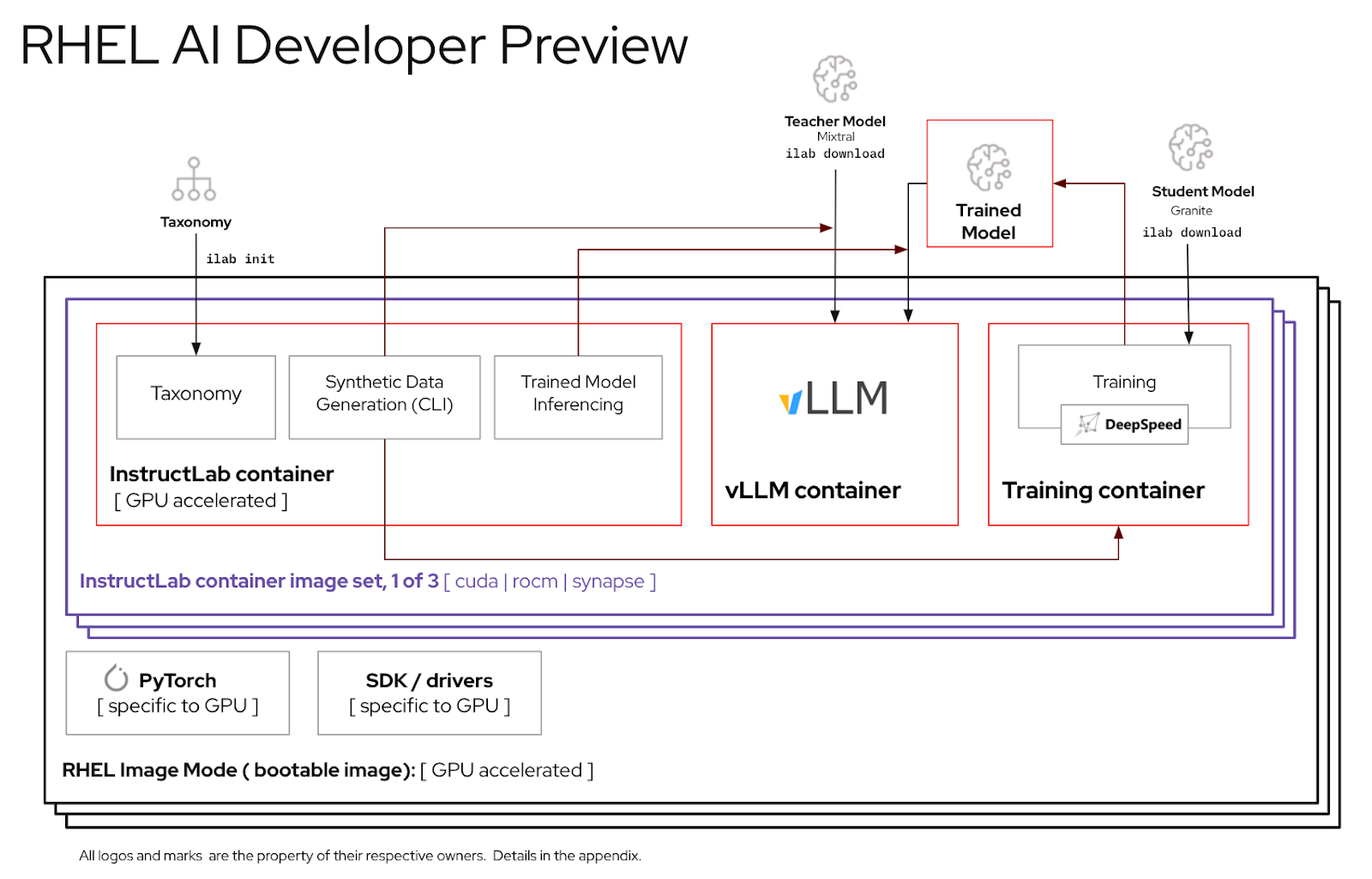
Ce guide vous aidera à assembler et à tester une version préliminaire pour développeur du produit RHEL AI.
Bienvenue dans l' aperçu du développeur Red Hat Enterprise Linux AI ! Ce guide est destiné à vous présenter les fonctionnalités de RHEL AI Developer Preview. Comme pour les autres Developer Previews, attendez-vous à des modifications de ces flux de travail, à une automatisation et une simplification supplémentaires, ainsi qu'à un élargissement des capacités, des versions de support matériel et logiciel, des améliorations des performances (et d'autres optimisations) avant GA.
RHEL AI est un produit open source qui comprend :
Note
RHEL AI est destiné aux plates-formes de serveurs et aux postes de travail dotés de GPU discrets. Pour les ordinateurs portables, veuillez utiliser InstructLab en amont.
Voici une liste de serveurs validés par les ingénieurs Red Hat pour fonctionner avec RHEL AI Developer Preview. Nous prévoyons que les systèmes récents certifiés pour exécuter RHEL 9, avec des GPU de centre de données récents tels que ceux répertoriés ci-dessous, fonctionneront avec cet aperçu du développeur.
| Fournisseur/Spécifications du GPU | Aperçu des développeurs RHEL AI |
|---|---|
| Dell (4) NVIDIA H100 | Oui |
Instances IBM GX3 | Oui |
| Lenovo (8) AMD MI300x | Oui |
| Instances AWS p4 et p5 (NVIDIA) | En cours |
| Intel | En cours |
Pour une meilleure expérience d'utilisation de la période d'aperçu des développeurs RHEL AI, nous avons inclus un arbre taxonomique élagué dans le conteneur InstructLab. Cela permettra de valider la formation dans un délai raisonnable sur un seul serveur.
Formule : un seul GPU peut entraîner environ 250 échantillons par minute. Si vous disposez de 8 GPU et de 10 000 échantillons, attendez-vous à ce que cela prenne
À la fin de cet exercice, vous aurez :
bootc est un système d'exploitation transactionnel sur place qui provisionne et met à jour à l'aide d'images de conteneurs OCI/Docker. bootc est le composant clé d'une mission plus large de conteneurs amorçables.
Le modèle de conteneur Docker original consistant à utiliser des « couches » pour modéliser les applications a été extrêmement efficace. Ce projet vise à appliquer la même technique aux systèmes hôtes amorçables - en utilisant des conteneurs OCI/Docker standard comme format de transport et de livraison pour les mises à jour du système d'exploitation de base.
L'image du conteneur inclut un noyau Linux (par exemple /usr/lib/modules ), qui est utilisé pour démarrer. Lors de l'exécution sur un système cible, l'espace utilisateur de base ne s'exécute pas lui-même dans un conteneur par défaut. Par exemple, en supposant que systemd est utilisé, systemd agit comme pid1 comme d'habitude - il n'y a pas de processus "externe".
Dans l'exemple suivant, le conteneur bootc est intitulé Node Base Image :
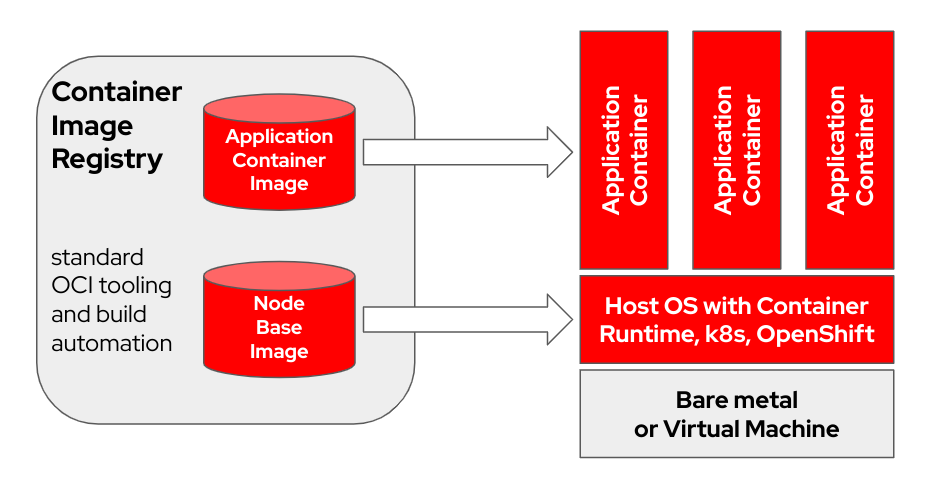
En fonction du matériel de votre hôte de construction et de la vitesse de votre connexion Internet, la création et le téléchargement d'images de conteneur peuvent prendre jusqu'à 2 heures.
m5.xlarge en utilisant le stockage GP3)quay.io ou un autre registre d'images. Enregistrez l'hôte (Comment enregistrer et abonner un système RHEL au portail client Red Hat à l'aide de Red Hat Subscription-Manager ?)
sudo subscription-manager register --username < username > --password < password >Installer les packages requis
sudo dnf install git make podman buildah lorax -yCloner le dépôt git RHEL AI Developer Preview
git clone https://github.com/RedHatOfficial/rhelai-dev-preview Authentifiez-vous auprès du registre Red Hat (authentification Red Hat Container Registry) à l'aide de votre compte redhat.com .
podman login registry.redhat.io --username < username > --password < password >
podman login --get-login registry.redhat.io
Your_login_here Assurez-vous de disposer d'une clé SSH sur l'hôte de build. Ceci est utilisé lors de la création de l’image de la boîte à outils du pilote. (Utilisation de ssh-keygen et partage pour l'authentification par clé sous Linux | Activer Sysadmin)
RHEL AI comprend un ensemble de Makefiles pour faciliter la création des images de conteneur. En fonction du matériel hôte de votre build et de la vitesse de votre connexion Internet, cela peut prendre jusqu'à une heure.
Créez l’image du conteneur InstructLab NVIDIA.
make instruct-nvidia Créez l'image du conteneur vllm .
make vllm Créez l’image du conteneur deepspeed .
make deepspeed Enfin, créez l’image du conteneur RHEL AI NVIDIA bootc . Il s'agit du conteneur « bootable » en mode image RHEL. Nous intégrons les 3 images ci-dessus dans ce conteneur.
make nvidia FROM=registry.redhat.io/rhel9/rhel-bootc:9.4 REGISTRY= < your-registry > REGISTRY_ORG= < your-org-name > L'image résultante est étiquetée ${REGISTRY}/${REGISTRY_ORG}/nvidia-bootc:latest . Pour plus de variables et d'exemples, voir la formation/README.
Envoyez l'image résultante dans votre registre. Vous ferez référence à cette URL dans un fichier kickstart dans une prochaine étape.
podman push ${REGISTRY} / ${REGISTRY_ORG} /nvidia-bootc:latest
e.g. podman push quay.io/ < your-user-name > /nvidia-bootc.latestÀ ce stade, vous disposez d’une image de conteneur amorçable RHEL AI prête à être installée sur un hôte physique ou virtuel.
Anaconda est le programme d'installation de Red Hat Enterprise Linux et il est intégré à toutes les images ISO téléchargeables RHEL. La principale méthode d'automatisation de l'installation de RHEL consiste à utiliser des scripts appelés Kickstart. Pour plus d'informations sur Anaconda et Kickstart, lisez ces documents.
Une commande kickstart récente appelée ostreecontainer a été introduite avec RHEL 9.4. Nous utilisons ostreecontainer pour provisionner le conteneur nvidia-bootc amorçable que vous venez de transférer vers votre registre via le réseau.
Voici un exemple de fichier kickstart. Copiez-le dans un fichier appelé rhelai-dev-preview-bootc.ks et personnalisez-le en fonction de votre environnement :
# text
## customize this for your target system
# network --bootproto=dhcp --device=link --activate
## Basic partitioning
## customize this for your target system
# clearpart --all --initlabel --disklabel=gpt
# reqpart --add-boot
# part / --grow --fstype xfs
# ostreecontainer --url quay.io//nvidia-bootc:latest
# firewall --disabled
# services --enabled=sshd
## optionally add a user
# user --name=cloud-user --groups=wheel --plaintext --password
# sshkey --username cloud-user "ssh-ed25519 AAAAC3Nza....."
## if desired, inject an SSH key for root
# rootpw --iscrypted locked
# sshkey --username root "ssh-ed25519 AAAAC3Nza..."
# reboot
Téléchargez l'ISO de démarrage RHEL 9.4 et utilisez la commande mkksiso pour intégrer le kickstart dans l'ISO de démarrage RHEL.
mkksiso rhelai-dev-preview-bootc.ks rhel-9.4-x86_64-boot.iso rhelai-dev-preview-bootc-ks.isoÀ ce stade, vous devriez avoir :
nvidia-bootc:latest : une image de conteneur amorçable avec prise en charge des GPU NVIDIArhelai-dev-preview-bootc.ks : un fichier kickstart personnalisé pour provisionner RHEL depuis votre registre de conteneurs vers votre système cible.rhelai-dev-preview-bootc-ks.iso : un ISO RHEL 9.4 bootable avec le kickstart intégré. Démarrez votre système cible à l'aide du fichier rhelai-dev-preview-bootc-ks.iso . anaconda extraira l'image nvidia-bootc:latest de votre registre et provisionnera RHEL en fonction de votre fichier kickstart.
Alternative : le fichier kickstart peut être servi via HTTP. Lors de l'installation via la ligne de commande du noyau et un serveur HTTP externe – ajoutez inst.ks=http(s)://kickstart/url/rhelai-dev-preview-bootc.ks
Avant d'utiliser l'environnement RHEL AI, vous devez télécharger deux modèles, chacun adapté à une fonction clé du processus de réglage haute fidélité. Granite est utilisé comme modèle étudiant et est chargé de faciliter la formation d’un nouveau mode affiné. Mixtral est utilisé comme modèle d'enseignant et est chargé de faciliter la phase de génération du processus LAB, où les compétences et les connaissances sont utilisées de concert pour produire un riche ensemble de données de formation.
Settings .Access Tokens . Cliquez sur le bouton New token et fournissez un nom. Le nouveau jeton nécessite uniquement l'utilisation des autorisations Read puisqu'il est uniquement utilisé pour récupérer des modèles. Sur cet écran, vous pourrez générer le contenu du jeton et enregistrer et copier le texte pour vous authentifier. 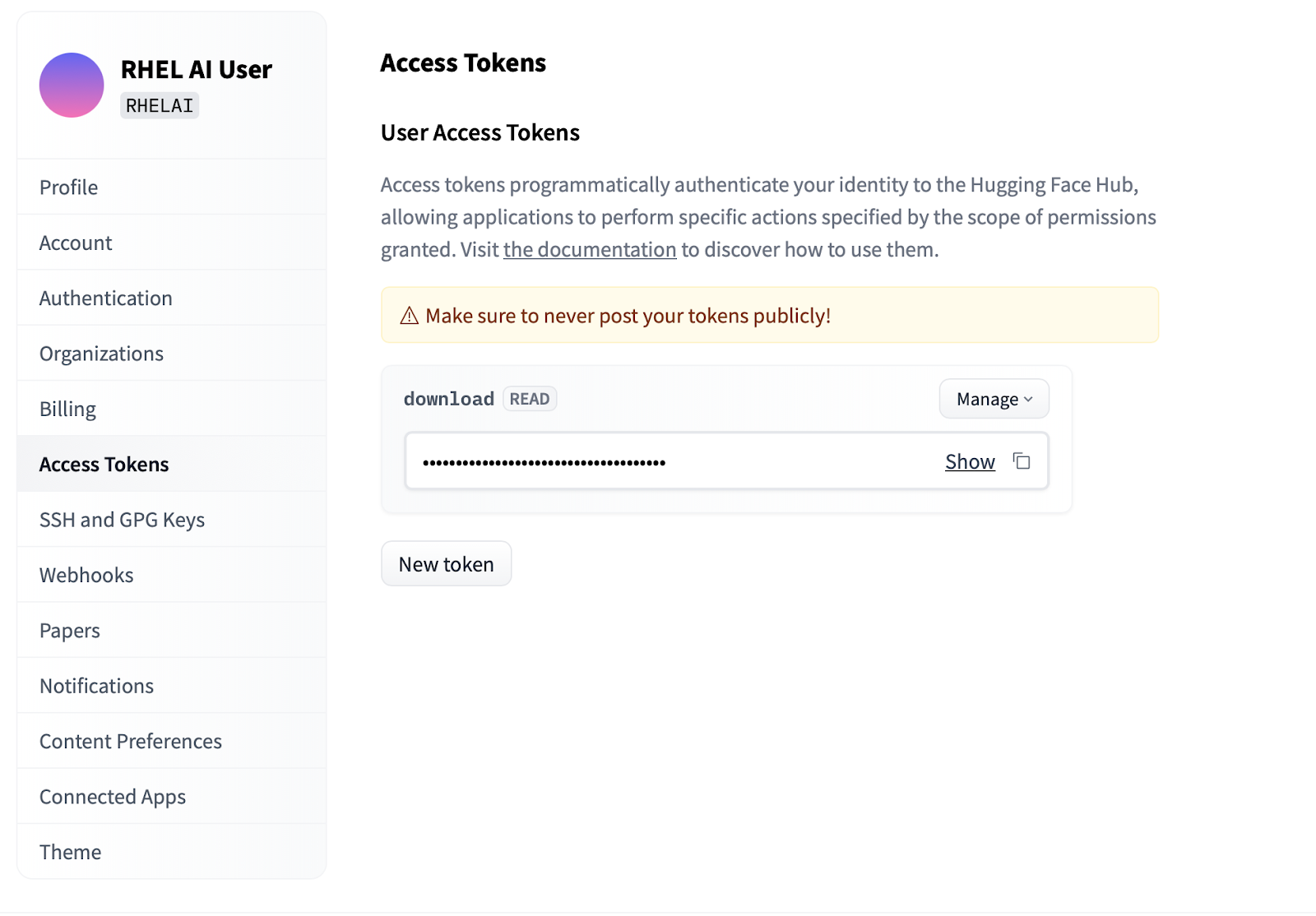
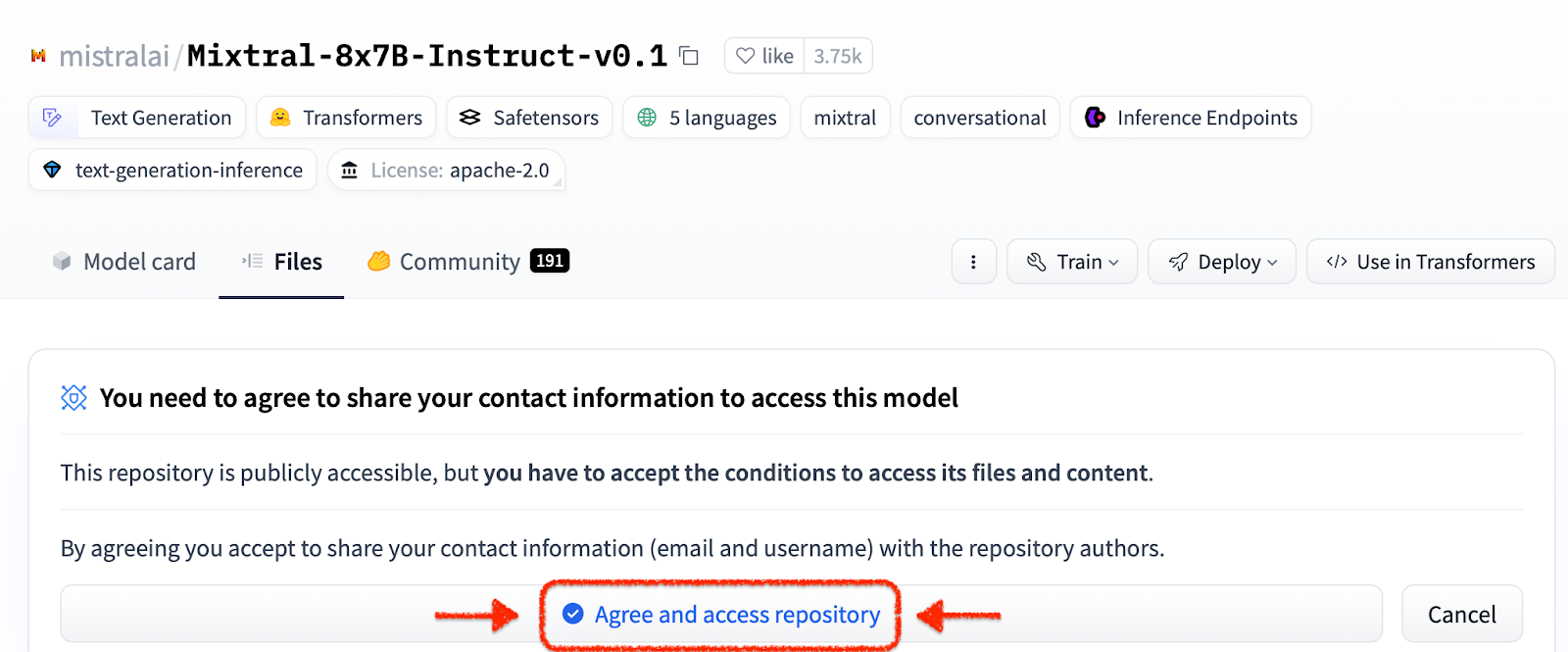
L'interface de ligne de commande ilab qui fait partie du projet InstructLab se concentre sur l'exécution de modèles quantifiés légers sur des appareils informatiques personnels tels que les ordinateurs portables. En revanche, RHEL AI permet d’utiliser une formation haute fidélité à l’aide de modèles de pleine précision. Pour plus de familiarité, la commande et les paramètres reflètent ceux de la commande ilab d'InstructLab ; cependant, la mise en œuvre du support est très différente.
Dans RHEL AI, la commande
ilabest un wrapper qui agit comme une interface frontale pour une architecture de conteneur pré-groupée sur le système RHEL AI.
ilabLa première étape consiste à créer un nouveau répertoire de travail pour votre projet. Tout sera relatif à ce répertoire de travail. Il contiendra vos modèles, journaux et données de formation.
mkdir my-project
cd my-project La toute première commande ilab que vous exécuterez configure l'environnement de base, y compris le téléchargement du dépôt de taxonomie si vous le souhaitez. Cela sera nécessaire pour les étapes ultérieures, il est donc recommandé de le faire.
ilab initDéfinissez une variable d'environnement à l'aide du jeton HF que vous avez créé dans la section ci-dessus sous Jetons d'accès.
export HF_TOKEN= < paste token value here > Ensuite, téléchargez le modèle de base IBM Granite. Important : Ne téléchargez pas les versions « laboratoire » du modèle. Le modèle à base de granit est le plus efficace pour effectuer un entraînement haute fidélité.
ilab download --repository ibm/granite-7b-baseSuivez le même processus pour télécharger le modèle Mistral.
ilab download --repository mistralai/Mixtral-8x7B-Instruct-v0.1Maintenant que vous avez initialisé votre projet et téléchargé vos premiers modèles, observez la structure des répertoires de votre projet
my-project/
├─ models/
├─ generated/
├─ taxonomy/
├─ training/
├─ training_output/
├─ cache/
| Dossier | But |
|---|---|
| modèles | Contient tous les modèles de langage, y compris la sortie enregistrée de ceux que vous générez avec RHEL AI |
| généré | Sortie de données générées à partir de la phase de génération, construite sur les modifications apportées au référentiel de taxonomie |
| taxonomie | Données de compétences ou de connaissances utilisées par la méthode LAB pour générer des données synthétiques pour la formation |
| entraînement | Données de départ converties pour faciliter le processus de formation |
| formation_sortie | Tous les résultats transitoires du processus de formation, y compris les journaux et les points de contrôle d'échantillons en vol |
| cache | Un cache interne utilisé par les données du modèle |
L'étape suivante consiste à apporter de nouvelles connaissances ou compétences au dépôt de taxonomie. Consultez la documentation InstructLab pour plus d’informations et des exemples sur la façon de procéder. Nous avons également une série d’exercices de laboratoire ici.
Avec l'ajout de données taxonomiques supplémentaires, il est désormais possible de générer de nouvelles données synthétiques pour éventuellement former un nouveau modèle. Cependant, avant que la génération puisse commencer, un modèle d'enseignant doit d'abord être lancé pour aider le générateur à construire de nouvelles données. Dans une session de terminal distincte, exécutez la commande « serve » et attendez la fin du démarrage de VLLM. Notez que ce processus peut prendre plusieurs minutes.
ilab serve
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit) Maintenant que VLLM dessert le mode enseignant, le processus de génération peut être démarré à l'aide de la commande ilab generate. Ce processus prendra un certain temps et produira continuellement le nombre total d'instructions générées au fur et à mesure de sa mise à jour. La valeur par défaut est 5 000 instructions, mais vous pouvez l'ajuster avec l'option --num-instructions .
ilab generate Q> How do cytokines influence the outcome of certain diseases involving tonsils?
A> The outcome of infectious, autoimmune, or malignant diseases affecting tonsils may be influenced by the overall balance of production profiles of pro-inflammatory and anti-inflammatory cytokines. Determining cytokine profiles in tonsil studies is essential for understanding the causes and underlying mechanisms of these disorders.
35%|████████████████████████████████████████▉
En plus des données actuelles imprimées à l'écran lors de la génération, une sortie complète est enregistrée dans le dossier généré. Avant la formation, il est recommandé d'examiner ce résultat pour vérifier qu'il répond aux attentes. Si cela n'est pas satisfaisant, essayez de modifier ou de créer de nouveaux exemples dans la taxonomie et de réexécuter.
less generated/generated_Mixtral * .jsonUne fois les données générées satisfaisantes, le processus de formation peut commencer. Bien que fermez d’abord l’instance VLLM dans la session de terminal qui a été démarrée pour la génération.
CTRL+C
INFO: Application shutdown complete.
INFO: Finished server process [1]
Vous pouvez recevoir une exception Python KeyboardInterrupt et une trace de pile. Cela peut être ignoré en toute sécurité.
Une fois VLLM arrêté et les nouvelles données générées, le processus de formation peut être lancé à l'aide de la commande ilab train . Par défaut, le processus de formation enregistre un point de contrôle du modèle tous les 4 999 échantillons. Vous pouvez ajuster cela en utilisant le paramètre --num-samples . De plus, l'entraînement s'exécute par défaut sur 10 époques, qui peuvent également être ajustées avec le paramètre --num-epochs . En général, plus d’époques sont préférables, mais après un certain point, plus d’époques entraîneront un surapprentissage. Il est généralement recommandé de rester dans une limite de 10 époques ou moins et d'examiner différents points d'échantillonnage pour trouver le meilleur résultat.
ilab train --num-epochs 9 RunningAvgSamplesPerSec=149.4829861942806, CurrSamplesPerSec=161.99957513920629, MemAllocated=22.45GB, MaxMemAllocated=29.08GB
throughput: 161.84935045724643 samples/s, lr: 1.3454545454545455e-05, loss: 0.840185821056366 cuda_mem_allocated: 22.45188570022583 GB cuda_malloc_retries: 0 num_loss_counted_tokens: 8061.0 batch_size: 96.0 total loss: 0.8581467866897583
Epoch 1: 100%|█████████████████████████████████████████████████████████| 84/84 [01:09<00:00, 1.20it/s]
total length: 2527 num samples 15 - rank: 6 max len: 187 min len: 149
Une fois le processus de formation terminé, les nouvelles entrées de modèles seront stockées dans le répertoire des modèles avec des emplacements imprimés sur le terminal.
Generated model in /root/workspace/models/tuned-0504-0051:
.
./samples_4992
./samples_9984
./samples_14976
./samples_19968
./samples_24960
./samples_29952
./samples_34944
./samples_39936
./samples_44928
./samples_49920
La même commande ilab serve peut être utilisée pour servir le nouveau modèle en passant l'option –model avec le nom et l'échantillon.
ilab serve --model tuned-0504-0051/samples_49920 Une fois que VLLM a démarré avec le nouveau modèle, une session de discussion peut être lancée en créant une nouvelle session de terminal et en transmettant le même paramètre --model au chat (notez que si cela ne correspond pas, vous recevrez un message d'erreur 404). Posez-lui une question liée à vos contributions à la taxonomie.
ilab chat --model tuned-0504-0051/samples_49920╭─────────────────────────────── system ────────────────────────────────╮
│ Welcome to InstructLab Chat w/ │
│ /INSTRUCTLAB/MODELS/TUNED-0504-0051/SAMPLES_49920 (type /h for help) │
╰───────────────────────────────────────────────────────────────────────╯
>>> What are tonsils ?
╭────────── /instructlab/models/tuned-0504-0051/samples_49920 ──────────╮
│ │
│ Tonsils are a type of mucosal lymphatic tissue found in the │
│ aerodigestive tracts of various mammals, including humans. In the │
│ human body, the tonsils play a crucial role in protecting the body │
│ from infections, particularly those caused by bacteria and viruses. │
╰─────────────────────────────────────────────── elapsed 0.469 seconds ─╯Pour quitter la session, tapez
exit
C'est ça! Le but d'un aperçu développeur est de fournir quelque chose à nos utilisateurs pour obtenir des commentaires précoces. Nous sommes conscients qu'il peut y avoir des bugs. Et nous apprécions votre temps et vos efforts si vous êtes arrivé jusqu'ici. Il y a de fortes chances que vous rencontriez des problèmes ou que vous deviez les résoudre. Nous vous encourageons à déposer des rapports de bogues, des demandes de fonctionnalités et à nous poser des questions. Consultez les coordonnées ci-dessous pour savoir comment procéder. Merci!
$ sudo subscription-manager config --rhsm.manage_repos=1nvidia-smi pour s'assurer que les pilotes fonctionnent et peuvent voir les GPUnvtop (disponible en EPEL) pour voir si les GPU sont utilisés (certains chemins de code ont un repli du CPU, ce dont nous ne voulons pas ici)make prune depuis le sous-répertoire de formation. Cela nettoiera les anciens artefacts de construction.--no-cache au processus de construction make nvidia-bootc CONTAINER_TOOL_EXTRA_ARGS= " --no-cache "TMPDIR : make < platform > TMPDIR=/path/to/tmp