YAYI2
1.0.0

[LISEZMOI] [?HF Repo] [?Version Web]
Chinois | Anglais
[2024.03.28] Tous les modèles et données sont téléchargés sur la communauté Magic.
[2023.12.22] Nous avons publié le rapport technique YAYI 2 : Grands modèles linguistiques multilingues open source.
YAYI 2 est une nouvelle génération de grand modèle de langage open source développé par Zhongke Wenge, comprenant les versions Base et Chat, avec une taille de paramètre de 30 Mo. YAYI2-30B est un grand modèle de langage basé sur Transformer, qui utilise un corpus multilingue de haute qualité de plus de 2 000 milliards de jetons pour la pré-formation. Pour les scénarios d'application généraux et spécifiques à un domaine, nous utilisons des millions d'instructions pour un réglage précis et utilisons des méthodes d'apprentissage par renforcement par rétroaction humaine pour mieux aligner le modèle sur les valeurs humaines.
Le modèle open source cette fois est le modèle de base YAYI2-30B. Nous espérons promouvoir le développement de la communauté open source chinoise de grands modèles pré-formés grâce à l'open source des grands modèles Yayi, et y contribuer activement. Grâce à l'open source, nous travaillons avec chaque partenaire pour construire l'écosystème de grands modèles Yayi.
Pour plus de détails techniques, veuillez lire notre rapport technique YAYI 2 : Grands modèles linguistiques multilingues open source.
| Nom de l'ensemble de données | taille | ? Identification du modèle HF | Adresse de téléchargement | Logo du modèle magique | Adresse de téléchargement |
|---|---|---|---|---|---|
| Données de pré-entraînement YAYI2 | 500G | wenge-research/yayi2_pretrain_data | Téléchargement de l'ensemble de données | wenge-research/yayi2_pretrain_data | Téléchargement de l'ensemble de données |
| Nom du modèle | longueur du contexte | ? Identification du modèle HF | Adresse de téléchargement | Logo du modèle magique | Adresse de téléchargement |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | wenge-research/yayi2-30b | Téléchargement du modèle | wenge-research/yayi2-30b | Téléchargement du modèle |
| YAYI2-30B-Chat | 4096 | wenge-research/yayi2-30b-chat | À venir... |
Nous avons effectué des évaluations sur plusieurs ensembles de données de référence, notamment C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval et MBPP. Nous avons examiné les performances du modèle en matière de compréhension du langage, de connaissance du sujet, de raisonnement mathématique, de raisonnement logique et de génération de code. Le modèle YAYI 2 démontre des améliorations significatives des performances par rapport aux modèles open source de taille similaire.
| connaissance du sujet | mathématiques | raisonnement logique | code | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Modèle | C-Eval(val) | MMLU | AGIEval | CMMLU | GAOKAO-Banc | GSM8K | MATHÉMATIQUES | BBH | HumanEval | MBPP |
| 5 coups | 5 coups | 3/0-shot | 5 coups | 0-coup | 8/4 plans | 4 coups | 3 coups | 0-coup | 3 coups | |
| MPT-30B | - | 46,9 | 33,8 | - | - | 15.2 | 3.1 | 38,0 | 25,0 | 32,8 |
| Faucon-40B | - | 55.4 | 37,0 | - | - | 19.6 | 5.5 | 37.1 | 0,6 | 29,8 |
| LLaMA2-34B | - | 62,6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33,0 |
| Baichuan2-13B | 59,0 | 59,5 | 37.4 | 61,3 | 45,6 | 52,6 | 10.1 | 49,0 | 17.1 | 30,8 |
| Qwen-14B | 71,7 | 67,9 | 51,9 | 70.2 | 62,5 | 61,6 | 25.2 | 53,7 | 32.3 | 39,8 |
| StagiaireLM-20B | 58,8 | 62.1 | 44,6 | 59,0 | 45,5 | 52,6 | 7.9 | 52,5 | 25.6 | 35,6 |
| Aquila2-34B | 98,5 | 76,0 | 43,8 | 78,5 | 37,8 | 50,0 | 17.8 | 42,5 | 0,0 | 41,0 |
| Yi-34B | 81,8 | 76,3 | 56,5 | 82,6 | 68,3 | 67,6 | 15.9 | 66,4 | 26.2 | 38.2 |
| YAYI2-30B | 80,9 | 80,5 | 62,0 | 84,0 | 64,4 | 71.2 | 14.8 | 54,5 | 53.1 | 45,8 |
Nous avons effectué notre évaluation en utilisant le code source fourni par le référentiel OpenCompass Github. Pour les modèles de comparaison, nous répertorions leurs résultats d'évaluation sur la liste OpenCompass, au 15 décembre 2023. Pour les autres modèles qui n'ont pas participé à l'évaluation sur la plateforme OpenCompass, notamment MPT, Falcon et LLaMa 2, nous avons adopté les résultats rapportés par LLaMA 2.
Nous fournissons des exemples simples pour illustrer comment utiliser rapidement YAYI2-30B pour l'inférence. Cet exemple peut être exécuté sur un seul A100/A800.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envVeuillez noter que ce projet nécessite Python 3.8 ou supérieur.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Lors de votre première visite, le modèle doit être téléchargé et chargé, ce qui peut prendre un certain temps.
Ce projet prend en charge le réglage fin des instructions basé sur le cadre de formation distribué deepspeed. Configurez l'environnement et exécutez le script correspondant pour démarrer le réglage fin des paramètres complets ou le réglage fin LoRA.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps Format des données : reportez-vous à data/yayi_train_example.json , qui est un fichier JSON standard. Chaque élément de données se compose de "system" et "conversations" , où "system" correspond aux informations de définition de rôle globales et peut être "conversations" chaîne vide. "conversations" sont de multiples séries de dialogues entre des personnages humains et yayi.
Instructions d'utilisation : Exécutez la commande suivante pour démarrer le réglage fin des paramètres complets du modèle Yayi. Cette commande prend en charge la formation multi-machines et multi-cartes. Il est recommandé d'utiliser une configuration matérielle 16*A100 (80G) ou supérieure.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True Ou démarrez via la ligne de commande :
bash scripts/start.sh Veuillez noter que si vous devez utiliser le modèle ChatML pour affiner les instructions, vous pouvez remplacer --module training.trainer_yayi2 dans la commande par --module training.trainer_chatml ; si vous devez personnaliser le modèle Chat, vous pouvez le modifier ; le système dans le modèle Chat de trainer_chatml.py Définitions de jetons spéciaux pour les trois rôles de , utilisateur et assistant. Voici un exemple de modèle ChatML Si ce modèle ou un modèle personnalisé est utilisé pendant la formation, il doit également être cohérent lors de l'inférence.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh Au cours de la phase de pré-formation, nous avons non seulement utilisé les données Internet pour entraîner les capacités linguistiques du modèle, mais nous avons également ajouté des données générales sélectionnées et des données de domaine pour améliorer les compétences professionnelles du modèle. La répartition des données est la suivante : 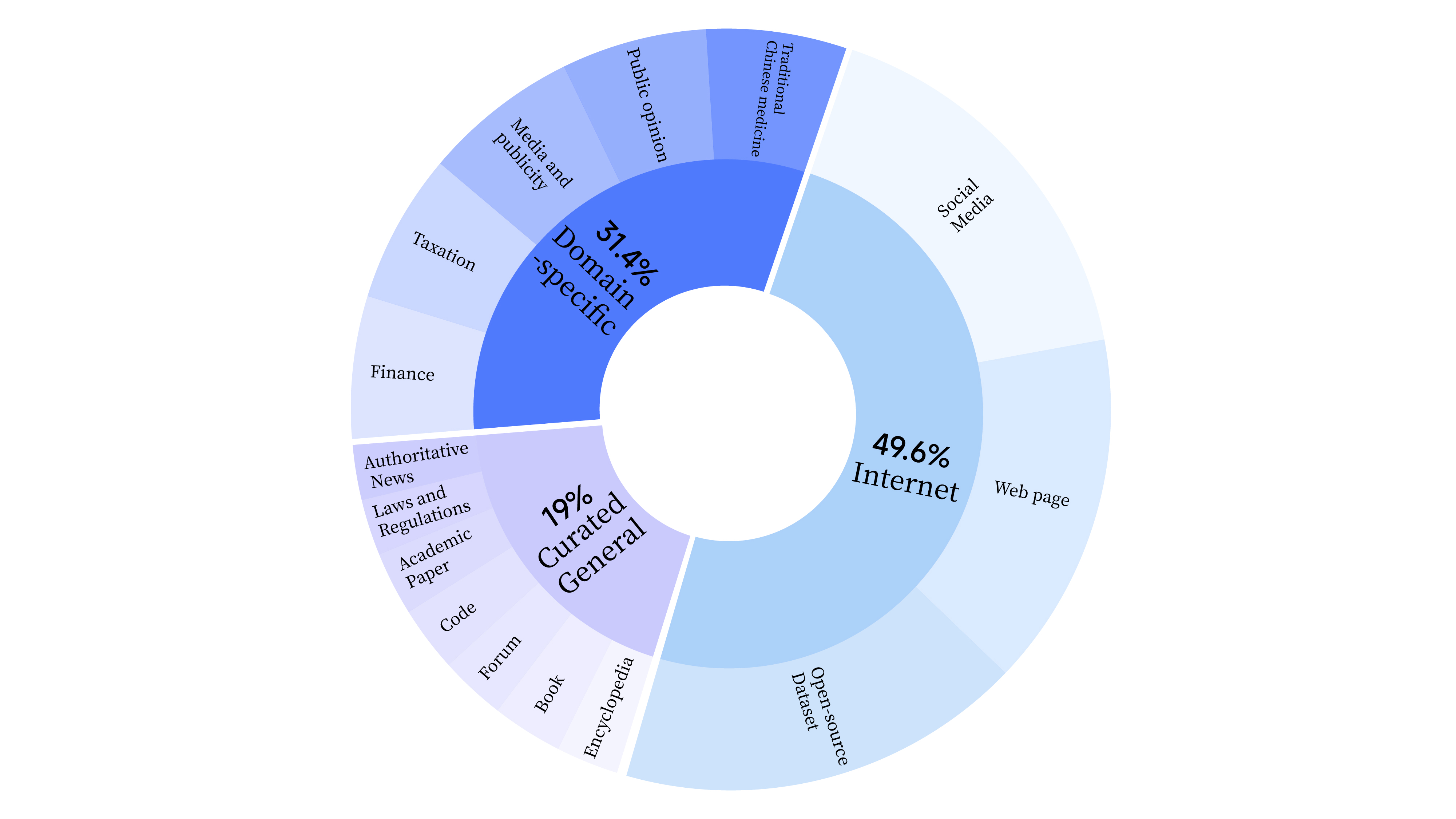
Nous avons construit un ensemble de pipelines de traitement de données pour améliorer la qualité des données sous tous leurs aspects, comprenant quatre modules : standardisation, nettoyage heuristique, déduplication multi-niveaux et filtrage de toxicité. Nous avons collecté un total de 240 To de données brutes, et il ne restait que 10,6 To de données de haute qualité après prétraitement. Le processus global est le suivant : 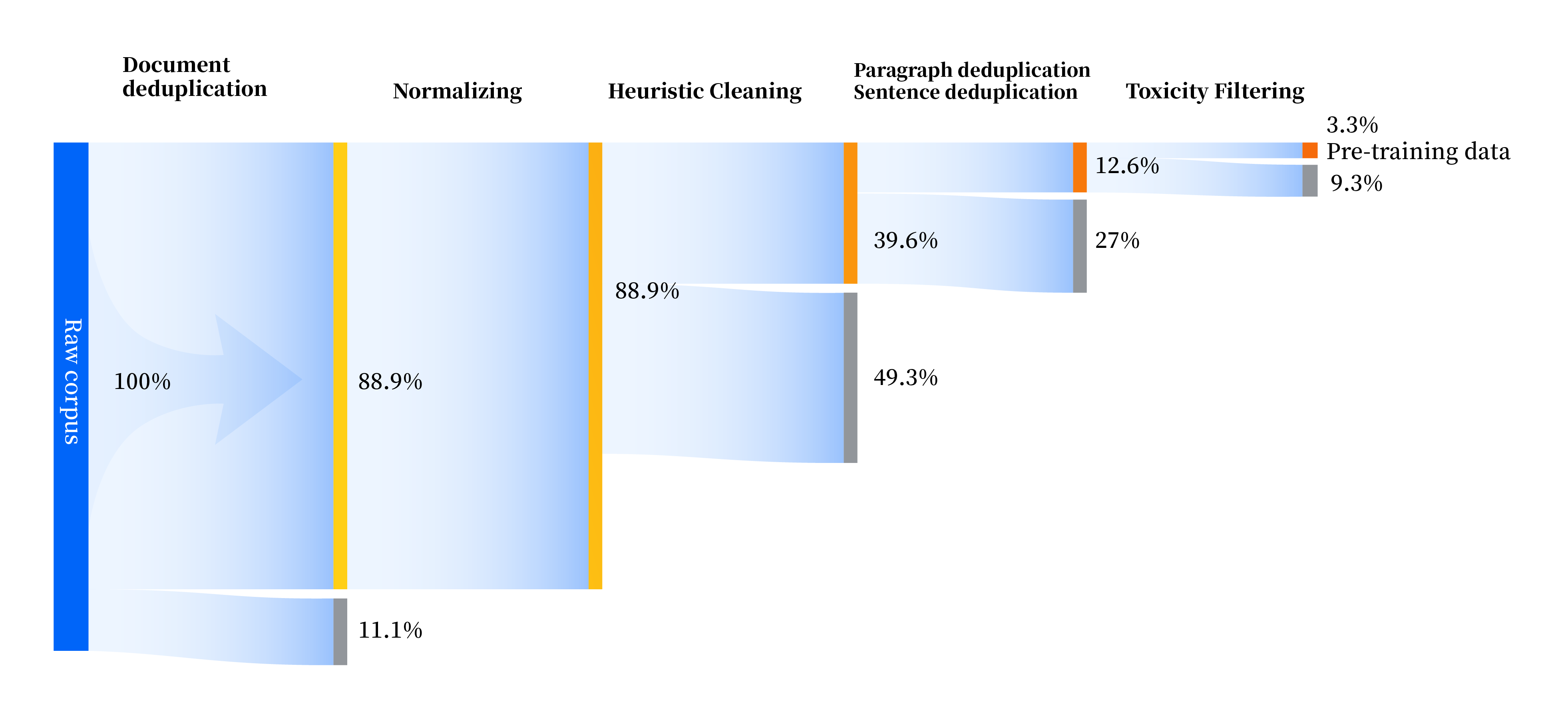

La courbe de perte du modèle YAYI 2 est présentée dans la figure ci-dessous : 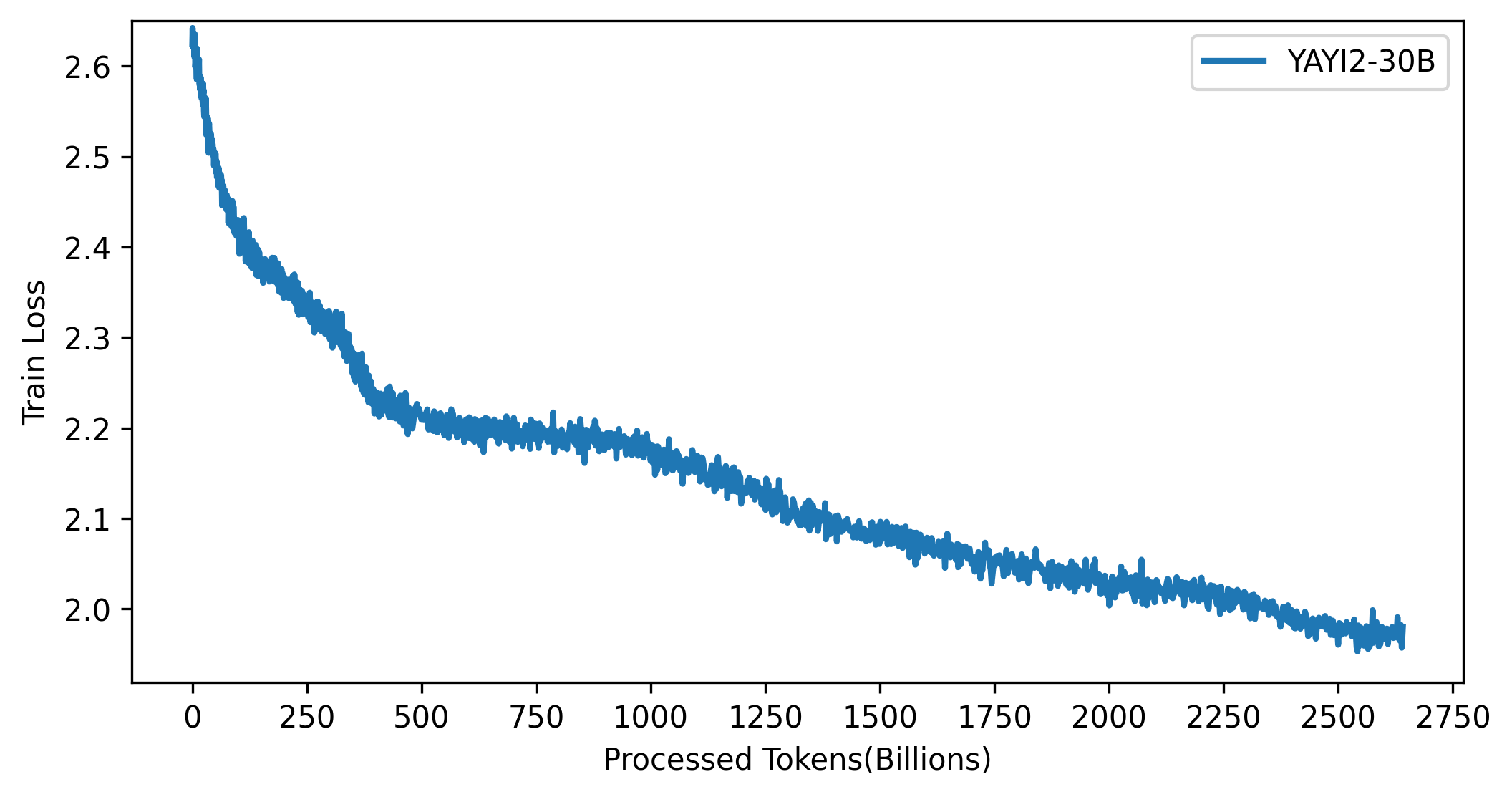
Le code de ce projet est open source conformément au protocole Apache-2.0. L'utilisation par la communauté du modèle et des données YAYI 2 doit être conforme au « Contrat de licence communautaire modèle Yayi YAYI 2 ». Si vous devez utiliser les modèles de la série YAYI 2 ou leurs dérivés à des fins commerciales, veuillez compléter les « Informations d'enregistrement commercial du modèle YAYI 2 » et l'envoyer à [email protected]. Nous vous répondrons dans les 3 jours ouvrables après réception de l'e-mail. l'examen sera effectué quotidiennement. Après avoir réussi l'examen, vous recevrez une licence commerciale. Veuillez respecter strictement le contenu pertinent du « Contrat de licence commerciale modèle YAYI 2 » pendant l'utilisation. Merci pour votre coopération !
Si vous utilisez notre modèle dans votre travail, veuillez citer notre article :
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


