SimplyRetrieve
Dependencies Update
? Actualités : 21 août 2023 -- Les utilisateurs peuvent désormais créer et ajouter des connaissances à la volée via le nouvel Knowledge Tab dans l'interface graphique. En outre, des barres de progression ont été ajoutées dans les onglets Configuration et Connaissances.
SimplyRetrieve est un outil open source dont l'objectif est de fournir une plate-forme GUI et API entièrement localisée, légère et conviviale pour l'approche de génération centrée sur la récupération (RCG) à la communauté d'apprentissage automatique.
Créez un outil de chat avec vos documents et modèles linguistiques, hautement personnalisable. Les fonctionnalités sont :
Un rapport technique sur cet outil est disponible sur arXiv.
Une courte vidéo sur cet outil est disponible sur YouTube.
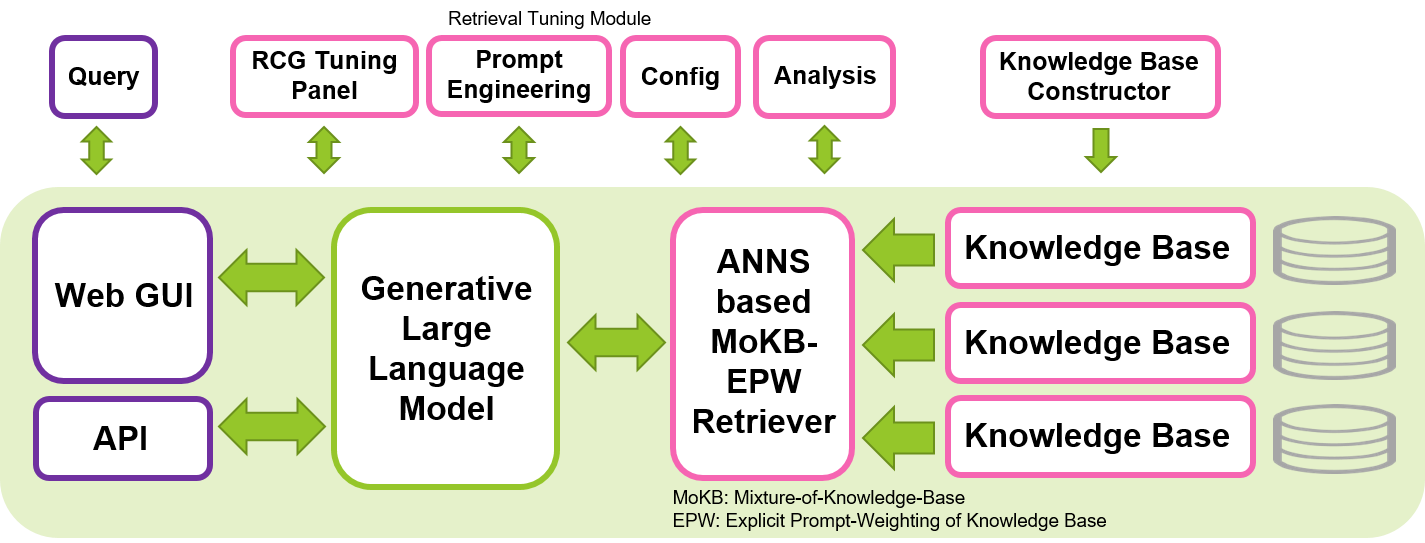
Nous visons à contribuer au développement de LLM sûrs, interprétables et responsables en partageant notre outil open source pour la mise en œuvre de l'approche RCG. Nous espérons que cet outil permettra à la communauté du machine learning d'explorer l'utilisation des LLM de manière plus efficace, tout en préservant la confidentialité et la mise en œuvre locale. La génération centrée sur la récupération, qui s'appuie sur le concept de génération augmentée par récupération (RAG) en mettant l'accent sur le rôle crucial des LLM dans l'interprétation du contexte et en confiant la mémorisation des connaissances au composant récupérateur, a le potentiel de produire une génération plus efficace et interprétable, et de réduire l'échelle des LLM requis pour les tâches génératives. Cet outil peut être exécuté sur un seul GPU Nvidia, tel que le T4, le V100 ou l'A100, le rendant accessible à un large éventail d'utilisateurs.
Cet outil est construit sur la base principalement des bibliothèques impressionnantes et familières de Hugging Face, Gradio, PyTorch et Faiss. Le LLM par défaut configuré dans cet outil est l'instruction affinée Wizard-Vicuna-13B-Uncensored. Le modèle d'intégration par défaut pour retriever est multilingual-e5-base. Nous avons constaté que ces modèles fonctionnent bien dans ce système, ainsi que dans de nombreux autres LLM et récupérateurs open source de différentes tailles disponibles dans Hugging Face. Cet outil peut être exécuté dans d'autres langues que l'anglais, en sélectionnant les LLM appropriés et en personnalisant les modèles d'invite en fonction de la langue cible.
pip install -r requirements.txtchat/data/ et exécutez le script de préparation des données ( cd chat/ puis la commande suivante) CUDA_VISIBLE_DEVICES=0 python prepare.py --input data/ --output knowledge/ --config configs/default_release.json
pdf, txt, doc, docx, ppt, pptx, html, md, csv et peuvent être facilement étendus en modifiant le fichier de configuration. Suivez les conseils sur ce problème si une erreur liée à NLTK s'est produite.Knowledge Tab de l'outil GUI. Les utilisateurs peuvent désormais ajouter des connaissances à la volée. Exécuter le script prepare.py ci-dessus avant d'exécuter l'outil n'est pas une nécessité. Après avoir configuré les conditions préalables ci-dessus, définissez le chemin actuel vers le répertoire chat ( cd chat/ ), exécutez la commande ci-dessous. Alors grab a coffee! car le chargement ne prendra que quelques minutes.
CUDA_VISIBLE_DEVICES=0 python chat.py --config configs/default_release.json
Ensuite, accédez à l'interface graphique Web à partir de votre navigateur préféré en accédant à http://<LOCAL_SERVER_IP>:7860 . Remplacez <LOCAL_SERVER_IP> par l'adresse IP de votre serveur GPU. Et ça y est, vous êtes prêt à partir !
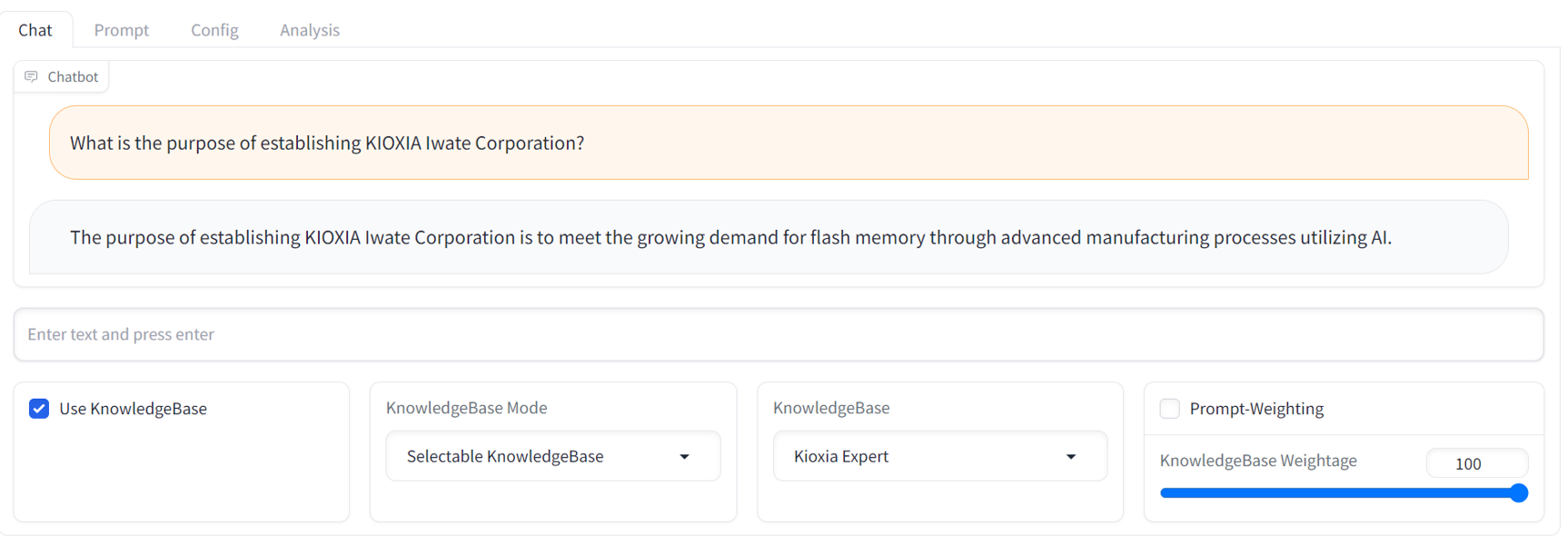
GUI operation manual , veuillez vous référer au fichier readme de l'interface graphique situé dans le répertoire docs/ .API access manual , veuillez vous référer au fichier Lisez-moi de l'API et aux exemples de scripts situés dans le répertoire examples/ .Vous trouverez ci-dessous un exemple de capture d'écran de discussion de l'interface graphique. Il fournit une interface de chatbot de streaming familière avec un panneau de réglage RCG complet.
Vous n'avez pas de serveur GPU local pour exécuter cet outil pour le moment ? Aucun problème. Visitez ce référentiel. Il montre les instructions pour essayer cet outil sur la plate-forme cloud AWS EC2.
N'hésitez pas à nous faire part de vos retours et commentaires. Nous apprécions toute discussion et contribution sur cet outil, y compris les nouvelles fonctionnalités, les améliorations et les meilleures documentations. N'hésitez pas à ouvrir un problème ou une discussion. Nous n'avons pas encore de modèle de problème ou de discussion, donc tout fera l'affaire pour l'instant.
Développements futurs
Il est important de noter que cet outil ne fournit pas une solution infaillible pour garantir une réponse totalement sûre et responsable des modèles d’IA génératifs, même dans le cadre d’une approche centrée sur la récupération. Le développement de systèmes d’IA plus sûrs, interprétables et responsables reste un domaine de recherche actif et d’efforts continus.
Les textes générés à partir de cet outil peuvent présenter des variations, même lorsqu'ils ne modifient que légèrement les invites ou les requêtes, en raison du prochain comportement de prédiction de jeton des LLM de la génération actuelle. Cela signifie que les utilisateurs devront peut-être affiner soigneusement les invites et les requêtes pour obtenir des réponses optimales.
Si vous trouvez notre travail utile, veuillez nous citer comme suit :
@article{ng2023simplyretrieve,
title={SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool},
author={Youyang Ng and Daisuke Miyashita and Yasuto Hoshi and Yasuhiro Morioka and Osamu Torii and Tomoya Kodama and Jun Deguchi},
year={2023},
eprint={2308.03983},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={arXiv preprint arXiv:2308.03983}
}
?️ Affiliation : Institute of Memory Technology R&D, Kioxia Corporation, Japon


