CDial GPT
1.0.0
Ce projet fournit un ensemble de données de conversation chinoise à grande échelle et un modèle de pré-entraînement à la conversation chinoise (modèle GPT chinois) sur cet ensemble de données. Pour plus d'informations, veuillez vous référer à notre article.
Le code de ce projet est modifié à partir de TransferTransfo et utilise la version HuggingFace Pytorch de la bibliothèque Transformers, qui peut être utilisée pour la pré-formation et le réglage fin.
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" L'ensemble de données LCCC (Conversation chinoise nettoyée à grande échelle) que nous fournissons se compose principalement de deux parties : LCCC-base (Baidu Netdisk, Google Drive) et LCCC-large (Baidu Netdisk, Google Drive). Nous avons conçu un processus de filtrage de données strict. assurer la qualité des données de conversation dans cet ensemble de données. Ce processus de filtrage des données comprend une série de règles manuelles et plusieurs classificateurs basés sur des algorithmes d'apprentissage automatique. Le bruit que nous filtrons comprend : les mots grossiers, les caractères spéciaux, les expressions faciales, les phrases grammaticales, les dialogues non pertinents, etc.
Les statistiques de cet ensemble de données sont présentées dans le tableau ci-dessous. Parmi eux, nous appelons le dialogue contenant seulement deux phrases un « dialogue à un seul tour », et nous appelons le dialogue contenant plus de deux phrases un « dialogue à plusieurs tours ». Utilisez la segmentation des mots Jieba pour compter la taille de la liste de mots.
| Base LCCC (Disque Cloud Baidu, Google Drive) | conversation à un tour | Plusieurs cycles de dialogue |
|---|---|---|
| le dialogue total tourne | 3 354 232 | 3 466 274 |
| Total des phrases de dialogue | 6 708 464 | 13 365 256 |
| Nombre total de caractères | 68 559 367 | 163 690 569 |
| Taille du vocabulaire | 372 063 | 666 931 |
| Nombre moyen de mots dans les phrases conversationnelles | 6,79 | 8.32 |
| Nombre moyen de phrases par cycle de conversation | 2 | 3,86 |
Notez que le processus de nettoyage de l'ensemble de données de base LCCC est plus strict que celui de LCCC-large, sa taille est donc également plus petite.
| LCCC-grand (Disque Cloud Baidu, Google Drive) | conversation à un tour | Plusieurs cycles de dialogue |
|---|---|---|
| le dialogue total tourne | 7 273 804 | 4 733 955 |
| Total des phrases de dialogue | 14 547 608 | 18 341 167 |
| Nombre total de caractères | 162 301 556 | 217 776 649 |
| Taille du vocabulaire | 662 514 | 690 027 |
| Nombre de mots d'évaluation pour les phrases conversationnelles | 7h45 | 8.14 |
| Nombre moyen de phrases par cycle de conversation | 2 | 3,87 |
Les données de conversation originales de l'ensemble de données de la base LCCC proviennent de conversations Weibo, et les données de conversation originales du grand ensemble de données LCCC sont intégrées à d'autres ensembles de données de conversation open source basés sur ces conversations Weibo :
| Ensemble de données | le dialogue total tourne | Exemple de conversation |
|---|---|---|
| Corpus Weibo | 79M | Q : J'ai mangé du hot pot sept ou huit fois à Chengdu, Chongqing. R : Hahahaha ! Alors ma bouche pourrait pourrir ! |
| Corpus de potins des PTT | 0,4M | Q : Pourquoi les villageois intimident-ils toujours les élèves du secondaire ? QQ R : Si vous pensez que si vous choisissez une bonne matière, vous deviendrez Bill Gates, alors autant abandonner l'école. |
| Corpus de sous-titres | 2,74 millions | Q : Les gens de l'Opéra de Pékin ne sont pas libres. R : Ils mettent les gens en cage. |
| Corpus Xiaohuangji | 0,45M | Q : Avez-vous déjà été amoureux ? A : Avez-vous déjà été amoureux ? Oh, n'en parlez pas, je suis triste... |
| Corpus Tieba | 2,32 millions | Q : Au premier rang, tous les fans de Lu se lèvent, n'est-ce pas ? R : Le titre parle de passes décisives, mais après avoir regardé ce ballon, c'est vraiment une ironie vivante. |
| Corpus Qingyun | 0,1M | Q : Il semble que vous aimez beaucoup l’argent. A : Oh, vraiment ? Alors tu y es presque |
| Corpus de conversations Douban | 0,5M | Q : Apprenez l'anglais pur en regardant des films originaux en anglais A : J'adore Friends et je l'ai regardé plusieurs fois Q : Je suis presque épuisé en regardant le même CD A : Alors votre anglais devrait être plutôt bon maintenant |
| Corpus de conversations e-commerciales | 0,5M | Q : Est-ce que ce sera une bonne affaire ? R : Pas encore Q : Sera-t-il disponible à l'avenir ? |
| Corpus de discussion chinois | 0,5M | Q : Mes jambes sont inutiles aujourd'hui. Vous fêtez les vacances, alors je vais déplacer des briques. A : C'est un travail difficile, je suis même allé gagner beaucoup d'argent à Noël. Allez. Je suis une personne sans petit ami. C'est la même chose pour toutes les vacances. |
Nous proposons également une série de modèles de pré-formation chinois (modèles GPT chinois). Le processus de pré-formation de ces modèles est divisé en deux étapes, d'abord une pré-formation sur de nouvelles données chinoises, puis une pré-formation sur les données LCCC. ensemble.
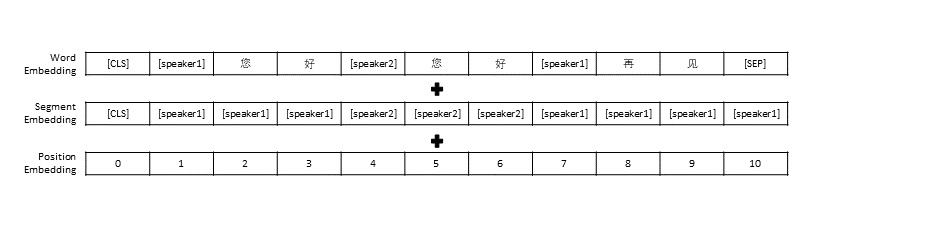
Nous avons suivi les paramètres de prétraitement des données dans TransferTransfo, qui ont regroupé tout l'historique de la conversation en une seule phrase, puis avons utilisé cette phrase comme entrée du modèle pour prédire la réponse de la conversation. En plus de la représentation vectorielle de chaque mot, l'entrée de notre modèle comprend également la représentation vectorielle du locuteur et la représentation vectorielle de la position.
| Modèle pré-entraîné | Nombre de paramètres | Données utilisées pour la pré-formation | décrire |
|---|---|---|---|
| Roman GPT | 95,5 millions | Données sur les romans chinois | Modèle GPT chinois pré-entraîné construit sur la base de nouvelles données chinoises (les nouvelles données comprennent un total de 1,3 milliard de mots) |
| Base CDial-GPT LCCC | 95,5 millions | Base LCCC | Basé sur GPT Novel , utilisez le modèle GPT chinois pré-entraîné formé par la base LCCC |
| Base CDial-GPT2 LCCC | 95,5 millions | Base LCCC | Basé sur GPT Novel , utilisez le modèle chinois GPT2 pré-entraîné formé avec la base LCCC |
| CDial-GPT LCCC-large | 95,5 millions | LCCC-grand | Basé sur GPT Novel , utilisez le modèle GPT chinois pré-entraîné formé par LCCC-large |
Installez directement à partir des sources :
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Étape 1 : Préparez l'ensemble de données requis pour le modèle de pré-entraînement et le réglage fin (tel que l'ensemble de données STC ou les données de jouets "data/toy_data.json" dans le répertoire du projet. Veuillez noter que si les données contiennent de l'anglais, elles doivent être séparées. par des lettres, telles que : bonjour)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps : Vous pouvez utiliser les liens suivants pour télécharger l'ensemble de formation et l'ensemble de vérification de STC (Baidu Cloud Disk, Google Drive)
Étape 2 : entraîner le modèle
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
ou
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
Le paramètre train_path est également fourni dans notre script de formation, qui permet aux utilisateurs de lire des fichiers texte brut par tranches. Si vous utilisez un système avec une mémoire limitée, envisagez d'utiliser ce paramètre pour lire les données d'entraînement. Si vous utilisez train_path vous devez laisser data_path vide.
Étape 3 : générer du texte
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
ps : Vous pouvez utiliser le lien suivant pour télécharger l'ensemble de tests STC (Baidu Cloud Disk, Google Drive)
Paramètres du script de formation
| paramètre | taper | valeur par défaut | décrire |
|---|---|---|---|
| modèle_checkpoint | str | "" | Chemin ou URL des fichiers de modèle (répertoire du modèle de pré-formation et des fichiers de configuration/vocab) |
| pré-entraîné | bouffon | FAUX | Si faux, entraînez le modèle à partir de zéro |
| chemin_données | str | "" | Chemin de l'ensemble de données |
| jeu de données_cache | str | par défaut="dataset_cache" | Chemin ou URL du cache de l'ensemble de données |
| chemin_train | str | "" | Chemin de l'ensemble de formation pour l'ensemble de données distribué |
| chemin_valide | str | "" | Chemin de l'ensemble de validation pour l'ensemble de données distribué |
| fichier_journal | str | "" | Exporter les journaux dans un fichier sous ce chemin |
| num_workers | int | 1 | Nombre de sous-processus pour le chargement des données |
| n_époques | int | 70 | Nombre d'époques de formation |
| train_batch_size | int | 8 | Taille du lot pour la formation |
| valid_batch_size | int | 8 | Taille du lot pour validation |
| max_historique | int | 15 | Nombre d'échanges précédents à conserver dans l'historique |
| planificateur | str | "noam" | Méthode d'optimisation |
| n_emd | int | 768 | Nombre de n_emd dans le fichier de configuration (pour noam) |
| eval_before_start | bouffon | FAUX | Si c'est vrai, commencez l'évaluation avant la formation |
| étapes_échauffement | int | 5000 | Étapes d'échauffement |
| étapes_valides | int | 0 | Effectuer la validation toutes les X étapes, si ce n'est pas 0 |
| gradient_accumulation_steps | int | 64 | Accumuler les dégradés sur plusieurs marches |
| max_norme | flotter | 1.0 | Norme de dégradé de détourage |
| appareil | str | "cuda" si torch.cuda.is_available() sinon "cpu" | Appareil (cuda ou processeur) |
| fp16 | str | "" | Réglé sur O0, O1, O2 ou O3 pour la formation fp16 (voir la documentation apex) |
| local_rank | int | -1 | Rang local pour les formations distribuées (-1 : non distribué) |
Nous avons évalué le modèle de pré-formation au dialogue affiné à l'aide de l'ensemble de données STC (ensemble de formation/ensemble de validation (Baidu Netdisk, Google Drive), ensemble de test (Baidu Netdisk, Google Drive)). Toutes les réponses ont été échantillonnées à l'aide du Nucleus Sampling (p = 0,9, température = 0,7).
| Modèle | Taille du modèle | PPL | BLEU-2 | BLEU-4 | Dist-1 | Dist-2 | Correspondance gourmande | Moyenne d'intégration |
|---|---|---|---|---|---|---|---|---|
| Attention-Seq2seq | 73M | 34.20 | 3,93 | 0,90 | 8.5 | 11.91 | 65,84 | 83.38 |
| Transformateur | 113M | 22h10 | 6,72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| Discussion GPT2 | 88M | - | 2.28 | 0,54 | 10.3 | 16h25 | 61,54 | 78,94 |
| Roman GPT | 95,5 millions | 21.27 | 5,96 | 2,71 | 8.0 | 11.72 | 66.12 | 83.34 |
| Base GPT LCCC | 95,5 millions | 18h38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| Base GPT2 LCCC | 95,5 millions | 22.76 | 5,69 | 2,50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-grand | 95,5 millions | 18.23 | 6,63 | 3.20 | 8.3 | 12.71 | 66.25 | 83,63 |
Nous avons échantillonné 200 réponses pour chaque modèle et invité 3 annotateurs sur la plateforme d'externalisation à évaluer manuellement ces réponses. Les dimensions d'évaluation étaient la fluidité conversationnelle, la pertinence contextuelle et la diversité des réponses. La plage de notation pour chaque dimension est de 2/1/0. Veuillez vous référer à notre article pour plus de détails.
| Modèle | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attention-Seq2Seq | 27,1% | 21,4% | 51,4% | 0,4544 |
| Transformateur | 42,4% | 23,6% | 34,0% | 0,4429 |
| Discussion GPT2 | 24,3% | 19,1% | 56,6% | 0,3941 |
| Base GPT LCCC | 46,7% | 21,8% | 31,5% | 0,3954 |
| GPT LCCC-grand | 48,6% | 24,5% | 27,0% | 0,4203 |
Nous avons échantillonné au hasard 1 000 réponses de conversation et compté les mauvaises réponses parmi ces réponses :
| Contient des déclarations répétées | Contient des mots maudits | Autres mauvaises réponses |
|---|---|---|
| vingt-trois | 9 | 2 |
Nous avons affiné les paramètres du modèle GPT LCCC-large sur l'ensemble de données STC et utilisé ce modèle affiné pour générer l'exemple de conversation suivant :
| Poste | Réponse |
|---|---|
| Il s’agit en réalité de Pékin, pas de Harbin. | Le temps à Harbin semble être meilleur qu'à Pékin. Il pleut légèrement ici et il y a des vents forts pendant la journée. |
| Le concours de publicité sur le campus de l’opérateur était tellement amusant ! Hahaha. | Je pensais que c'était la publicité de Jack Ma. |
| Robe de mariée Delsa S Posa Candy Color Series, rose, bleu, rouge et violet, ludique et fraîche, vous l'aimez ? | Le dernier est tellement beau, tellement beau ! |
Nous avons également utilisé le modèle affiné ci-dessus pour obtenir les résultats d'interaction suivants :
| Roel | Réponse |
|---|---|
| Utilisateur | Ne m'aime pas en vain |
| Bot | L'amour stérile est si douloureux. |
| Utilisateur | Mais ce n'est pas grave si tu l'as aimé |
| Bot | Parfois, l'amour est un jeu. |
| Utilisateur | je perds toujours |
| Bot | Je t'aime autant que je t'aime. |
| Utilisateur | Pouvez-vous le tirer ? |
| Bot | Vous pouvez le tirer. |
| Utilisateur | Ne m'imite pas |
| Bot | Ce que je dis, c'est que vous ne pouvez pas le faire. |
| Utilisateur | Tu m'obliges à le faire, n'est-ce pas ? |
| Bot | Non, je te force à parler, n'est-ce pas ? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
L'ensemble de données LCCC et le modèle de dialogue pré-entraîné fournis par ce projet sont uniquement destinés à des fins de recherche scientifique. Les conversations de l'ensemble de données LCCC sont collectées à partir de différentes sources. Bien que nous ayons conçu un processus strict de nettoyage des données, nous ne garantissons pas que tous les contenus inappropriés ont été filtrés. Tous les contenus et opinions contenus dans ces données sont indépendants des auteurs de ce projet. Le modèle et le code fournis dans ce projet ne sont qu'un composant du système de dialogue complet. Les scripts de décodage que nous fournissons sont uniquement destinés à des fins de recherche scientifique. Tout le contenu de dialogue généré à l'aide des modèles et des scripts de ce projet n'a rien à voir avec l'auteur de. ce projet.
Si vous trouvez notre projet utile, veuillez citer notre article :
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
Ce projet fournit un ensemble de données de conversation chinoise nettoyées à grande échelle et un modèle GPT chinois pré-entraîné sur cet ensemble de données. Veuillez vous référer à notre article pour plus de détails.
Notre code utilisé pour la pré-formation est adapté du modèle TransferTransfo basé sur la bibliothèque Transformers. Les codes utilisés à la fois pour la pré-formation et la mise au point sont fournis dans ce référentiel.
Nous présentons un corpus de conversations chinoises nettoyées à grande échelle (LCCC) contenant : LCCC-base (Baidu Netdisk, Google Drive) et LCCC-large (Baidu Netdisk, Google Drive). Un pipeline de nettoyage de données rigoureux est conçu pour garantir la qualité du corpus de conversations chinoises nettoyées à grande échelle (LCCC). Ce pipeline implique un ensemble de règles et plusieurs filtres basés sur des classificateurs. Les bruits tels que les mots offensants ou sensibles, les symboles spéciaux, les emojis, les phrases grammaticalement incorrectes et les conversations incohérentes sont détectés. filtré.
Les statistiques de notre corpus sont présentées ci-dessous. Les dialogues avec seulement deux énoncés sont considérés comme « à tour unique », et les dialogues avec plus de trois énoncés sont considérés comme « à plusieurs tours ». Jieba est utilisé pour symboliser chaque énoncé en mots.
| Base LCCC (Baidu Netdisk, Google Drive) | Monotour | Multi-tours |
|---|---|---|
| Séances | 3 354 382 | 3 466 607 |
| Énoncés | 6 708 554 | 13 365 268 |
| Personnages | 68 559 727 | 163 690 614 |
| Vocabulaire | 372 063 | 666 931 |
| Mots moyens par énoncé | 6,79 | 8.32 |
| Moy. d'énoncés par session | 2 | 3,86 |
Notez que la base LCCC est nettoyée selon des règles plus strictes que la base LCCC.
| LCCC-grand (Baidu Netdisk, Google Drive) | Monotour | Multi-tours |
|---|---|---|
| Séances | 7 273 804 | 4 733 955 |
| Énoncés | 14 547 608 | 18 341 167 |
| Personnages | 162 301 556 | 217 776 649 |
| Vocabulaire | 662 514 | 690 027 |
| Mots moyens par énoncé | 7h45 | 8.14 |
| Moy. d'énoncés par session | 2 | 3,87 |
Les dialogues bruts pour la base LCCC proviennent d'un corpus Weibo que nous avons exploré à partir de Weibo, et les dialogues bruts pour la base LCCC sont construits en combinant plusieurs ensembles de données de conversation en plus du corpus Weibo :
| Ensemble de données | Séances | Échantillon |
|---|---|---|
| Corpus Weibo | 79M | Q : J'ai mangé du hot pot sept ou huit fois à Chengdu, Chongqing. R : Hahahaha ! Alors ma bouche pourrait pourrir ! |
| Corpus de potins des PTT | 0,4M | Q : Pourquoi les villageois intimident-ils toujours les élèves du secondaire ? QQ R : Si vous pensez que si vous choisissez une bonne matière, vous deviendrez Bill Gates, alors autant abandonner l'école. |
| Corpus de sous-titres | 2,74 millions | Q : Les gens de l'Opéra de Pékin ne sont pas libres. R : Ils mettent les gens en cage. |
| Corpus Xiaohuangji | 0,45M | Q : Avez-vous déjà été amoureux ? A : Avez-vous déjà été amoureux ? Oh, n'en parlez pas, je suis triste... |
| Corpus Tieba | 2,32 millions | Q : Au premier rang, tous les fans de Lu se lèvent, n'est-ce pas ? R : Le titre parle de passes décisives, mais après avoir regardé ce ballon, c'est vraiment une ironie vivante. |
| Corpus Qingyun | 0,1M | Q : Il semble que vous aimez beaucoup l’argent. A : Oh, vraiment ? Alors tu y es presque |
| Corpus de conversations Douban | 0,5M | Q : Apprenez l'anglais pur en regardant des films originaux en anglais A : J'adore Friends et je l'ai regardé plusieurs fois Q : Je suis presque épuisé en regardant le même CD A : Alors votre anglais devrait être plutôt bon maintenant |
| Corpus de conversations e-commerciales | 0,5M | Q : Est-ce que ce sera une bonne affaire ? R : Pas encore Q : Sera-t-il disponible à l'avenir ? |
| Corpus de discussion chinois | 0,5M | Q : Mes jambes sont inutiles aujourd'hui. Vous fêtez les vacances, alors je vais déplacer des briques. A : C'est un travail difficile, je suis même allé gagner beaucoup d'argent à Noël. Allez. Je suis une personne sans petit ami. C'est la même chose pour toutes les vacances. |
Nous présentons également une série de modèles GPT chinois qui sont d'abord pré-entraînés sur un nouvel ensemble de données chinois, puis post-entraînés sur notre ensemble de données LCCC.
Semblable à TransferTransfo, nous concaténons tous les historiques de dialogue en une seule phrase contextuelle et utilisons cette phrase pour prédire la réponse. L'entrée de notre modèle consiste en l'intégration de mots, l'intégration de locuteurs et l'intégration de position de chaque mot.
| Modèles | Taille du paramètre | Ensemble de données de pré-formation | Description |
|---|---|---|---|
| Roman GPT | 95,5 millions | Roman chinois | Un modèle GPT pré-entraîné sur un ensemble de données de roman chinois (1,3 milliard de mots, notez que nous ne fournissons pas le détail de ce modèle) |
| Base CDial-GPT LCCC | 95,5 millions | Base LCCC | Un modèle GPT post-entraîné sur un ensemble de données basé sur LCCC de GPT Novel |
| Base CDial-GPT2 LCCC | 95,5 millions | Base LCCC | Un modèle GPT2 post-entraîné sur un ensemble de données basé sur LCCC de GPT Novel |
| CDial-GPT LCCC-large | 95,5 millions | LCCC-grand | Un modèle GPT post-entraîné sur un grand ensemble de données LCCC de GPT Novel |
Installer à partir des codes sources :
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Étape 1 : Préparez les données pour un réglage fin (par exemple, l'ensemble de données STC ou "data/toy_data.json" dans notre référentiel) et le modèle pré-essayé :
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps : Vous pouvez télécharger le train et la répartition valide du STC à partir des liens suivants : (Baidu Netdisk, Google Drive)
Étape 2 : entraîner le modèle
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
ou
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
Remarque : Nous avons également fourni l'argument train_path dans le script de formation pour lire l'ensemble de données en texte brut, qui sera découpé et géré de manière distribuée. Vous pouvez envisager d'utiliser cet argument si l'ensemble de données est trop volumineux pour la mémoire de votre système (également. n'oubliez pas de laisser l'argument data_path vide si vous utilisez train_path ).
Étape 3 : Mode d'inférence
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
ps : Vous pouvez télécharger la répartition de test de STC à partir des liens suivants : (Baidu Netdisk, Google Drive)
Arguments de formation
| Arguments | Taper | Valeur par défaut | Description |
|---|---|---|---|
| modèle_checkpoint | str | "" | Chemin ou URL des fichiers de modèle (répertoire du modèle de pré-formation et des fichiers de configuration/vocab) |
| pré-entraîné | bouffon | FAUX | Si faux, entraînez le modèle à partir de zéro |
| chemin_données | str | "" | Chemin de l'ensemble de données |
| jeu de données_cache | str | par défaut="dataset_cache" | Chemin ou URL du cache de l'ensemble de données |
| chemin_train | str | "" | Chemin de l'ensemble de formation pour l'ensemble de données distribué |
| chemin_valide | str | "" | Chemin de l'ensemble de validation pour l'ensemble de données distribué |
| fichier_journal | str | "" | Exporter les journaux dans un fichier sous ce chemin |
| num_workers | int | 1 | Nombre de sous-processus pour le chargement des données |
| n_époques | int | 70 | Nombre d'époques de formation |
| train_batch_size | int | 8 | Taille du lot pour la formation |
| valid_batch_size | int | 8 | Taille du lot pour validation |
| max_historique | int | 15 | Nombre d'échanges précédents à conserver dans l'historique |
| planificateur | str | "noam" | Méthode d'optimisation |
| n_emd | int | 768 | Nombre de n_emd dans le fichier de configuration (pour noam) |
| eval_before_start | bouffon | FAUX | Si c'est vrai, commencez l'évaluation avant la formation |
| étapes_échauffement | int | 5000 | Étapes d'échauffement |
| étapes_valides | int | 0 | Effectuer la validation toutes les X étapes, si ce n'est pas 0 |
| gradient_accumulation_steps | int | 64 | Accumuler les dégradés sur plusieurs marches |
| max_norme | flotter | 1.0 | Norme de dégradé de détourage |
| appareil | str | "cuda" si torch.cuda.is_available() sinon "cpu" | Appareil (cuda ou processeur) |
| fp16 | str | "" | Réglé sur O0, O1, O2 ou O3 pour la formation fp16 (voir la documentation apex) |
| local_rank | int | -1 | Rang local pour les formations distribuées (-1 : non distribué) |
L'évaluation est effectuée sur les résultats générés par des modèles affinés sur
Ensemble de données STC (répartition Train/Valide (Baidu Netdisk, Google Drive), répartition test (Baidu Netdisk, Google Drive)). Toutes les réponses sont générées à l'aide du schéma Nucleus Sampling avec un seuil de 0,9 et une température de 0,7.
| Modèles | Taille du modèle | PPL | BLEU-2 | BLEU-4 | Dist-1 | Dist-2 | Correspondance gourmande | Moyenne d'intégration |
|---|---|---|---|---|---|---|---|---|
| Attention-Seq2seq | 73M | 34.20 | 3,93 | 0,90 | 8.5 | 11.91 | 65,84 | 83.38 |
| Transformateur | 113M | 22h10 | 6,72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| Discussion GPT2 | 88M | - | 2.28 | 0,54 | 10.3 | 16h25 | 61,54 | 78,94 |
| Roman GPT | 95,5 millions | 21.27 | 5,96 | 2,71 | 8.0 | 11.72 | 66.12 | 83.34 |
| Base GPT LCCC | 95,5 millions | 18h38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| Base GPT2 LCCC | 95,5 millions | 22.76 | 5,69 | 2,50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-grand | 95,5 millions | 18.23 | 6,63 | 3.20 | 8.3 | 12.71 | 66.25 | 83,63 |
Nous avons également employé 3 annotateurs participatifs pour évaluer 200 échantillons de chaque modèle en termes de fluidité, de pertinence et de diversité sur la base d'un schéma de score 2/1/0. Reportez-vous à notre article pour plus de détails.
| Modèles | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27,1% | 21,4% | 51,4% | 0,4544 |
| Transformateur | 42,4% | 23,6% | 34,0% | 0,4429 |
| Discussion GPT2 | 24,3% | 19,1% | 56,6% | 0,3941 |
| Base GPT LCCC | 46,7% | 21,8% | 31,5% | 0,3954 |
| GPT LCCC-grand | 48,6% | 24,5% | 27,0% | 0,4203 |
Nous sélectionnons au hasard 1000 échantillons générés, et réalisons une statistique de génération toxique :
| Répétition | Gros mot | Autres mauvais cas |
|---|---|---|
| vingt-trois | 9 | 2 |
Exemples générés à un tour à partir de l'ensemble de données STC (affinés sur STC) :
| Poste | Réponse |
|---|---|
| Il s’agit en réalité de Pékin, pas de Harbin. | Le temps à Harbin semble être meilleur qu'à Pékin. Il pleut légèrement ici et il y a des vents forts pendant la journée. |
| Le concours de publicité sur le campus de l’opérateur était tellement amusant ! Hahaha. | Je pensais que c'était la publicité de Jack Ma. |
| Robe de mariée Delsa S Posa Candy Color Series, rose, bleu, rouge et violet, ludique et fraîche, vous l'aimez ? | Le dernier est tellement beau, tellement beau ! |
Exemples générés multi-tours à l'aide du script interactif :
| Roel | Réponse |
|---|---|
| Utilisateur | Ne m'aime pas en vain |
| Bot | L'amour stérile est si douloureux. |
| Utilisateur | Mais ce n'est pas grave si tu l'as aimé |
| Bot | Parfois, l'amour est un jeu. |
| Utilisateur | je perds toujours |
| Bot | Je t'aime autant que je t'aime. |
| Utilisateur | Pouvez-vous le tirer ? |
| Bot | Vous pouvez le tirer. |
| Utilisateur | Ne m'imite pas |
| Bot | Ce que je dis, c'est que vous ne pouvez pas le faire. |
| Utilisateur | Tu m'obliges à le faire, n'est-ce pas ? |
| Bot | Non, je te force à parler, n'est-ce pas ? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
L'ensemble de données LCCC et les modèles pré-entraînés visent à faciliter la recherche pour la génération de conversations. L'ensemble de données LCCC fourni dans ce référentiel provient de diverses sources. Bien qu'un processus de nettoyage rigoureux ait été effectué, rien ne garantit que tous les contenus inappropriés ont été détectés. a été complètement filtré. Tout le contenu contenu dans cet ensemble de données ne représente pas l'opinion des auteurs. Ce référentiel ne contient qu'une partie de la machinerie de modélisation nécessaire pour produire réellement un modèle de dialogue. Le script de décodage fourni dans ce référentiel est uniquement destiné à des fins de recherche. . Nous ne sommes pas responsables de tout contenu généré à l’aide de notre modèle.
Veuillez citer notre article si vous utilisez les ensembles de données ou les modèles dans votre recherche :
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


