Cliquez sur le lien Gradio (« s'exécutant sur une URL publique »)
- Utilisez l'interface Web comme d'habitude
- Envoyez le lien sur votre téléphone et vous pourrez générer des images lors de vos déplacements
- Pour ajouter de nouveaux modèles et LoRA, vous devriez avoir de nouveaux dossiers dans votre Google Drive :
gdrive/MyDrive/sd/stable-diffusion-webui , et à partir de ce dossier de base, vous pouvez utiliser la même structure de dossiers que vous avez utilisée dans le local. Interface utilisateur Web- Effectuez l'installation de l'extension LoRA comme précédemment et la structure des dossiers se remplira automatiquement comme sur le bureau.
- Désormais, chaque fois que vous souhaitez l'utiliser, il vous suffit d'exécuter le bloc de code 'Démarrer la diffusion stable' (aucun autre élément), d'obtenir un lien gradio et le tour est joué.
Google Colab est toujours gratuit et vous pouvez l'utiliser pour toujours, mais cela peut être un peu lent. La mise à niveau vers Colab Pro pour 10 $/mois vous donne plus de puissance. Mais Colab Pro+ pour 50 $/mois est là où le plaisir est vraiment. Pro+ vous permet d'exécuter votre code pendant 24 heures même après avoir fermé l'onglet.
TODO J'obtiens une erreur étrange qui l'interrompt avec mon abonnement Pro lorsque je règle mes paramètres d'exécution -> bloc-notes de type runetime sur la classe GPU Premium et la RAM élevée. C'est parce que xFormers n'a pas été construit avec le support CUDA. Cela pourrait être résolu en utilisant des TPU à la place ou en désactivant les xFormers, mais je n'ai pas la patience pour le moment. Essayez les problèmes du Colab.
À mi-parcours
MJ est vraiment bon pour les artistes. Ce n'est pas du tout aussi extensible ou puissant que SD dans WebUI (NSFW est impossible), mais vous pouvez générer des choses assez impressionnantes. Vous pouvez l'utiliser gratuitement sur MJ Discord (inscrivez-vous sur leur site) pour quelques invites ou payer 8 $/mois pour le forfait de base, après quoi vous pourrez l'utiliser sur votre propre serveur privé. Toutes les commandes Discord peuvent être trouvées ici et ici. La structure d'invite pour MJ est :
/imagine <optional image prompt> <prompt> --parameters
Paramètres MJ
Ce sont pour MJ V4, pour la plupart les mêmes pour MJ 5. Tous les modèles sont décrits ici.
- --ar 1.2-2.1 : format d'image, par défaut 1:1
- --chaos 0-100 : variation, la valeur par défaut est 0
- --pas de plantes : supprime les plantes
- --q 0.0-2.0 : temps de qualité du rendu, la valeur par défaut est 1
- --graine : la graine
- --stop 10-100 : arrêtez le travail à mi-chemin pour générer une image plus floue
- --style 4a/4b/4c : style de MJ 4'
- --stylize 0-1000 : la force avec laquelle l'esthétique de MJ est libre, la valeur par défaut est 100
- --uplight : utilisez un upscaler "léger", l'image est moins détaillée
- --upbeta : utiliser un upscaler bêta, plus proche de l'image originale
- --upanime : upscaler pour les images d'anime
- --niji : modèle alternatif pour les images d'anime
- --hd : utilisez un modèle antérieur qui produit des images plus grandes, idéal pour les abstraits et les paysages
- --test : utilisez le modèle de test spécial MJ
- - TESTP: Utilisez le modèle de test spécial axé sur la photographie MJ
- - Tile: pour MJ 5 uniquement, génère une image répétitive
- Vérificateur d'image incliable
- --v 1/2/3/4/5: Quelle version MJ à utiliser (5 est le meilleur)
Invites avancées MJ
- Vous pouvez injecter une image (ou des images) au début d'une invite pour influencer son style et ses couleurs. Voir ce doc. Téléchargez une image sur votre serveur Discord et cliquez avec le bouton droit pour obtenir le lien.
- Le remixage vous permet de faire des variations d'une image, de modifications de modèles, de sujets ou de médium. Voir ce doc.
- Plus des invites permet à MJ de considérer deux ou plusieurs concepts séparés individuellement. Versions MJ 1-4 et Niji uniquement. Par exemple, "Hot Dog" fera des images de la nourriture, "Hot :: Dog" fera des images d'une canine chaude. Vous pouvez également ajouter des poids aux invites; Par exemple, "Hot :: 2 Dog" fera du feu des images de chiens. MJ 1/2/3 accepte les poids entiers, MJ 4 peut accepter des décimales. Voir ce doc.
- Le mélange vous permet de télécharger 2 à 5 images pour les fusionner dans une nouvelle image. La commande / mélange est décrite ici.
Dreamstudio
FAIRE
DreamStudio (pas Dreambooth) est la plate-forme phare de la Stabilité Ai Company. Leur site est une plate-forme, Dreambooth Studio, à partir duquel vous pouvez générer des images. Il se situe en quelque sorte entre MidJourney et le Webui en termes de fonctionnalité ouverte. Dreambooth Studio semble être construit au sommet de la plate-forme Invoke.ai, que vous pouvez installer et exécuter localement comme le webui.
Horde stable
FAIRE
La Horde stable est un effort communautaire pour rendre la diffusion stable libre pour tout le monde. Il fonctionne essentiellement comme le torrent ou le hachage du bitcoin, où tout le monde contribue une partie de leur puissance GPU pour générer du contenu SD. L'application Horde est accessible ici.
Dreambooth
FAIRE
Dreambooth (pas Dreamstudio) était l'implémentation par Google d'une technique de réglage fin du modèle de diffusion stable. En bref: vous pouvez l'utiliser pour former des modèles avec vos propres photos. Vous pouvez l'utiliser directement à partir d'ici ou d'ici. Il est plus complexe que de simplement télécharger des modèles et de cliquer dans le webui, car vous travaillez pour former et sérialiser un nouveau modèle. Certaines vidéos résument comment le faire:
- Dreambooth Easy Tutorial
- Dreambooth 10 minutes
- Extension webui dreambooth
Et quelques bons guides:
- Reddit Advanced Dreambooth Conseils
- Dreambooth simple
- Dreambooth Dump (beaucoup d'informations, faites défiler les liens)
Un Google Colab pour Dreambooth:
- Thelastben Dreambooth Training Colab (même auteur que le SD Colab décrit dans la configuration de Google Colab)
Il y a aussi un entraîneur modèle appelé EveryDream. Une comparaison complète entre Dreambooth et EveryDream peut être trouvée ici.
Diffusion vidéo
FAIRE
Il est possible en mars 2023 d'utiliser une diffusion stable pour générer des vidéos. Actuellement (avril 2023), la fonctionnalité est plutôt simpliste, car les vidéos sont générées à partir d'images similaires, cadre par image, donnant aux vidéos une sorte de look "flipbook". Il y a deux extensions principales pour le webui que vous pouvez utiliser:
- Animateur - plus facile
- Deforum - plus de fonctionnalités
Dépotoir
Des trucs que je ne connais pas grand-chose mais j'ai besoin de regarder
Il y a un processus que vous pouvez suivre pour obtenir de bons résultats encore et encore ... cela sera affiné au fil du temps.
- FAIRE
- Highres Fix, ici
- augmenter, partout mais ici surtout
Intégration de Chatgpt?
sursaut
dall-e 2
Deforum https://deforum.github.io/


