EasyEdit
1.0.0

Un cadre d'édition de connaissances facile à utiliser pour les grands modèles de langage.
Installation • Démarrage rapide • Document • Document • Démo • Benchmark • Contributeurs • Diapositives • Vidéo • Présenté par AK
2024-10-23, EasyEdit intègre des méthodes de décodage contraintes depuis l'édition de pilotage pour atténuer les hallucinations dans LLM et MLLM, avec des informations détaillées disponibles dans DoLa et DeCo.
2024-09-26, ?? notre article « WISE : Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models » a été accepté par NeurIPS 2024 .
2024-09-20, ?? nos articles : "Mécanismes de connaissances dans les grands modèles de langage : une enquête et une perspective" et "Édition des connaissances conceptuelles pour les grands modèles de langage" ont été acceptés par les résultats de l'EMNLP 2024 .
2024-07-29, EasyEdit a ajouté un nouvel algorithme d'édition de modèle EMMET, qui généralise ROME au paramétrage par lots. Cela permet essentiellement d'effectuer des modifications par lots à l'aide de la fonction de perte ROME.
2024-07-23, nous publions un nouvel article : « Mécanismes de connaissances dans les grands modèles linguistiques : une enquête et une perspective », qui examine la manière dont les connaissances sont acquises, utilisées et évoluent dans les grands modèles linguistiques. Cette enquête peut fournir les mécanismes fondamentaux pour manipuler (éditer) avec précision et efficacité les connaissances dans les LLM.
2024-06-04, ?? EasyEdit Paper a été accepté par le programme de démonstration du système ACL 2024 .
2024-06-03, nous avons publié un article intitulé « WISE : Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models » , ainsi que l'introduction d'une nouvelle tâche d'édition : l'édition continue des connaissances et la méthode d'édition permanente correspondante appelée WISE.
2024-04-24, EasyEdit a annoncé la prise en charge de la méthode ROME pour Llama3-8B . Il est conseillé aux utilisateurs de mettre à jour leur package Transformers vers la version 4.40.0.
2024-03-29, EasyEdit a introduit la prise en charge de la restauration pour GRACE . Pour une introduction détaillée, reportez-vous à la documentation EasyEdit. Les futures mises à jour incluront progressivement la prise en charge de la restauration pour d'autres méthodes.
2024-03-22, un nouvel article intitulé « Détoxifier les grands modèles linguistiques via l'édition de connaissances » a été publié, ainsi qu'un nouvel ensemble de données nommé SafeEdit et une nouvelle méthode de désintoxication appelée DINM.
Le 12/03/2024, un autre article intitulé « Édition des connaissances conceptuelles pour les grands modèles linguistiques » a été publié, introduisant un nouvel ensemble de données nommé ConceptEdit.
01/03/2024, EasyEdit a ajouté la prise en charge d'une nouvelle méthode appelée FT-M . Cette méthode implique la formation d'une couche MLP spécifique en utilisant une perte d'entropie croisée sur la réponse cible et en masquant le texte original . Il surpasse l'implémentation FT-L dans ROME. L'auteur du numéro 173 est remercié pour ses conseils.
2024-02-27, EasyEdit a ajouté la prise en charge d'une nouvelle méthode appelée InstructEdit, avec des détails techniques fournis dans l'article « InstructEdit : Instruction-based Knowledge Editing for Large Language Models » .
Accelerate .Une étude complète de l'édition des connaissances pour les grands modèles de langage [article][benchmark][code]
Tutoriel IJCAI 2024 Google Drive
Tutoriel COLING 2024 Google Drive
Tutoriel AAAI 2024 Google Drive
Tutoriel AACL 2023 [Google Drive] [Baidu Pan]
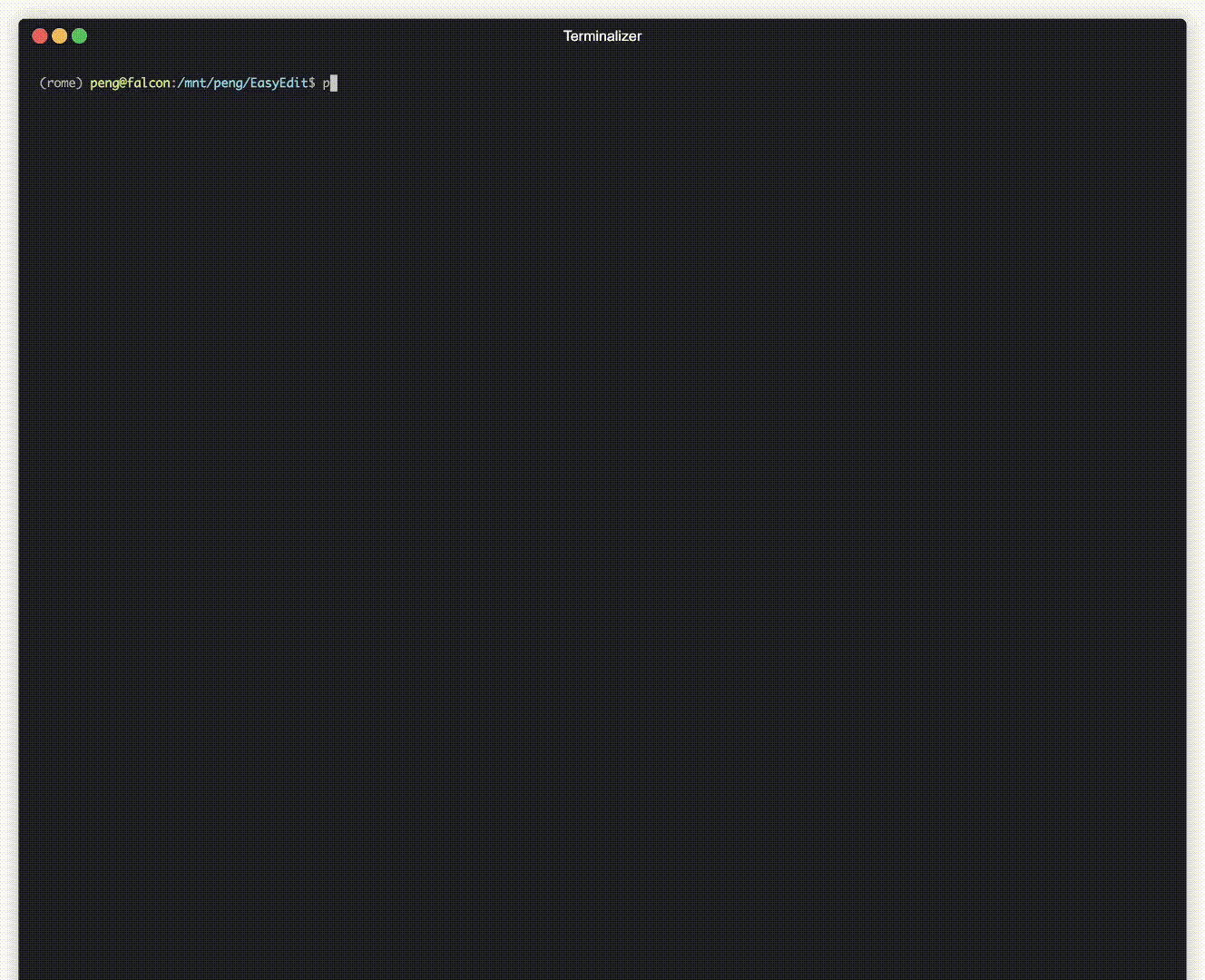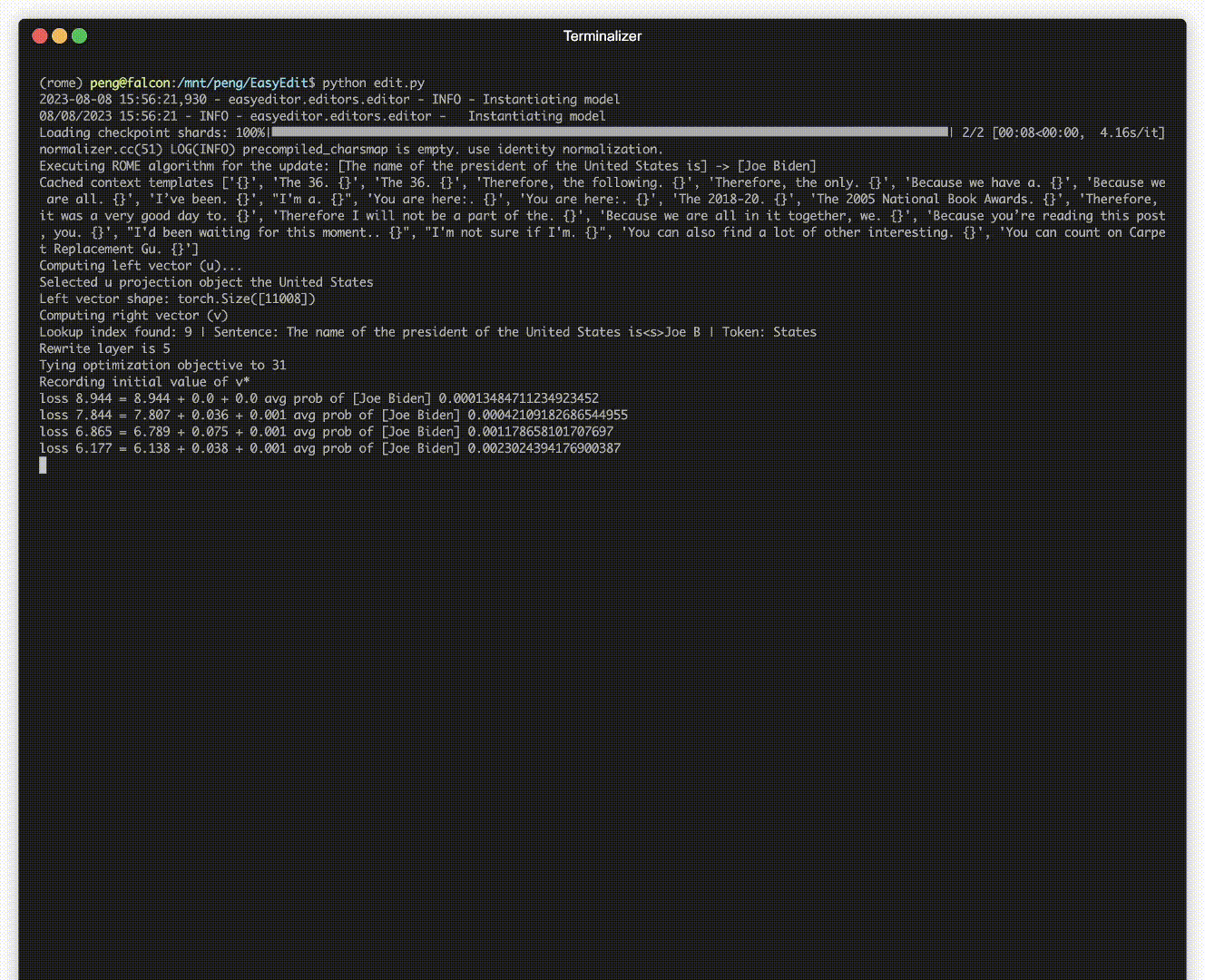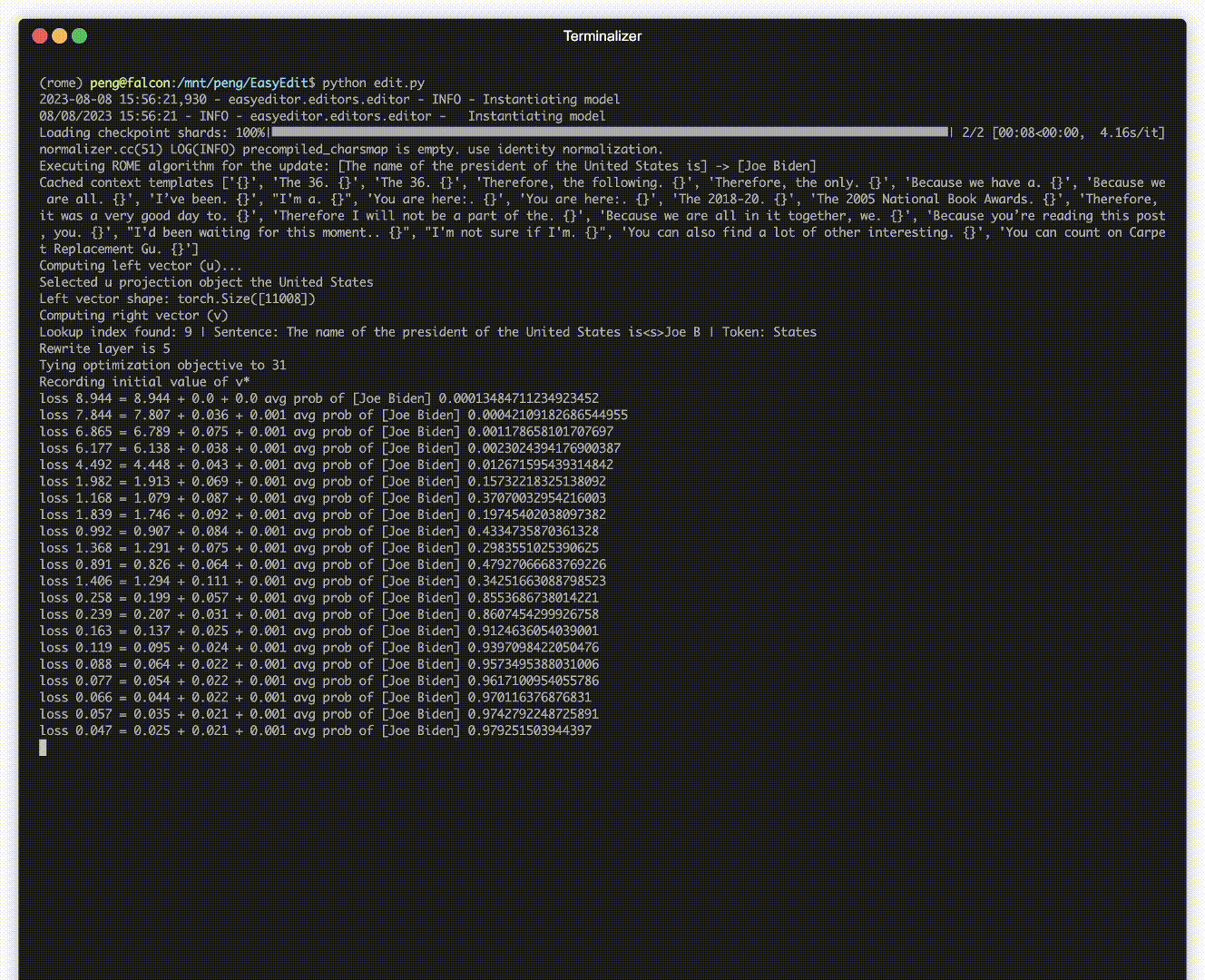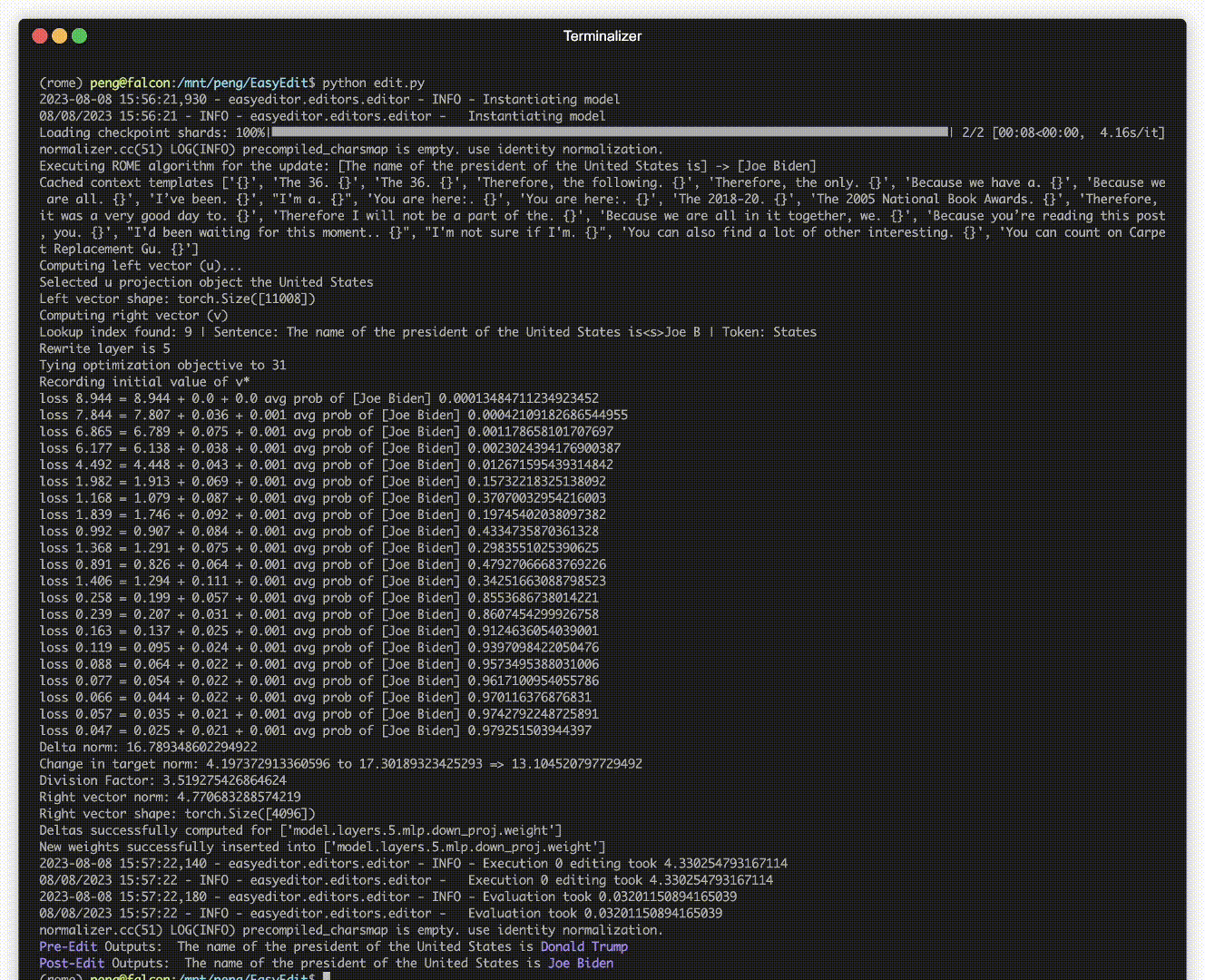
Il y a une démonstration de montage. Le fichier GIF est créé par Terminalizer.
Nous fournissons un bloc-notes Jupyter pratique ! Il vous permet de modifier les connaissances d'un LLM sur le président américain, en passant de Biden à Trump et même de revenir à Biden. Cela inclut des méthodes telles que WISE, AlphaEdit, AdaLoRA et l'édition basée sur des invites.
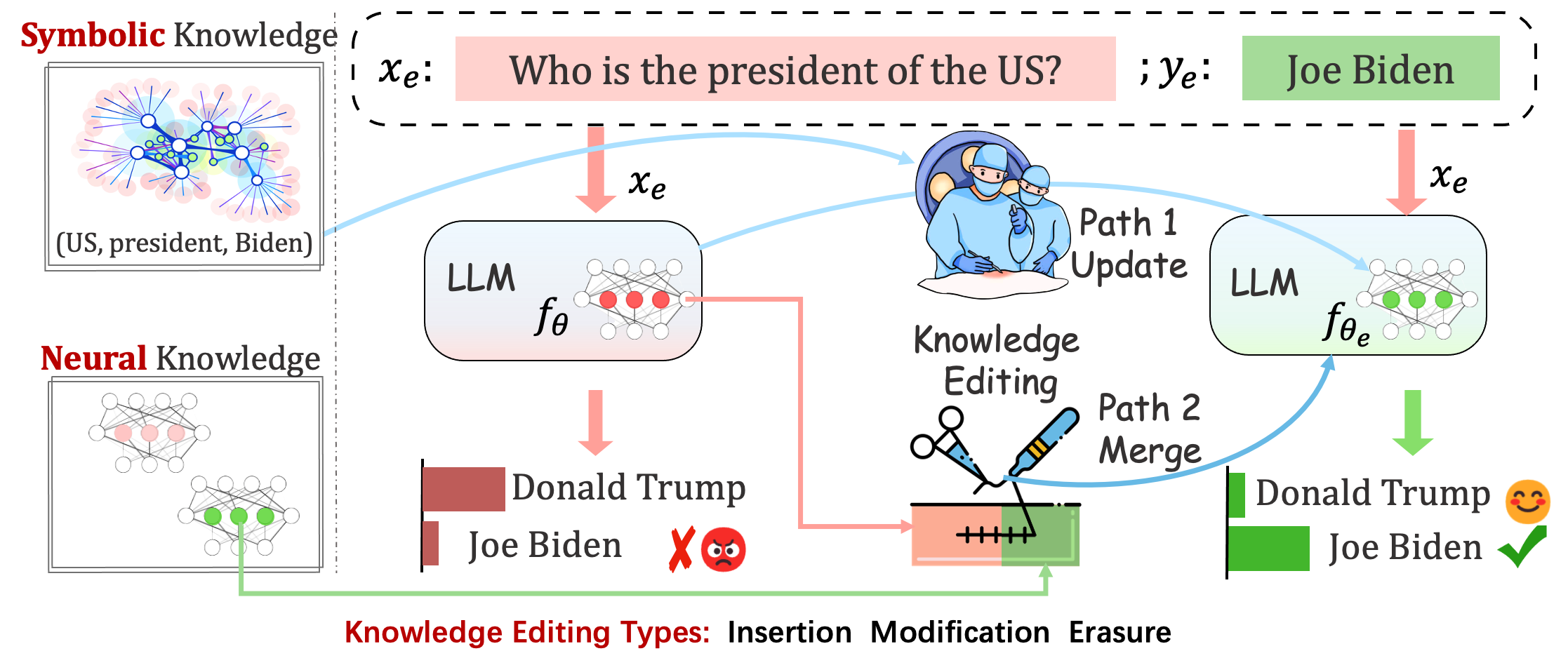
Les modèles déployés peuvent toujours commettre des erreurs imprévisibles. Par exemple, les LLM hallucinent , perpétuent les préjugés et se dégradent factuellement , nous devrions donc être en mesure d'ajuster les comportements spécifiques des modèles pré-entraînés.
L'édition des connaissances vise à ajuster les modèles de base
Évaluation des performances du modèle après une seule modification. Le modèle recharge les poids d'origine (par exemple, LoRA supprime les poids de l'adaptateur) après une seule modification. Vous devez définir sequential_edit=False
Cela nécessite une édition séquentielle et une évaluation est effectuée une fois que toutes les mises à jour des connaissances ont été appliquées :
Il effectue des ajustements de paramètres pour sequential_edit=True : README (pour plus de détails).
Sans influencer le comportement du modèle sur des échantillons non liés, le but ultime est de créer un modèle modifié.
Tâche d'édition pour le sous-titrage d'images et la réponse visuelle aux questions . LISEZMOI
La tâche proposée consiste en une tentative préliminaire de modification de la personnalité des LLM en modifiant leurs opinions sur des sujets spécifiques, étant donné que les opinions d'un individu peuvent refléter certains aspects de ses traits de personnalité. Nous nous appuyons sur la théorie établie du BIG FIVE comme base pour construire notre ensemble de données et évaluer les expressions de personnalité des LLM. LISEZMOI
Évaluation
Basé sur les logits
Basé sur la génération
Pour évaluer Acc et TPEI , vous pouvez télécharger le classificateur formé à partir d'ici.
Le processus d'édition des connaissances a généralement un impact sur les prédictions pour un large ensemble d'entrées étroitement associées à l'exemple d'édition, appelé portée d'édition .
Une modification réussie doit ajuster le comportement du modèle dans la portée de l'édition tout en restant des entrées indépendantes :
Reliability : le taux de réussite de l'édition avec un descripteur d'édition donnéGeneralization : le taux de réussite de l'édition dans le cadre de l'éditionLocality : indique si la sortie du modèle change après la modification pour des entrées non liéesPortability : le taux de réussite de l'édition pour le raisonnement/l'application (one hop, synonyme, généralisation logique)Efficiency : consommation de temps et de mémoire EasyEdit est un package Python pour éditer des modèles de langage étendus (LLM) comme GPT-J , Llama , GPT-NEO , GPT2 , T5 (supporte les modèles de 1B à 65B ), dont l'objectif est de modifier efficacement le comportement des LLM au sein d'un domaine spécifique sans impact négatif sur les performances des autres entrées. Il est conçu pour être facile à utiliser et à étendre.
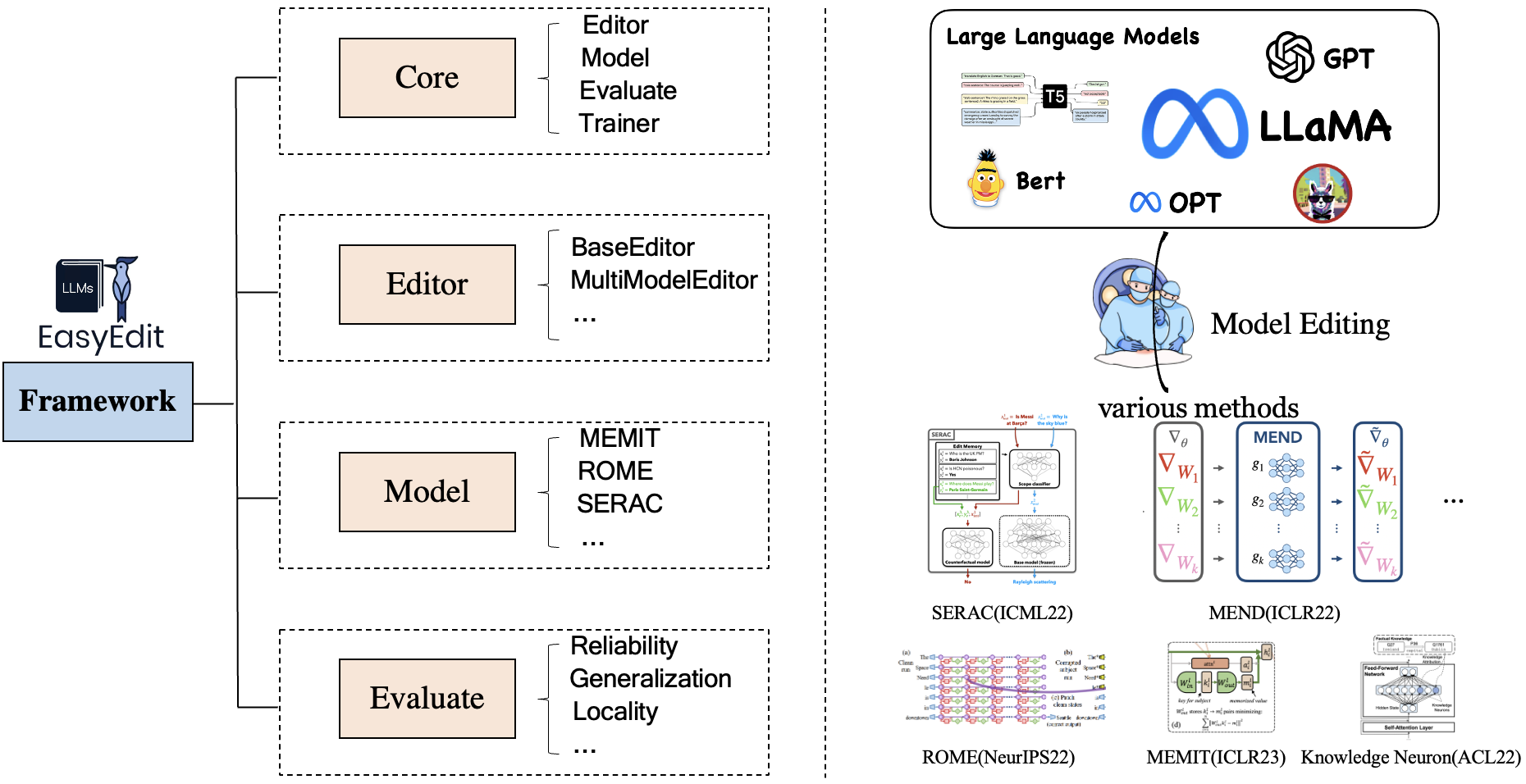
EasyEdit contient un cadre unifié pour Editor , Method et Evaluate , représentant respectivement le scénario d'édition, la technique d'édition et la méthode d'évaluation.
Chaque scénario d'édition de connaissances comprend trois composants :
Editor : tel que BaseEditor( Factual Knowledge and Generation Editor) pour LM, MultiModalEditor( MultiModal Knowledge ).Method : la technique spécifique d'édition des connaissances utilisée (telle que ROME , MEND , ..).Evaluate : mesures permettant d'évaluer les performances d'édition des connaissances.Reliability , Generalization , Locality , PortabilityLes techniques d'édition de connaissances actuellement prises en charge sont les suivantes :
Remarque 1 : En raison de la compatibilité limitée de cette boîte à outils, certaines méthodes d'édition de connaissances, notamment T-Patcher, KE, CaliNet, ne sont pas prises en charge.
Note 2 : De même, la méthode MALMEN n'est que partiellement prise en charge pour les mêmes raisons et continuera d'être améliorée.
Vous pouvez choisir différentes méthodes d'édition en fonction de vos besoins spécifiques.
| Méthode | T5 | GPT-2 | GPT-J | GPT-NEO | Lama | Baichuan | ChatGLM | StagiaireLM | Qwen | Mistral |
|---|---|---|---|---|---|---|---|---|---|---|
| FT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| AdaloRA | ✅ | ✅ | ||||||||
| SÉRAC | ✅ | ✅ | ✅ | ✅ | ||||||
| IKÉ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| RÉPARER | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| KN | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ROME | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| r-ROME | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| MEMIT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| EMMET | ✅ | ✅ | ✅ | |||||||
| GRÂCE | ✅ | ✅ | ✅ | |||||||
| MÉLO | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| Instruire | ✅ | ✅ | ||||||||
| DINM | ✅ | ✅ | ✅ | |||||||
| SAGE | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| Alpha | ✅ | ✅ | ✅ |
❗️❗️ Si vous avez l'intention d'utiliser Mistral, veuillez mettre à jour manuellement la bibliothèque
transformersvers la version 4.34.0. Vous pouvez utiliser le code suivant :pip install transformers==4.34.0.
| Travail | Description | Chemin |
|---|---|---|
| Instruire | InstructEdit : édition de connaissances basée sur des instructions pour les grands modèles de langage | Démarrage rapide |
| DINM | Détoxifier les grands modèles de langage via l'édition des connaissances | Démarrage rapide |
| SAGE | WISE : Repenser la mémoire des connaissances pour l'édition permanente de modèles de langage volumineux | Démarrage rapide |
| Concept | Modification des connaissances conceptuelles pour les grands modèles de langage | Démarrage rapide |
| MM | Pouvons-nous modifier des modèles de langage étendus multimodaux ? | Démarrage rapide |
| Personnalité | Modification de la personnalité pour les grands modèles de langage | Démarrage rapide |
| RAPIDE | Méthodes d'édition de connaissances basées sur PROMPT | Démarrage rapide |
Référence : KnowEdit [Hugging Face][WiseModel][ModelScope]
❗️❗️ À noter, KnowEdit est construit en réorganisant et en étendant les ensembles de données existants, notamment WikiBio , ZsRE , WikiData Counterfact , WikiData recent , convsent , Sanitation pour effectuer une évaluation complète pour l'édition des connaissances. Un merci spécial aux constructeurs et aux responsables de ces ensembles de données.
Veuillez noter que Counterfact et WikiData Counterfact ne sont pas le même ensemble de données.
| Tâche | Insertion des connaissances | Modification des connaissances | Effacement des connaissances | |||
|---|---|---|---|---|---|---|
| Ensembles de données | Wiki récent | ZsRE | WikiBio | Contrefait WikiData | Consentement | Sanitaire |
| Taper | Fait | Réponse aux questions | Hallucination | Contrefait | Sentiment | Informations indésirables |
| # Former | 570 | 10 000 | 592 | 1 455 | 14 390 | 80 |
| # Test | 1 266 | 1301 | 1 392 | 885 | 800 | 80 |
Nous fournissons des scripts détaillés permettant à l'utilisateur d'utiliser facilement KnowEdit, veuillez vous référer aux exemples.
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| ensemble de données | ÉtreindreVisage | Modèle sage | ModèlePortée | Description |
|---|---|---|---|---|
| CConnaître | [Visage câlin] | [Modèle sage] | [ModèlePortée] | ensemble de données pour l'édition des connaissances chinoises |
CKnowEdit est un ensemble de données en langue chinoise de haute qualité pour l'édition de connaissances, fortement caractérisé par la langue chinoise, avec toutes les données provenant de bases de connaissances chinoises. Il est méticuleusement conçu pour discerner plus profondément les nuances et les défis inhérents à la compréhension de la langue chinoise par les LLM actuels, fournissant ainsi une ressource solide pour affiner les connaissances spécifiques au chinois au sein des LLM.
Les descriptions des champs pour les données dans CknowEdit sont les suivantes :
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| ensemble de données | Google Drive | BaiduNetDisk | Description |
|---|---|---|---|
| ZsRE plus | [Google Drive] | [BaiduNetDisk] | Ensemble de données de réponse aux questions utilisant des reformulations de questions |
| Contrefact plus | [Google Drive] | [BaiduNetDisk] | Ensemble de données de contrefact utilisant le remplacement d'entité |
Nous fournissons des ensembles de données zsre et contrefact pour vérifier l'efficacité de l'édition des connaissances. Vous pouvez les télécharger ici. [Google Drive], [BaiduNetDisk].
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse| ensemble de données | Google Drive | Ensemble de données HuggingFace | Description |
|---|---|---|---|
| Concept | [Google Drive] | [Ensemble de données HuggingFace] | ensemble de données pour l'édition des connaissances conceptuelles |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
Paramètres d'évaluation spécifiques au concept
Instance Change : capturer les subtilités de ces changements au niveau de l'instanceConcept Consistency : la similarité sémantique de la définition du concept généré | ensemble de données | Google Drive | BaiduNetDisk | Description |
|---|---|---|---|
| E-IC | [Google Drive] | [BaiduNetDisk] | ensemble de données pour l'édition du sous- titrage d'image |
| E-VQA | [Google Drive] | [BaiduNetDisk] | ensemble de données pour l'édition de la réponse visuelle aux questions |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| ensemble de données | Ensemble de données HuggingFace | Description |
|---|---|---|
| Coffre-fort | [Ensemble de données HuggingFace] | ensemble de données pour les LLM détoxifiants |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
Mesures d’évaluation spécifiques à la détoxification
Defense Duccess (DS) : le taux de réussite de la désintoxication du LLM édité pour une entrée contradictoire (invite d'attaque + question nuisible), qui est utilisé pour modifier le LLM.Defense Generalization (DG) : le taux de réussite de la détoxification du LLM édité pour les entrées malveillantes hors domaine.General Performance : les effets secondaires de l'exécution de tâches sans rapport. | Méthode | Description | GPT-2 | Lama |
|---|---|---|---|
| IKÉ | Apprentissage en contexte (ICL) Modifier | [Colab-gpt2] | [Colab-lama] |
| ROME | Localiser puis modifier les neurones | [Colab-gpt2] | [Colab-lama] |
| MEMIT | Localiser puis modifier les neurones | [Colab-gpt2] | [Colab-lama] |
Remarque : veuillez utiliser Python 3.9+ pour EasyEdit. Pour commencer, installez simplement conda et exécutez :
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txtNos résultats sont tous basés sur la configuration par défaut
| lama-2-7B | chatglm2 | gpt-j-6b | gpt-xl | |
|---|---|---|---|---|
| FT | 60 Go | 58 Go | 55 Go | 7 Go |
| SÉRAC | 42 Go | 32 Go | 31 Go | 10 Go |
| IKÉ | 52 Go | 38 Go | 38 Go | 10 Go |
| RÉPARER | 46 Go | 37 Go | 37 Go | 13 Go |
| KN | 42 Go | 39 Go | 40 Go | 12 Go |
| ROME | 31 Go | 29 Go | 27 Go | 10 Go |
| MEMIT | 33 Go | 31 Go | 31 Go | 11 Go |
| AdaloRA | 29 Go | 24 Go | 25 Go | 8 Go |
| GRÂCE | 27 Go | 23 Go | 6 Go | |
| SAGE | 34 Go | 27 Go | 7 Go |
Modifier de grands modèles de langage (LLM) environ 5 secondes
L'exemple suivant vous montre comment effectuer l'édition avec EasyEdit. Plus d'exemples et de tutoriels peuvent être trouvés dans Exemples
BaseEditorest la classe d'édition des connaissances sur les modalités linguistiques. Vous pouvez choisir la méthode d'édition appropriée en fonction de vos besoins spécifiques.
Grâce à la modularité et à la flexibilité d' EasyEdit , vous pouvez facilement l'utiliser pour éditer un modèle.
Étape 1 : Définissez un PLM comme objet à modifier. Choisissez le PLM à modifier. EasyEdit prend en charge les modèles partiels ( T5 , GPTJ , GPT-NEO , LlaMA jusqu'à présent) récupérables sur HuggingFace. Le répertoire du fichier de configuration correspondant est hparams/YUOR_METHOD/YOUR_MODEL.YAML , tel que hparams/MEND/gpt2-xl.yaml , définissez le model_name correspondant pour sélectionner l'objet pour l'édition des connaissances.
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingÉtape 2 : Choisissez la méthode d'édition des connaissances appropriée
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )Étape 3 : Fournissez le descripteur de modification et la cible de modification
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ] Étape 4 : Combinez-les dans un BaseEditor EasyEdit fournit un moyen simple et unifié d'initialiser Editor , comme huggingface: from_hparams .
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )Étape 5 : Fournissez les données pour l'évaluation Notez que les données de portabilité et de localité sont toutes deux facultatives (définies sur Aucune pour l'évaluation de base du taux de réussite de l'édition uniquement). Le format de données pour les deux est un dict , pour chaque dimension de mesure, vous devez fournir l'invite correspondante et la vérité terrain correspondante. Voici un exemple des données :
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}Dans l'exemple ci-dessus, nous évaluons les performances des méthodes d'édition sur « quartier » et « distrayant ».
Étape 6 : Modification et évaluation terminées ! Nous pouvons effectuer des modifications et des évaluations pour que votre modèle soit modifié. La fonction edit renverra une série de métriques liées au processus d'édition ainsi que les poids du modèle modifiés. [ sequential_edit=True pour une édition continue]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelLa longueur d'entrée maximale pour EasyEdit est de 512. Si cette longueur est dépassée, vous rencontrerez l'erreur « Erreur CUDA : assertion côté appareil déclenchée ». Vous pouvez modifier la longueur maximale dans le fichier suivant : LIEN
Étape 7 : Restaurer En édition séquentielle, si vous n'êtes pas satisfait du résultat de l'une de vos modifications et que vous ne souhaitez pas perdre vos modifications précédentes, vous pouvez utiliser la fonction de restauration pour annuler votre modification précédente. Actuellement, nous ne prenons en charge que la méthode GRACE. Tout ce que vous avez à faire est d'écrire une seule ligne de code, en utilisant la touche edit_key pour annuler votre modification.
editor.rolllback('edit_key')
Dans EasyEdit, nous utilisons par défaut target_new comme edit_key
Nous spécifions les métriques de retour au format dict , y compris les évaluations de prédiction du modèle avant et après l'édition. Pour chaque modification, elle inclura les métriques suivantes :
rewrite_acc rephrase_acc locality portablility 

