nmt
1.0.0
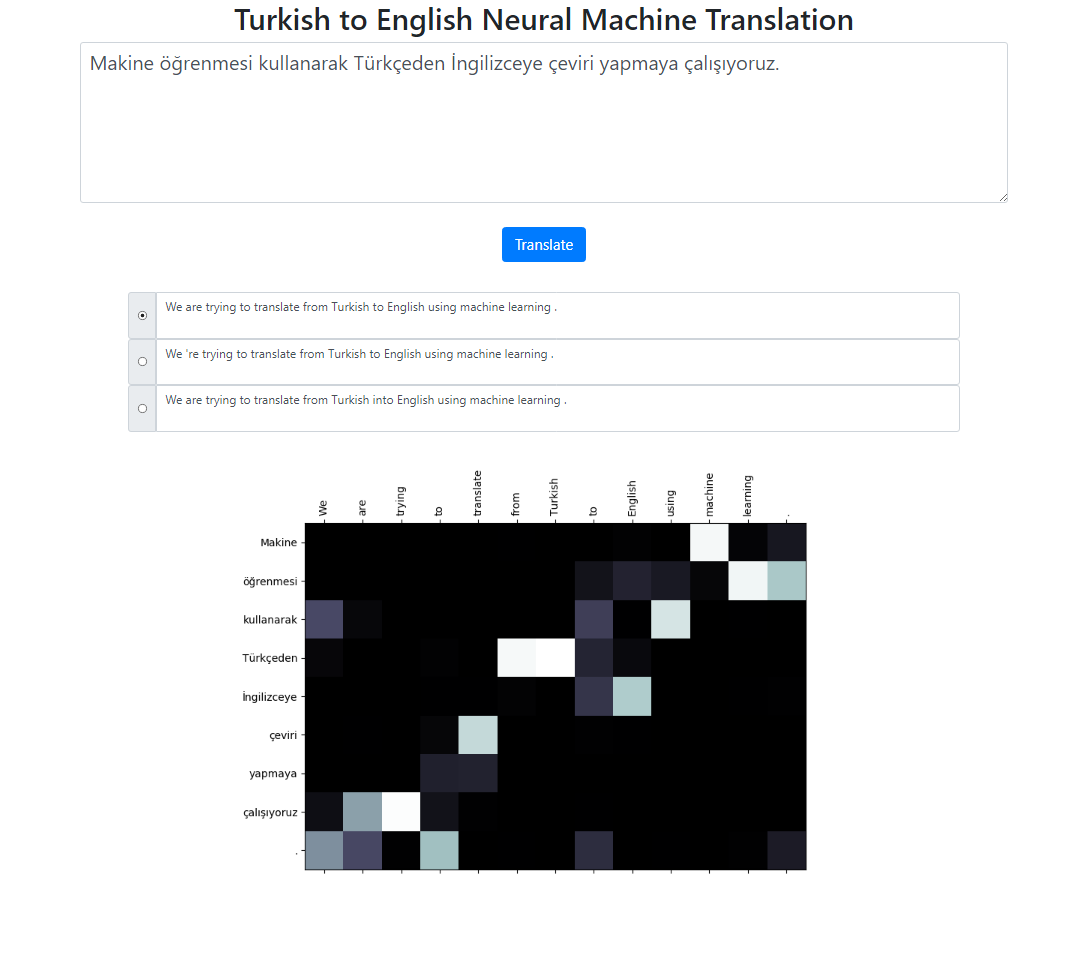
Ce référentiel implémente un système de traduction automatique neuronale du turc vers l'anglais utilisant le modèle Seq2Seq + Global Attention. Il existe également une application Flask que vous pouvez exécuter localement. Vous pouvez saisir le texte, traduire et inspecter les résultats ainsi que la visualisation de l'attention. Nous effectuons une recherche de faisceau avec une taille de faisceau 3 en arrière-plan et renvoyons les séquences les plus probables triées par leur score relatif.
L'ensemble de données de ce projet provient d'ici. J'ai utilisé le corpus Tatoeba. J'ai supprimé certains des doublons trouvés dans les données. J'ai également prétokénisé l'ensemble de données. La version finalisée peut être trouvée dans le dossier de données.
Pour symboliser les phrases turques, j'ai utilisé le RegexpTokenizer de nltk.
puncts_sauf_apostrophe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_sauf_apostrophe}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "Titanic 15 Nisan "tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# Sortie : Titanic 15 minutes à 02 : 20 'de batterie .# Cette propriété de division sur "02 : 20" est différent du tokenizer anglais.# On pouvait gérer ces situations. Mais je voulais garder c'est simple et voyez si # la répartition de l'attention sur ces mots s'aligne sur les jetons anglais.# Il existe des cas similaires principalement sur les dates, comme dans cet exemple : 02/09/2019Pour symboliser les phrases anglaises, j'ai utilisé le modèle anglais de Spacy.
en_nlp = spacy.load('en_core_web_sm')text = "Le Titanic a coulé à 02h20 le lundi 15 avril."tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text ]))# Sortie : Le Titanic a coulé à 02h20 le lundi 15 avril.Les phrases en turc et en anglais devraient se trouver dans deux fichiers différents.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
Veuillez exécuter python train.py -h pour la liste complète des arguments.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
Pour calculer le score bleu au niveau du corpus.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
Pour exécuter l'application localement, exécutez :
python app.py
Assurez-vous que les chemins de votre modèle dans le fichier config.py sont correctement définis.
Fichier modèle
Fichier de vocabulaire
Utilisation d'unités de sous-mots (pour le turc et l'anglais)
Différents mécanismes d'attention (apprentissage de différents paramètres d'attention)
Le code squelette de ce projet est tiré du cours PNL de Stanford : CS224n.


