wikisearch
1.0.0
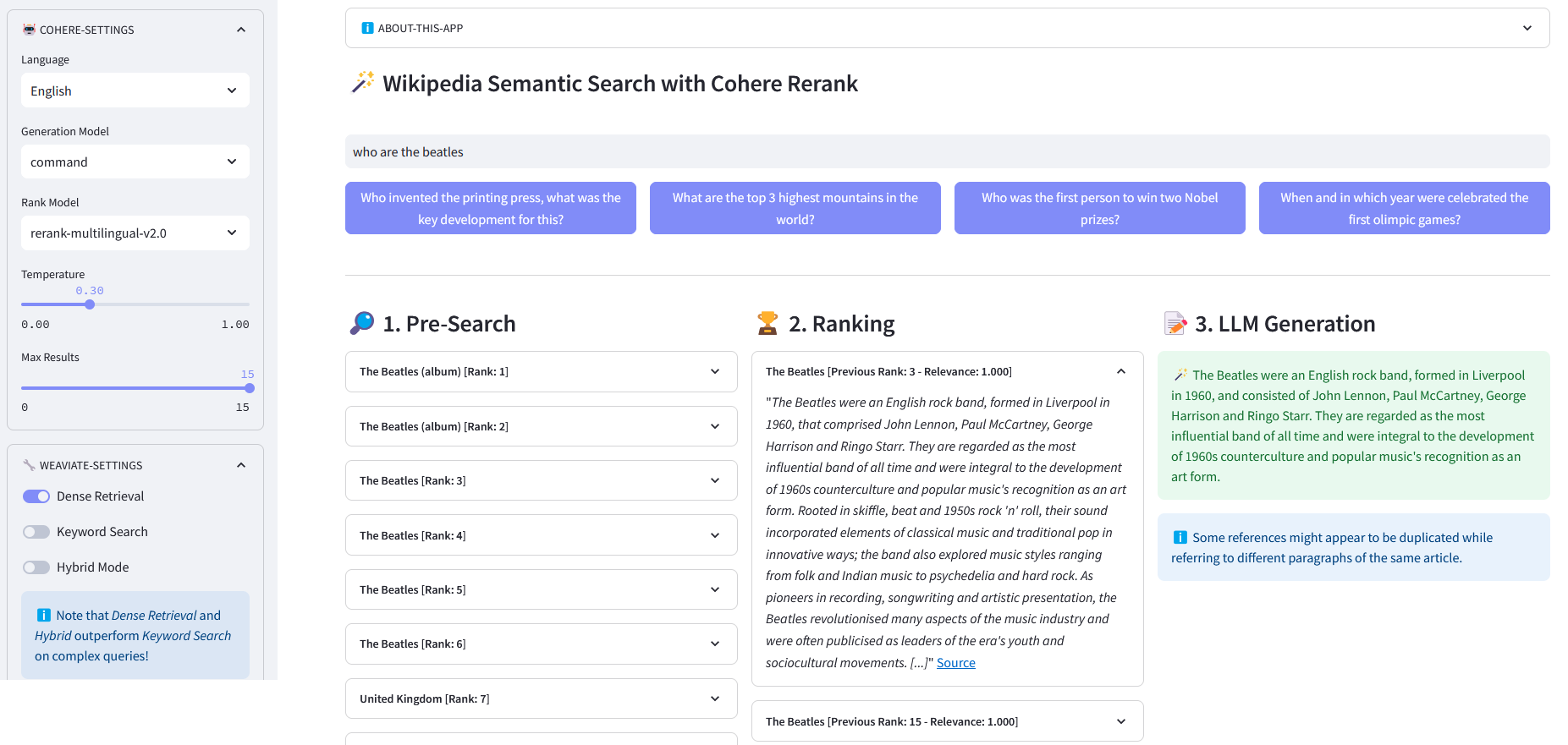
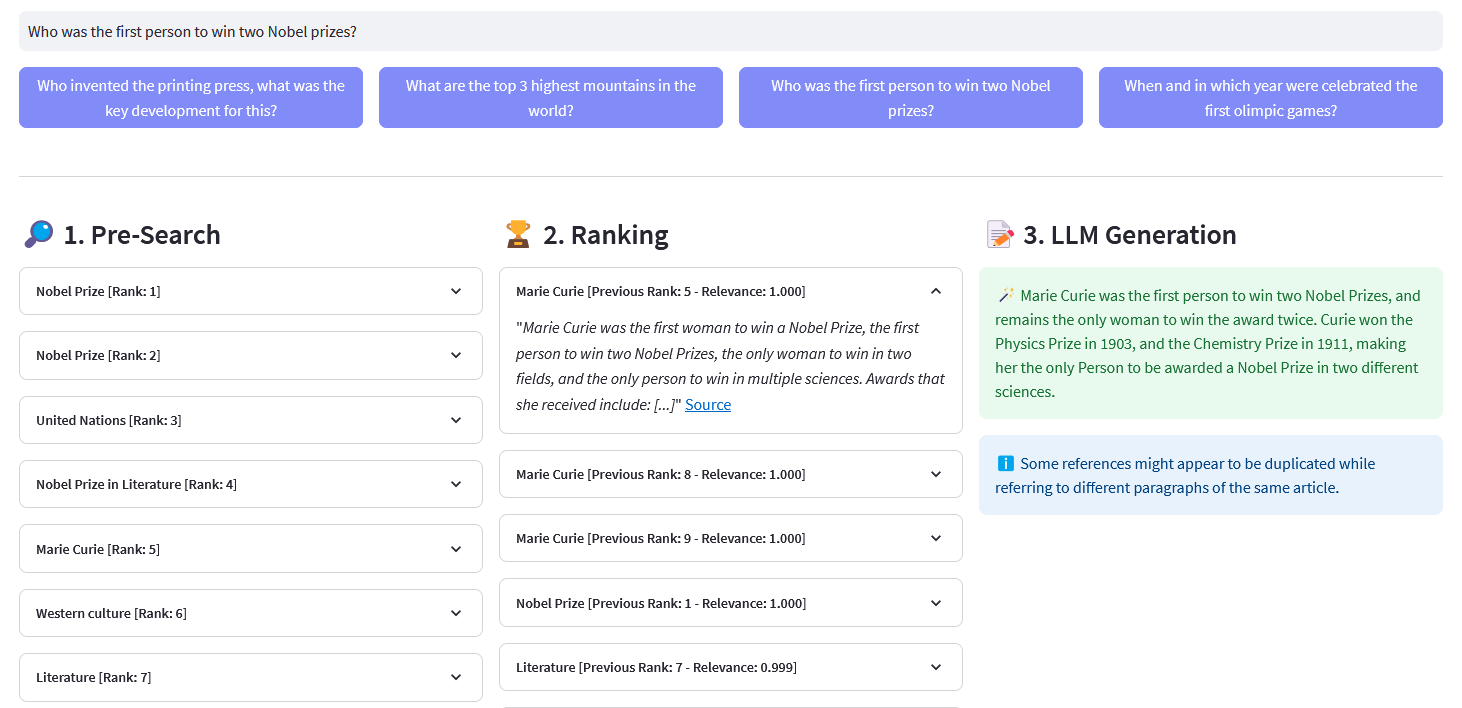
Application Streamlit pour la recherche sémantique multilingue sur plus de 10 millions de documents Wikipédia vectorisés dans les intégrations par Weaviate. Cette implémentation est basée sur le blog de Cohere « Using LLMs for Search » et son notebook correspondant. Il permet de comparer les performances de la recherche par mots clés , de la récupération dense et de la recherche hybride pour interroger l'ensemble de données Wikipédia. Il démontre en outre l'utilisation de Cohere Rerank pour améliorer la précision des résultats, et de Cohere Generate pour fournir une réponse basée sur lesdits résultats classés.
La recherche sémantique fait référence à des algorithmes de recherche qui prennent en compte l'intention et la signification contextuelle des expressions de recherche lors de la génération de résultats, plutôt que de se concentrer uniquement sur la correspondance des mots clés. Il fournit des résultats plus précis et pertinents en comprenant la sémantique, ou la signification, derrière la requête.
Une intégration est un vecteur (liste) de nombres à virgule flottante représentant des données telles que des mots, des phrases, des documents, des images ou de l'audio. Ladite représentation numérique capture le contexte, la hiérarchie et la similarité des données. Ils peuvent être utilisés pour des tâches en aval telles que la classification, le clustering, la détection des valeurs aberrantes et la recherche sémantique.
Les bases de données vectorielles, telles que Weaviate, sont spécialement conçues pour optimiser les capacités de stockage et d'interrogation pour les intégrations. En pratique, une base de données vectorielles utilise une combinaison de différents algorithmes qui participent tous à la recherche du voisin le plus proche (ANN). Ces algorithmes optimisent la recherche grâce au hachage, à la quantification ou à la recherche basée sur des graphiques.
Pré-recherche : pré-recherche sur les intégrations Wikipédia avec correspondance de mots clés , récupération dense ou recherche hybride :
Keyword Matching : il recherche les objets qui contiennent les termes de recherche dans leurs propriétés. Les résultats sont notés selon la fonction BM25F :
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" Exécute un mot-clé recherche (récupération clairsemée) sur les articles Wikipédia utilisant des intégrations stockées dans Weaviate Paramètres : - query (str) : La requête de recherche - lang (str, facultatif) : La langue des articles par défaut est 'en'. - top_n (int, facultatif) : Le nombre de meilleurs résultats à renvoyer est 10. Renvoie : - list : Liste des meilleurs articles basée sur la notation BM25F. ""logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_bm25(requête=requête)
.with_where(où_filter)
.with_limit(top_n)
.faire()
)retourner la réponse["data"]["Get"]["Articles"]Récupération dense : recherchez les objets les plus similaires à un texte brut (non vectorisé) :
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" Effectue une sémantique recherche (récupération dense) sur les articles Wikipédia utilisant des intégrations stockées dans Weaviate Paramètres : - query (str) : La requête de recherche - lang (str, facultatif) : La langue des articles. La langue par défaut est 'en'. - top_n (int, facultatif) : Le nombre de meilleurs résultats à renvoyer est 10. Renvoie : - list : Liste des meilleurs articles basée sur la similarité sémantique. ""logging.info("with_neartext()")nearText = {"concepts": [requête]
}where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_near_text(nearText)
.with_where(où_filter)
.with_limit(top_n)
.faire()
)retourner la réponse['data']['Get']['Articles']Recherche hybride : produit des résultats basés sur une combinaison pondérée des résultats d'une recherche par mot clé (bm25) et d'une recherche vectorielle.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" Effectue un hybride rechercher sur les articles Wikipédia en utilisant les intégrations stockées dans Weaviate. Paramètres : - query (str) : La requête de recherche - lang (str, facultatif) : La langue par défaut est. 'en'. - top_n (int, facultatif) : Le nombre de meilleurs résultats à renvoyer. Par défaut, c'est 10. Renvoie : - list : Liste des meilleurs articles basée sur la notation hybride """logging.info("with_hybrid()" )where_filter = {"path": ["lang"],"operator": "Equal", "valueString": lang}response = (self.weaviate.query.get("Articles", soi.WIKIPEDIA_PROPERTIES)
.with_hybrid(requête=requête)
.with_where(où_filter)
.with_limit(top_n)
.faire()
)retourner la réponse["data"]["Get"]["Articles"]ReRank : Cohere Rerank réorganise la pré-recherche en attribuant un score de pertinence à chaque résultat de pré-recherche en fonction de la requête d'un utilisateur. Par rapport à la recherche sémantique basée sur l'intégration, elle donne de meilleurs résultats de recherche, en particulier pour les requêtes complexes et spécifiques à un domaine.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, query, documents, top_n=10, model='rerank-english-v2.0') -> dict:""" Reclasse une liste de réponses à l'aide de l'API de reclassement de Cohere. Paramètres : - query (str) : La requête de recherche. - documents (list) : Liste des documents à reclasser. - top_n (int, facultatif) : Le nombre de résultats les mieux classés à renvoyer par défaut est 10. - model : Le modèle à utiliser pour le reclassement est 'rerank-english-v2.0'. dict : documents reclassés à partir de l'API de Cohere """return self.cohere.rerank(query=query, documents=documents, top_n=top_n, model=model)
Source : Cohérer
Génération de réponses : Cohere Generate compose une réponse basée sur les résultats classés.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, temperature=0.2, model="command", lang="english") -> list:prompt = f""" Utilisez les informations fournies ci-dessous pour répondre aux questions à la fin. / Incluez des faits curieux ou pertinents extraits du contexte. / Générez la réponse dans la langue de la requête. Si vous ne pouvez pas déterminez la langue de la requête, utilisez {lang}. / Si la réponse à la question n'est pas contenue dans les informations fournies, générez "La réponse n'est pas dans le contexte". --- Informations contextuelles : {contexte} --- Question. : {query} """return self.cohere.generate(prompt=prompt,num_generations=1,max_tokens=1000,temperature=temperature,model=model,
)Clonez le dépôt :
[email protected]:dcarpintero/wikisearch.git
Créez et activez un environnement virtuel :
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
Installer les dépendances :
pip install -r requirements.txt
Lancer une application Web
streamlit run ./app.py
Application Web de démonstration déployée sur Streamlit Cloud et disponible sur https://wikisearch.streamlit.app/
Cohérer le reclassement
Nuage rationalisé
Les archives d'intégration : des millions d'intégrations d'articles Wikipédia dans de nombreuses langues
Utilisation des LLM pour la recherche avec récupération dense et reclassement
Bases de données vectorielles
Recherche de vecteurs Weaviate
Recherche Weaviate BM25
Recherche hybride Weaviate


