This template can be used for both Azure AI Studio and Azure Machine Learning.It can be used for both AZURE and LOCAL execution.It supports all types of flow - python Class flows, Function flows and YAML flows.It supports Github, Azure DevOps and Jenkins CI/CD orchestration.It supports pure python based Evaluation as well using promptflow-evals package.It should be used for INNER-LOOP Experimentation and Evaluation.It should be used for OUTER-LOOP Deployment and Inferencing. NOTE: A new FAQ section is added to help Engineers, Data Scientist and developers find answers to general questions on configuring and using this template.
FAQ ICI
Les Large Language Model Operations, ou LLMOps, sont devenues la pierre angulaire d'une ingénierie rapide efficace et du développement et du déploiement d'applications induits par LLM. Alors que la demande d'applications induites par le LLM continue de monter en flèche, les organisations ont besoin d'un processus cohérent et rationalisé pour gérer leur cycle de vie de bout en bout.
L’essor de l’IA et des grands modèles linguistiques (LLM) a transformé diverses industries, permettant le développement d’applications innovantes dotées de capacités de compréhension et de génération de textes semblables à celles des humains. Cette révolution a ouvert de nouvelles possibilités dans des domaines tels que le service client, la création de contenu et l'analyse de données.
À mesure que les LLM évoluent rapidement, l’importance de Prompt Engineering devient de plus en plus évidente. Prompt Engineering joue un rôle crucial dans l’exploitation de tout le potentiel des LLM en créant des invites efficaces adaptées à des scénarios commerciaux spécifiques. Ce processus permet aux développeurs de créer des solutions d'IA sur mesure, rendant l'IA plus accessible et utile à un public plus large.
Il s'agit d'un cadre d'expérimentation et d'évaluation pour Prompt Flow. Il ne s'agit tout simplement pas de pipelines CI/CD pour Prompt Flow, bien qu'il le prenne en charge. Il dispose d'un riche ensemble de fonctionnalités pour l'expérimentation, l'évaluation, le déploiement et la surveillance de Prompt Flow. Il s’agit d’une solution complète de bout en bout pour l’opérationnalisation de Prompt Flow.
Le modèle prend en charge à la fois Azure AI Studio et Azure Machine Learning. Selon la configuration, le modèle peut être utilisé à la fois pour Azure AI Studio et Azure Machine Learning. Il offre une expérience de migration transparente pour l'expérimentation, l'évaluation et le déploiement de Prompt Flow entre les services.
Ce modèle prend en charge différents types de flux, vous permettant de définir et d'exécuter des flux de travail en fonction de vos besoins spécifiques. Les deux principaux types de flux pris en charge sont :
Flux flexibles
Flux de graphiques acycliques dirigés (DAG)
L'une des fonctionnalités puissantes de ce projet est sa capacité à détecter automatiquement le type de flux et à exécuter le flux en conséquence. Cela vous permet d’expérimenter différents types de flux et de choisir celui qui correspond le mieux à vos besoins.
Ce modèle prend en charge :
La gestion des flux basés sur Large Language, depuis l'expérimentation locale jusqu'au déploiement en production, est loin d'être simple et ne constitue pas une tâche unique.
Chaque flux a son cycle de vie unique, de l'expérimentation initiale au déploiement, et chaque étape présente son propre ensemble de défis.
Les organisations gèrent souvent plusieurs flux simultanément, chacun avec ses objectifs, ses exigences et ses complexités. Cela peut rapidement devenir écrasant sans outils de gestion appropriés.
Cela implique de gérer plusieurs flux, leurs cycles de vie uniques, d'expérimenter diverses configurations et d'assurer des déploiements fluides.
C'est là qu'intervient LLMOps avec flux Prompt . LLMOps avec flux Prompt est un « modèle et des conseils LLMOps » pour vous aider à créer des applications infusées LLM à l'aide du flux Prompt. Il offre les fonctionnalités suivantes :
Hébergement de code centralisé : ce référentiel prend en charge l'hébergement de code pour plusieurs flux en fonction du flux d'invite, fournissant ainsi un référentiel unique pour tous vos flux. Considérez cette plate-forme comme un référentiel unique où réside tout votre code de flux d'invite. C'est comme une bibliothèque pour vos flux, ce qui facilite la recherche, l'accès et la collaboration sur différents projets.
Gestion du cycle de vie : chaque flux bénéficie de son propre cycle de vie, permettant des transitions fluides de l'expérimentation locale au déploiement en production.
Expérimentation de variantes et d'hyperparamètres : expérimentez plusieurs variantes et hyperparamètres, en évaluant facilement les variantes de flux. Les variantes et les hyperparamètres sont comme les ingrédients d’une recette. Cette plateforme vous permet d'expérimenter différentes combinaisons de variantes sur plusieurs nœuds d'un flux.
Déploiement A/B : mettez en œuvre de manière transparente des déploiements A/B, vous permettant de comparer facilement différentes versions de flux. Tout comme dans les tests A/B traditionnels pour les sites Web, cette plateforme facilite le déploiement A/B pour des flux de flux rapides. Cela signifie que vous pouvez facilement comparer différentes versions d’un flux dans un environnement réel pour déterminer laquelle est la plus performante.
Relations plusieurs-à-plusieurs ensembles de données/flux : acceptez plusieurs ensembles de données pour chaque flux de norme et d'évaluation, garantissant ainsi la polyvalence des tests et des évaluations de flux. La plateforme est conçue pour accueillir plusieurs ensembles de données pour chaque flux.
Cibles de déploiement multiples : le référentiel prend en charge le déploiement de flux vers des calculs Kubernetes et Azure gérés via la configuration, garantissant que vos flux peuvent évoluer selon les besoins.
Rapports complets : générez des rapports détaillés pour chaque variante de configuration, vous permettant de prendre des décisions éclairées. Fournit une collecte de métriques détaillée pour toutes les variantes d’exécutions et d’expériences en masse, permettant des décisions basées sur les données dans des fichiers CSV et HTML.
Propose BYOF (apportez vos propres flux). Une plate-forme complète pour développer plusieurs cas d'utilisation liés aux applications infusées LLM.
Offre un développement basé sur la configuration . Pas besoin d’écrire un code passe-partout détaillé.
Fournit l’exécution d’ expérimentations et d’évaluations rapides localement ainsi que sur le cloud.
Fournit des blocs-notes pour l’évaluation locale des invites. Fournit une bibliothèque de fonctions pour l’expérimentation locale.
Test des points de terminaison dans le pipeline après le déploiement pour vérifier sa disponibilité et son état de préparation.
Fournit un Human-in-loop facultatif pour valider les métriques d’invite avant le déploiement.
LLMOps avec Prompt Flow offre des fonctionnalités pour les applications simples et complexes infusées de LLM. Il est entièrement personnalisable selon les besoins de l'application.
Chaque cas d'utilisation (ensemble de flux standards d'invite et flux d'évaluation) doit suivre la structure de dossiers comme indiqué ici :
De plus, il existe un fichier experiment.yaml qui configure le cas d'utilisation (voir la description et les spécifications du fichier pour plus de détails). Il existe également un fichier sample-request.json contenant des données de test pour tester les points de terminaison après le déploiement.
Le dossier « .azure-pipelines » contient les pipelines Azure DevOps communs à la plateforme et toute modification apportée à ceux-ci aura un impact sur l’exécution de tous les flux.
Le dossier « .github » contient les workflows Github pour la plateforme ainsi que les cas d'utilisation. Ceci est un peu différent d'Azure DevOps car tous les workflows Github doivent se trouver dans ce dossier unique pour être exécutés.
Le dossier « .jenkins » contient les pipelines déclaratifs Jenkins pour la plateforme ainsi que les cas d'utilisation et les tâches individuelles.
Le dossier « docs » contient de la documentation pour des guides étape par étape pour la configuration liée à Azure DevOps, Github Workflow et Jenkins.
Le dossier 'llmops' contient tout le code lié à l'exécution, à l'évaluation et au déploiement du flux.
Le dossier 'dataops' contient tout le code lié au déploiement du pipeline de données.
Le dossier « local_execution » contient des scripts Python pour exécuter localement le flux standard et le flux d'évaluation.
Le projet comprend 6 exemples illustrant différents scénarios :
Emplacement : ./web_classification Importance : montre un résumé du contenu d'un site Web avec plusieurs variantes, mettant en valeur la flexibilité et les options de personnalisation disponibles dans le modèle.
Emplacement : ./named_entity_recognition Importance : présente l'extraction d'entités nommées à partir du texte, ce qui est utile pour diverses tâches de traitement du langage naturel et d'extraction d'informations.
Emplacement : ./math_coding Importance : présente la capacité à effectuer des calculs mathématiques et à générer des extraits de code, soulignant la polyvalence du modèle dans la gestion des tâches de calcul.
Emplacement : ./chat_with_pdf Importance : Démontre une interface conversationnelle pour interagir avec les documents PDF, en tirant parti de la puissance de la génération augmentée par récupération (RAG) pour fournir des réponses précises et pertinentes.
Emplacement : ./function_flows Importance : démontre la génération d'extraits de code basés sur les invites de l'utilisateur, démontrant le potentiel d'automatisation des tâches de génération de code.
Emplacement : ./class_flows Importance : présente une application de chat construite à l'aide de flux basés sur des classes, illustrant la structuration et l'organisation d'interfaces conversationnelles plus complexes.
Le référentiel facilite le déploiement sur Kubernetes, Kubernetes ARC, Azure Web Apps et le calcul géré AzureML ainsi que le déploiement A/B pour le calcul géré AzureML.
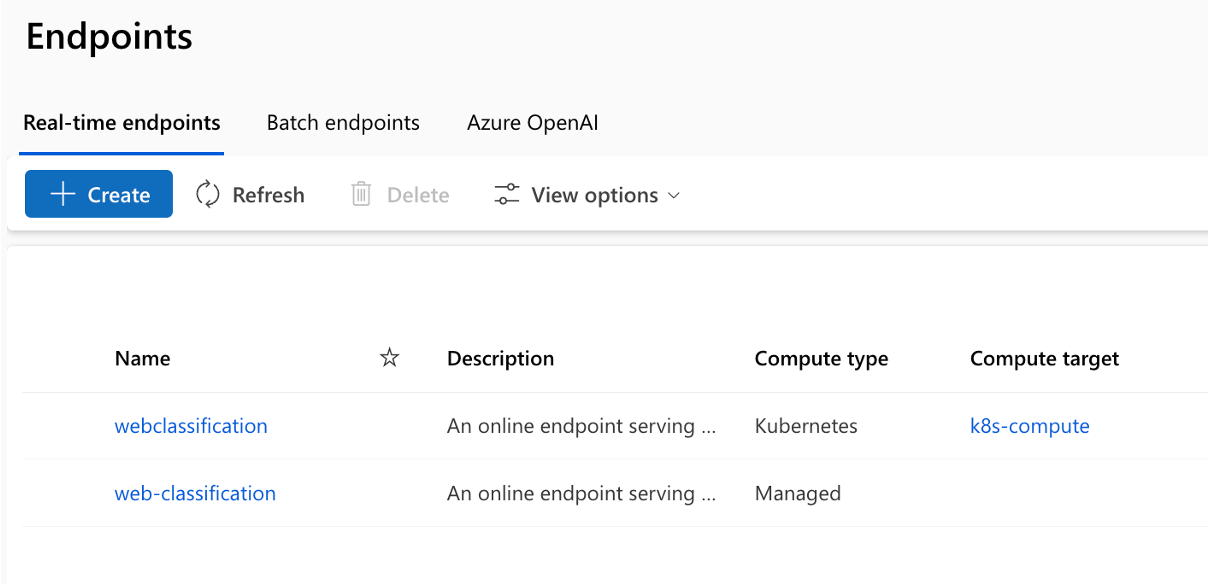
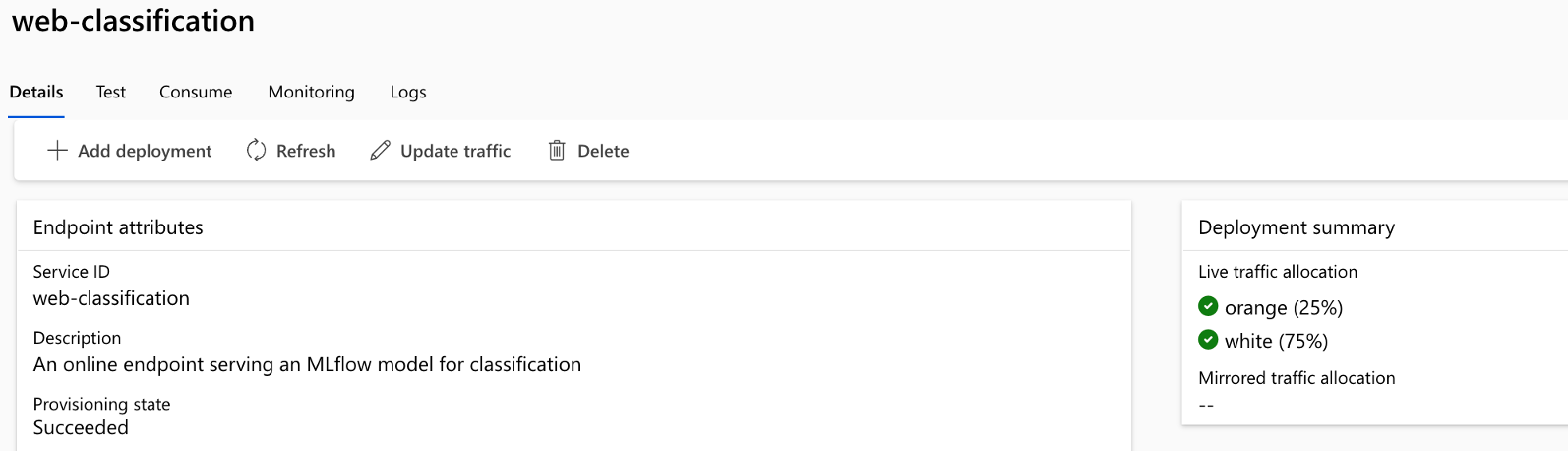
L'exécution du pipeline se compose de plusieurs étapes et tâches dans chaque étape :
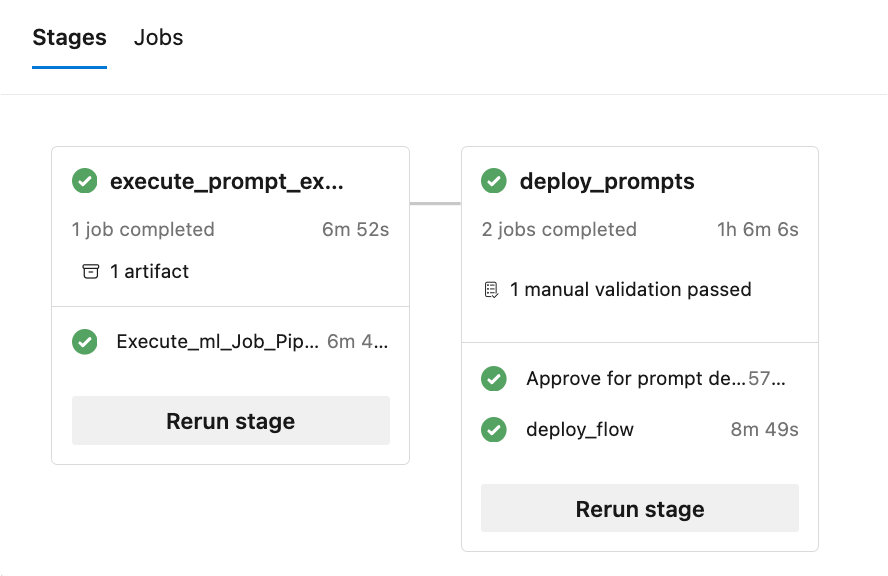
Le dépôt génère plusieurs rapports (des exemples d'exécutions d'expériences et de métriques sont présentés) :


Pour exploiter les capacités de l' exécution locale , suivez ces étapes d'installation :
git clone https://github.com/microsoft/llmops-promptflow-template.gitaoai . Ajoutez une ligne aoai={"api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"} avec des valeurs mises à jour pour api_key et api_base. Si des connexions supplémentaires portant des noms différents sont utilisées dans vos flux, elles doivent être ajoutées en conséquence. Actuellement, utilisez AzureOpenAI en tant que fournisseur, tel que pris en charge. experiment_name=
connection_name_1={ " api_key " : " " , " api_base " : " " , " api_type " : " azure " , " api_version " : " 2023-03-15-preview " }
connection_name_2={ " api_key " : " " , " api_base " : " " , " api_type " : " azure " , " api_version " : " 2023-03-15-preview " }python -m pip install promptflow promptflow-tools promptflow-sdk jinja2 promptflow[azure] openai promptflow-sdk[builtins] python-dotenv
Apportez ou écrivez vos flux dans le modèle en fonction de la documentation ici.
Écrivez des scripts Python similaires aux exemples fournis dans le dossier local_execution.
DataOps combine des aspects du DevOps, des méthodologies agiles et des pratiques de gestion des données pour rationaliser le processus de collecte, de traitement et d'analyse des données. DataOps peut aider à apporter de la discipline dans la construction des ensembles de données (formation, expérimentation, évaluation, etc.) nécessaires au développement d'applications LLM.
Les pipelines de données sont séparés des flux d'ingénierie rapides. Les pipelines de données créent les ensembles de données et les ensembles de données sont enregistrés en tant qu'actifs de données dans Azure ML pour les flux à consommer. Cette approche permet de faire évoluer et de dépanner indépendamment différentes parties du système.
Pour plus de détails sur la façon de démarrer avec DataOps, veuillez suivre ce document - Comment configurer DataOps.
Ce projet accueille les contributions et suggestions. La plupart des contributions nécessitent que vous acceptiez un contrat de licence de contributeur (CLA) déclarant que vous avez le droit de nous accorder, et que vous nous accordez effectivement, le droit d'utiliser votre contribution. Pour plus de détails, visitez https://cla.opensource.microsoft.com.
Lorsque vous soumettez une pull request, un robot CLA déterminera automatiquement si vous devez fournir un CLA et décorera le PR de manière appropriée (par exemple, vérification du statut, commentaire). Suivez simplement les instructions fournies par le bot. Vous n’aurez besoin de le faire qu’une seule fois pour tous les dépôts utilisant notre CLA.
Ce projet a adopté le code de conduite Microsoft Open Source. Pour plus d’informations, consultez la FAQ sur le code de conduite ou contactez [email protected] pour toute question ou commentaire supplémentaire.
Ce projet peut contenir des marques ou des logos pour des projets, des produits ou des services. L'utilisation autorisée des marques ou logos Microsoft est soumise et doit respecter les directives relatives aux marques et aux marques de Microsoft. L'utilisation des marques ou logos Microsoft dans les versions modifiées de ce projet ne doit pas prêter à confusion ni impliquer le parrainage de Microsoft. Toute utilisation de marques ou de logos tiers est soumise aux politiques de ces tiers.
Ce projet a adopté le code de conduite Microsoft Open Source. Pour plus d’informations, consultez la FAQ sur le code de conduite ou contactez [email protected] pour toute question ou commentaire supplémentaire.
Droit d'auteur (c) Microsoft Corporation. Tous droits réservés.
Sous licence MIT.


