test arranger
v1.6.3
En TDD il y a 3 phases : organiser, agir et affirmer (donné, quand, puis en BDD). La phase d'assertion dispose d'un excellent support d'outils, vous connaissez peut-être AssertJ, FEST-Assert ou Hamcrest. Cela contraste avec la phase d’arrangement. Bien que l'organisation des données de test soit souvent difficile et qu'une partie importante du test y soit généralement consacrée, il est difficile de désigner un outil qui le prend en charge.
Test Arranger tente de combler cette lacune en organisant les instances de classes requises pour les tests. Les instances sont remplies de valeurs pseudo-aléatoires qui simplifient le processus de création de données de test. Le testeur déclare uniquement les types des objets requis et obtient de toutes nouvelles instances. Lorsqu'une valeur pseudo-aléatoire pour un champ donné n'est pas suffisante, seul ce champ doit être défini manuellement :
Product product = Arranger . some ( Product . class );
product . setBrand ( "Ocado" );< dependency >
< groupId >com.ocadotechnology.gembus</ groupId >
< artifactId >test-arranger</ artifactId >
< version >1.6.3</ version >
</ dependency >testImplementation ' com.ocadotechnology.gembus:test-arranger:1.6.3 ' La classe Arranger dispose de plusieurs méthodes statiques pour générer des valeurs pseudo-aléatoires de types simples. Chacun d'eux dispose d'une fonction d'encapsulation pour simplifier les appels pour Kotlin. Certains des appels possibles sont répertoriés ci-dessous :
| Java | Kotlin | résultat |
|---|---|---|
Arranger.some(Product.class) | some<Product>() | une instance de Product avec tous les champs remplis de valeurs |
Arranger.some(Product.class, "brand") | some<Product>("brand") | une instance de Produit sans valeur pour le champ marque |
Arranger.someSimplified(Category.class) | someSimplified<Category>() | une instance de Catégorie, les champs de type collection ont une taille réduite à 1 et la profondeur de l'arborescence des objets est limitée à 3 |
Arranger.someObjects(Product.class, 7) | someObjects<Product>(7) | un flux de taille 7 d'instances de Product |
Arranger.someEmail() | someEmail() | une chaîne contenant l'adresse e-mail |
Arranger.someLong() | someLong() | un nombre pseudo aléatoire de type long |
Arranger.someFrom(listOfCategories) | someFrom(listOfCategories) | une entrée du formulaire listOfCategories |
Arranger.someText() | someText() | une chaîne générée à partir d'une chaîne de Markov ; par défaut, c'est une chaîne très simple, mais elle peut être reconfigurée en mettant un autre fichier 'enMarkovChain' sur le chemin de classe de test avec une définition alternative, vous pouvez en trouver un formé sur un corpus anglais ici ; consultez le fichier 'enMarkovChain' inclus dans le projet pour le format de fichier |
| - | some<Product> {name = "not so random"} | une instance de Product avec tous les champs remplis de valeurs aléatoires à l'exception du name qui est défini sur "pas si aléatoire", cette syntaxe peut être utilisée pour définir autant de champs de l'objet que nécessaire, mais chacun des objets doit être modifiable |
Des données complètement aléatoires peuvent ne pas convenir à tous les cas de test. Il existe souvent au moins un champ crucial pour l’objectif du test et nécessitant une certaine valeur. Lorsque la classe organisée est mutable, qu'il s'agit d'une classe de données Kotlin ou qu'il existe un moyen de créer une copie modifiée (par exemple @Builder(toBuilder = true) de Lombok), utilisez simplement ce qui est disponible. Heureusement, même s'il n'est pas réglable, vous pouvez utiliser le Test Arranger. Il existe des versions dédiées des méthodes some() et someObjects() qui acceptent un paramètre de type Map<String,Supplier> . Les clés de cette carte représentent les noms de champs tandis que les fournisseurs correspondants fournissent des valeurs que Test Arranger définira pour vous sur ces champs, par exemple :
Product product = Arranger . some ( Product . class , Map . of ( "name" , () -> value ));Par défaut, les valeurs aléatoires sont générées en fonction du type de champ. Les valeurs aléatoires ne correspondent pas toujours bien aux invariants de classe. Lorsqu'une entité doit toujours être organisée concernant certaines règles concernant les valeurs des champs, vous pouvez fournir un arrangeur personnalisé :
class ProductArranger extends CustomArranger < Product > {
@ Override
protected Product instance () {
Product product = enhancedRandom . nextObject ( Parent . class );
product . setPrice ( BigDecimal . valueOf ( Arranger . somePositiveLong ( 9_999L )));
return product ;
}
} Pour contrôler le processus d'instanciation Product nous devons remplacer la méthode instance() . Dans la méthode, nous pouvons créer l’instance de Product comme nous le souhaitons. Plus précisément, nous pouvons générer des valeurs aléatoires. Pour plus de commodité, nous avons un champ enhancedRandom dans la classe CustomArranger . Dans l'exemple donné, nous générons une instance de Product avec tous les champs ayant des valeurs pseudo-aléatoires, mais nous modifions ensuite le prix en quelque chose d'acceptable dans notre domaine. Ce n’est ni négatif ni inférieur au nombre 10k.
Le ProductArranger est automatiquement (par réflexion) récupéré par l'Arranger et utilisé chaque fois qu'une nouvelle instance de Product est demandée. Cela concerne non seulement les appels directs comme Arranger.some(Product.class) , mais aussi indirects. En supposant qu'il existe une classe Shop avec products de champ de type List<Product> . Lors de l'appel de Arranger.some(Shop.class) , l'arrangeur utilisera ProductArranger pour créer tous les produits stockés dans Shop.products .
Le comportement de l'organisateur de tests peut être configuré à l'aide des propriétés. Si vous créez un fichier arranger.properties et que vous l'enregistrez à la racine du chemin de classe (il s'agira généralement du répertoire src/test/resources/ ), il sera récupéré et les propriétés suivantes seront appliquées :
arranger.root Les arrangeurs personnalisés sont récupérés par réflexion. Toutes les classes étendant CustomArranger sont considérées comme des arrangeurs personnalisés. La réflexion se porte sur un certain package qui par défaut est com.ocado . Cela ne vous convient pas nécessairement. Cependant, avec arranger.root=your_package il peut être remplacé par your_package . Essayez d'avoir le package aussi spécifique que possible, car avoir quelque chose de générique (par exemple juste com qui est le package racine dans de nombreuses bibliothèques) entraînera l'analyse de centaines de classes, ce qui prendra un temps considérable.arranger.randomseed Par défaut, toujours la même graine est utilisée pour initialiser le générateur de valeurs pseudo-aléatoires sous-jacent. En conséquence, les exécutions ultérieures généreront les mêmes valeurs. Pour obtenir un caractère aléatoire entre les exécutions, c'est-à-dire pour toujours commencer avec d'autres valeurs aléatoires, il est nécessaire de définir arranger.randomseed=true .arranger.cache.enable Le processus d'organisation des instances aléatoires prend un certain temps. Si vous créez un grand nombre d'instances et que vous n'avez pas besoin qu'elles soient complètement aléatoires, l'activation du cache peut être la solution. Lorsqu'il est activé, le cache stocke la référence à chaque instance aléatoire et, à un moment donné, l'organisateur de tests arrête d'en créer de nouvelles et réutilise à la place les instances mises en cache. Par défaut, le cache est désactivé.arranger.overridedefaults Test-arranger respecte l'initialisation du champ par défaut, c'est à dire lorsqu'il y a un champ initialisé avec une chaîne vide, l'instance renvoyée par test-arranger a la chaîne vide dans ce champ. Ce n'est pas toujours ce dont vous avez besoin dans les tests, en particulier lorsqu'il existe une convention dans le projet pour initialiser les champs avec des valeurs vides. Heureusement, vous pouvez forcer l'organisateur de tests à écraser les valeurs par défaut avec des valeurs aléatoires. Définissez arranger.overridedefaults sur true pour remplacer l'initialisation par défaut.arranger.maxRandomizationDepth Certaines structures de données de test peuvent générer des chaînes d'objets de n'importe quelle longueur qui se référencent les unes aux autres. Cependant, pour les utiliser efficacement dans un scénario de test, il est crucial de contrôler la longueur de ces chaînes. Par défaut, Test-arrangeur arrête de créer de nouveaux objets au 4ème niveau de profondeur d'imbrication. Si ce paramètre par défaut ne convient pas aux cas de test de votre projet, il peut être ajusté à l'aide de ce paramètre. Lorsque vous disposez d'un enregistrement Java qui pourrait être utilisé comme données de test, mais que vous devez modifier un ou deux de ses champs, la classe Data avec sa méthode de copie fournit une solution. Ceci est particulièrement utile lorsqu'il s'agit d'enregistrements immuables pour lesquels il n'existe pas de moyen évident de modifier directement leurs champs.
La méthode Data.copy vous permet de créer une copie superficielle d'un enregistrement tout en modifiant sélectivement les champs souhaités. En fournissant une carte des remplacements de champs, vous pouvez spécifier les champs qui doivent être modifiés et leurs nouvelles valeurs. La méthode de copie se charge de créer une nouvelle instance de l'enregistrement avec les valeurs de champ mises à jour.
Cette approche vous évite de créer manuellement un nouvel objet d'enregistrement et de définir les champs individuellement, offrant ainsi un moyen pratique de générer des données de test avec de légères variations par rapport aux enregistrements existants.
Dans l'ensemble, la classe Data et sa méthode de copie sauvent la situation en permettant la création de copies superficielles d'enregistrements avec des champs sélectionnés modifiés, offrant ainsi flexibilité et commodité lorsque vous travaillez avec des types d'enregistrements immuables :
Data . copy ( myRecord , Map . of ( "recordFieldName" , () -> "altered value" ));Lorsqu'on teste un projet logiciel, on a rarement l'impression qu'on ne peut pas faire mieux. Dans le cadre de l'organisation des données de test, nous essayons d'améliorer deux domaines avec Test Arranger.
Les tests sont beaucoup plus faciles à comprendre lorsqu'on connaît l'intention du créateur, c'est-à-dire pourquoi le test a été écrit et quels types de problèmes il doit détecter. Malheureusement, il n'est pas extraordinaire de voir des tests avoir dans la section arranger (données) des instructions comme celle-ci :
Product product = Product . builder ()
. withName ( "Some name" )
. withBrand ( "Some brand" )
. withPrice ( new BigDecimal ( "12.99" ))
. withCategory ( "Water, Juice & Drinks / Juice / Fresh" )
...
. build ();Lorsqu'on examine un tel code, il est difficile de dire quelles valeurs sont pertinentes pour le test et lesquelles sont fournies uniquement pour satisfaire certaines exigences non nulles. Si le test porte sur la marque, pourquoi ne pas l'écrire comme ça :
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );Il est désormais évident que la marque est importante. Essayons d'aller plus loin. L'ensemble du test peut ressembler à ceci :
//arrange
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( "Some brand" ) Nous testons maintenant que le rapport a été créé pour la marque "Une certaine marque". Mais est-ce le but ? Il est plus logique de s'attendre à ce que le rapport soit généré pour la même marque à laquelle le produit donné est attribué. Donc ce que nous voulons tester c'est :
//arrange
Product product = Arranger . some ( Product . class );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( product . getBrand ()) Dans le cas où le champ de marque est mutable et que nous craignons que le sut le modifie, nous pouvons stocker sa valeur dans une variable avant de passer à la phase d'action et l'utiliser plus tard pour l'assertion. L'épreuve sera plus longue, mais l'intention reste claire.
Il est à noter que ce que nous venons de faire est une application des modèles de valeur générée et, dans une certaine mesure, de méthode de création décrits dans Modèles de test xUnit : Refactoring Test Code de Gerard Meszaros.
Avez-vous déjà modifié une petite chose dans le code de production et vous êtes retrouvé avec des erreurs dans des dizaines de tests ? Certains d’entre eux signalent un échec d’assertion, d’autres refusent peut-être même de compiler. C'est une odeur de code de chirurgie au fusil de chasse qui vient de jaillir lors de vos tests innocents. Enfin, peut-être pas si innocents, car ils pourraient être conçus différemment, pour limiter les dommages collatéraux causés par de petits changements. Analysons-le à l'aide d'un exemple. Supposons que nous ayons dans notre domaine la classe suivante :
class TimeRange {
private LocalDateTime start ;
private long durationinMs ;
public TimeRange ( LocalDateTime start , long durationInMs ) {
... et qu'il est utilisé dans de nombreux endroits. Surtout dans les tests, sans Test Arranger, en utilisant des instructions comme celle-ci : new TimeRange(LocalDateTime.now(), 3600_000L); Que se passera-t-il si, pour des raisons importantes, nous sommes obligés de changer de classe pour :
class TimeRange {
private LocalDateTime start ;
private LocalDateTime end ;
public TimeRange ( LocalDateTime start , LocalDateTime end ) {
... Il est assez difficile de proposer une série de refactorisations qui transforment l’ancienne version en la nouvelle sans interrompre tous les tests dépendants. Plus probable est un scénario dans lequel les tests sont ajustés un par un à la nouvelle API de la classe. Cela signifie beaucoup de travail pas vraiment passionnant avec de nombreuses questions concernant la valeur souhaitée de la durée (dois-je la convertir soigneusement en end de type LocalDateTime ou s'agissait-il simplement d'une valeur aléatoire pratique). La vie serait beaucoup plus facile avec Test Arranger. Lorsque dans tous les endroits nécessitant simplement TimeRange non nul, nous avons Arranger.some(TimeRange.class) , c'est aussi bon pour la nouvelle version de TimeRange que pour l'ancienne. Cela nous laisse avec ces quelques cas nécessitant TimeRange non aléatoire, mais comme nous utilisons déjà Test Arranger pour révéler l'intention du test, dans chaque cas, nous savons exactement quelle valeur doit être utilisée pour le TimeRange .
Mais ce n’est pas tout ce que nous pouvons faire pour améliorer les tests. Vraisemblablement, nous pouvons identifier certaines catégories de l'instance TimeRange , par exemple les plages du passé, les plages du futur et les plages actuellement actives. Le TimeRangeArranger est un excellent endroit pour organiser cela :
class TimeRangeArranger extends CustomArranger < TimeRange > {
private final long MAX_DISTANCE = 999_999L ;
@ Override
protected TimeRange instance () {
LocalDateTime start = enhancedRandom . nextObject ( LocalDateTime . class );
LocalDateTime end = start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
public TimeRange fromPast () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime end = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( end . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )), end );
}
public TimeRange fromFuture () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )));
}
public TimeRange currentlyActive () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
LocalDateTime end = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
} Une telle méthode de création ne doit pas être créée à l'avance mais plutôt correspondre aux cas de tests existants. Néanmoins, il est possible que TimeRangeArranger couvre tous les cas où des instances de TimeRange sont créées pour des tests. En conséquence, à la place des appels de constructeur avec plusieurs paramètres mystérieux, nous avons un arrangeur avec une méthode bien nommée expliquant la signification du domaine de l'objet créé et aidant à comprendre l'intention du test.
Nous avons identifié deux niveaux de créateurs de données de test lors de l'examen des défis résolus par Test Arranger. Pour que le tableau soit complet, nous devons en mentionner au moins un autre, à savoir les luminaires. Pour les besoins de cette discussion, nous pouvons supposer que Fixture est une classe conçue pour créer des structures complexes de données de test. L'arrangeur personnalisé se concentre toujours sur une classe, mais vous pouvez parfois observer dans vos cas de test des constellations récurrentes de deux classes ou plus. Il peut s'agir de l'Utilisateur et de son compte bancaire. Il peut y avoir un CustomArranger pour chacun d'eux, mais pourquoi ignorer le fait qu'ils se réunissent souvent. C’est à ce moment-là qu’il faut commencer à réfléchir à un luminaire. Il sera responsable de la création du compte utilisateur et du compte bancaire (vraisemblablement en utilisant des arrangeurs personnalisés dédiés) et de les relier entre eux. Les appareils sont décrits en détail, y compris plusieurs variantes d'implémentation dans xUnit Test Patterns: Refactoring Test Code par Gerard Meszaros.
Nous avons donc trois types de blocs de construction dans les classes de test. Chacun d’entre eux peut être considéré comme la contrepartie d’un concept (building block Domain Driven Design) issu du code de production : 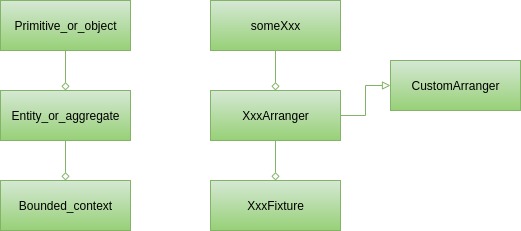
En surface, on y trouve des primitifs et des objets simples. C’est quelque chose qui apparaît même dans les tests unitaires les plus simples. Vous pouvez organiser ces données de test avec les méthodes someXxx de la classe Arranger .
Vous pouvez donc avoir des services nécessitant des tests qui fonctionnent uniquement sur les instances User ou à la fois sur User et sur d'autres classes contenues dans la classe User , comme une liste d'adresses. Pour couvrir de tels cas, un arrangeur personnalisé est généralement requis, c'est-à-dire le UserArranger . Il créera des instances de User respectant toutes les contraintes et invariants de classe. De plus, il récupérera AddressArranger , lorsqu'il existe, pour remplir la liste d'adresses avec des données valides. Lorsque plusieurs cas de test nécessitent un certain type d'utilisateur, par exemple des utilisateurs sans domicile avec une liste d'adresses vide, une méthode supplémentaire peut être créée dans UserArranger. Par conséquent, chaque fois qu'il sera nécessaire de créer une instance User pour les tests, il suffira de regarder dans UserArranger et de sélectionner une méthode de fabrique adéquate ou simplement d'appeler Arranger.some(User.class) .
Le cas le plus délicat concerne les tests dépendant de grandes structures de données. Dans le commerce électronique, il peut s'agir d'une boutique contenant de nombreux produits, mais également de comptes d'utilisateurs avec un historique d'achats. Organiser les données pour de tels cas de test n'est généralement pas trivial et répéter une telle chose ne serait pas judicieux. Il est bien préférable de le stocker dans une classe dédiée sous une méthode bien nommée, comme shopWithNineProductsAndFourCustomers , et de le réutiliser dans chacun des tests. Nous recommandons fortement d'utiliser une convention de dénomination pour ces classes, afin de les rendre faciles à trouver, notre suggestion est d'utiliser le suffixe Fixture . Finalement, nous pourrions nous retrouver avec quelque chose comme ceci :
class ShopFixture {
Repository repo ;
public void shopWithNineProductsAndFourCustomers () {
Arranger . someObjects ( Product . class , 9 )
. forEach ( p -> repo . save ( p ));
Arranger . someObjects ( Customer . class , 4 )
. forEach ( p -> repo . save ( p ));
}
}La dernière version de l'organisateur de tests est compilée à l'aide de Java 17 et doit être utilisée dans le runtime Java 17+. Cependant, il existe également une branche Java 8 pour la rétrocompatibilité, couverte par les versions 1.4.x.


