Copulas
v0.12.0 - 2024-11-12
Ce référentiel fait partie du projet Synthetic Data Vault, un projet de DataCebo.

Copulas est une bibliothèque Python permettant de modéliser des distributions multivariées et d'en échantillonner à l'aide de fonctions de copule. Étant donné un tableau de données numériques, utilisez des copules pour apprendre la distribution et générer de nouvelles données synthétiques suivant les mêmes propriétés statistiques.
Principales caractéristiques :
Modélisez des données multivariées. Choisissez parmi une variété de distributions et de copules univariées, notamment les copules archimédiennes, les copules gaussiennes et les copules vigne.
Comparez visuellement les données réelles et synthétiques après avoir construit votre modèle. Les visualisations sont disponibles sous forme d'histogrammes 1D, de nuages de points 2D et de nuages de points 3D.
Accédez et manipulez les paramètres appris. Avec un accès complet aux composants internes du modèle, définissez ou ajustez les paramètres selon votre choix.
Installez la bibliothèque Copulas en utilisant pip ou conda.
pip install copulasconda install -c conda-forge copulasCommencez à utiliser un ensemble de données de démonstration. Cet ensemble de données contient 3 colonnes numériques.
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()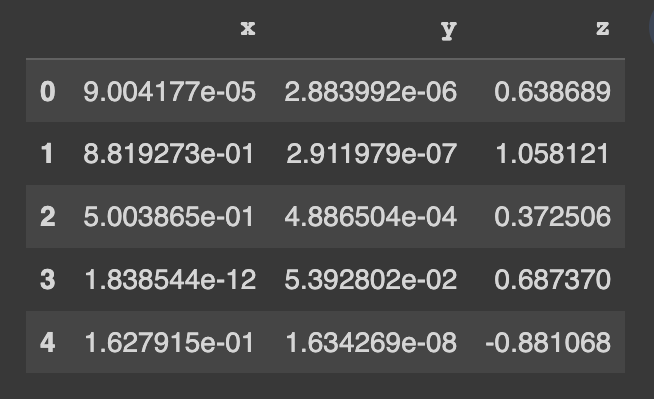
Modélisez les données à l'aide d'une copule et utilisez-la pour créer des données synthétiques. La bibliothèque Copulas offre de nombreuses options, notamment la copule gaussienne, les copules de vigne et les copules archimédiennes.
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))Visualisez côte à côte les données réelles et synthétiques. Faisons cela en 3D, alors consultez notre ensemble de données complet.
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )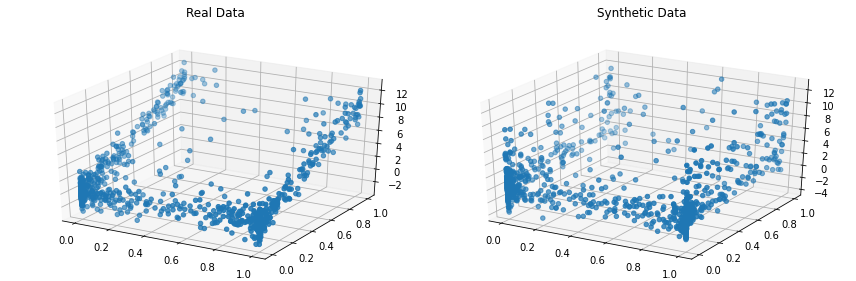
Cliquez ci-dessous pour exécuter le code vous-même sur un notebook Colab et découvrir de nouvelles fonctionnalités.
Apprenez-en plus sur la bibliothèque Copulas sur notre site de documentation.
Des questions ou des problèmes ? Rejoignez notre chaîne Slack pour en savoir plus sur les copules et les données synthétiques. Si vous trouvez un bug ou avez une demande de fonctionnalité, vous pouvez également ouvrir un ticket sur notre GitHub.
Vous souhaitez contribuer à Copulas ? Lisez notre guide de contribution pour commencer.
Le projet open source Copulas a démarré pour la première fois au Data to AI Lab du MIT en 2018. Merci à notre équipe de contributeurs qui ont construit et maintenu la bibliothèque au fil des ans !
Voir les contributeurs

Le projet Synthetic Data Vault a été créé pour la première fois au Data to AI Lab du MIT en 2016. Après 4 ans de recherche et de traction avec l'entreprise, nous avons créé DataCebo en 2020 dans le but de développer le projet. Aujourd'hui, DataCebo est le fier développeur de SDV, le plus grand écosystème de génération et d'évaluation de données synthétiques. Il héberge plusieurs bibliothèques prenant en charge les données synthétiques, notamment :
Commencez à utiliser le package SDV : une solution entièrement intégrée et votre guichet unique pour les données synthétiques. Ou utilisez les bibliothèques autonomes pour des besoins spécifiques.


