Cosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) Etablissez votre configuration avec : accelerate config puis : accelerate launch train.py
KOSMOS-1 utilise une architecture de transformateur uniquement décodeur basée sur Magneto (Foundation Transformers), c'est-à-dire une architecture qui utilise une approche dite sub-LN où la normalisation des couches est ajoutée à la fois avant le module d'attention (pré-ln) et après (post-LN). ln) combinant les avantages des deux approches respectivement pour la modélisation du langage et la compréhension des images. Le modèle est également initialisé selon une métrique spécifique également décrite dans l'article, permettant une formation plus stable à des taux d'apprentissage plus élevés.
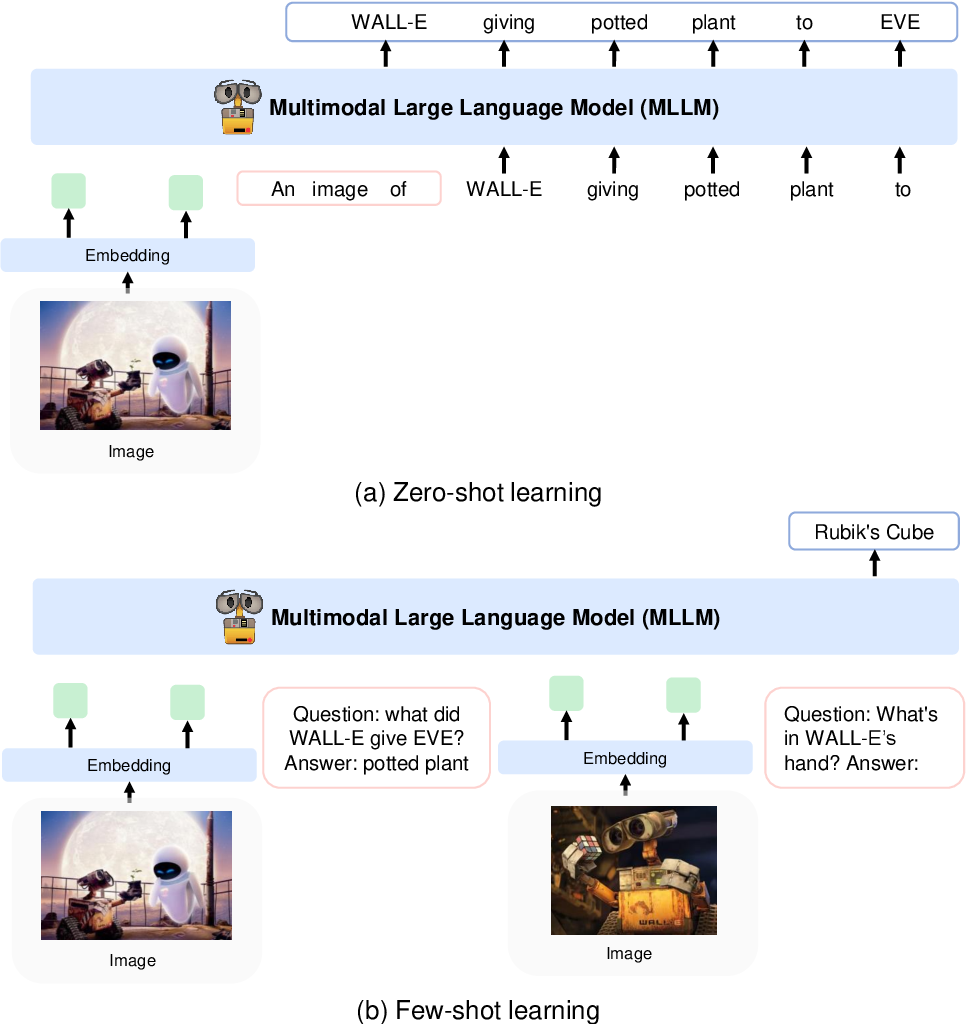
Ils encodent les images en caractéristiques d'image à l'aide d'un modèle CLIP VIT-L/14 et utilisent un rééchantillonneur de perception introduit dans Flamingo pour regrouper les caractéristiques d'image de 256 -> 64 jetons. Les fonctionnalités de l'image sont combinées avec les intégrations de jetons en les ajoutant à la séquence d'entrée entourée de jetons spéciaux . Un exemple est
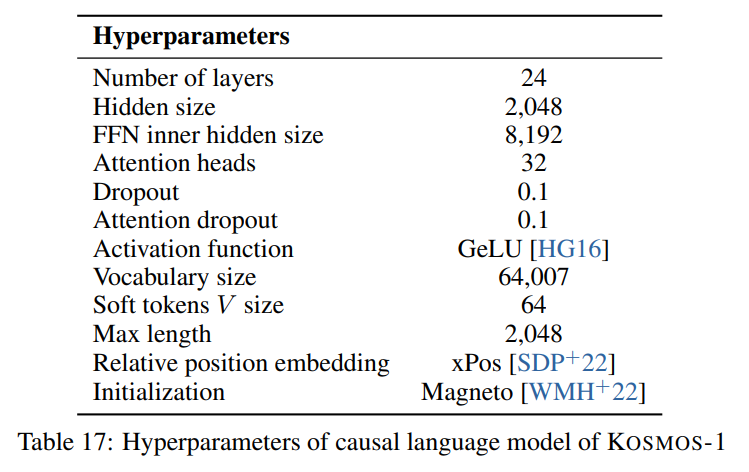
Nous suivons les hyperparamètres décrits dans l'article visible dans l'image suivante :
Nous utilisons l'implémentation à grande échelle de l'architecture Transformer uniquement avec décodeur de Foundation Transformers :
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)Pour le modèle d'image (CLIP VIT-L/14), nous utilisons un modèle OpenClip pré-entraîné :
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]Nous suivons les hyperparams par défaut pour le rééchantillonneur de percepteur car aucun hyperparam n'est donné dans l'article :
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) Étant donné que le modèle s'attend à une dimension cachée de 2048 , nous utilisons un calque nn.Linear pour projeter les caractéristiques de l'image à la dimension correcte et l'initialiser selon le schéma d'initialisation de Magneto :
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) L'article décrit un SentencePièce avec un vocabulaire de 64007 jetons. Pour plus de simplicité (car nous n'avons pas le corpus de formation disponible), nous utilisons la meilleure alternative open source qui est le tokenizer pré-entraîné T5-large de HuggingFace. Ce tokenizer a un vocabulaire de 32002 tokens.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "" , "" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) Nous intégrons ensuite les jetons avec une couche nn.Embedding . Nous utilisons en fait un bnb.nn.Embedding de bitandbytes qui nous permet d'utiliser AdamW 8 bits plus tard.
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Pour les plongements positionnels, nous utilisons :
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Nous ajoutons également une couche de projection en sortie pour projeter la dimension cachée à la taille du vocabulaire et l'initialisons selon le schéma d'initialisation de Magneto :
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) J'ai dû apporter quelques légères modifications au décodeur pour lui permettre d'accepter les fonctionnalités déjà intégrées dans la passe avant. Cela était nécessaire pour permettre la séquence de saisie plus complexe décrite ci-dessus. Les changements sont visibles dans la différence suivante à la ligne 391 de torchscale/architecture/decoder.py :
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )Voici un tableau de démarques avec des métadonnées pour les ensembles de données mentionnés dans l'article :
| Ensemble de données | Description | Taille | Lien |
|---|---|---|---|
| La pile | Corpus de textes anglais diversifié | 800 Go | Visage câlin |
| Exploration commune | Données d'exploration du Web | - | Exploration commune |
| LAION-400M | Paires image-texte de Common Crawl | 400 millions de paires | Visage câlin |
| LAION-2B | Paires image-texte de Common Crawl | 2B paires | ArXiv |
| COYO | Paires image-texte de Common Crawl | 700 millions de paires | GitHub |
| Légendes conceptuelles | Paires image-texte alternatif | 15 millions de paires | ArXiv |
| Données CC entrelacées | Texte et images de Common Crawl | 71 millions de documents | Ensemble de données personnalisé |
| HistoireClose | Raisonnement de bon sens | 16 000 exemples | Anthologie du LCA |
| HellaSwag | NLI de bon sens | 70 000 exemples | ArXiv |
| Schéma de Winograd | Ambiguïté du mot | 273 exemples | PKRR2012 |
| Winogrande | Ambiguïté du mot | 1,7k exemples | AAAI 2020 |
| PIQA | Assurance qualité de bon sens physique | 16 000 exemples | AAAI 2020 |
| BoolQ | Assurance qualité | 15 000 exemples | LCA 2019 |
| CB | Inférence en langage naturel | 250 exemples | Sinn et Bedeutung 2019 |
| COPA | Raisonnement causal | 1 000 exemples | Symposium de printemps de l'AAAI 2011 |
| Taille relative | Raisonnement de bon sens | 486 paires | ArXiv2016 |
| Couleur Mémoire | Raisonnement de bon sens | 720 exemples | ArXiv2021 |
| Conditions de couleur | Raisonnement de bon sens | 320 exemples | LCA 2012 |
| Test de QI | Raisonnement non verbal | 50 exemples | Ensemble de données personnalisé |
| Légendes COCO | Légende des images | 413 000 images | PAMI 2015 |
| Flickr30k | Légende des images | 31 000 images | TACL 2014 |
| VQAv2 | Assurance qualité visuelle | 1 million de paires d'assurance qualité | CVPR 2017 |
| Visualisation | Assurance qualité visuelle | 31 000 paires de contrôle qualité | CVPR 2018 |
| WebSRC | Assurance qualité Web | 1,4k exemples | EMNLP 2021 |
| ImageNet | Classement des images | 1,28 million d'images | CVPR 2009 |
| CUBE | Classement des images | 200 espèces d'oiseaux | TOG 2011 |
APACHES
