Adding Private Data to LLMs
1.0.0
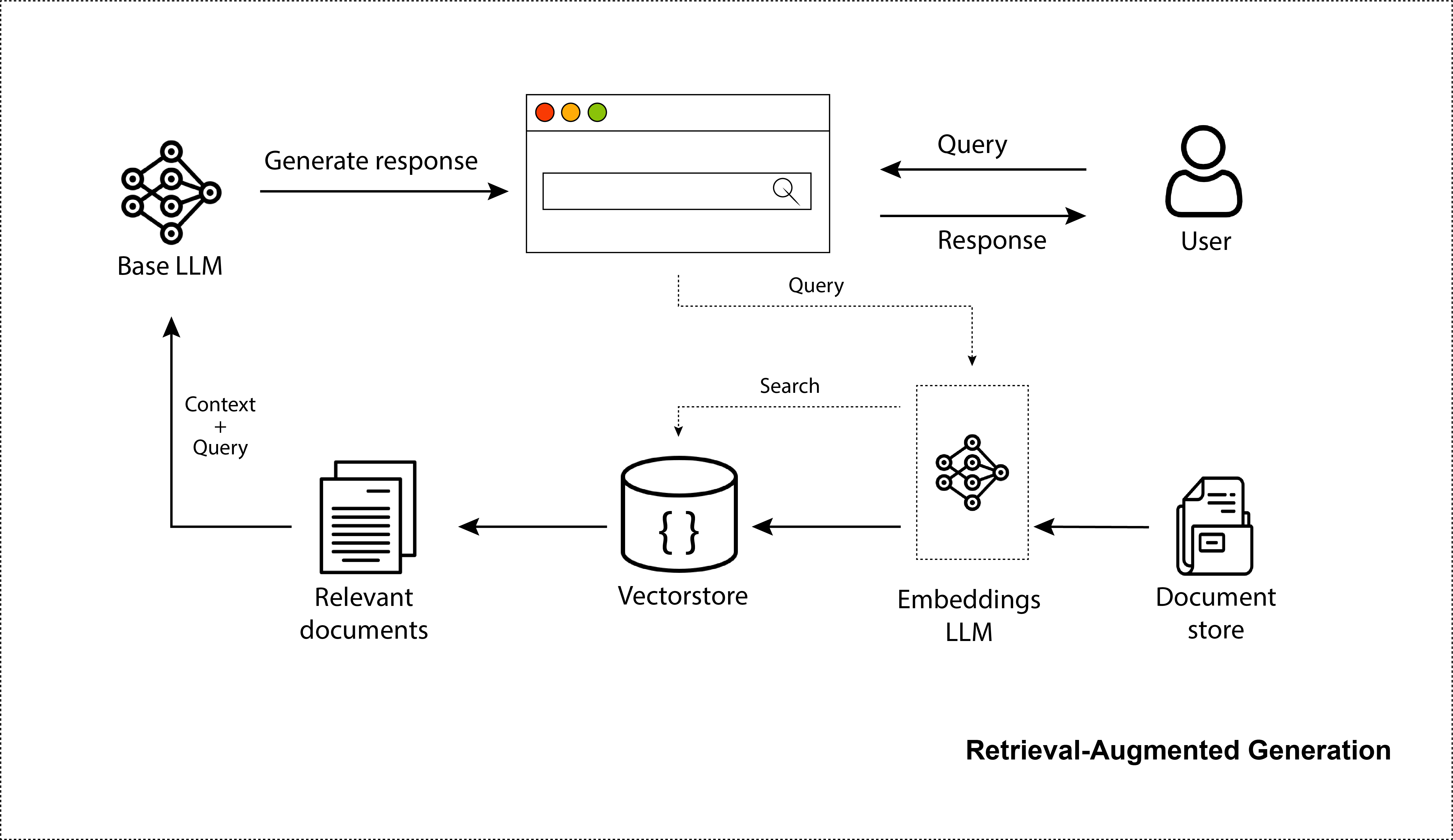
Les LLM ont stupéfié le monde par leur capacité à créer des images, du code et des dialogues réalistes. Sans aucun doute, ChatGPT a pris d’assaut le monde. Des millions de personnes l'utilisent. Mais bien qu’il soit idéal pour les connaissances générales, il ne connaît que les informations sur lesquelles il a été formé, à savoir les données Internet généralement disponibles avant 2021. Il ne connaît pas vos données privées et reste mal informé des sources de données récentes. Ainsi, pour les améliorer à cet égard, nous pouvons leur fournir les informations que nous avons récupérées lors d’une étape de recherche. Cela les rend plus factuels et donne une meilleure capacité à fournir au modèle des informations à jour, sans avoir besoin de recycler ces modèles massifs. C’est précisément ce qu’est un système LLM ou Retrieval-Augmented Generation (RAG). En effet, ce référentiel décrira précisément la création d'un système RAG et élucidera les étapes d'optimisation impliquées.
CHIFFON
Pile technologique
Installation
Liens utiles
Contact
LangChaîne
LamaIndex
Azure OpenAI
Gradio
Cloner le dépôt Github
clone git https://github.com/zekaouinoureddine/Adding-Private-Data-to-LLMs.git
Accédez au répertoire du projet et assurez-vous que Python 3 est installé, ainsi que les dépendances nécessaires.
cd Ajout de données privées aux LLM pip install -r exigences.txt
Exécutez l'application Gradio
python rag.py
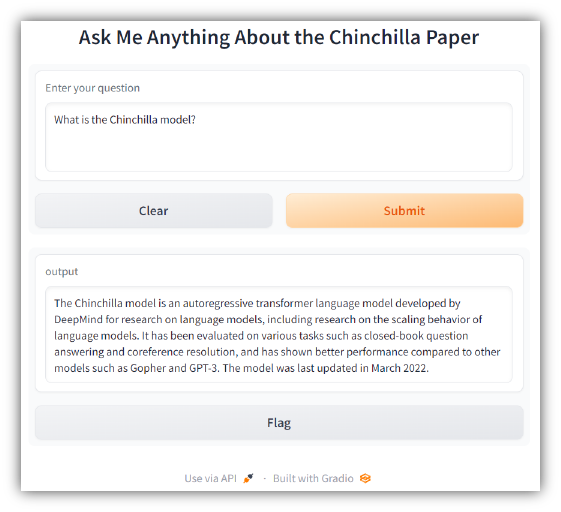
Visitez http://127.0.0.1:7860 sur votre ordinateur pour tester l'application. Vous devriez voir quelque chose comme ce qui suit :
| Blogue | Plateforme | Langue | Carnet de notes |
|---|---|---|---|
| Demandez vos propres données | Blogue Hiberus | ES | |
| Demandez vos propres données | Moyen | FR | |
| Demandez à vos pages Web | Blogue Hiberus | ES | |
| Demandez à vos pages Web | Moyen | FR |
Si vous l'aimez, donnez-lui un , puis suivez-moi sur :
LinkedIn : Nour Eddine ZEKAOUI
Twitter : @NZekaoui
Retour au sommet


