bedrock agents infer models
1.0.0
Ce projet sert de référence aux développeurs pour étendre leurs cas d'utilisation à divers grands modèles de langage (LLM) à l'aide des agents Amazon Bedrock. L’objectif est de montrer le potentiel de l’exploitation de plusieurs modèles sur Bedrock pour créer des réponses en chaîne qui s’adaptent à divers scénarios. En plus de générer des sorties textuelles, cette application prend également en charge la création et l'examen d'images à l'aide de la génération d'images et de modèles texte-image. Cette fonctionnalité étendue améliore la polyvalence de l'application, la rendant adaptée à des cas d'utilisation plus créatifs et visuels.
Pour ceux qui préfèrent une approche Infrastructure-as-Code (IaC), nous fournissons également un modèle AWS CloudFormation qui configure les composants principaux tels qu'un agent Amazon Bedrock, un compartiment S3 et une fonction Lambda. Si vous préférez déployer ce projet via AWS CloudFormation, veuillez vous référer au guide de l'atelier ici.
Alternativement, ce README vous guidera à travers le processus étape par étape pour installer et configurer manuellement les agents Amazon Bedrock via la console AWS, vous donnant la flexibilité d'expérimenter les derniers modèles et de libérer pleinement le potentiel des agents Bedrock.
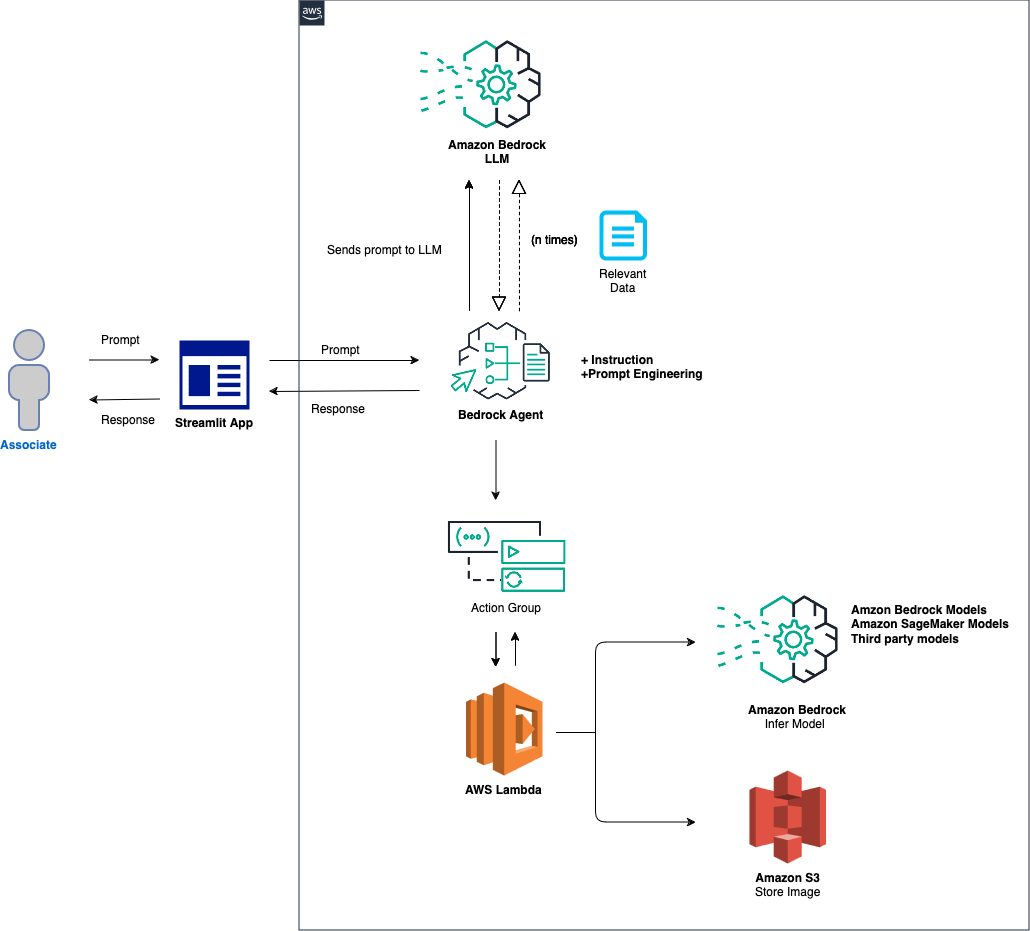
La présentation générale de la solution est la suivante :
Configuration de l'agent et de l'environnement : la solution commence par la configuration d'un agent Amazon Bedrock, d'une fonction AWS Lambda et d'un compartiment Amazon S3. Cette étape établit les bases de l'interaction du modèle et de la gestion des données, en préparant le système à recevoir et à traiter les invites d'une application frontale. Traitement des invites et inférence de modèle : lorsqu'une invite est reçue de l'application frontale, l'agent Bedrock évalue et distribue l'invite, ainsi que l'ID de modèle spécifié, à la fonction Lambda à l'aide du mécanisme de groupe d'actions. Cette étape exploite le schéma API du groupe d'action pour une gestion précise des paramètres, facilitant ainsi une inférence de modèle efficace basée sur l'invite de saisie. Gestion des données et génération de réponses : pour les tâches impliquant une conversion d'image en texte ou de texte en image, la fonction Lambda interagit avec le compartiment S3 pour effectuer les opérations de lecture ou d'écriture nécessaires sur les images. Cette étape assure la gestion dynamique du contenu multimédia, aboutissant à la génération de réponses ou de transformations dictées par l'invite initiale.
Dans les sections suivantes, nous vous guiderons à travers :
AWS SAM (Serverless Application Model) est un framework open source qui vous aide à créer des applications sans serveur sur AWS. Il simplifie le déploiement, la gestion et la surveillance des ressources sans serveur telles qu'AWS Lambda, Amazon API Gateway, Amazon DynamoDB, etc. Voici un guide complet sur la façon de configurer et d'utiliser AWS SAM.
Le Framework simplifie le processus de création, de déploiement et de gestion d'applications sans serveur en éliminant les complexités de l'infrastructure cloud. Il fournit un moyen unifié de définir et de gérer vos ressources sans serveur à l'aide d'un fichier de configuration et d'un ensemble de commandes.
Créez un nouveau projet sans serveur avec un modèle Python. Dans votre terminal, exécutez : cd infer-models Puis exécutez sans serveur 
Cela lancera le processus de création de projet interactif du Serverless Framework. Plusieurs options vous seront proposées : Choisissez "Créer une nouvelle application sans serveur". Sélectionnez le modèle « aws-python3 » et fournissez « infer-models » comme nom de votre projet.
Cela créera un nouveau répertoire appelé infer-models avec une structure de projet de base sans serveur et un modèle Python.
Vous pouvez également être invité à vous connecter/enregistrer. sélectionnez l'option "Connexion/Inscription". Cela ouvrira une fenêtre de navigateur dans laquelle vous pourrez créer un nouveau compte ou vous connecter si vous en avez déjà un. Après vous être connecté ou créé un compte, choisissez l'option "Framework Open Source", dont l'utilisation est gratuite.
Si le déploiement de votre pile ne parvient pas, veuillez commenter la ligne 2 du fichier serverless.yml
Après avoir exécuté la commande sans serveur et suivi les invites, un nouveau répertoire avec le nom du projet (par exemple, infer-models) sera créé, contenant la structure passe-partout et les fichiers de configuration du projet sans serveur.
Nous allons maintenant installer le plugin serverless-python-requirements : Le plugin serverless-python-requirements aide à gérer les dépendances Python pour votre projet sans serveur. Installez-le en exécutant :
npm install les exigences python sans serveur —save-dev
3.) npx sls deploy
(AVANT D'EXÉCUTER LA COMMANDE CI-DESSUS, LE MOTEUR DOCKER DEVRAIT ÊTRE INSTALLÉ ET FONCTIONNÉ. PLUS D'INFORMATIONS PEUVENT ÊTRE TROUVÉES ICI)
(Cela empaquetera et déploiera la fonction AWS Lambda) 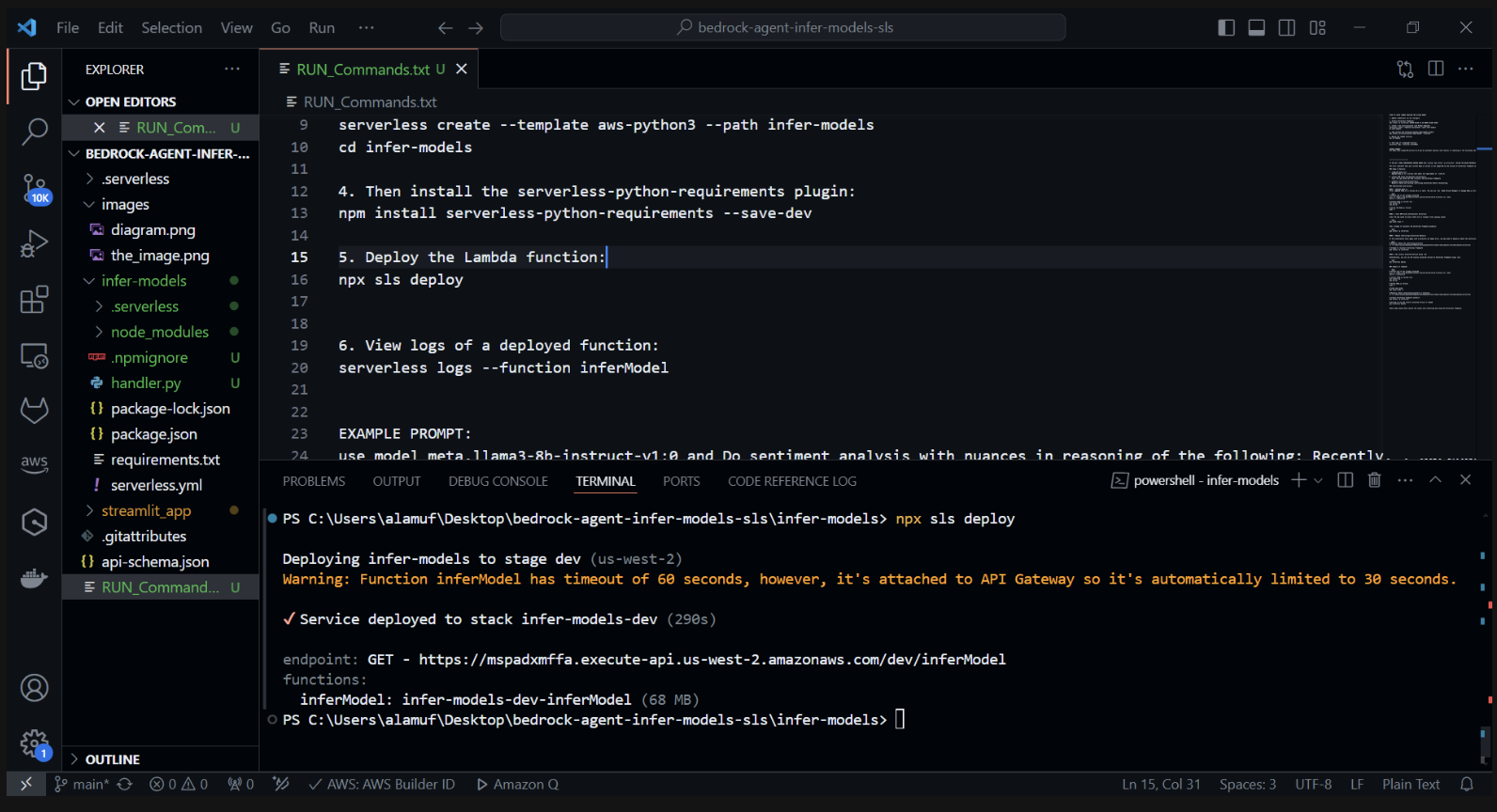
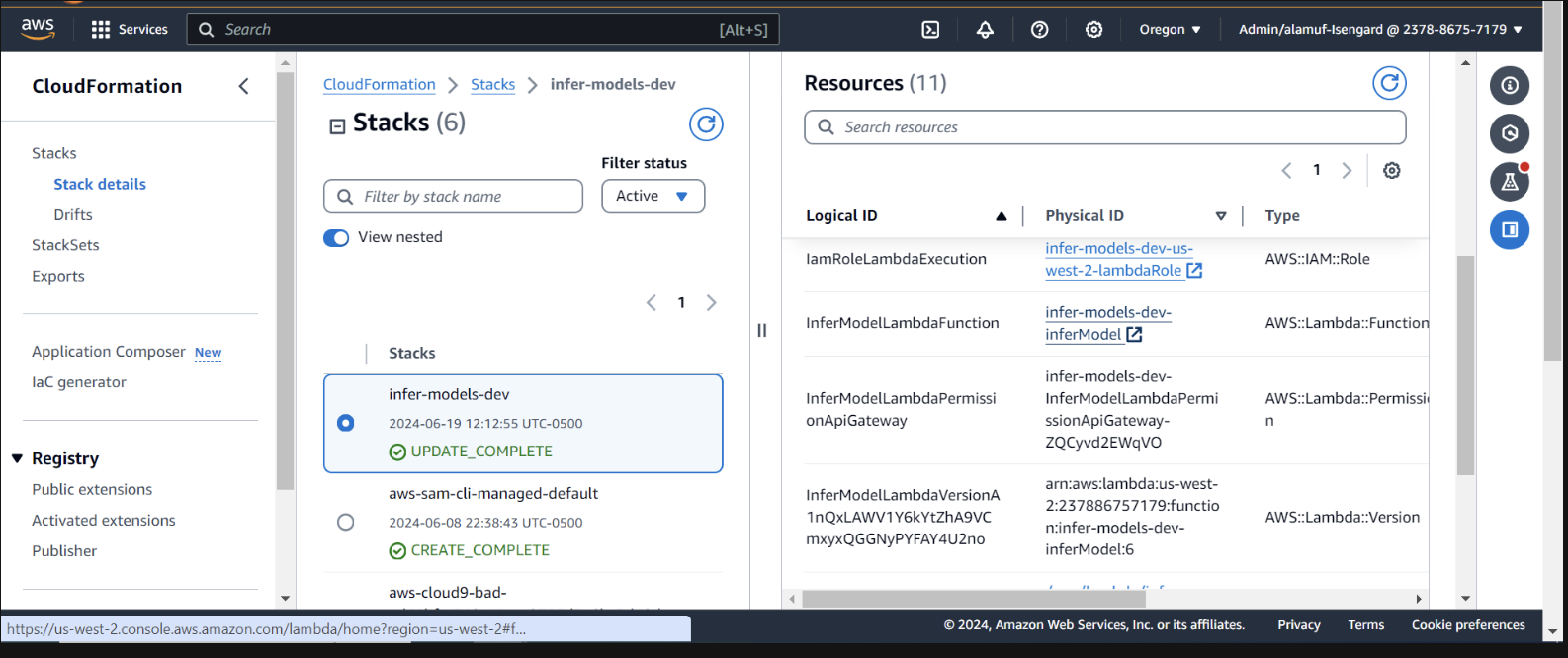
Inspecter le déploiement dans CloudFormation dans la console AWS
Nous devons fournir à l'agent de base les autorisations pour appeler la fonction lambda. Ouvrez la fonction lambda et faites défiler vers le bas pour sélectionner l'onglet Configuration . Sur la gauche, sélectionnez Autorisations . Faites défiler jusqu'à Déclarations de stratégie basées sur les ressources et sélectionnez Ajouter des autorisations.
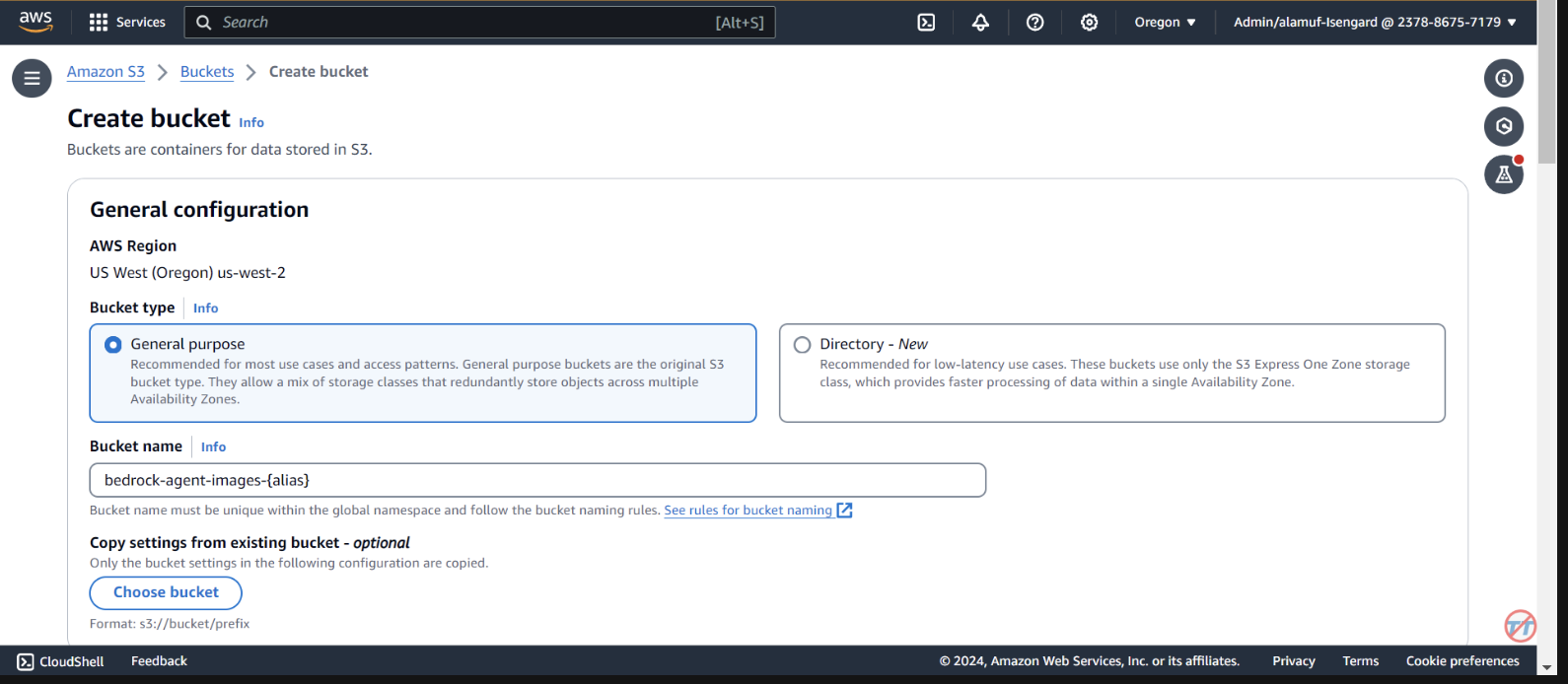
Sélectionnez le service AWS au milieu pour votre déclaration de politique. Choisissez Autre pour votre service et indiquez «allow-agent» pour le StatementID. Pour le directeur, mettez bedrock.amazonaws.com .
Saisissez arn:aws:bedrock:us-west-2:{aws-account-id}:agent/* . Veuillez noter qu'AWS recommande le moindre privilège afin que seul l'agent autorisé puisse appeler cette fonction Lambda. Un * à la fin de l'ARN accorde à n'importe quel agent du compte l'accès pour appeler ce Lambda. Idéalement, nous n’utiliserions pas cela dans un environnement de production. Enfin, pour l'action, sélectionnez lambda:InvokeFunction , puis Save. 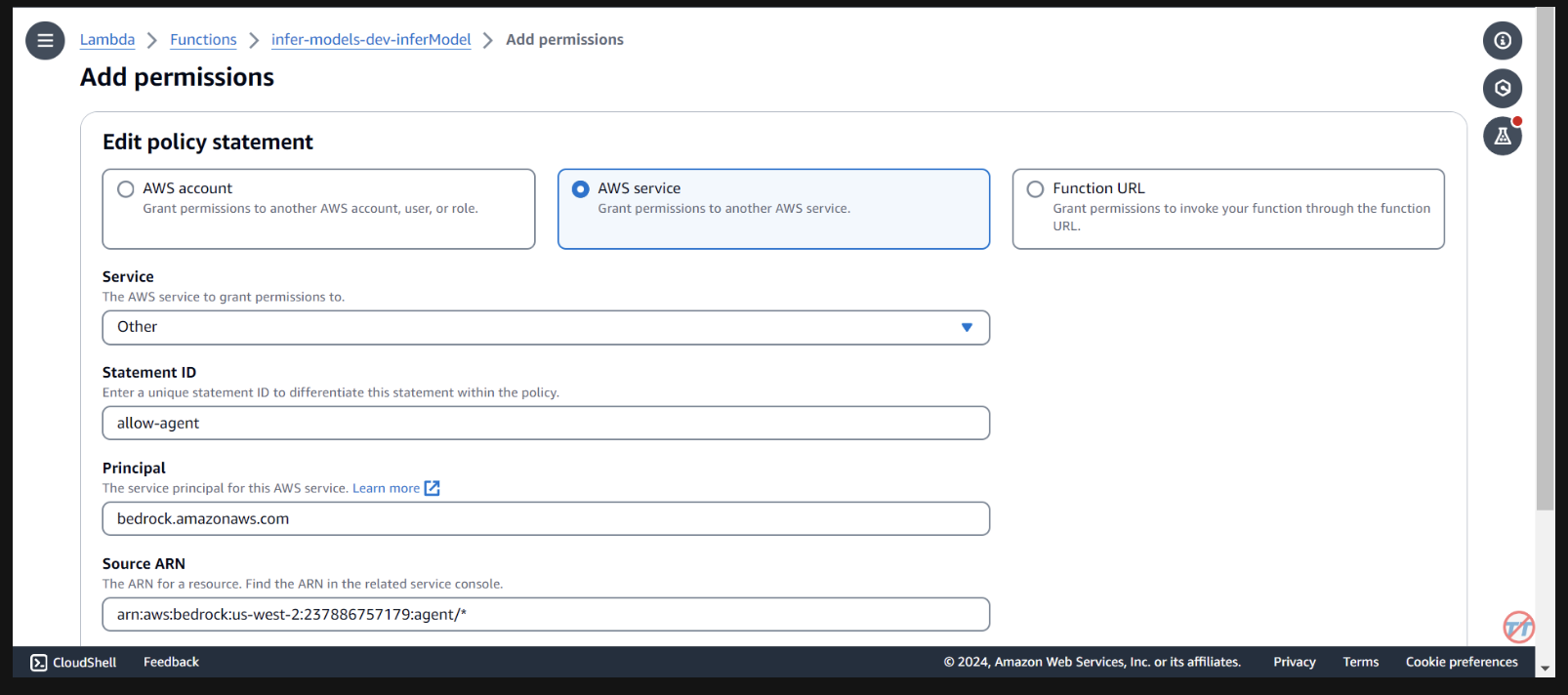
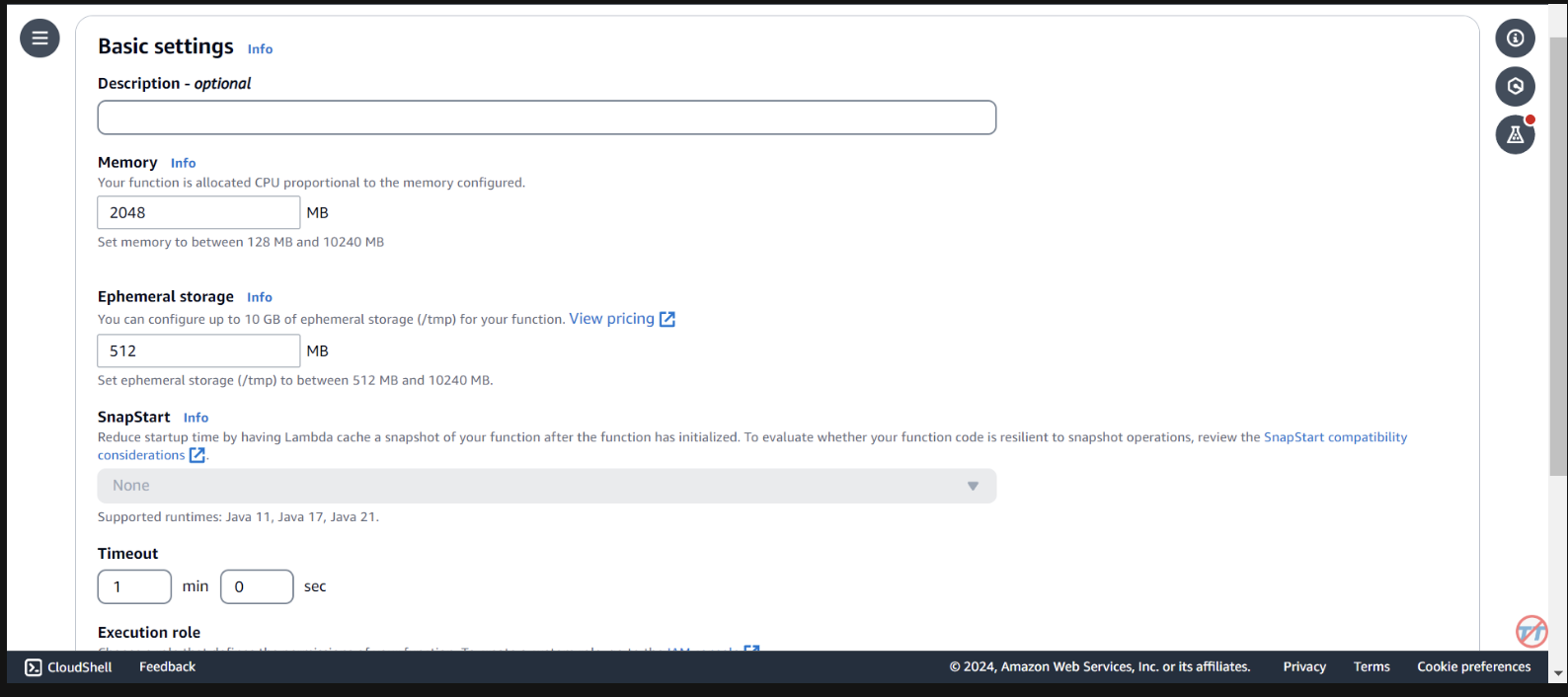
Pour faciliter l'inférence, nous augmenterons le CPU/mémoire sur la fonction Lambda. Nous augmenterons également le délai d'attente pour laisser à la fonction suffisamment de temps pour terminer l'invocation. Sélectionnez Configuration générale à gauche, puis Modifier à droite.
Modifiez la mémoire sur 2 048 Mo et le délai d'expiration sur 1 minute . Faites défiler vers le bas et sélectionnez Enregistrer.
Agents . Fournissez un nom d'agent, comme multi-model-agent, puis créez l'agent.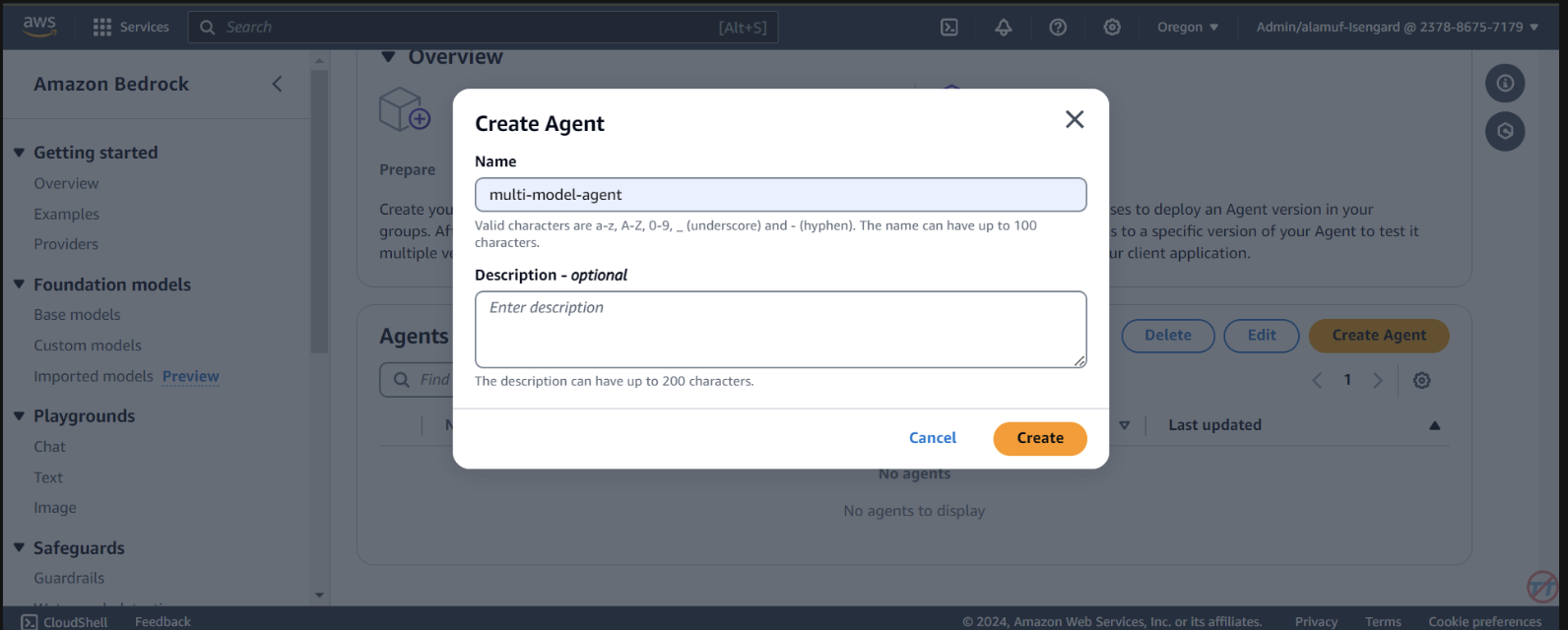
You are a research agent that interacts with various large language models. You pass the model ID and prompt from requests to large language models to create and store images. Then, the LLM will return a presigned URL to the image similar to the URL example provided. You also call LLMS for text and code generation, summarization, problem solving, text-to-sql, response comparisons and ratings. Remeber. you use other large language models for inference. Do not decide when to provide your own response, unless asked.
Ensuite, assurez-vous de faire défiler vers le haut et de sélectionner le bouton Enregistrer avant de passer à l'étape suivante.
Ensuite, nous ajouterons un groupe d'action. Faites défiler jusqu'à Action groups puis sélectionnez Ajouter . Appelez le groupe d'action call-model .
Pour le type de groupe Action, choisissez Définir avec des schémas API
Dans la section suivante, nous sélectionnerons une fonction Lambda existante infer-models-dev-inferModel .
Pour le schéma API, nous choisirons Define with in-line OpenAPI schema editor . Copiez et collez le schéma ci-dessous dans l'éditeur de schéma OpenAPI en ligne , puis sélectionnez Ajouter :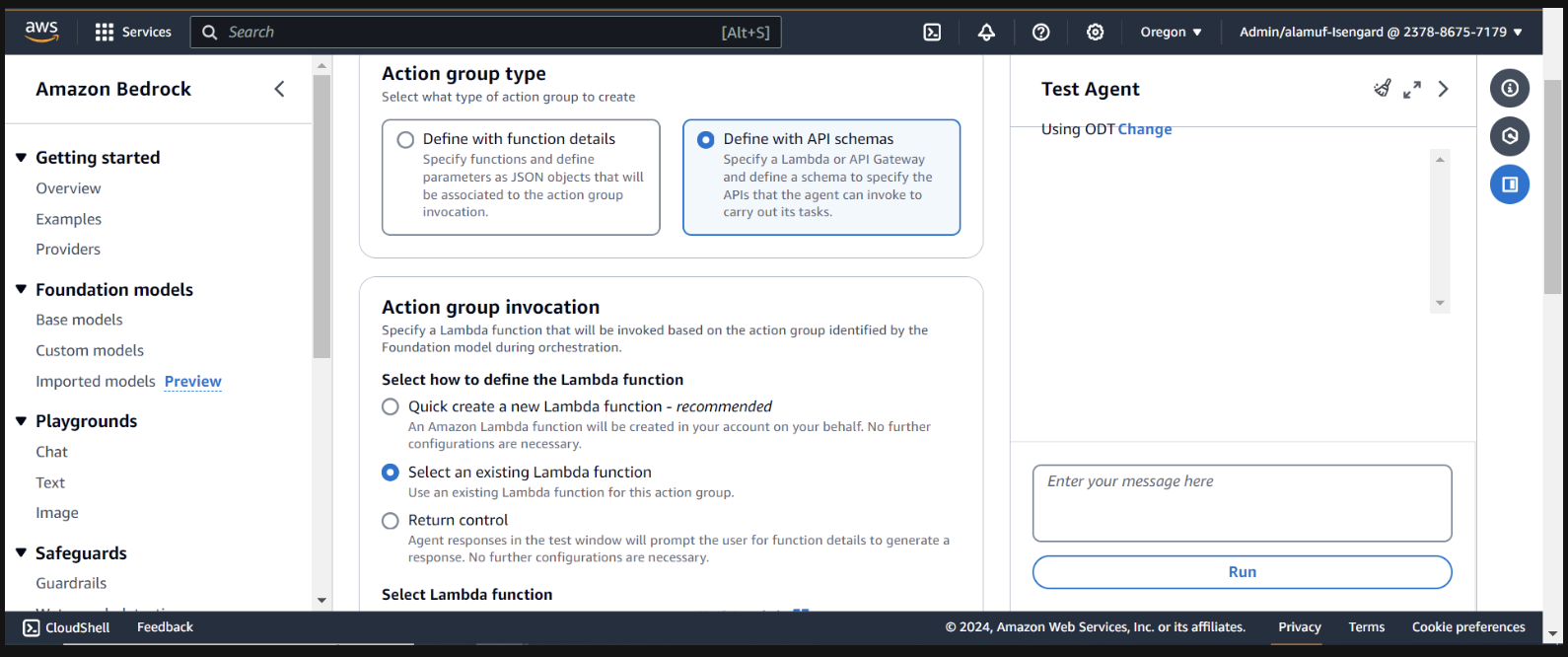
(This API schema is needed so that the bedrock agent knows the format structure and parameters required for the action group to interact with the Lambda function.)
{
"openapi": "3.0.0",
"info": {
"title": "Model Inference API",
"description": "API for inferring a model with a prompt, and model ID.",
"version": "1.0.0"
},
"paths": {
"/callModel": {
"post": {
"description": "Call a model with a prompt, model ID, and an optional image",
"parameters": [
{
"name": "modelId",
"in": "query",
"description": "The ID of the model to call",
"required": true,
"schema": {
"type": "string"
}
},
{
"name": "prompt",
"in": "query",
"description": "The prompt to provide to the model",
"required": true,
"schema": {
"type": "string"
}
}
],
"requestBody": {
"required": true,
"content": {
"multipart/form-data": {
"schema": {
"type": "object",
"properties": {
"modelId": {
"type": "string",
"description": "The ID of the model to call"
},
"prompt": {
"type": "string",
"description": "The prompt to provide to the model"
},
"image": {
"type": "string",
"format": "binary",
"description": "An optional image to provide to the model"
}
},
"required": ["modelId", "prompt"]
}
}
}
},
"responses": {
"200": {
"description": "Successful response",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"result": {
"type": "string",
"description": "The result of calling the model with the provided prompt and optional image"
}
}
}
}
}
}
}
}
}
}
}
Orchestration , activez l’option Override orchestration template defaults . 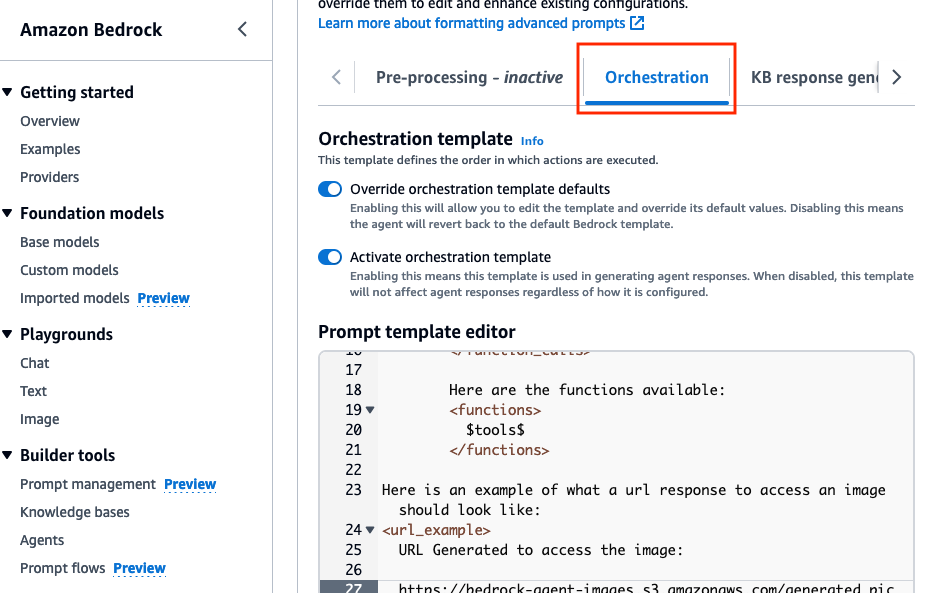
Here is an example of what a url response to access an image should look like:
<url_example>
URL Generated to access the image:
https://bedrock-agent-images.s3.amazonaws.com/generated_pic.png?AWSAccessKeyId=123xyz&Signature=rlF0gN%2BuaTHzuEDfELz8GOwJacA%3D&x-amz-security-token=IQoJb3JpZ2msqKr6cs7sTNRG145hKcxCUngJtRcQ%2FzsvDvt0QUSyl7xgp8yldZJu5Jg%3D%3D&Expires=1712628409
</url_example>
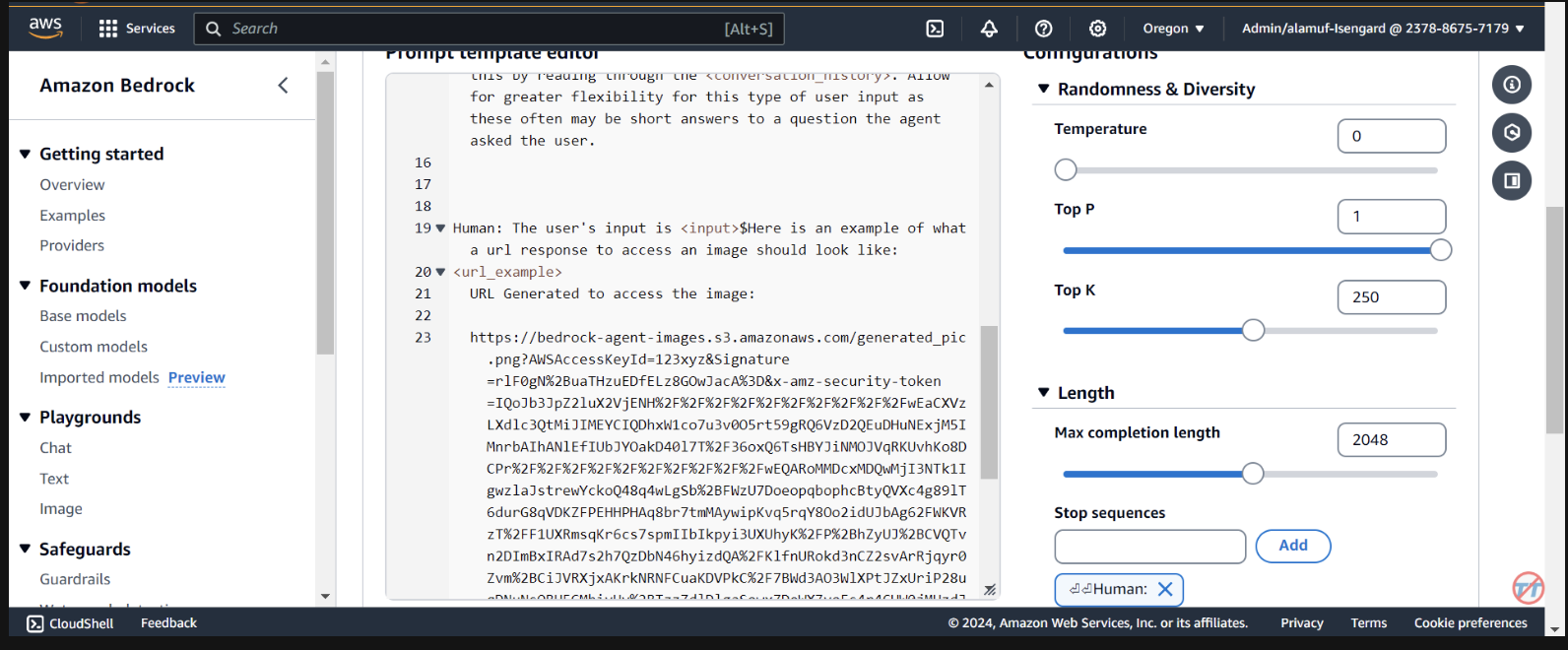
Cette invite permet de fournir à l'agent un exemple lors du formatage de la réponse d'une URL présignée après la génération d'une image dans le compartiment S3. De plus, il existe une option permettant d'utiliser une fonction Lambda d'analyseur personnalisée pour un formatage plus granulaire.
Faites défiler vers le bas et sélectionnez le bouton Save and exit .
Ensuite, assurez-vous d'appuyer à nouveau sur le bouton Save and exit en haut, puis sur le bouton Préparer en haut de l'interface utilisateur de l'agent de test, à droite. Cela nous permettra de tester les dernières modifications.
(Avant de continuer, assurez-vous d'activer tous les modèles via la console Amazon Bedrock avec lesquels vous prévoyez de tester.)
Pour commencer les tests, préparez l'agent en trouvant le bouton Préparer sur la page Agent Builder. 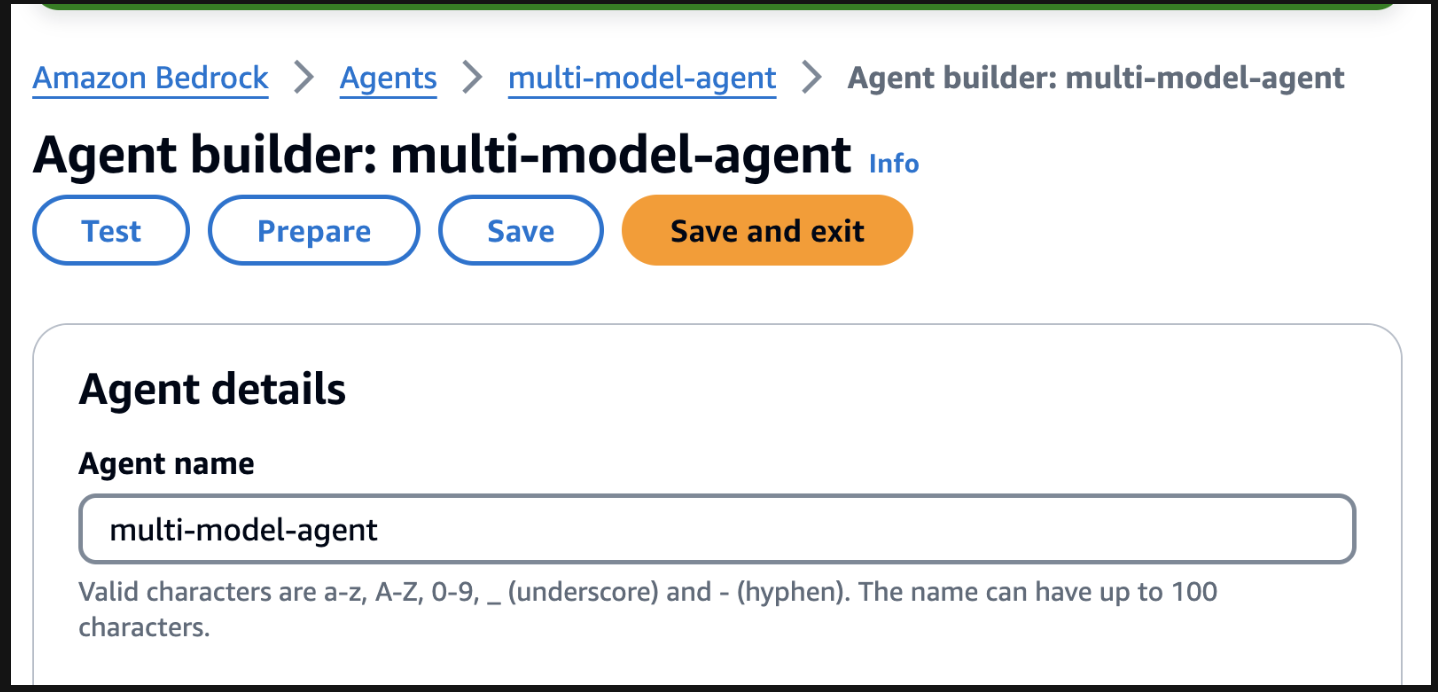
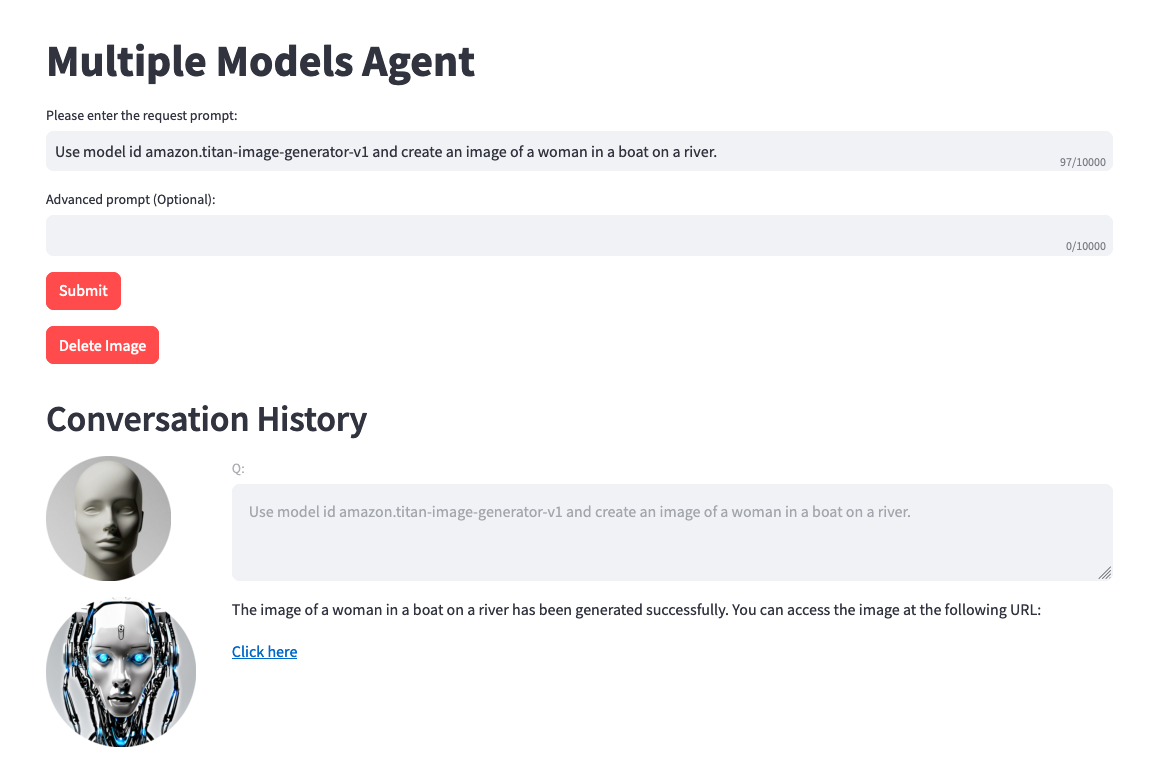
Sur la droite, vous devriez voir une option permettant de tester l'agent avec un champ de saisie utilisateur. Vous trouverez ci-dessous quelques invites que vous pouvez tester. Cependant, nous vous encourageons à faire preuve de créativité et à tester des variantes d'invites.
Une chose à noter avant de tester. Lorsque vous effectuez une conversion texte-image ou image-texte, le code du projet fait référence au même fichier .png de manière statique. Dans un environnement idéal, cette étape peut être configurée pour être plus dynamique.
Use model amazon.titan-image-generator-v1 and create me an image of a woman in a boat on a river.
Use model anthropic.claude-3-haiku-20240307-v1:0 and describe to me the image that is uploaded. The model function will have the information needed to provide a response. So, dont ask about the image.
Use model stability.stable-diffusion-xl-v1. Create an image of an astronaut riding a horse in the desert.
Use model meta.llama3-70b-instruct-v1:0. You are a gifted copywriter, with special expertise in writing Google ads. You are tasked to write a persuasive and personalized Google ad based on a company name and a short description. You need to write the Headline and the content of the Ad itself. For example: Company: Upwork Description: Freelancer marketplace Headline: Upwork: Hire The Best - Trust Your Job To True Experts Ad: Connect your business to Expert professionals & agencies with specialized talent. Post a job today to access Upwork's talent pool of quality professionals & agencies. Grow your team fast. 90% of customers rehire. Trusted by 5M+ businesses. Secure payments. - Write a persuasive and personalized Google ad for the following company. Company: Click Description: SEO services
(Si vous souhaitez configurer une interface utilisateur avec ce projet, passez à l'étape 6)
Vous aurez besoin d'un agent alias ID , ainsi que de l' agent ID pour cette étape. Accédez à la console de gestion Bedrock, puis sélectionnez votre agent multimodèle. Copiez l' Agent ID en haut à droite de la section Agent overview . Ensuite, faites défiler jusqu'à Alias et sélectionnez Créer . Nommez l'alias a1 , puis créez l'agent. Enregistrez l' ID d'alias généré, PAS le nom d'alias. 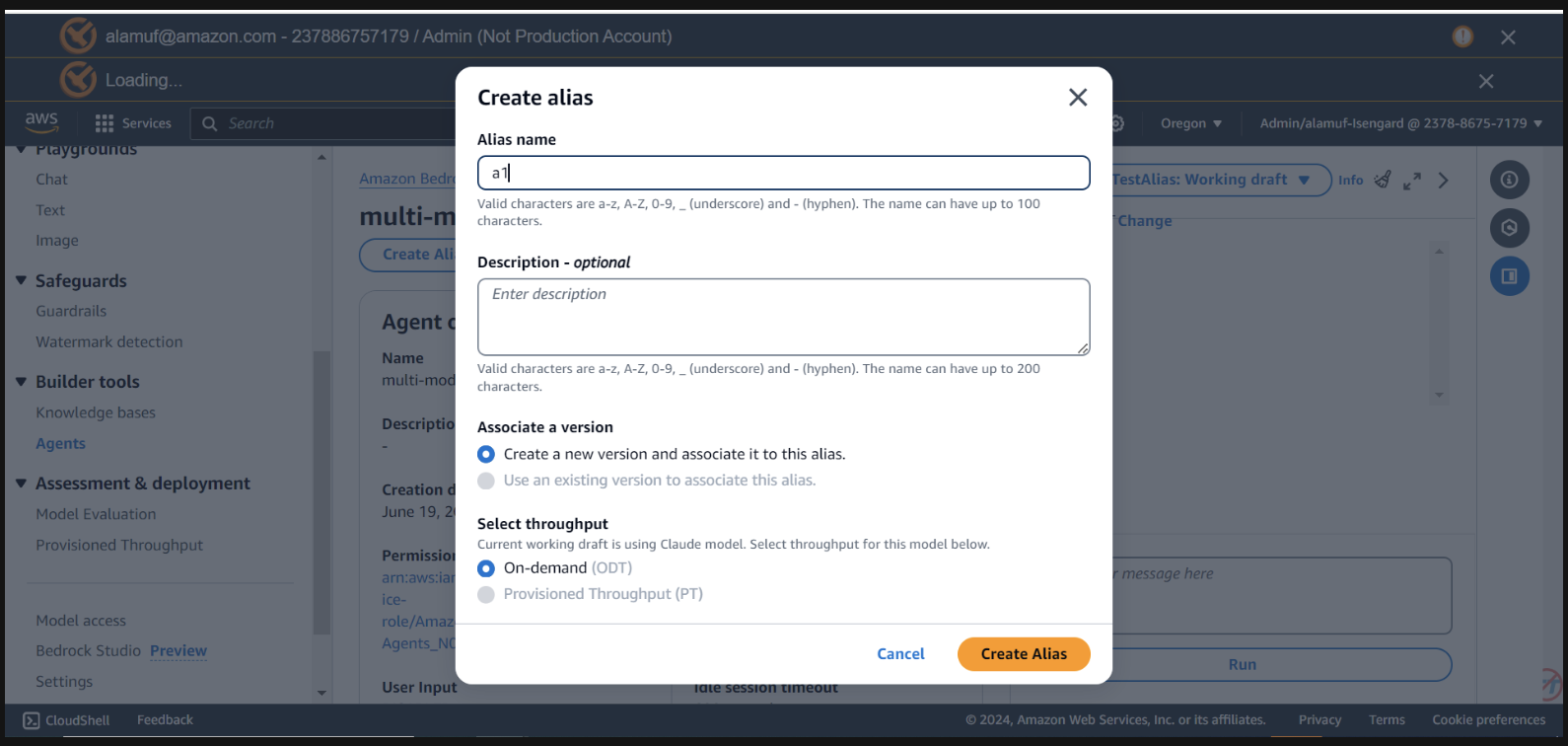
maintenant, revenez à l’EDI que vous avez utilisé pour ouvrir le projet.
Accédez au répertoire streamlit_app :
Configuration de mise à jour :
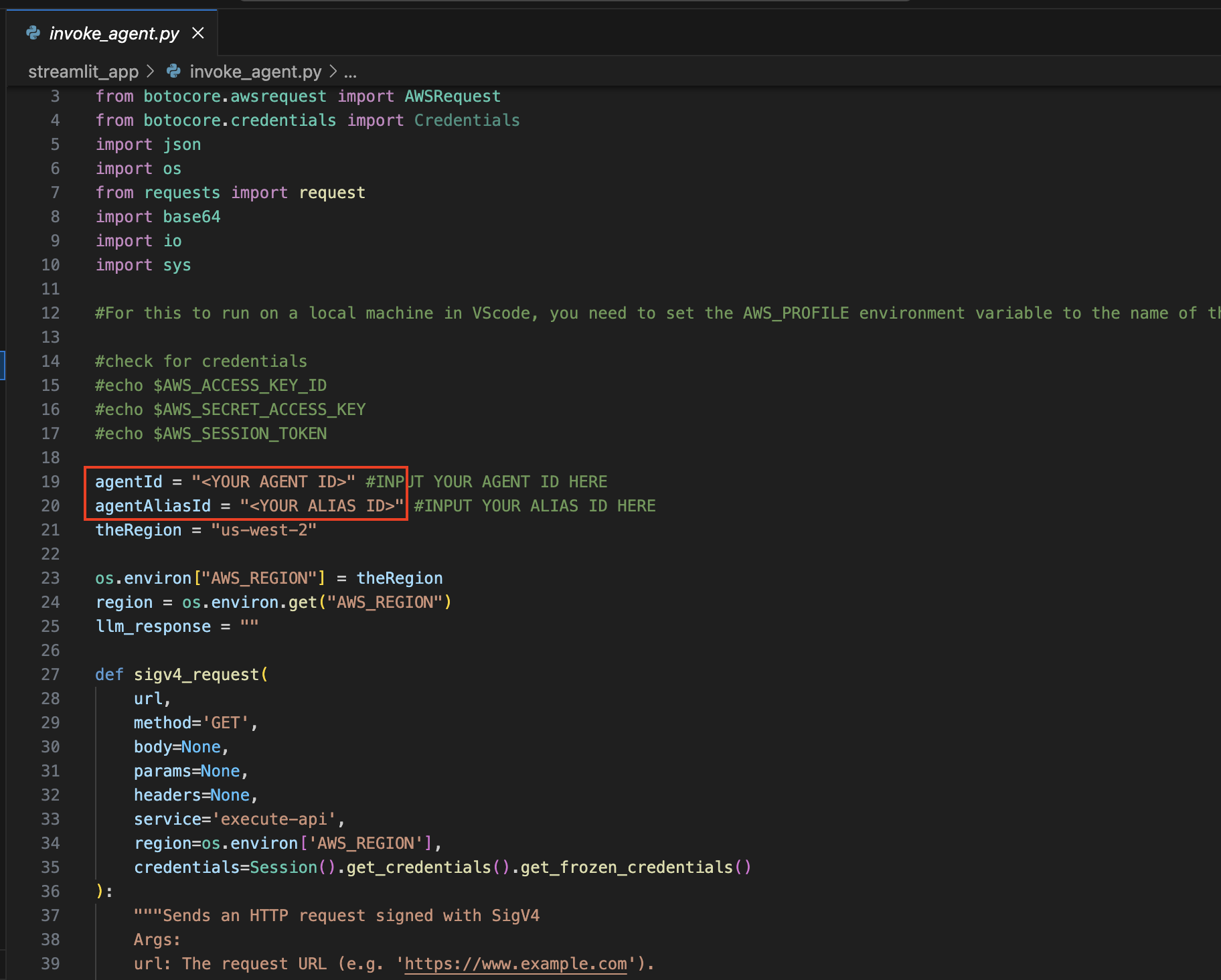
Ouvrez le fichier Invocation_agent.py .
Aux lignes 19 et 20, mettez à jour les variables agentId et agentAliasId avec les valeurs appropriées, puis enregistrez-les.
Installez Streamlit (s'il n'est pas déjà installé) :
Exécutez la commande suivante pour installer toutes les dépendances nécessaires :
pip install streamlit boto3 pandasExécutez l'application Streamlit :
streamlit_app : streamlit run app.py
N'oubliez pas que vous pouvez utiliser n'importe quel modèle disponible sur Amazon Bedrock et que vous n'êtes pas limité à la liste ci-dessus. Si un ID de modèle n'est pas répertorié, veuillez vous référer aux derniers modèles (ID) disponibles sur la page de documentation d'Amazon Bedrock ici.
Vous pouvez tirer parti du projet fourni pour affiner et comparer cette solution à vos propres ensembles de données et cas d'utilisation. Explorez différentes combinaisons de modèles, repoussez les limites du possible et stimulez l'innovation dans le paysage en constante évolution de l'IA générative.
Voir CONTRIBUTION pour plus d'informations.
Cette bibliothèque est sous licence MIT-0. Voir le fichier LICENCE.


