gen ai document sumarization
1.0.0
Ce projet explore le potentiel des modèles d'IA génératifs open source, en particulier ceux basés sur l'architecture Transformer, pour automatiser la synthèse du contenu des documents. L'objectif est d'évaluer et d'appliquer des modèles d'IA générative existants pour analyser, comprendre le contexte et générer des résumés pour les documents non structurés.
Pour y parvenir, j'ai affiné deux modèles importants : t5-small et facebook/bart-base, en me concentrant sur l'amélioration de leurs performances de synthèse.
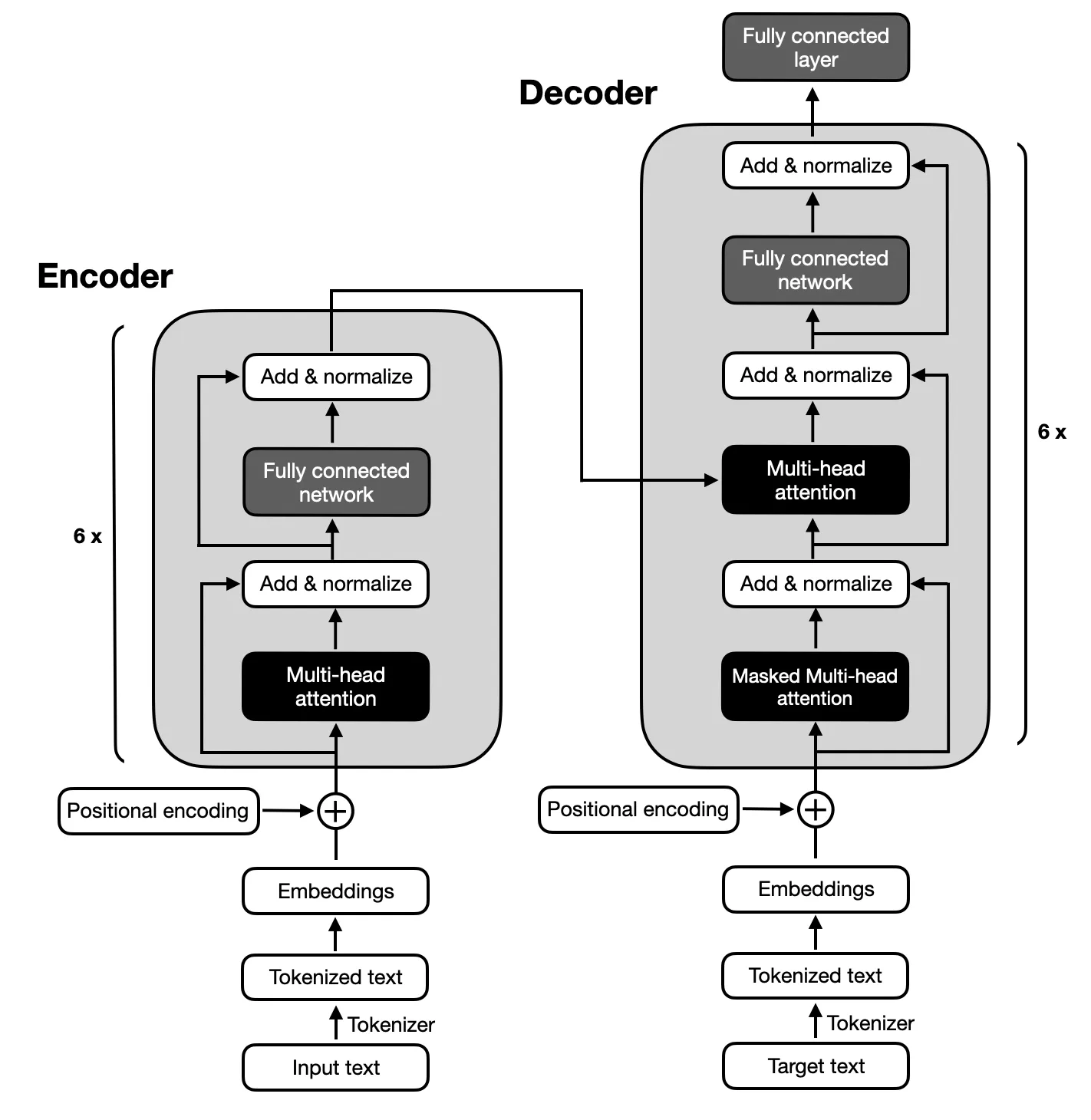
L'accent est mis sur les modèles d'encodeur-décodeur suivant l'architecture proposée par les Transformers originaux en raison du mappage complexe entre les séquences d'entrée et de sortie requis pour le résumé du texte. Les modèles codeur-décodeur sont capables de capturer les relations au sein de ces séquences, ce qui les rend adaptés à cette tâche.
Assurez-vous que Python 3.x est installé sur votre système. Suivez ensuite les étapes ci-dessous pour configurer votre environnement :
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.pyLe projet comprend six phases principales :
L'ensemble de données utilisé pour affiner les modèles T5 et BART était le Big Patent Dataset, composé de 1,3 million de documents de brevet américains ainsi que de leurs résumés abstraits rédigés par des humains. Chaque document de cet ensemble de données est classé sous un code de classification coopérative des brevets (CPC), couvrant un large éventail de sujets allant des nécessités humaines à la physique et à l'électricité. Cette diversité garantit que les modèles rencontrent une grande variété d'utilisations linguistiques et de jargon technique, ce qui est crucial pour développer une capacité de synthèse robuste.
Le Big Patent Dataset a été choisi en raison de sa pertinence par rapport à l'objectif du projet consistant à résumer des documents complexes. Les brevets sont intrinsèquement détaillés et techniques, ce qui en fait un défi idéal pour tester la capacité des modèles à condenser l'information tout en préservant le contenu et le contexte de base. Le format structuré de l'ensemble de données et la présence de résumés de haute qualité constituent une base solide pour la formation et l'évaluation des performances des modèles dans la génération de résumés précis et cohérents.
Les performances des modèles ont été évaluées à l'aide de la métrique ROUGE, mettant l'accent sur leur capacité à générer des résumés étroitement alignés sur les résumés rédigés par des humains. Les modèles BART et T5 ont été affinés à l'aide du Big Patent Dataset, en mettant l'accent sur l'obtention d'un résumé des résumés de haute qualité.
| Métrique | Valeur |
|---|---|
| Perte d'évaluation (perte d'évaluation) | 1,9244 |
| Rouge-1 | 0,5007 |
| Rouge-2 | 0,2704 |
| Rouge-L | 0,3627 |
| Rouge-Lsum | 0,3636 |
| Durée moyenne d'une génération (Gen Len) | 122.1489 |
| Durée d'exécution (secondes) | 1459.3826 |
| Échantillons par seconde | 1.312 |
| Pas par seconde | 0,164 |
| Métrique | Valeur |
|---|---|
| Perte d'évaluation (perte d'évaluation) | 1,9984 |
| Rouge-1 | 0,503 |
| Rouge-2 | 0,286 |
| Rouge-L | 0,3813 |
| Rouge-Lsum | 0,3813 |
| Durée moyenne d'une génération (Gen Len) | 151.918 |
| Durée d'exécution (secondes) | 714.4344 |
| Échantillons par seconde | 2.679 |
| Pas par seconde | 0,336 |


