langchain opensearch rag
1.0.0
Créez une collection Amazon OpenSearch Serverless (tapez Recherche vectorielle et choisissez l'option Création facile ) - documentation.
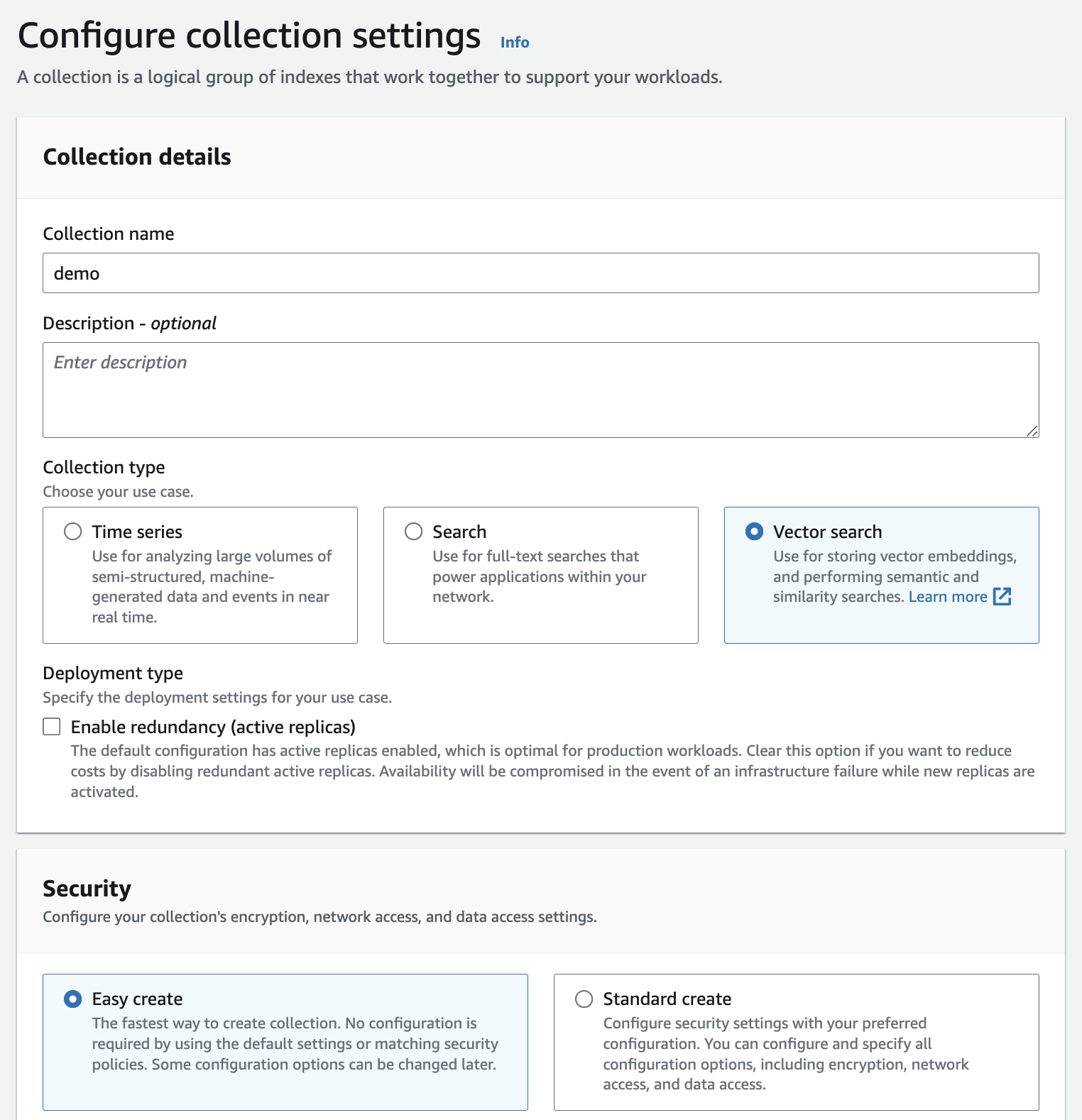
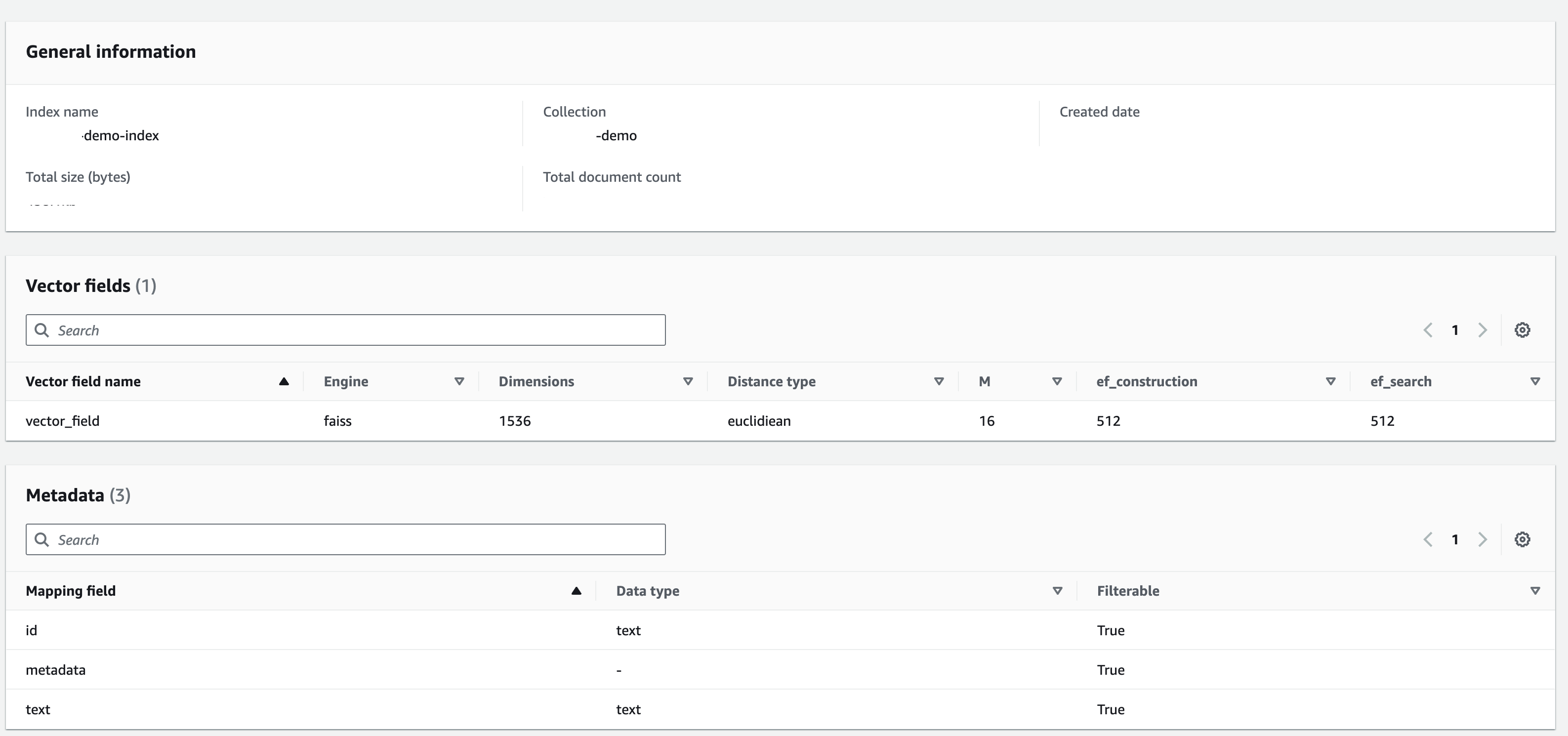
Créez un index avec la configuration ci-dessous :
Téléchargez la lettre aux actionnaires d'Amazon 2022 et placez-la dans le même répertoire.
Créez un fichier .env et fournissez les informations suivantes sur votre configuration Amazon OpenSearch :
opensearch_index_name= ' <enter name> '
opensearch_url= ' <enter URL> '
engine= ' faiss '
vector_field= ' vector_field '
text_field= ' text '
metadata_field= ' metadata ' Assurez-vous d'avoir configuré Amazon Bedrock pour l'accès depuis votre machine locale. En outre, vous devez accéder au modèle d'intégration amazon.titan-embed-text-v1 et au modèle anthropic.claude-v2 dans Amazon Bedrock - suivez ces instructions pour plus de détails.
Charger des données PDF :
python3 -m venv myenv
source myenv/bin/activate
pip3 install -r requirements.txt
python3 load.pyVérifier les données dans la collection OpenSearch
streamlit run app_semantic_search.py --server.port 8080Vous pouvez poser des questions, telles que :
What is Amazon ' s doing in the field of generative AI?
What were the key challenges Amazon faced in 2022?
What were some of the important investments and initiatives mentioned in the letter? 
Dans un autre terminal :
source myenv/bin/activate
streamlit run app_rag.py --server.port 8081Vous pouvez poser des questions, telles que :
What is Amazon ' s doing in the field of generative AI?
What were the key challenges Amazon faced in 2022?
What were some of the important investments and initiatives mentioned in the letter? 


