iceriver oc
ver ASICs
Micrologiciel modifié pour tous les ASIC IceRiver, ajoutant un contrôle d'horloge et de tension, des graphiques de capteurs, une connexion et un accès API correctement sécurisés, ainsi que d'autres avantages.
OC/OV personnalisables, frais minimes au profit de la communauté, aucune modification inutile sur votre appareil.
Les fichiers du micrologiciel peuvent être téléchargés à partir de la section Versions sur le côté droit de cette page.
Si vous rencontrez des problèmes, me trouver (pbfarmer) sur Kaspa Discord entraînera probablement la réponse/résolution la plus rapide.
Aucun de ces firmwares ne serait possible sans les efforts d'un certain nombre de personnes en matière de tests et de commentaires.
Cependant, une personne en particulier a sacrifié ses machines dès le début, m'accordant un accès direct pour le développement, me permettant de risquer ses machines tout en testant de toutes nouvelles fonctionnalités, et subissant de nombreuses interruptions de minage lors des fréquentes mises à jour et redémarrages.
Cette personne s'appelle Onslivion sur Discord - ce serait génial si vous pouviez lui envoyer un remerciement sur Kaspa Discord, et peut-être même lui envoyer un pourboire ou une partie de votre hashrate :
kaspa:qzh2xglq33clvzm8820xsj7nnvtudaulnewxwl2kn0ydw9epkqgs2cjw6dh3y
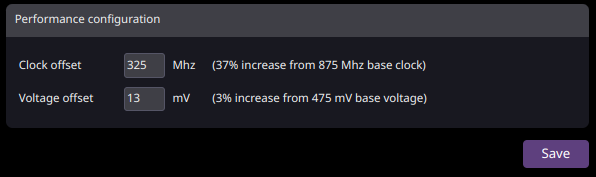
Les paramètres d'horloge et de tension ont été ajoutés à la page « Mineur ». L'horloge peut être augmentée/diminuée jusqu'à n'importe quelle valeur entière (dans les limites matérielles). Les modifications prennent effet immédiatement sans redémarrage, mais notez que les augmentations d'horloge sont appliquées progressivement par incréments de 25 MHz toutes les 30 s. Par conséquent, cela peut prendre un certain temps pour atteindre la pleine vitesse, peut-être même environ 10 minutes, selon l'ampleur du décalage que vous choisissez.
La tension peut également être augmentée/diminuée jusqu'à n'importe quelle valeur entière (dans les limites matérielles), les modifications prenant effet immédiatement. Les paramètres seront arrondis au multiple le plus proche de 6,25 mV en interne pour tout sauf le KS0 Pro. Un modèle simple à garder à l'esprit est que pour chaque augmentation de 25 mV, les incréments appropriés sont 7 mv-6 mv-6 mv-6 mv, ou par exemple 7, 13, 19, 25 pour les premiers 25 mv.
Pour le KS0 Pro, la tension peut être ajustée par incréments de 2 mV.
LE CONTRÔLE DE TENSION N'EST PAS DISPONIBLE POUR LE KS3/M/L POUR LE MOMENT.
IMPORTANT : IL N'Y A ACTUELLEMENT AUCUN GARDE-CORPS, NI AUCUNE LIMITE IMPLIQUÉE PAR CE LOGICIEL, NI HORLOGES NI TENSION, DONC À UTILISER AVEC PRUDENCE.
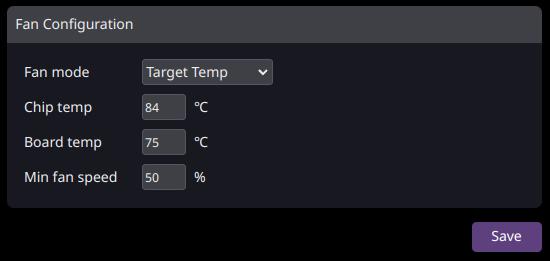
Un nouveau mode de ventilateur a été ajouté qui ajuste automatiquement la vitesse du ventilateur pour maintenir les températures maximales de la puce de hachage et de la carte. Les températures sont lues toutes les 10 secondes et la vitesse du ventilateur est ajustée si nécessaire.
Attention, ce réglage ne garantit pas la température réglée. Elle peut être dépassée jusqu'à ~5 C pendant le démarrage ou d'autres périodes dynamiques, mais elle doit se stabiliser à ou près de la température demandée.
Si vous constatez que les températures cibles sont dépassées au-delà de votre confort pendant le démarrage ou d'autres périodes dynamiques, vous devez augmenter la vitesse minimale du ventilateur.
Les vitesses de ventilateur fixes seront également désormais réappliquées au démarrage, après un délai d'environ 1 à 2 minutes, bien qu'il s'agisse d'une application unique. Cela signifie que si le logiciel IceRiver sous-jacent décide de modifier à nouveau la vitesse du ventilateur pour une raison quelconque, ce mode ne réappliquera pas votre paramètre. Pensez à utiliser le mode « Target Temp » avec une vitesse minimale de ventilateur appropriée comme alternative.
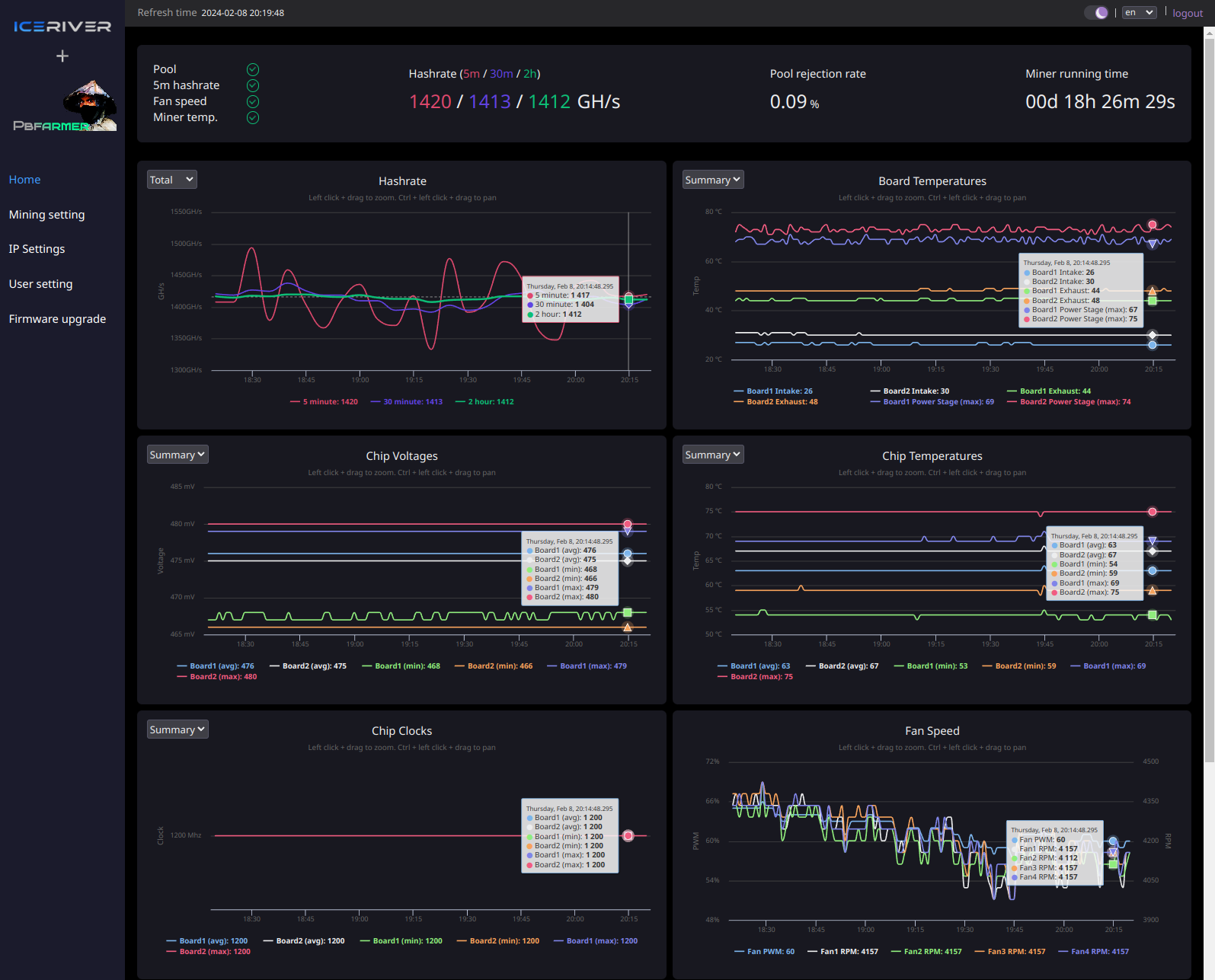
Deux heures de graphiques ont été ajoutées pour toutes les métriques des puces, avec des filtres pour les résumés (par carte min/max/avg), la carte ou toutes les puces.
Une température de puce de 80°C semble donner des performances de hachage idéales (bien que cela puisse être difficile sur KS0/Pro sans modules de refroidissement.) Aucune indication n'a été fournie par IceRiver quant aux limites de température de puce sûres, mais leur logiciel de mineur semble limiter les augmentations d'horloge au-dessus de 95°C. , et limitera en fait les horloges au-dessus de 110 °C. Il est probablement prudent de suivre au moins les directives générales des G/CPU (par exemple, zone d'avertissement > 90 °C, zone de danger > 95 °C, zone critique > 105 °C).
Veuillez noter que la tension en temps réel ne correspondra jamais à votre réglage : les conducteurs sous charge subissent une chute de tension, ce qui signifie que la tension de fonctionnement sera toujours inférieure à votre réglage de tension, une charge plus importante entraînant une chute plus importante. La tension de la puce sera remplacée par la consommation électrique pour le KS5L/M, car aucune lecture de tension de la puce n'est disponible. Une limite logicielle de 3 350 W est appliquée sur ces modèles, où les cœurs seront désactivés par groupes de 4 si vous dépassez cette limite.
Des graphiques de température de la carte ont été ajoutés pour tous les modèles, qui incluent les températures des capteurs d'admission et d'échappement, ainsi que les températures de l'étage de puissance (pilote) pour KS0/Pro/Ultra, KS1 et KS2. En mode résumé, la température maximale de l'étage de puissance est affichée pour chaque carte, tandis qu'en mode carte, la température maximale de l'étage de puissance est affichée pour chaque groupe/contrôleur (PSG). La température de fonctionnement maximale recommandée est de 125 °C selon la documentation de la puce, bien qu'il soit probablement sage de conserver une marge saine en dessous de cette température.
Veuillez noter que la température n'est pas le seul facteur à prendre en compte pour un fonctionnement sain. La consommation de puissance/courant est également une préoccupation, pour laquelle nous n'avons actuellement aucune visibilité ni spécifications.
Les graphiques de hashrate (ainsi que les statistiques principales) incluent désormais un suivi sur 30 minutes et 2 heures, ainsi qu'un filtrage au niveau de la carte.
Les info-bulles du survol de la souris ont été synchronisées sur tous les graphiques, pour faciliter le diagnostic des problèmes/anomalies.
Les valeurs instantanées sont affichées dans la légende et des lignes individuelles peuvent être désactivées/activées en cliquant sur les étiquettes. Les échelles graphiques ne sont plus basées sur zéro et s'ajustent en fonction des lignes affichées, ce qui signifie qu'elles ne sont plus artificiellement aplaties en raison d'une mauvaise résolution, et vous pouvez réellement voir la variabilité de chaque mesure.
Espérons que cela aide à clarifier à quel point les lectures à 5 m sont réellement variables.
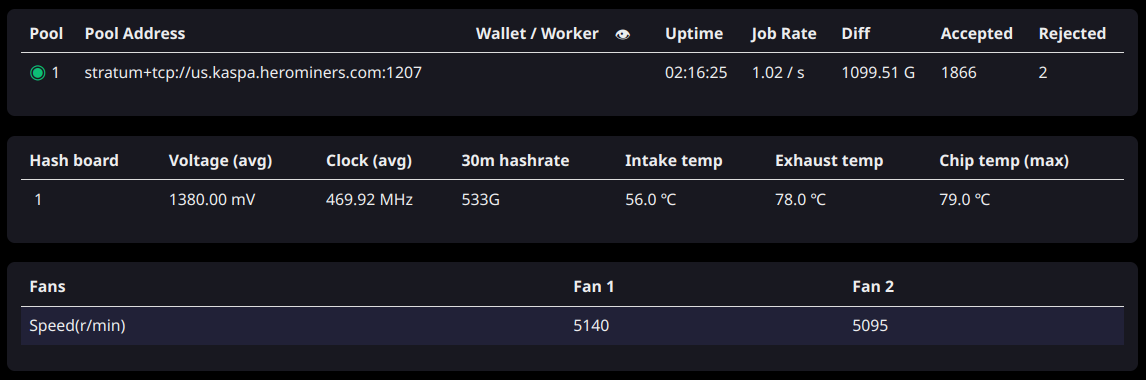
La disponibilité ininterrompue et le taux d'émission des tâches sont ajoutés à la section des statistiques du pool. Le taux de travail est simplement un indicateur de santé supplémentaire d'une connexion au pool - actuellement, le taux de travail pour le réseau Kaspa devrait être d'environ 1 par seconde (bientôt 10/s avec le déploiement de Rust) avec une variation d'environ +/- 15 %. Bien que des taux d'emploi constamment supérieurs ou inférieurs à ce chiffre ne devraient pas techniquement affecter vos revenus en raison de la politique d'acceptation en bloc de Kaspa (en supposant que le pool ne rejette pas inutilement les « anciennes » actions), c'est un signal que le pool peut ne pas fonctionner correctement, et vous vous voudrez peut-être alerter l'exploitant de la piscine ou éventuellement trouver une autre option.
Les opérateurs de Kaspa-pool ont indiqué qu'ils réduisaient intentionnellement le taux de travail pour limiter les frais généraux et que cela n'affectait pas les taux de partage obsolètes dans leur cas.
Plusieurs indicateurs d'état ont été ajoutés à la section pool pour aider à diagnostiquer différents problèmes de réseau/pool. Une icône grise occupée (en rotation) indique que l'asic tente de se connecter au pool. Une icône verte occupée indique une connexion réseau, mais pas encore de connexion de strate. Une icône d'avertissement jaune indique une connexion de strate réussie, mais aucune tâche n'a été reçue.
Alors que l'API précédemment disponible sur le port 4111 est toujours disponible, une nouvelle API rationalisée incluant toutes les fonctionnalités supplémentaires de l'interface utilisateur est désormais disponible sur https (port 443).
La documentation complète est disponible au format json.
Un certain nombre de fonctionnalités ont été ajoutées à une version « commerciale » distincte destinée à l'hébergement ou à d'autres déploiements à grande échelle. Ces versions incluent un « c » après le numéro de version (par exemple pbv081c_ks5mupdate.bgz ) et comportent actuellement des frais supplémentaires de 0,33 % (1,33 % par rapport aux 1 % standard).
En plus de l'utilisateur principal/administrateur standard, plusieurs utilisateurs avec des autorisations d'accès différentes peuvent être ajoutés. Cela permet des configurations dans lesquelles, par exemple, le propriétaire de la machine peut bénéficier d'un accès direct à la machine, avec l'autorisation d'afficher la page de surveillance principale et de modifier les configurations du pool, tout en étant empêché de modifier les paramètres de réseau, de ventilateur ou d'horloge/tension.
La puissance de hachage de l'ASIC peut être répartie sur plusieurs points de terminaison en fonction d'un pourcentage configurable, pour permettre la configuration des frais d'hébergement. Le nombre de divisions n'est pas limité, mais gardez à l'esprit que le micrologiciel maintiendra une connexion pool/strate pour chaque division, ce qui multiplie le trafic entrant.
Cette fonctionnalité peut également être utilisée pour diviser le hashrate sur plusieurs pièces KHeavyHash à la fois.
Le logo « PbFarmer » peut être remplacé par une image de marque de votre choix. Le format de l'image doit être un PNG 112x60.
Boucle de vérification de l’état exécutée sur la disponibilité du pool principal. Si le mineur est passé à l'un des pools secondaires pour une raison quelconque, vous reviendrez à votre pool principal dès qu'il sera à nouveau disponible.
Remplacement du serveur Web d'origine par une version mise à jour et ciblée sur l'environnement de production, ajout d'une configuration de contrôle de cache/mémoire et correction des fuites de mémoire. Cela devrait résoudre les problèmes rencontrés par les utilisateurs de HiveOS et d'autres outils de surveillance externes qui provoquaient le crash du serveur Web après un trop grand nombre de chargements de pages (entraînant l'indisponibilité de l'interface utilisateur ASIC.)
Les contrôles d'authentification et d'autorisation ont été complètement remplacés et tout le trafic redirigé via https. Cela signifie que le transfert du trafic http(s) via votre pare-feu pour une surveillance hors site devrait être beaucoup plus sûr (même si je ne le recommanderais toujours pas nécessairement - simplement en raison des meilleures pratiques de sécurité...) La connexion n'est plus transmise via http non sécurisé, et les gens ne peuvent plus pirater votre asic simplement en définissant un cookie pour ignorer la connexion. Les messages aléatoires de « connexion incorrecte » dus à une corruption du système de fichiers devraient également appartenir au passé. Veuillez garder à l'esprit que cela signifie que votre mot de passe sera réinitialisé aux valeurs par défaut après la première installation. De plus, le premier démarrage après l'installation prendra plus de 2 minutes, car la machine génère les certificats TLS.
De plus, l'API repensée a été sécurisée avec un jeton d'accès, grâce auquel des autorisations granulaires peuvent être attribuées. Les jetons doivent être inclus avec les requêtes API dans un en-tête du formulaire « Autorisation : porteur <jeton> ».
Tout comme vous mettriez à jour le mot de passe de connexion, VEUILLEZ SUPPRIMER/REMPLACER CE JETON API si vous prévoyez d'exposer votre machine publiquement, car il est le même sur toutes les machines par défaut.
Les certificats TLS (et l'autorité de certification) pour https sont automatiquement générés sur l'ASIC, ce qui signifie qu'ils provoqueront des avertissements « Non sécurisé » dans votre navigateur puisqu'ils ne proviennent pas d'une autorité bien connue. Bien qu'inoffensifs, ces avertissements peuvent être ennuyeux, c'est pourquoi le micrologiciel offre la possibilité de télécharger le certificat CA afin qu'il puisse être téléchargé dans le magasin de certificats de votre navigateur.
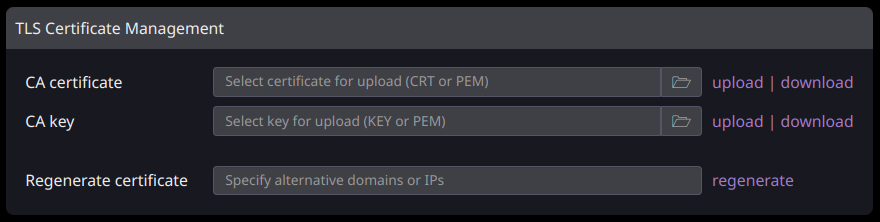
Pour ce faire dans Chrome, par exemple, allez sur chrome://settings/security, cliquez sur « Gérer les certificats », sélectionnez l'onglet « Autorités de certification racine de confiance » (ou simplement « Autorités » pour Linux) et cliquez sur l'importation. bouton. Après avoir redémarré votre navigateur, vous ne devriez plus voir l'avertissement « Non sécurisé ».
Si vous disposez de plusieurs ASIC, vous aurez par défaut une autorité de certification différente pour chacun. Cependant, au lieu d'ajouter chacun de ces éléments à votre (vos) navigateur(s) ou à d'autres appareils, vous pouvez propager une seule autorité de certification sur tous les ASIC en téléchargeant à la fois le certificat d'autorité de certification et la clé d'autorité de certification à partir d'un ASIC, en téléchargeant les deux fichiers sur tous vos autres ASIC. puis régénérer le certificat sur chacun de ces autres ASIC.
Si vous accédez à votre ASIC via un nom de domaine ou plusieurs IP, vous pouvez également les ajouter au certificat TLS en les répertoriant dans le champ « Régénérer le certificat » et en cliquant sur « Régénérer ».
Une boucle de contrôle de santé a été ajoutée, qui redémarrera automatiquement le mineur ou le serveur Web en cas de panne pour une raison quelconque.
De plus, l'exécutable de « réinitialisation » qui disparaît aléatoirement des machines des utilisateurs (même les configurations d'origine) est désormais fourni avec le micrologiciel et une boucle de contrôle de santé a été ajoutée pour remplacer/redémarrer le fichier si nécessaire. Cela devrait résoudre les boucles de redémarrage de 30 millions de personnes que de nombreuses personnes connaissent.
NE PAS installer sur le micrologiciel xyys (y compris de marque tswift) sur les modèles KS0 Ultras ou KS5*. Assurez-vous de suivre ses instructions de désinstallation avant d'installer ce firmware ou tout autre firmware !
Il s'agit d'un package de mise à jour standard du micrologiciel, comprenant/améliorant le dernier micrologiciel IceRiver, et appliqué exactement comme le serait le micrologiciel officiel. L'application sur toutes les mises à jour précédentes devrait fonctionner pour les modèles KS0/Pro, KS1, KS2 et KS3*. L'application de versions excédentaires ou précédentes de ce micrologiciel devrait également fonctionner pour les modèles KS0 Ultra et KS5*.
Cependant, si vous rencontrez des problèmes, essayez le processus suivant :
Assurez-vous également de refaire les paramètres de votre pool, car ils auront été réinitialisés à l'adresse par défaut de Kaspa Dev Fund.
Les alimentations pour ordinateurs portables pour les modèles KS0/Pro/Ultra doivent généralement être de 19,5 V avec des connecteurs de 5,5 mm x 2,5 mm, mais l'intensité nominale peut varier en fonction de vos objectifs OC. Cependant, les connecteurs cylindriques de cette taille ont tendance à être évalués pour 5 ou 10 A, et il est peu probable qu'IceRiver ait utilisé des options 5 A, il serait donc raisonnable de supposer qu'ils ont utilisé 10 A (7,5 A est une autre possibilité). Cela signifie que tout adaptateur de plus de 200 W dépasse probablement la puissance nominale de la prise, de sorte que la fiche pourrait fondre ou même prendre feu si elle n'est pas activement refroidie (même dans ce cas, le risque demeure). Soyez extrêmement prudent si vous choisissez d’utiliser l’une des options de chargeur d’ordinateur portable les plus puissantes.
Il est fortement recommandé d'avoir un wattmètre connecté à vos machines, pour vous assurer que vous respectez les limites de votre bloc d'alimentation. Cela est particulièrement vrai pour les modèles KS3* et KS5*, qui ont très peu de marge sur le bloc d'alimentation, même avec les paramètres d'origine, ainsi que pour les modèles KS0* en raison de la large gamme d'alimentations.
Les modèles KS0 Pro et Ultra nécessitent une attention particulière au refroidissement. Les étages de puissance de ceux-ci fonctionnent déjà très chauds, c'est pourquoi des modifications matérielles pour un refroidissement amélioré sont fortement recommandées - y compris des dissipateurs thermiques et une meilleure circulation de l'air.
Les puces de hachage sur tous les modèles ont tendance à fonctionner mieux dans la plage 75-80c, mais cela est particulièrement vrai pour le KS0 Ultra, où même en passant de 80c à 75c, j'ai constaté une baisse du hashrate sur 2 heures de > 3 %.
LE POURCENTAGE DE DÉCALAGE DE L'HORLOGE ET LE POURCENTAGE D'AUGMENTATION DU HASHRATE DOIVENT ÊTRE ÉGAUX SUR UNE MACHINE SAINE.
Par exemple, si votre décalage d'horloge est de 30 % sur un KS1, alors votre hashrate devrait être de 1,3TH/s, soit 30 % de plus que le 1 TH/s par défaut. Si ce n'est pas le cas (sur une fenêtre de mesure appropriée), cela signifie que vos puces manquent de tension.
Un bon réglage est un processus qui prend du temps. Utiliser les paramètres d’autres personnes n’est généralement pas une bonne idée, car chaque machine est différente. La meilleure pratique consiste à démarrer avec un décalage d'horloge conservateur qui entraîne une augmentation correspondante du hashrate sans changement de tension. Au fur et à mesure que vous augmentez vos horloges par petits incréments (par exemple 25 MHz ou moins), une fois que vous ne voyez plus le hashrate répondre 1: 1 (ou peut-être même commencer à baisser), cela indique qu'une tension plus élevée est nécessaire.
À ce stade, augmentez la tension d'un seul pas (2 mv pour le KS0 Pro, 7 ou 6 mv selon le niveau de courant pour tous les autres modèles), puis voyez si le hashrate répond. Si c'est le cas et qu'il équivaut encore une fois au décalage d'horloge sur une base en pourcentage, revenez à l'augmentation de l'horloge. Continuez ce va-et-vient entre les décalages d'horloge et de tension jusqu'à ce que vous atteigniez le hashrate souhaité, tout en étant attentif aux limites de température et de puissance.
Bien que les hashrates de 5 m et 30 m dans l'interface graphique soient des outils utiles pour le guidage directionnel une fois que la machine a eu le temps de monter en puissance, les mesures finales du hashrate doivent être effectuées sur une période de temps prolongée. Les lectures de hashrate de 5 minutes sont assez variables, et même les lectures de hashrate de 30 minutes ne sont pas excellentes, car vous pouvez toujours avoir une variabilité de quelques pour cent. La lecture sur 2 heures dans l'interface utilisateur devrait avoir une variabilité inférieure à 1 % d'après mon expérience (peut être légèrement supérieure à 1 % sur KS5L/M et KS0Ultra), bien qu'elle ne prenne pas en compte les erreurs matérielles/rejets de pool.
Et enfin, si vous essayez de reproduire les résultats OC d'un autre firmware...
Tous les firmwares OC, y compris celui-ci, contrôlent uniquement les horloges et les tensions. D'après mon expérience, étant donné la tension nécessaire, le hashrate répond linéairement sur une base de 1:1 au changement d'horloge, en pourcentage. Mais en fin de compte, tout ce que nous pouvons faire est de changer l’horloge et d’espérer que l’ASIC répondra avec le changement de hashrate attendu.
Les lectures de hashrate dans l'interface utilisateur ASIC ne ressemblent pas à celles du minage CPU/GPU. Les ASIC IceRiver ne comptent pas les hachages réels - ils estiment simplement le hashrate en fonction du nombre d'actions produites * difficulté. C'est exactement ainsi qu'un pool mesure votre hashrate, mais le problème est que la plupart des pools ont décidé d'utiliser une difficulté beaucoup trop élevée pour les ASIC IceRiver, ce qui empêche des mesures fiables du hashrate à court terme - avec une différence élevée, le taux de partage est faible, ce qui signifie des sautes sauvages dans le hashrate. En conséquence, IceRiver a publié une mise à jour du micrologiciel qui a commencé à utiliser une difficulté interne complètement différente et plus faible pour les mesures de hashrate sur son propre tableau de bord.
Par conséquent, même pour la même période exacte, vous ne pouvez pas comparer de manière fiable une mesure du hashrate de pool au hashrate de l'interface utilisateur ASIC - ils n'utilisent pas les mêmes données. Pour aggraver encore la situation, étant donné que les machines IceRiver généraient très tôt un grand nombre de partages invalides, un certain nombre de pools ont décidé de cesser de signaler les partages rejetés à l'ASIC afin que les utilisateurs cessent de se plaindre (ou de changer de pool) et de les signaler comme acceptés. , tout en les rejetant silencieusement de leur côté. En fonction du taux de rejet réel, cela peut signifier une divergence significative entre le hashrate ASIC et le hashrate du pool, même s'ils ont été mesurés sur la même période et avec la même difficulté.
Quelle que soit la différence sélectionnée, les mesures de hashrate basées sur les parts * difficulté sont sujettes à des fluctuations basées sur la chance. Plus le nombre de partages est faible (la différence est élevée), plus la chance affecte le hashrate et plus les fluctuations sont sauvages. Ainsi, pour avoir une mesure de hashrate statistiquement significative, vous avez besoin de suffisamment d’actions pour réduire au maximum l’effet de chance. Les lectures de 5 m sur l'ASIC ne conviennent pas à cela, en particulier lorsque l'on tente de vérifier le résultat de changements d'OC à un chiffre, et les lectures de piscine à court terme sont encore pires.
Vous avez besoin de 1 200 actions juste pour obtenir une variance attendue de +/- 10 % avec un niveau de confiance de 99 %. Par exemple, pour un hashrate attendu de 1TH/s, dans des mesures 99/100 après 1200 partages, vous aurez une lecture comprise entre 0,9TH/s et 1,1TH/s. Vous avez besoin de 4 800 actions pour réduire cet écart à +/- 5 %. De nombreux pools utilisent des difficultés qui produisent des taux de partage de l'ordre de ~5 parts/min. Par conséquent, juste pour obtenir une lecture de hashrate avec une variance attendue de <= +/- 10 %, vous auriez besoin d'une lecture de 1 200/5 = 240 minutes, soit 4 heures. Si vous souhaitez une lecture avec une variance attendue de +/- 5 %, vous aurez besoin de plus de 16 heures de données. Vous ne pourrez jamais confirmer les résultats d'un niveau d'OC inférieur à la variance attendue sur une période donnée. Par exemple, vous ne pouvez pas déterminer si un OC à 5 % fonctionne correctement dans une fenêtre de partage de 4 heures/1 200 avec une variance attendue de 10 %. Même à 16h / 4800 actions, la variance attendue peut annuler complètement un OC de 5%.
Et cela nous amène au nœud du problème : la plupart des pools ne fournissent rien de plus qu'une mesure sur 24 heures, ce qui à environ 5 actions/minute signifie environ 7 200 actions, ce qui représente toujours une variance attendue de 4 %. Vous avez besoin de 10 000 actions pour un écart de 3,3 % seulement et d'environ 100 000 actions pour un écart de 1 %. La lecture sur 30 mois dans l'interface utilisateur ASIC devrait avoir une variance d'environ 2 % et la nouvelle lecture sur 2 heures devrait avoir une variance inférieure à 1 %, mais aucune ne reflète les rejets du pool. Par conséquent, la seule solution est alors de trouver un pool qui vous permet de définir votre propre difficulté, afin que vous puissiez générer un nombre de partages statistiquement pertinent pour les périodes disponibles. Herominers est l’un de ces pools qui permet cela.
La meilleure option pour définir votre propre différence et voir des délais de mesure suffisamment longs est l'exploitation minière en solo sur votre propre nœud et le pont kaspa-stratum. Les paramètres par défaut de vardiff produiront un minimum de 20 partages/min, ce qui est suffisant pour avoir une variance <= +/- 5 % en 4 heures, et le tableau de bord (grafana) permet des mesures dans n'importe quel délai/résolution de votre choix, y compris des délais nettement plus longs que 24 heures.
Comme exemple concret de la différence entre les mesures valides et invalides (ainsi que de la façon dont kaspa-stratum-bridge peut aider), voici les lectures de hashrate de 3 machines utilisant des diffs produisant >= 30 partages/min, un KS0 à 51% OC, un KS1 à 37% OC et un KS3M à 1% OC. Les mesures sont, de haut en bas, 24 heures (>= 43 000 partages), 1 heure (>= 1 800 partages) et 30 minutes (> 900 partages). Vous pouvez voir à quel point les mesures peuvent différer de celles attendues pour les périodes les plus courtes :
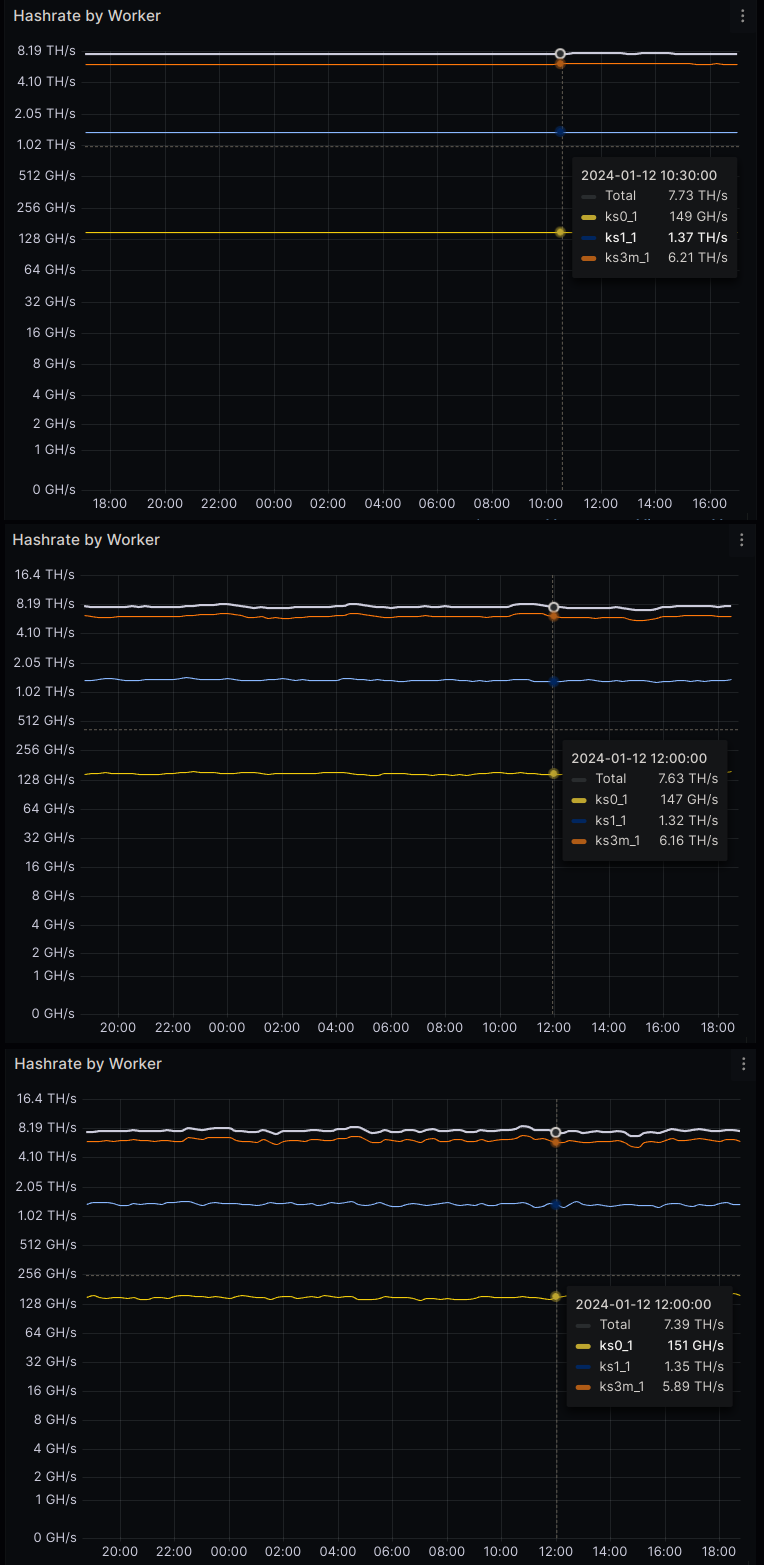
Bref, si vous essayez de confirmer les effets d'un petit OC sur l'interface utilisateur ASIC, vous devrez utiliser la lecture de 2 heures, mais vous ne saurez pas si vous générez des partages qui seraient rejetés. Pour avoir une image complète, vous aurez besoin d'une mesure à long terme à partir d'un pool qui permet des taux de partage élevés - et je ne peux indiquer aucune option qui puisse le faire pour le moment, autre que l'extraction sur votre propre nœud + kaspa-stratum. -pont.


