uniflow llm based pdf extraction text cleaning data clustering
0.0.31
uniflow fournit une interface LLM unifiée pour extraire et transformer des documents bruts.
Uniflow relève deux défis clés dans la préparation des données de formation LLM pour les scientifiques ML :
Par conséquent, nous avons construit Uniflow, une interface LLM unifiée pour extraire et transformer des documents bruts.
Uniflow vise à aider chaque data scientist à générer ses propres ensembles de données de formation prêts à l'emploi et à confidentialité préservée pour le réglage fin du LLM, et ainsi rendre le réglage fin du LLM plus accessible à tous :rocket :.
Découvrez les solutions pratiques d'Uniflow :
L'installation uniflow prend environ 5 à 10 minutes si vous suivez les 3 étapes ci-dessous :
Créez un environnement conda sur votre terminal en utilisant :
conda create -n uniflow python=3.10 -y
conda activate uniflow # some OS requires `source activate uniflow`
Installez le pytorch compatible en fonction de votre système d'exploitation.
nvcc -V . pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121 # cu121 means cuda 12.1
pip3 install torch
Installer uniflow :
pip3 install uniflow
(Facultatif) Si vous exécutez l'un des flux OpenAI suivants, vous devrez configurer votre clé API OpenAI. Pour ce faire, créez un fichier .env dans votre dossier racine Uniflow. Ajoutez ensuite la ligne suivante au fichier .env :
OPENAI_API_KEY=YOUR_API_KEY
(Facultatif) Si vous exécutez HuggingfaceModelFlow , vous devrez également installer les bibliothèques transformers , accelerate , bitsandbytes et scipy :
pip3 install transformers accelerate bitsandbytes scipy
(Facultatif) Si vous exécutez LMQGModelFlow , vous devrez également installer les bibliothèques lmqg et spacy :
pip3 install lmqg spacy
Félicitations, vous avez terminé l'installation !
Si vous souhaitez contribuer à nous, voici les configurations préliminaires de développement.
conda create -n uniflow python=3.10 -y
conda activate uniflow
cd uniflow
pip3 install poetry
poetry install --no-root
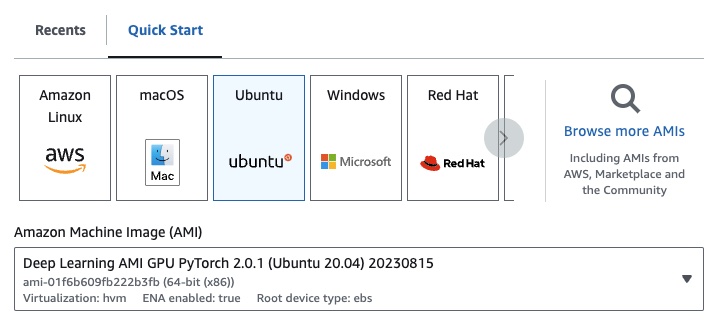
Si vous êtes sur EC2, vous pouvez lancer une instance GPU avec la configuration suivante :
g4dn.xlarge (si vous souhaitez exécuter un LLM pré-entraîné avec des paramètres 7B)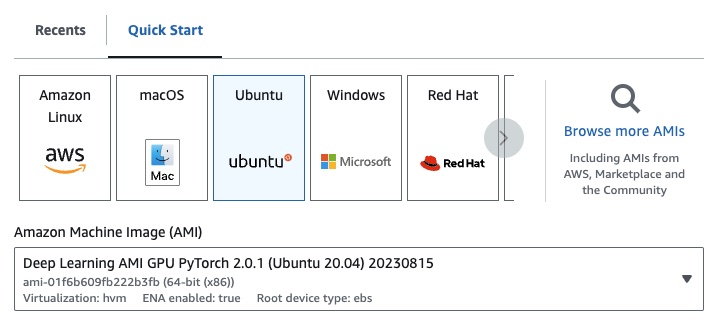
Si vous exécutez l'un des flux OpenAI suivants, vous devrez configurer votre clé API OpenAI.
Pour ce faire, créez un fichier .env dans votre dossier racine Uniflow. Ajoutez ensuite la ligne suivante au fichier .env :
OPENAI_API_KEY=YOUR_API_KEY
Pour utiliser uniflow , suivez trois étapes principales :
Choisissez une Config
Celui-ci détermine le LLM et les différents paramètres configurables.
Construisez vos Prompts
Construisez le contexte que vous souhaitez utiliser pour inviter votre modèle. Vous pouvez configurer des instructions et des exemples personnalisés à l'aide de la classe PromptTemplate .
Exécutez votre Flow
Exécutez le flux sur vos données d'entrée et générez la sortie de votre LLM.
Remarque : nous sommes actuellement en train de créer des flux
Preprocessingpour aider à traiter les données provenant de différentes sources, telles quehtml,Markdown, etc.
La Config détermine quel LLM est utilisé et comment les données d'entrée sont sérialisées et désérialisées. Il possède également des paramètres spécifiques au LLM.
Voici un tableau des différentes configurations prédéfinies que vous pouvez utiliser et leurs LLM correspondants :
| Configuration | LLM |
|---|---|
| Configuration | gpt-3.5-turbo-1106 |
| OuvrirAIConfig | gpt-3.5-turbo-1106 |
| HuggingfaceConfig | mistralai/Mistral-7B-Instruct-v0.1 |
| LMQGConfig | lmqg/t5-base-squad-qg-ae |
Vous pouvez exécuter chaque configuration avec les valeurs par défaut ou transmettre des paramètres personnalisés, tels que temperature ou batch_size à la configuration pour votre cas d'utilisation. Consultez la section de configuration personnalisée avancée pour plus de détails.
Par défaut, uniflow est configuré pour générer des questions et des réponses en fonction du Context que vous transmettez. Pour ce faire, il dispose d'une instruction par défaut et de quelques exemples qu'il utilise pour guider le LLM.
Voici l'instruction par défaut :
Generate one question and its corresponding answer based on the last context in the last example. Follow the format of the examples below to include context, question, and answer in the response
Voici quelques exemples par défaut :
context="The quick brown fox jumps over the lazy brown dog.",
question="What is the color of the fox?",
answer="brown."
context="The quick brown fox jumps over the lazy black dog.",
question="What is the color of the dog?",
answer="black."
Pour exécuter avec ces instructions et exemples par défaut, tout ce que vous avez à faire est de transmettre une liste d'objets Context au flux. uniflow générera ensuite une invite personnalisée avec les instructions et quelques exemples pour chaque objet Context à envoyer au LLM. Voir la section Exécution du flux pour plus de détails.
La classe Context est utilisée pour transmettre le contexte de l'invite LLM. Un Context consiste en une propriété context , qui est une chaîne de texte.
Pour exécuter uniflow avec les instructions par défaut et quelques exemples, vous pouvez transmettre une liste d'objets Context au flux. Par exemple:
from uniflow.op.prompt import Context
data = [
Context(
context="The quick brown fox jumps over the lazy brown dog.",
),
...
]
client.run(data)
Pour une présentation plus détaillée de l’exécution du flux, consultez la section Exécution du flux.
Si vous souhaitez exécuter avec une instruction d'invite personnalisée ou des exemples simples, vous pouvez utiliser l'objet PromptTemplate . Il a des propriétés instruction et example .
| Propriété | Taper | Description |
|---|---|---|
instruction | str | Instructions détaillées pour le LLM |
examples | Liste[Contexte] | Les quelques exemples tirés. |
Vous pouvez remplacer n'importe quelle valeur par défaut si nécessaire.
Pour voir un exemple d'utilisation de PromptTemplate pour exécuter uniflow avec une instruction personnalisée, quelques exemples et des champs Context personnalisés pour générer un résumé, consultez le bloc-notes openai_pdf_source_10k_summary.
Une fois que vous avez décidé de votre Config et de votre stratégie d'invite, vous pouvez exécuter le flux sur les données d'entrée.
Importez les objets uniflow Client , Config et Context .
from uniflow.flow.client import TransformClient
from uniflow.flow.config import TransformOpenAIConfig, OpenAIModelConfig
from uniflow.op.prompt import Context
Prétraitez vos données en morceaux à transmettre dans le flux. À l'avenir, nous aurons des flux Preprocessing pour vous aider dans cette étape, mais pour l'instant, vous pouvez utiliser une bibliothèque de votre choix, comme pypdf, pour fragmenter vos données.
raw_input_context = ["It was a sunny day and the sky color is blue.", "My name is bobby and I am a talent software engineer working on AI/ML."]
Créez une liste d'objets Context pour transmettre vos données dans le flux.
data = [
Context(context=c)
for c in raw_input_context
]
[Facultatif] Si vous souhaitez utiliser une instruction personnalisée et/ou des exemples, créez un PromptTemplate .
from uniflow.op.prompt import PromptTemplate
guided_prompt = PromptTemplate(
instruction="Generate a one sentence summary based on the last context below. Follow the format of the examples below to include context and summary in the response",
few_shot_prompt=[
Context(
context="When you're operating on the maker's schedule, meetings are a disaster. A single meeting can blow a whole afternoon, by breaking it into two pieces each too small to do anything hard in. Plus you have to remember to go to the meeting. That's no problem for someone on the manager's schedule. There's always something coming on the next hour; the only question is what. But when someone on the maker's schedule has a meeting, they have to think about it.",
summary="Meetings disrupt the productivity of those following a maker's schedule, dividing their time into impractical segments, while those on a manager's schedule are accustomed to a continuous flow of tasks.",
),
],
)
Créez un objet Config à transmettre à l'objet Client .
config = TransformOpenAIConfig(
prompt_template=guided_prompt,
model_config=OpenAIModelConfig(
response_format={"type": "json_object"}
),
)
client = TransformClient(config)
Utilisez l'objet client pour exécuter le flux sur les données d'entrée.
output = client.run(data)
Traitez les données de sortie. Par défaut, la sortie LLM sera une liste de dictionnaires de sortie, un pour chaque Context transmis dans le flux. Chaque dict a une propriété response qui contient la réponse LLM, ainsi que toutes les erreurs. Par exemple, output[0]['output'][0] ressemblerait à ceci :
{
'response': [{'context': 'It was a sunny day and the sky color is blue.',
'question': 'What was the color of the sky?',
'answer': 'blue.'}],
'error': 'No errors.'
}
Pour plus d’exemples, consultez le dossier d’exemples.
Vous pouvez également configurer les flux en transmettant des configurations ou des arguments personnalisés à l'objet Config si vous souhaitez affiner davantage des paramètres spécifiques tels que le modèle LLM, le nombre de threads, la température, etc.
Chaque configuration possède les paramètres suivants :
| Paramètre | Taper | Description |
|---|---|---|
prompt_template | PromptTemplate | Modèle à utiliser pour l'invite guidée. |
num_threads | int | Le nombre de threads à utiliser pour le flux. |
model_config | ModelConfig | La configuration à transmettre au modèle. |
Vous pouvez configurer davantage le model_config en transmettant l'une des Model Configs avec des paramètres personnalisés.
Le Model Config est une configuration qui est transmise à l'objet Config de base et détermine quel modèle LLM est utilisé et possède des paramètres spécifiques au modèle LLM.
La configuration de base s'appelle ModelConfig et possède les paramètres suivants :
| Paramètre | Taper | Défaut | Description |
|---|---|---|---|
model_name | str | gpt-3.5-turbo-1106 | Site OpenAI |
OpenAIModelConfig hérite de ModelConfig et possède les paramètres supplémentaires suivants :
| Paramètre | Taper | Défaut | Description |
|---|---|---|---|
num_calls | int | 1 | Le nombre d'appels à effectuer vers l'API OpenAI. |
temperature | flotter | 1,5 | La température à utiliser pour l'API OpenAI. |
response_format | Dict[str, str] | {"type": "texte"} | Le format de réponse à utiliser pour l'API OpenAI. Peut être "texte" ou "json" |
Le HuggingfaceModelConfig hérite du ModelConfig , mais remplace le paramètre model_name pour utiliser le modèle mistralai/Mistral-7B-Instruct-v0.1 par défaut.
| Paramètre | Taper | Défaut | Description |
|---|---|---|---|
model_name | str | mistralai/Mistral-7B-Instruct-v0.1 | Site Câlins Visage |
batch_size | int | 1 | La taille du lot à utiliser pour l'API Hugging Face. |
Le LMQGModelConfig hérite du ModelConfig , mais remplace le paramètre model_name pour utiliser le modèle lmqg/t5-base-squad-qg-ae par défaut.
| Paramètre | Taper | Défaut | Description |
|---|---|---|---|
model_name | str | lmqg/t5-base-squad-qg-ae | Site Câlins Visage |
batch_size | int | 1 | Taille du lot à utiliser pour l'API LMQG. |
Voici un exemple de la façon de transmettre une configuration personnalisée à l'objet Client :
from uniflow.flow.client import TransformClient
from uniflow.flow.config import TransformOpenAIConfig, OpenAIModelConfig
from uniflow.op.prompt import Context
contexts = ["It was a sunny day and the sky color is blue.", "My name is bobby and I am a talent software engineer working on AI/ML."]
data = [
Context(
context=c
)
for c in contexts
]
config = OpenAIConfig(
num_threads=2,
model_config=OpenAIModelConfig(
model_name="gpt-4",
num_calls=2,
temperature=0.5,
),
)
client = TransformClient(config)
output = client.run(data)
Comme vous pouvez le voir, nous transmettons des paramètres personnalisés à OpenAIModelConfig aux configurations OpenAIConfig en fonction de nos besoins.