JoyVASA
1.0.0
Xuyang Cao 1* Guoxin Wang 12* Sheng Shi 1* Jun Zhao 1 Yang Yao 1
Jintao Fei 1 Minyu Gao 1
1 JD Health International Inc. 2 Université du Zhejiang
L'animation de portraits audio a fait des progrès significatifs avec les modèles basés sur la diffusion, améliorant ainsi la qualité vidéo et la précision de la synchronisation labiale. Cependant, la complexité croissante de ces modèles a conduit à des inefficacités en matière de formation et d'inférence, ainsi qu'à des contraintes sur la longueur de la vidéo et la continuité inter-images. Dans cet article, nous proposons JoyVASA, une méthode basée sur la diffusion pour générer une dynamique faciale et un mouvement de la tête dans une animation faciale audio. Plus précisément, dans la première étape, nous introduisons un cadre de représentation faciale découplé qui sépare les expressions faciales dynamiques des représentations faciales statiques en 3D. Ce découplage permet au système de générer des vidéos plus longues en combinant n'importe quelle représentation faciale 3D statique avec des séquences de mouvements dynamiques. Ensuite, dans un deuxième temps, un transformateur de diffusion est entraîné pour générer des séquences de mouvements directement à partir de signaux audio, indépendamment de l'identité du personnage. Enfin, un générateur formé lors de la première étape utilise la représentation faciale 3D et les séquences de mouvements générées comme entrées pour restituer des animations de haute qualité. Grâce à la représentation faciale découplée et au processus de génération de mouvement indépendant de l'identité, JoyVASA s'étend au-delà des portraits humains pour animer des visages d'animaux de manière transparente. Le modèle est formé sur un ensemble de données hybrides de données privées chinoises et publiques anglaises, permettant une prise en charge multilingue. Les résultats expérimentaux valident l’efficacité de notre approche. Les travaux futurs se concentreront sur l'amélioration des performances en temps réel et l'affinement du contrôle de l'expression, élargissant ainsi les applications du cadre dans l'animation de portraits.
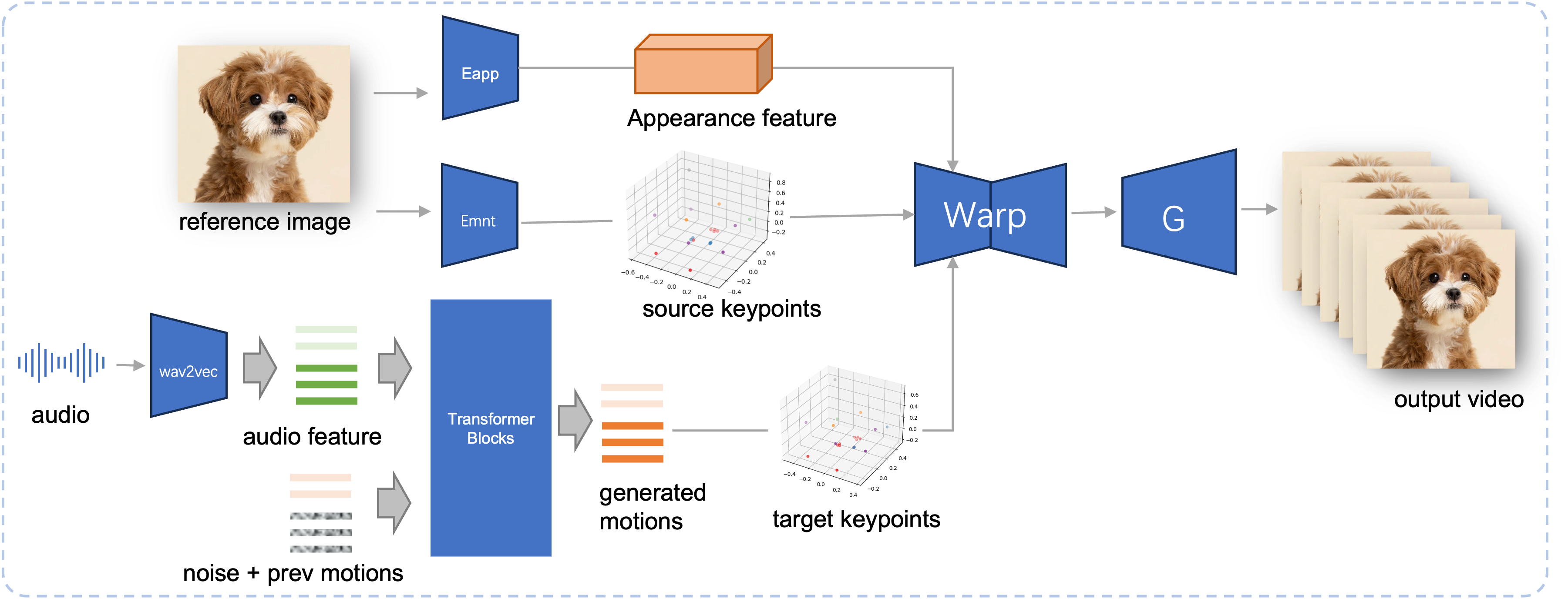
Pipeline d'inférence du JoyVASA proposé. À partir d'une image de référence, nous extrayons d'abord la fonction d'apparence faciale 3D à l'aide de l'encodeur d'apparence de LivePortrait, ainsi qu'une série de points clés 3D appris à l'aide de l'encodeur de mouvement. Pour la parole d'entrée, les caractéristiques audio sont initialement extraites à l'aide de l'encodeur wav2vec2. Les séquences de mouvements audio sont ensuite échantillonnées à l'aide d'un modèle de diffusion formé lors de la deuxième étape selon une fenêtre glissante. À l'aide des points clés 3D de l'image de référence et des séquences de mouvements cibles échantillonnées, les points clés cibles sont calculés. Enfin, la fonction d'apparence faciale 3D est déformée en fonction des points clés source et cible et rendue par un générateur pour produire la vidéo de sortie finale.
Configuration système requise :
Ubuntu :
Testé sur Ubuntu 20.04, Cuda 11.3
GPU testés : A100
Fenêtres :
Testé sur Windows 11, CUDA 12.1
GPU testés : GPU VRAM pour ordinateur portable RTX 4060 de 8 Go
Créer un environnement :
# 1. Créer un environnement de baseconda create -n joyvasa python=3.10 -y conda active joyvasa # 2. Installez exigencespip install -r exigences.txt# 3. Installez ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. Installez MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # égal à cd ../../../../../../../
Assurez-vous que git-lfs est installé et téléchargez tous les points de contrôle suivants sur pretrained_weights :
installer git lfs clone git https://huggingface.co/jdh-algo/JoyVASA
Nous prenons en charge deux types d'encodeurs audio, notamment wav2vec2-base et hubert-chinese.
Exécutez les commandes suivantes pour télécharger les poids pré-entraînés Hubert-Chinese :
installer git lfs clone git https://huggingface.co/TencentGameMate/chinese-hubert-base
Pour obtenir les poids pré-entraînés wav2vec2-base, exécutez les commandes suivantes :
installer git lfs clone git https://huggingface.co/facebook/wav2vec2-base-960h
Note
Le modèle de génération de mouvement avec l'encodeur wav2vec2 sera pris en charge ultérieurement.
# !pip install -U "huggingface_hub[cli]"huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
En vous référant à Liveportrait pour plus de méthodes de téléchargement.
pretrained_weights Le répertoire final pretrained_weights devrait ressembler à ceci :
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonNote
Le dossier TencentGameMate:chinese-hubert-base dans Windows doit être renommé chinese-hubert-base .
Animal:
python inference.py -r actifs/exemples/imgs/joyvasa_001.png -a actifs/exemples/audios/joyvasa_001.wav --animation_mode animal --cfg_scale 2.0
Humain:
python inference.py -r actifs/exemples/imgs/joyvasa_003.png -a actifs/exemples/audios/joyvasa_003.wav --animation_mode humain --cfg_scale 2.0
Vous pouvez modifier cfg_scale pour obtenir des résultats avec différentes expressions et poses.
Note
Une non-concordance entre le mode d'animation et l'image de référence peut entraîner des résultats incorrects.
Utilisez la commande suivante pour démarrer la démo Web :
application python.py
La démo sera créée sur http://127.0.0.1:7862.
Si vous trouvez notre travail utile, pensez à nous citer :
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}Nous tenons à remercier les contributeurs aux référentiels LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet et VBench, pour leur recherche ouverte et leur travail extraordinaire.


