La conception de tableaux cumulatifs est un outil d'ingénierie de données extrêmement puissant que tous les ingénieurs de données devraient connaître.
Cette conception produit des tableaux qui peuvent fournir des analyses efficaces sur des périodes arbitrairement longues (jusqu'à des milliers de jours).
Voici un diagramme de la conception du pipeline de haut niveau pour ce modèle :
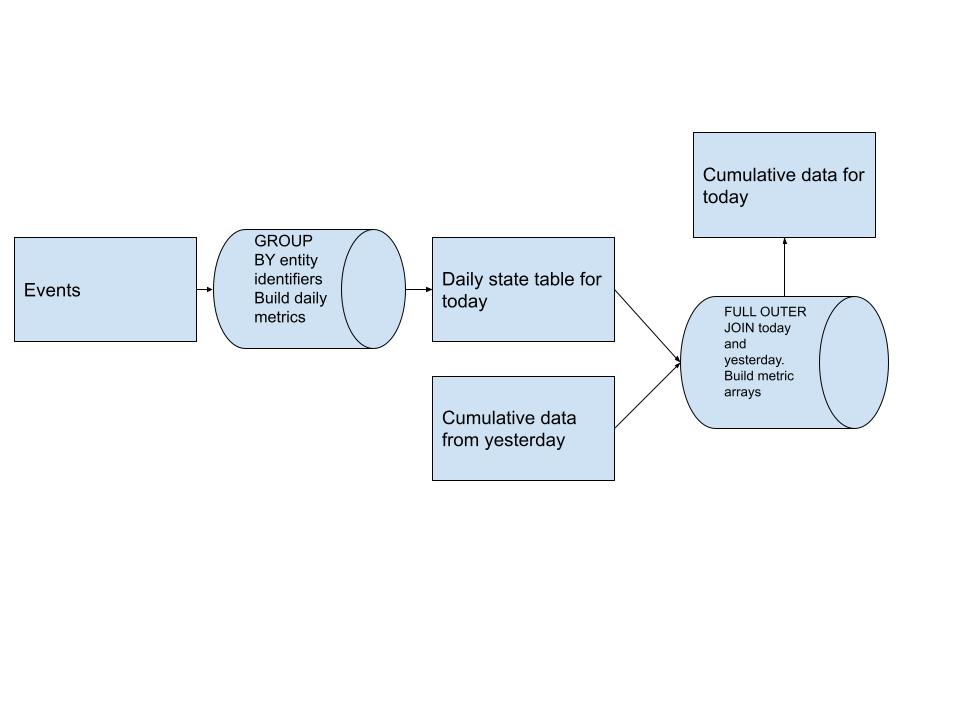
Nous construisons dans un premier temps notre tableau de mesures quotidiennes qui est à la base de notre entité. Ces données sont dérivées de toutes les sources d'événements dont nous disposons en amont.
Après avoir obtenu nos métriques quotidiennes, nous FULL OUTER JOIN la table cumulative d'hier avec les données quotidiennes d'aujourd'hui et construisons nos tableaux de métriques pour chaque utilisateur. Cela nous permet d’introduire la nouvelle histoire sans avoir à la scanner en entier. (un gros gain de performances)
Ces tableaux de métriques nous permettent de répondre facilement aux requêtes sur l'historique de tous les utilisateurs en utilisant des éléments comme ARRAY_SUM pour calculer la métrique souhaitée, quelle que soit la période autorisée par le tableau.
Plus la période de votre analyse est longue, plus ce modèle devient critique !!
Toute la syntaxe de requête utilise la syntaxe et les fonctions Presto/Trino. Cet exemple devra être modifié pour d'autres variantes de SQL !
Nous utiliserons les dates :
- 01/01/2022, comme aujourd'hui en termes de flux d'air, nous sommes
{{ ds }}- 31/12/2021 comme hier dans les termes des modèles Airflow, c'est
{{ yesterday_ds}}
Dans cet exemple, nous verrons comment créer cette conception pour calculer les utilisateurs actifs quotidiens, hebdomadaires et mensuels ainsi que les likes, les commentaires et les partages des utilisateurs.
Notre table source dans ce cas est events .
event_type qui est like , comment , share ou viewIl est tentant de penser que la solution à ce problème consiste à exploiter un pipeline du genre
SELECT
COUNT(DISTINCT user_id) as num_monthly_active_users,
COUNT(CASE WHEN event_type = 'like' THEN 1 END) as num_likes_30d,
COUNT(CASE WHEN event_type = 'comment' THEN 1 END) as num_comments_30d,
COUNT(CASE WHEN event_type = 'share' THEN 1 END) as num_shares_30d,
...
FROM events
WHERE event_date BETWEEN DATE_SUB('2022-01-01', 30), AND '2022-01-01'
Le problème est que nous analysons chaque jour 30 jours de données d’événements pour produire ces chiffres. Un pipeline plutôt inutile, mais simple. Il devrait y avoir un moyen de n'analyser les données de l'événement qu'une seule fois et de les combiner avec les résultats des 29 jours précédents, n'est-ce pas ? Pouvons-nous créer une structure de données dans laquelle un data scientist peut interroger nos données et connaître facilement le nombre d'actions qu'un utilisateur a effectuées au cours des N derniers jours ?
Cette conception est assez simple avec seulement 3 étapes :
GROUP BY user_id , puis comptez-les comme actifs quotidiennement s'ils ont des événementsCOUNT(CASE WHEN event_type = 'like' THEN 1 END) pour déterminer également le nombre de likes, de commentaires et de partages quotidiensFULL OUTER JOIN ces deux ensembles de données today.user_id = yesterday.user_idCOALESCE(today.user_id, yesterday.user_id) as user_id pour garder une trace de tous les utilisateurs.activity_array . Nous voulons uniquement que activity_array stocke les données des 30 derniers joursCARDINALITY(activity_array) < 30 pour comprendre si nous pouvons simplement ajouter la valeur d'aujourd'hui au début du tableau ou devons-nous découper un élément à la fin du tableau avant d'ajouter la valeur d'aujourd'hui au débutCOALESCE(t.is_active_today, 0) pour mettre des valeurs nulles dans le tableau lorsqu'un utilisateur n'est pas actifactivity_array mais également pour les likes, les commentaires et les partages !CASE WHEN ARRAY_SUM(activity_array) > 0 THEN 1 ELSE 0 END nous donne des actifs mensuels puisque nous limitons la taille du tableau à 30CASE WHEN ARRAY_SUM(SLICE(activity_array, 1, 7)) > 0 THEN 1 ELSE 0 END nous donne un actif hebdomadaire puisque nous ne vérifions que les 7 premiers éléments du tableau (c'est-à-dire les 7 derniers jours)ARRAY_SUM(SLICE(like_array, 1, 7)) as num_likes_7d nous donne le nombre de likes que cet utilisateur a fait au cours des 7 derniers joursARRAY_SUM(like_array) as num_likes_30d nous donne le nombre de likes que cet utilisateur a fait au cours des 30 derniers jours depuis que le tableau est fixé à cette tailledepends_on_past: True

