Tutorbot Spock
1.0.0
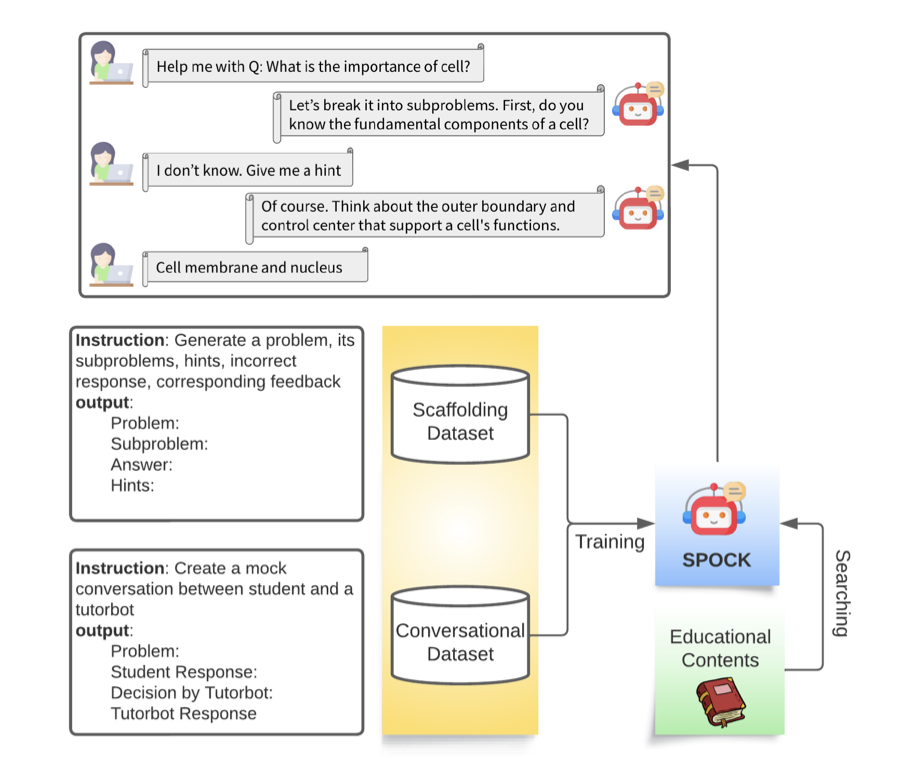
CLASSE : Un cadre de conception pour la création de systèmes de tutorat intelligents basés sur les principes des sciences de l'apprentissage (EMNLP 2023)
Shashank Sonkar, Naiming Liu, Debshila Basu Mallick, Richard G. Baraniuk
Article : https://arxiv.org/abs/2305.13272
Branche : CLASSE
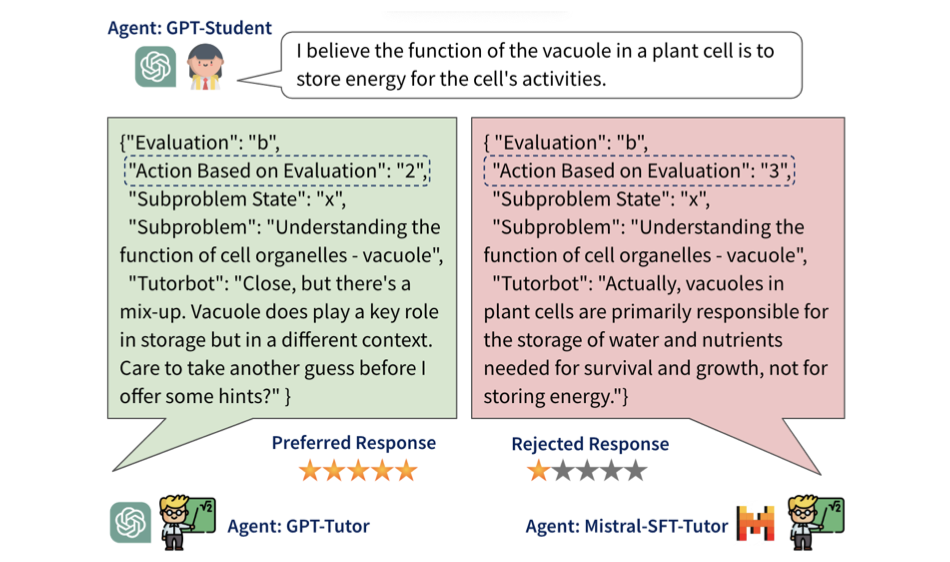
Alignement pédagogique des grands modèles linguistiques (EMNLP 2024)
Shashank Sonkar*, Kangqi Ni*, Sapana Chaudhary, Richard G. Baraniuk
Article : https://arxiv.org/abs/2402.05000
Branche : principale
Ce référentiel vise à développer des agents de tutorat intelligents et efficaces qui aident les étudiants à développer leur pensée critique et leurs compétences en résolution de problèmes.
Veuillez vous référer à scripts/run.sh comme exemple, qui exécute la formation et l'évaluation d'un modèle sélectionné à l'aide de 4 GPU A100. Pour exécuter cet exemple sans formation, téléchargez les modèles de la section ci-dessous et reportez-vous à scripts/run_no-train.sh . Les sous-sections suivantes décomposent scripts/run.sh avec des explications plus détaillées.
La formation et l'évaluation utilisent bio-dataset-1.json, bio-dataset-2.json, bio-dataset-3.json et bio-dataset-ppl.json du dossier datasets. Chacun contient des conversations simulées entre un étudiant et un tuteur basées sur des concepts de biologie générés à partir du GPT-4 d'OpenAI. Ces données sont ensuite prétraitées dans les formats requis pour les ensembles de données de formation et d'évaluation. Veuillez vous référer à la branche CLASS pour obtenir des instructions sur la génération de ces données.
Définissez les paramètres utilisateur :
FULL_MODEL_PATH="meta-llama/Meta-Llama-3.1-8B-Instruct"
MODEL_DIR="models"
DATA_DIR="datasets"
SFT_OPTION="transformers" # choices: ["transformers", "fastchat"]
ALGO="dpo" # choices: ["dpo", "ipo", "kto"]
BETA=0.1 # choices: [0.0 - 1.0]
Données de prétraitement :
python src/preprocess_sft_data.py --data_dir $DATA_DIR
Nous proposons 2 options pour SFT : (1) Transformers (2) FastChat.
(1) Exécutez SFT avec Transformers :
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=20001 src/train/train_sft.py
--model_path $FULL_MODEL_PATH
--train_dataset_path $SFT_DATASET_PATH
--eval_dataset_path ${DATA_DIR}/bio-test.json
--output_dir $SFT_MODEL_PATH
--cache_dir cache
--bf16
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 2
--evaluation_strategy "epoch"
--eval_accumulation_steps 50
--save_strategy "epoch"
--seed 42
--learning_rate 2e-5
--weight_decay 0.05
--warmup_ratio 0.1
--lr_scheduler_type "cosine"
--logging_steps 1
--max_seq_length 4096
--gradient_checkpointing
(2) Exécutez SFT avec FastChat :
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=20001 FastChat/fastchat/train/train.py
--model_name_or_path $FULL_MODEL_PATH
--data_path $SFT_DATASET_PATH
--eval_data_path ${DATA_DIR}/bio-test.json
--output_dir $SFT_MODEL_PATH
--cache_dir cache
--bf16 True
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 2
--evaluation_strategy "epoch"
--eval_accumulation_steps 50
--save_strategy "epoch"
--seed 42
--learning_rate 2e-5
--weight_decay 0.05
--warmup_ratio 0.1
--lr_scheduler_type "cosine"
--logging_steps 1
--tf32 True
--model_max_length 4096
--gradient_checkpointing True
Générez des données de préférence :
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $SFT_MODEL_PATH --output_dir ${SFT_MODEL_PATH}/final_checkpoint-dpo --test_dataset_path $DPO_DATASET_PATH --batch_size 256
python src/preprocess/preprocess_dpo_data.py --response_file ${SFT_MODEL_PATH}/final_checkpoint-dpo/responses.csv --data_file $DPO_PREF_DATASET_PATH
Exécuter l'alignement des préférences :
DPO_MODEL_PATH="${MODEL_DIR}_dpo/${MODEL_NAME}_bio-tutor_${ALGO}"
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --config_file=ds_config/deepspeed_zero3.yaml --num_processes=4 train/train_dpo.py
--train_data $DPO_PREF_DATASET_PATH
--model_path $SFT_MODEL_PATH
--output_dir $DPO_MODEL_PATH
--beta $BETA
--loss $ALGO
--gradient_checkpointing
--bf16
--gradient_accumulation_steps 4
--per_device_train_batch_size 2
--num_train_epochs 3
Évaluez la précision et les scores F1 des modèles SFT et Aligned :
# Generate responses from the SFT model
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $SFT_MODEL_PATH --output_dir ${SFT_MODEL_PATH}/final_checkpoint-eval --test_dataset_path $TEST_DATASET_PATH --batch_size 256
# Generate responses from the Aligned model
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $DPO_MODEL_PATH --output_dir ${DPO_MODEL_PATH}/final_checkpoint-eval --test_dataset_path $TEST_DATASET_PATH --batch_size 256
# Evaluate the SFT model
echo "Metrics of the SFT Model:"
python src/evaluate/evaluate_responses.py --response_file ${SFT_MODEL_PATH}/final_checkpoint-eval/responses.csv
# Evaluate the Aligned model
echo "Metrics of the RL Model:"
python src/evaluate/evaluate_responses.py --response_file ${DPO_MODEL_PATH}/final_checkpoint-eval/responses.csv
Évaluez le personnel des modèles SFT et Aligned :
CUDA_VISIBLE_DEVICES=0,1 python src/evaluate/evaluate_ppl.py --model_path $SFT_MODEL_PATH
CUDA_VISIBLE_DEVICES=0,1 python src/evaluate/evaluate_ppl.py --model_path $DPO_MODEL_PATH
Pour un accès plus facile aux modèles, téléchargez-les depuis Hugging Face.
Modèles SFT :
Modèles alignés :
Si vous trouvez notre travail utile, veuillez citer :
@misc{sonkar2023classdesignframeworkbuilding,
title={CLASS: A Design Framework for building Intelligent Tutoring Systems based on Learning Science principles},
author={Shashank Sonkar and Naiming Liu and Debshila Basu Mallick and Richard G. Baraniuk},
year={2023},
eprint={2305.13272},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2305.13272},
}
@misc{sonkar2024pedagogical,
title={Pedagogical Alignment of Large Language Models},
author={Shashank Sonkar and Kangqi Ni and Sapana Chaudhary and Richard G. Baraniuk},
year={2024},
eprint={2402.05000},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2402.05000},
}


