evidently
v0.4.40
Un framework open source pour évaluer, tester et surveiller les systèmes basés sur ML et LLM.

Documents | Communauté Discorde | Blogue | Twitter | Évidemment Cloud
Évidemment 0.4.25 . Évaluation LLM -> Tutoriel
Il s’agit évidemment d’une bibliothèque Python open source pour l’évaluation et l’observabilité ML et LLM. Il permet d'évaluer, de tester et de surveiller les systèmes et les pipelines de données basés sur l'IA, de l'expérimentation à la production.
Évidemment, c'est très modulaire. Vous pouvez commencer par des évaluations ponctuelles à l'aide Reports ou Test Suites en Python ou bénéficier d'un service Dashboard de surveillance en temps réel.
Les rapports calculent diverses données, mesures de qualité ML et LLM. Vous pouvez commencer avec des préréglages ou les personnaliser.
| Rapports |
|---|
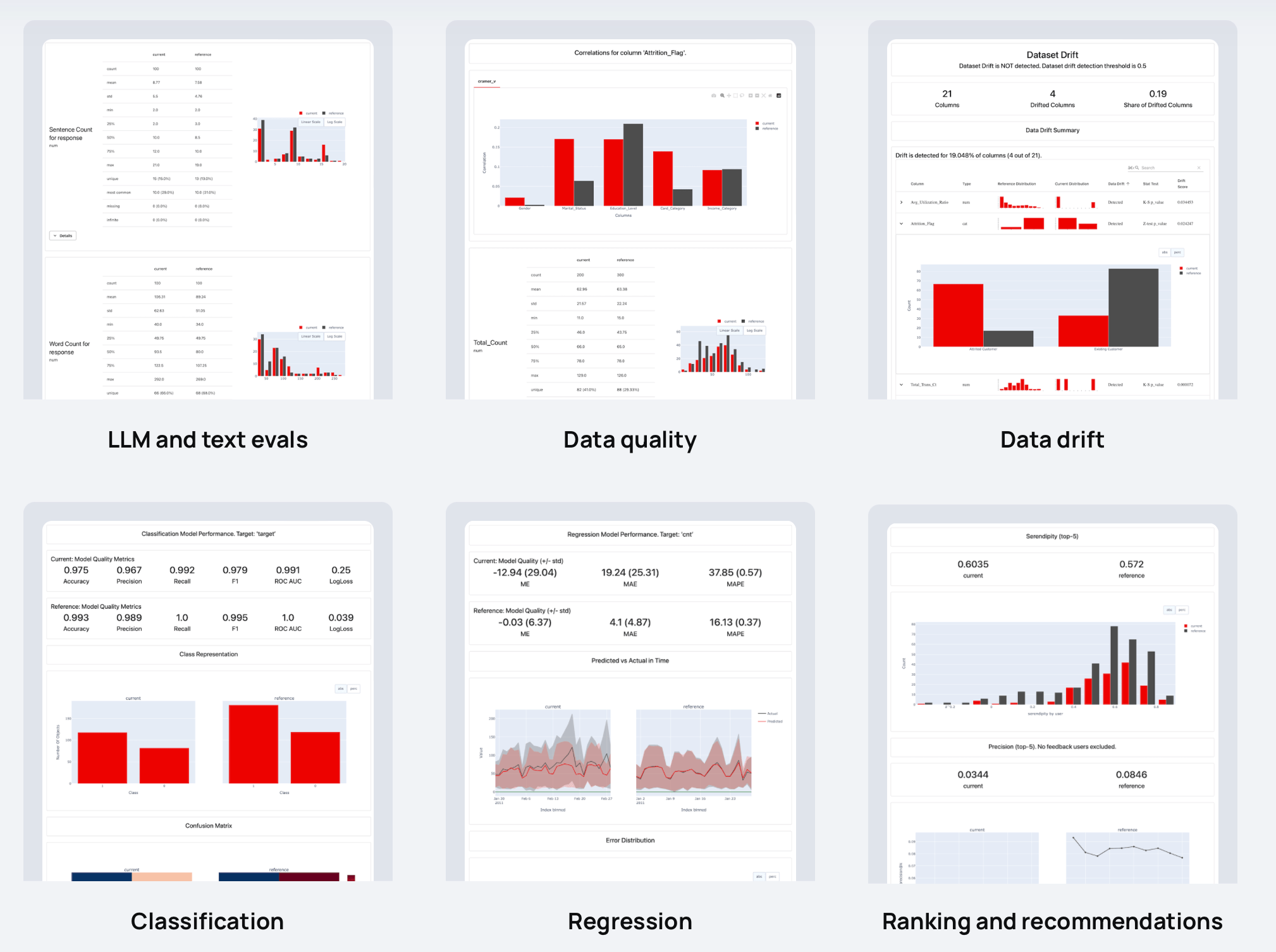 |
Les suites de tests vérifient les conditions définies sur les valeurs de métriques et renvoient un résultat de réussite ou d'échec.
gt (supérieur à), lt (inférieur à), etc.| Suite de tests |
|---|
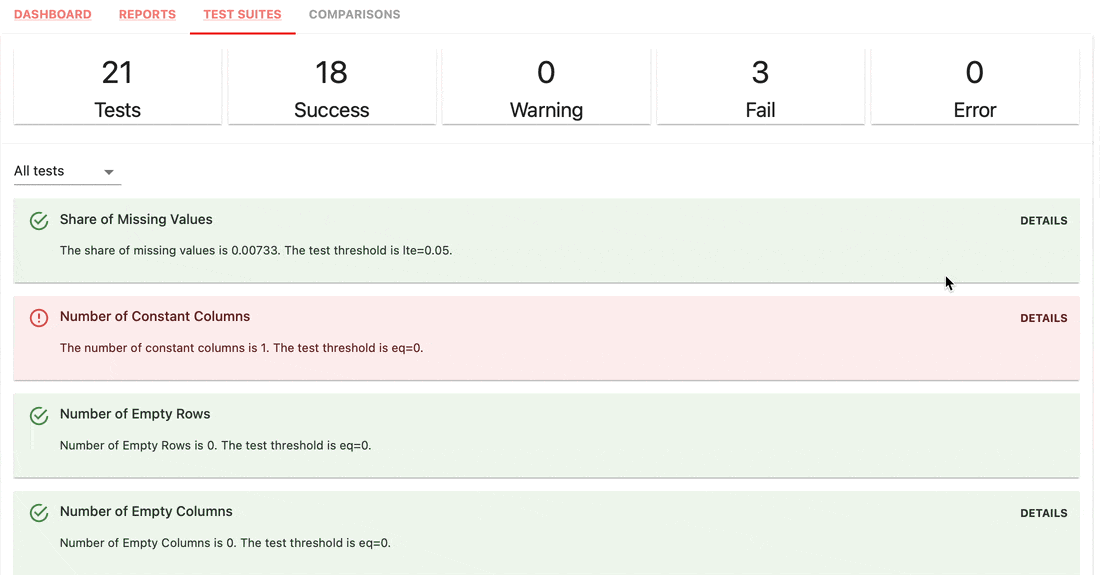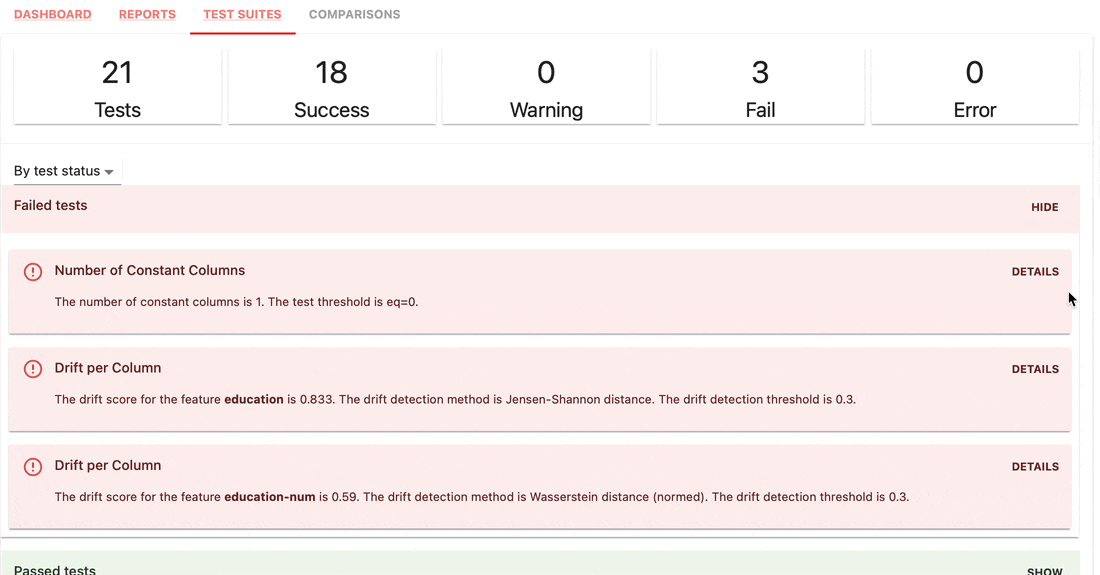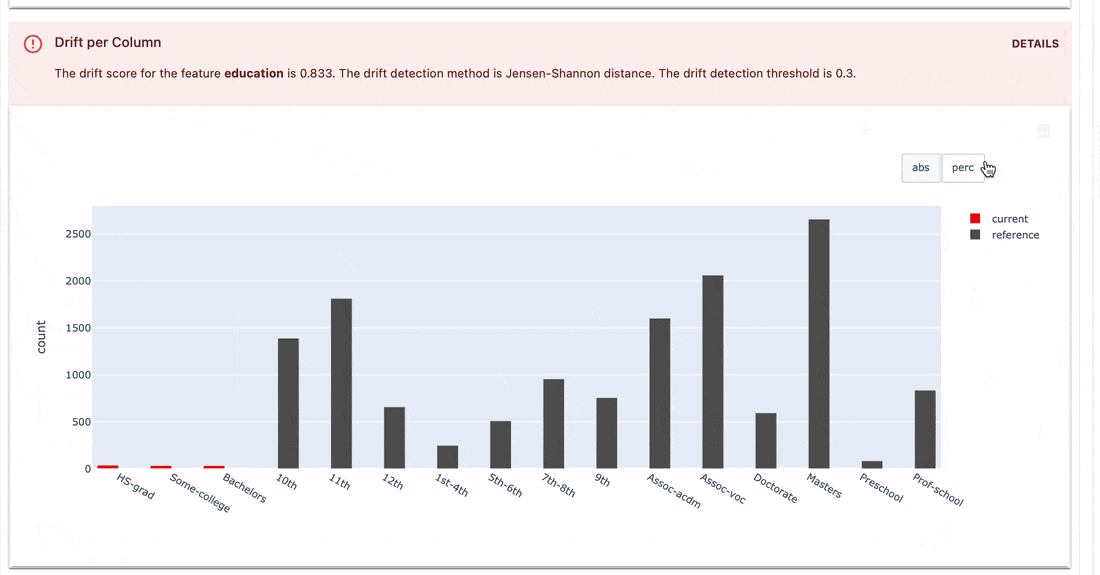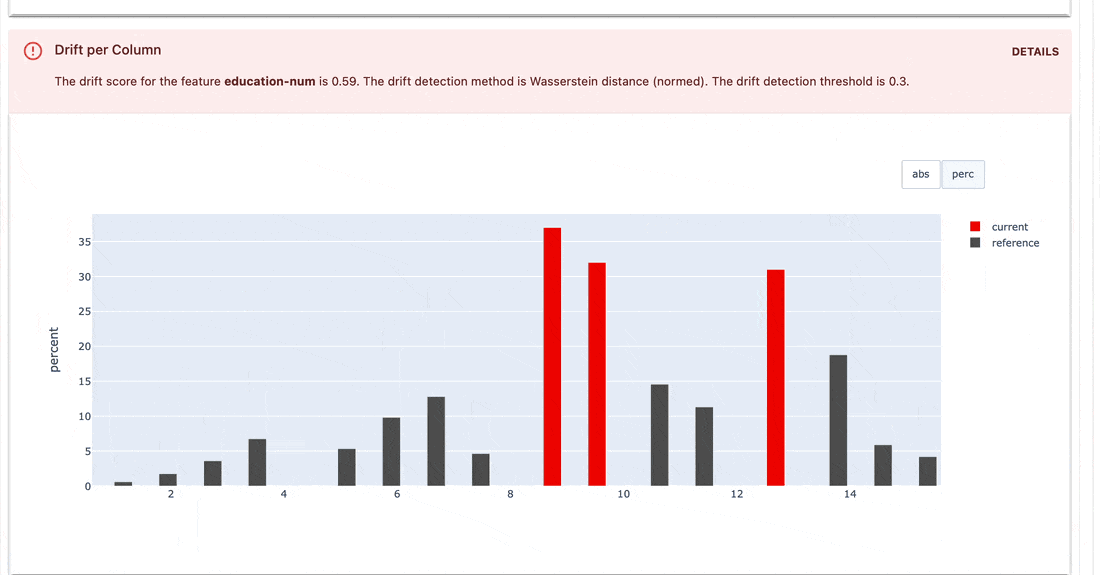 |
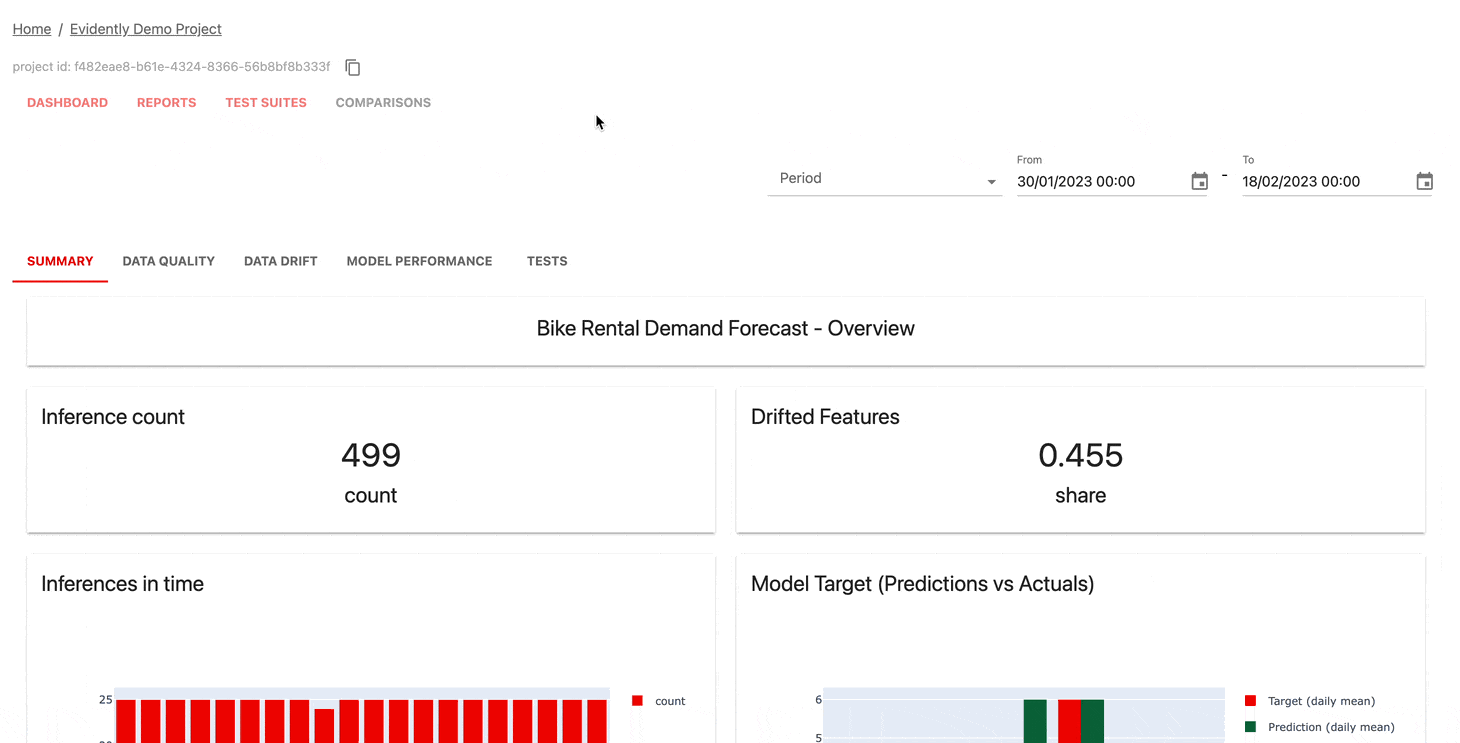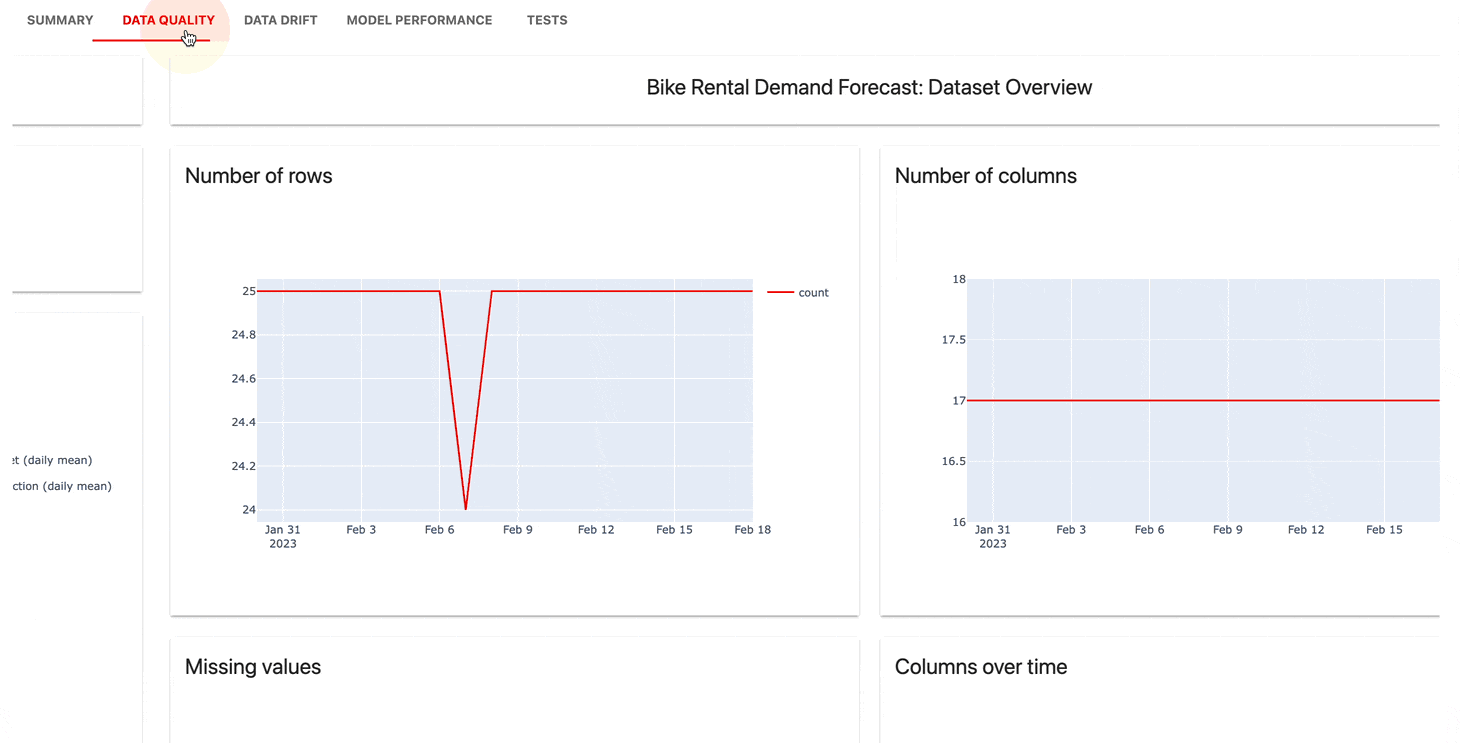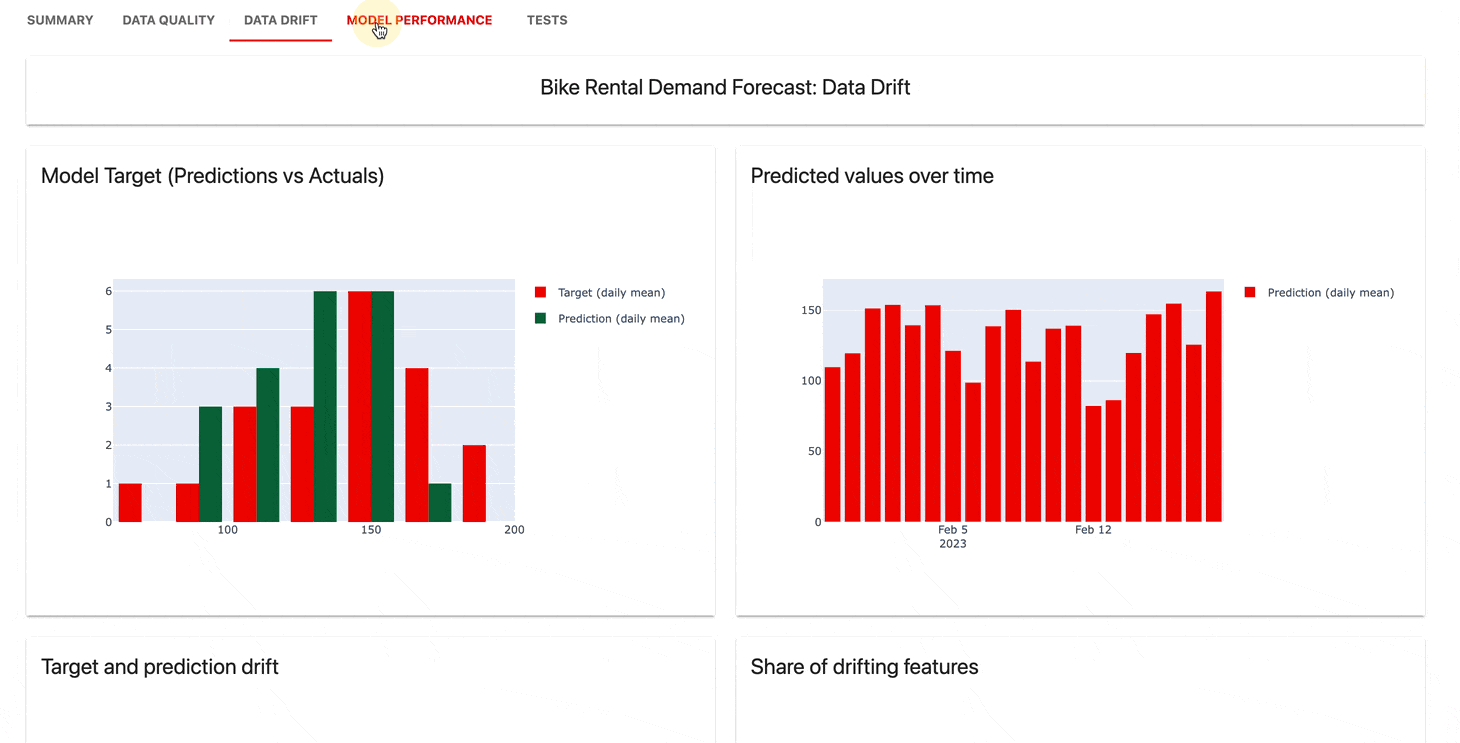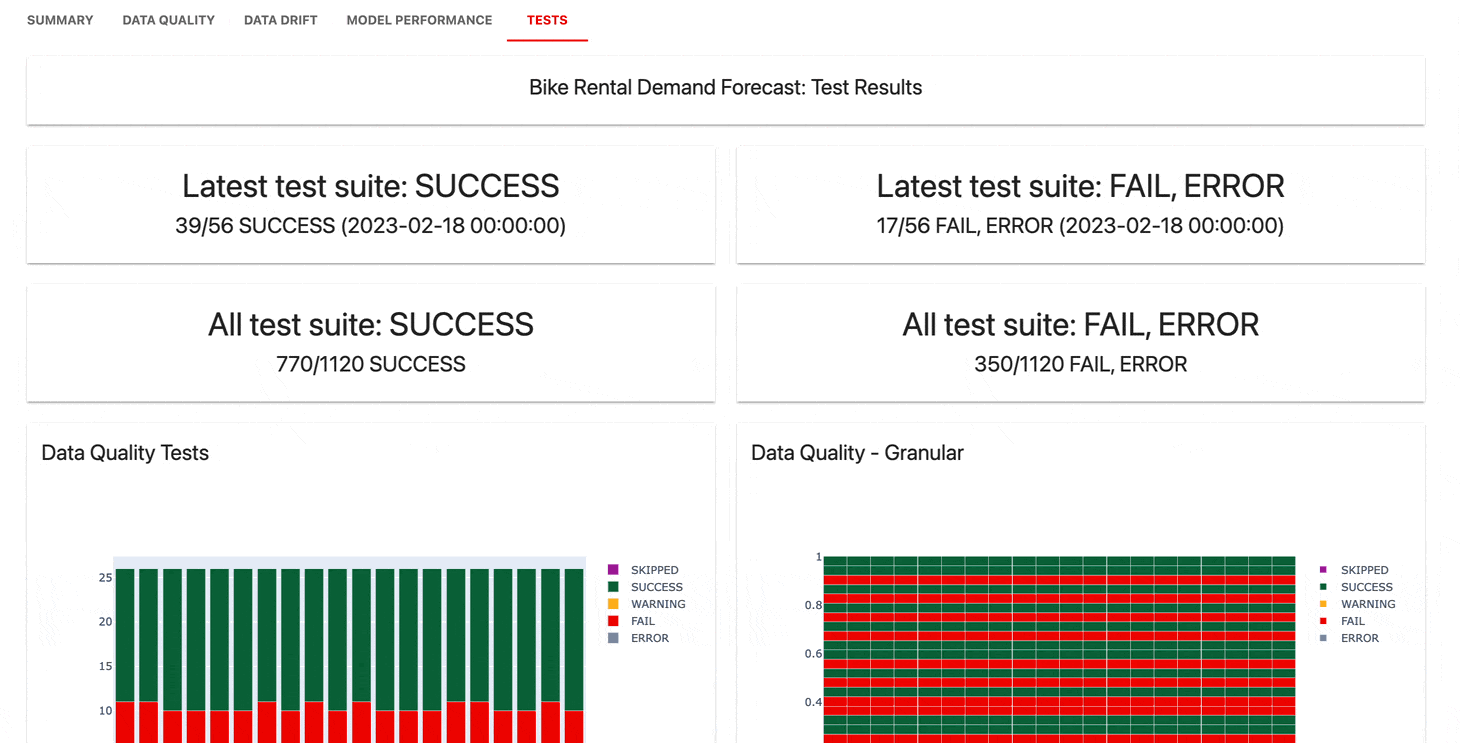
Le service de surveillance de l'interface utilisateur permet de visualiser les métriques et les résultats des tests au fil du temps.
Vous pouvez choisir :
Évidemment, Cloud offre un niveau gratuit généreux et des fonctionnalités supplémentaires telles que la gestion des utilisateurs, les alertes et les évaluations sans code.
| Tableau de bord |
|---|
 |
Il est évidemment disponible sous forme de package PyPI. Pour l'installer à l'aide du gestionnaire de packages pip, exécutez :
pip install evidentlyPour installer Evidemment à l'aide du programme d'installation de conda, exécutez :
conda install -c conda-forge evidentlyIl s’agit d’un simple Hello World. Consultez les didacticiels pour en savoir plus : données tabulaires ou évaluation LLM.
Importez la suite de tests , le préréglage d'évaluation et l'ensemble de données tabulaires de jouets.
import pandas as pd
from sklearn import datasets
from evidently . test_suite import TestSuite
from evidently . test_preset import DataStabilityTestPreset
iris_data = datasets . load_iris ( as_frame = True )
iris_frame = iris_data . frame Divisez le DataFrame en référence et actuel. Exécutez la suite de tests de stabilité des données qui générera automatiquement des contrôles sur les plages de valeurs des colonnes, les valeurs manquantes, etc. à partir de la référence. Obtenez le résultat dans le notebook Jupyter :
data_stability = TestSuite ( tests = [
DataStabilityTestPreset (),
])
data_stability . run ( current_data = iris_frame . iloc [: 60 ], reference_data = iris_frame . iloc [ 60 :], column_mapping = None )
data_stabilityVous pouvez également enregistrer un fichier HTML. Vous devrez l'ouvrir à partir du dossier de destination.
data_stability . save_html ( "file.html" )Pour obtenir le résultat au format JSON :
data_stability . json ()Vous pouvez choisir d'autres préréglages, des tests individuels et définir des conditions.
Importez le rapport , le préréglage d'évaluation et l'ensemble de données tabulaires de jouets.
import pandas as pd
from sklearn import datasets
from evidently . report import Report
from evidently . metric_preset import DataDriftPreset
iris_data = datasets . load_iris ( as_frame = True )
iris_frame = iris_data . frame Exécutez le rapport de dérive des données qui comparera les distributions de colonnes entre current et reference :
data_drift_report = Report ( metrics = [
DataDriftPreset (),
])
data_drift_report . run ( current_data = iris_frame . iloc [: 60 ], reference_data = iris_frame . iloc [ 60 :], column_mapping = None )
data_drift_reportEnregistrez le rapport au format HTML. Vous devrez ensuite l'ouvrir à partir du dossier de destination.
data_drift_report . save_html ( "file.html" )Pour obtenir le résultat au format JSON :
data_drift_report . json ()Vous pouvez choisir d'autres préréglages et métriques individuelles, y compris des évaluations LLM pour les données textuelles.
Cela lance un projet de démonstration dans l’interface utilisateur d’Evidemment. Consultez les didacticiels pour l’auto-hébergement ou évidemment Cloud.
Étape recommandée : créez un environnement virtuel et activez-le.
pip install virtualenv
virtualenv venv
source venv/bin/activate
Après avoir installé Evidently ( pip install evidently ), exécutez l'interface utilisateur d'Evidemment avec les projets de démonstration :
evidently ui --demo-projects all
Accédez au service Evidemment UI dans votre navigateur. Accédez au localhost:8000 .
A évidemment plus de 100 évaluations intégrées. Vous pouvez également en ajouter des personnalisés. Chaque métrique dispose d'une visualisation facultative : vous pouvez l'utiliser dans Reports , Test Suites ou tracer sur un Dashboard .
Voici des exemples de choses que vous pouvez vérifier :
| ? Descripteurs de texte | Résultats du LLM |
| Longueur, sentiment, toxicité, langage, symboles spéciaux, correspondances d'expressions régulières, etc. | Similarité sémantique, pertinence de la récupération, qualité du résumé, etc. avec des évaluations basées sur des modèles et des LLM. |
| ? Qualité des données | Dérive de la distribution des données |
| Valeurs manquantes, doublons, plages min-max, nouvelles valeurs catégorielles, corrélations, etc. | Plus de 20 tests statistiques et mesures de distance pour comparer les changements dans la distribution des données. |
| Classification | ? Régression |
| Exactitude, précision, rappel, ROC AUC, matrice de confusion, biais, etc. | MAE, ME, RMSE, distribution des erreurs, normalité des erreurs, biais d'erreur, etc. |
| ? Classement (y compris RAG) | ? Recommandations |
| NDCG, MAP, MRR, taux de réussite, etc. | Sérendipité, nouveauté, diversité, biais de popularité, etc. |
Nous apprécions les contributions ! Lisez le Guide pour en savoir plus.
Pour plus d’informations, reportez-vous à une documentation complète. Vous pouvez commencer par les tutoriels :
Voir plus d'exemples dans la documentation.
Explorez les guides pratiques pour comprendre les fonctionnalités spécifiques d’Evidemment.
Si vous souhaitez discuter et vous connecter, rejoignez notre communauté Discord !


