Combiner des algorithmes de classification pour prédire le vainqueur de chaque match de baseball professionnel
Kyle Johnson
Article de blog : https://kylejohnson363.github.io/sourcing_mlb_data
La capacité de prédire l’avenir, même légèrement meilleure qu’un tirage au sort, peut être extrêmement lucrative. Sans boule de cristal, la meilleure chose que nous puissions faire est d’exploiter la puissance de grands ensembles de données pour trouver des modèles cachés qui peuvent être utilisés pour donner un léger avantage dans la réalisation de grandes quantités de prédictions. Le baseball est parfaitement adapté à cela car pratiquement tout ce qui se passe est quantifiable et se répète des centaines de fois par match et chaque match se répète des milliers de fois par an. L'objectif de ce projet est d'utiliser des techniques d'apprentissage automatique pour faire des prédictions sur les matchs de la Major League Baseball d'une manière meilleure que celle des créateurs de livres de Vegas. Être capable de prédire correctement 70 % des jeux ne sert à rien si Vegas a également prédit correctement ces mêmes jeux ; Afin d'avoir un modèle utile, je dois en créer un qui rapporte constamment de l'argent en pariant contre les bookmakers de Vegas.
Veuillez consulter le cahier intitulé « Summary_Start_Here » pour une feuille de route détaillée de ce projet afin de bien comprendre le processus.
Les données de ce projet proviennent de l'API de MLB Advanced Media, de baseball-reference.com et de sportsbookreviewonline.com, puis prétraitées sous une forme utile. Quatre modèles de classification ont ensuite été créés et optimisés, qui ont ensuite utilisé une procédure de vote pour effectuer une prédiction finale. 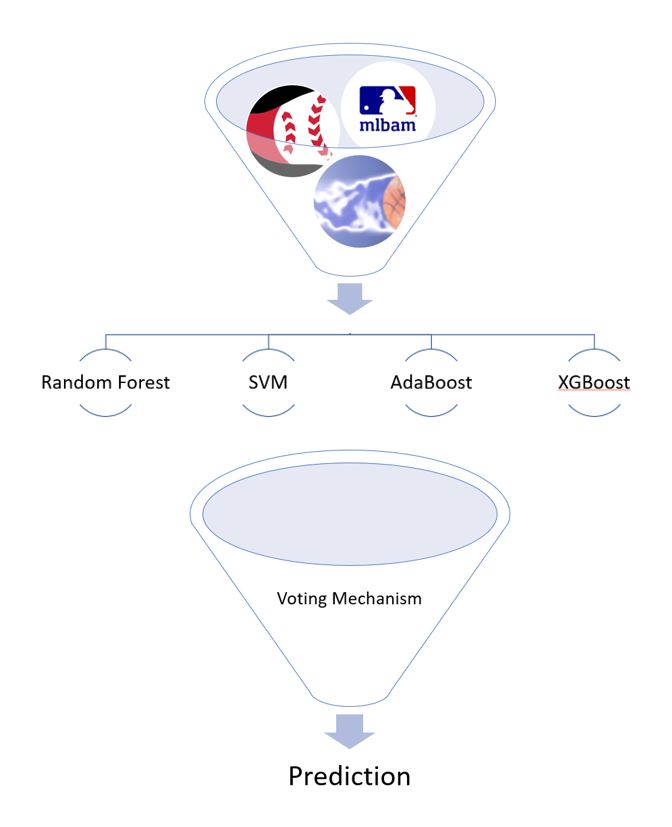
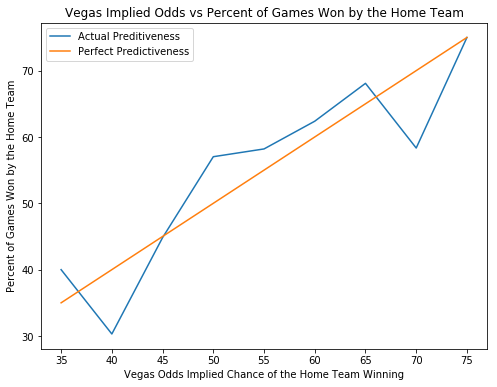
La référence en matière de performance pour ce projet est constituée par les prédictions créées par les créateurs de paris de Vegas. Si le modèle créé peut gagner de l’argent en pariant contre Vegas, alors nous savons que le modèle a une valeur ajoutée. Vous trouverez ci-dessous un graphique montrant la relation entre la confiance de Vegas dans une prédiction et le pourcentage de temps pendant lequel cette prédiction est correcte. Les lignes orange et bleue sont assez corrélées, ce qui signifie que Vegas est assez bon pour prédire les matchs, ce qui est logique car sinon, ils feraient faillite très rapidement.
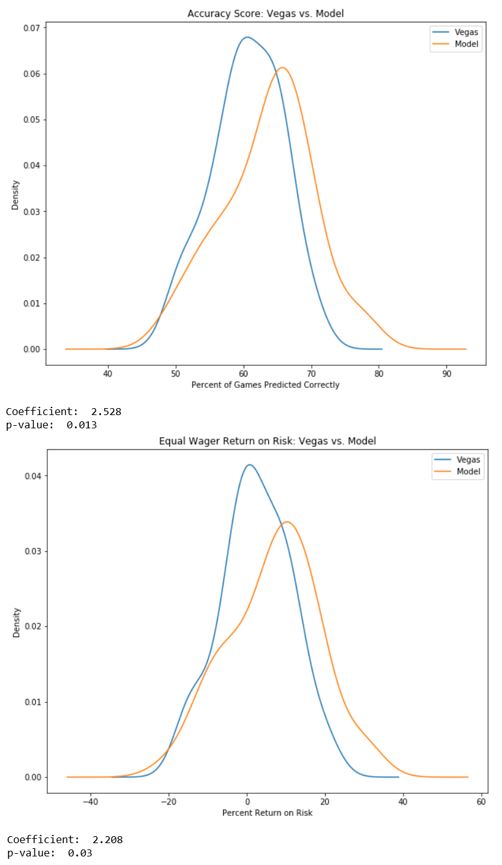
Le modèle final a pu surpasser les fabricants de cotes de Vegas avec une signification statistique à la fois en termes de précision des choix et de retour sur risque généré en plaçant des paris sur les jeux prédits.
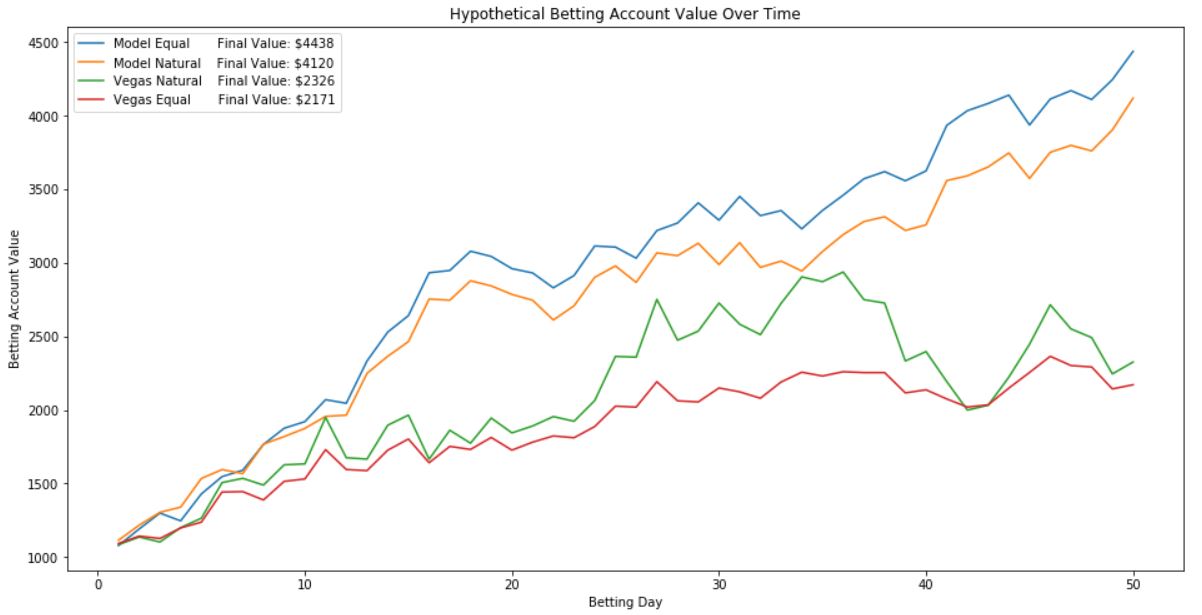
Vous trouverez ci-dessous une visualisation des performances d'un compte de paris simulé sur les données hors échantillon, à partir de 1 000 $.
-J'ai pu créer un modèle qui prédit les matchs de la MLB de manière plus précise et plus rentable que les cotes de Vegas, de manière statistiquement significative. J'ai fait cela en interrogeant les données de plusieurs bases de données de baseball en ligne, puis en optimisant plusieurs modèles de classification différents, avant de les combiner pour voter sur le résultat de chaque match.
-Curieusement, il semble que toujours parier avec les cotes de Vegas soit une stratégie rentable, mais utiliser le modèle créé dans ce projet est potentiellement presque deux fois plus rentable. Cela nous indique que Vegas est bon pour prédire les matchs de la MLB, mais qu'il existe encore des inefficacités qui peuvent être exploitées.
Utilisez plus de types de données (statistiques nouvelles et très avancées) et plus de jeux des saisons précédentes.
Optimisez le nombre de jours dans la catégorie « récente » des statistiques.
Automatisez le processus de collecte des données nécessaires pour les jeux d'aujourd'hui et publiez un rapport sur les jeux sur lesquels parier.
Créez des « prédictions mineures » telles que les courses à marquer ou à autoriser et intégrez ces prédictions dans le modèle de classification.


