hercules
v10.7.2
Analyse de l'historique Git rapide, perspicace et hautement personnalisable.
Présentation • Comment utiliser • Installation • Contributions • Licence
Hercules est un moteur d'analyse de référentiel Git incroyablement rapide et hautement personnalisable écrit en Go. Les piles sont incluses. Propulsé par go-git.
Avis (novembre 2020) : l'auteur principal sort des limbes et reprend progressivement le développement. Voir la feuille de route.
Il existe deux outils de ligne de commande : hercules et labours . Le premier est un programme écrit en Go qui utilise un référentiel Git et exécute un graphique acyclique dirigé (DAG) de tâches d'analyse sur l'historique complet des validations. Le second est un script Python qui affiche des tracés prédéfinis sur les données collectées. Ces deux outils sont normalement utilisés ensemble à travers un tuyau. Il est possible d'écrire des analyses personnalisées à l'aide du système de plugins. Il est également possible de fusionner plusieurs résultats d'analyse, ce qui est pertinent pour les organisations. L'historique des validations analysé comprend les branches, les fusions, etc.
Hercules a été utilisé avec succès pour plusieurs projets internes à la source{d}. Il y a des articles de blog : 1, 2 et une présentation. Veuillez contribuer en testant, en corrigeant des bugs, en ajoutant de nouvelles analyses ou en codant avec fanfaronnade !
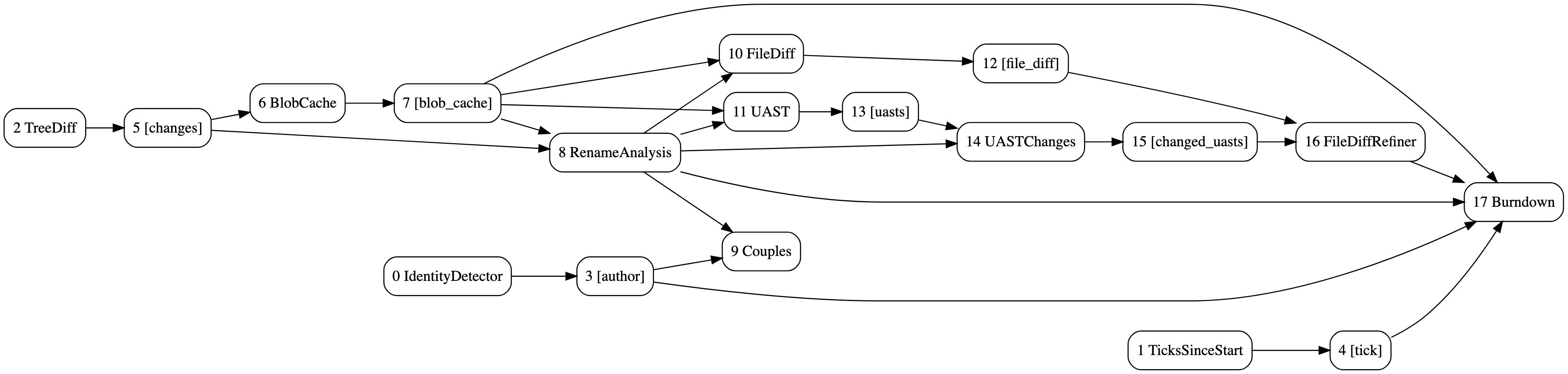
Le DAG des analyses de burndown et de couples avec raffinement des différences UAST. Généré avec hercules --burndown --burndown-people --couples --feature=uast --dry-run --dump-dag doc/dag.dot https://github.com/src-d/hercules
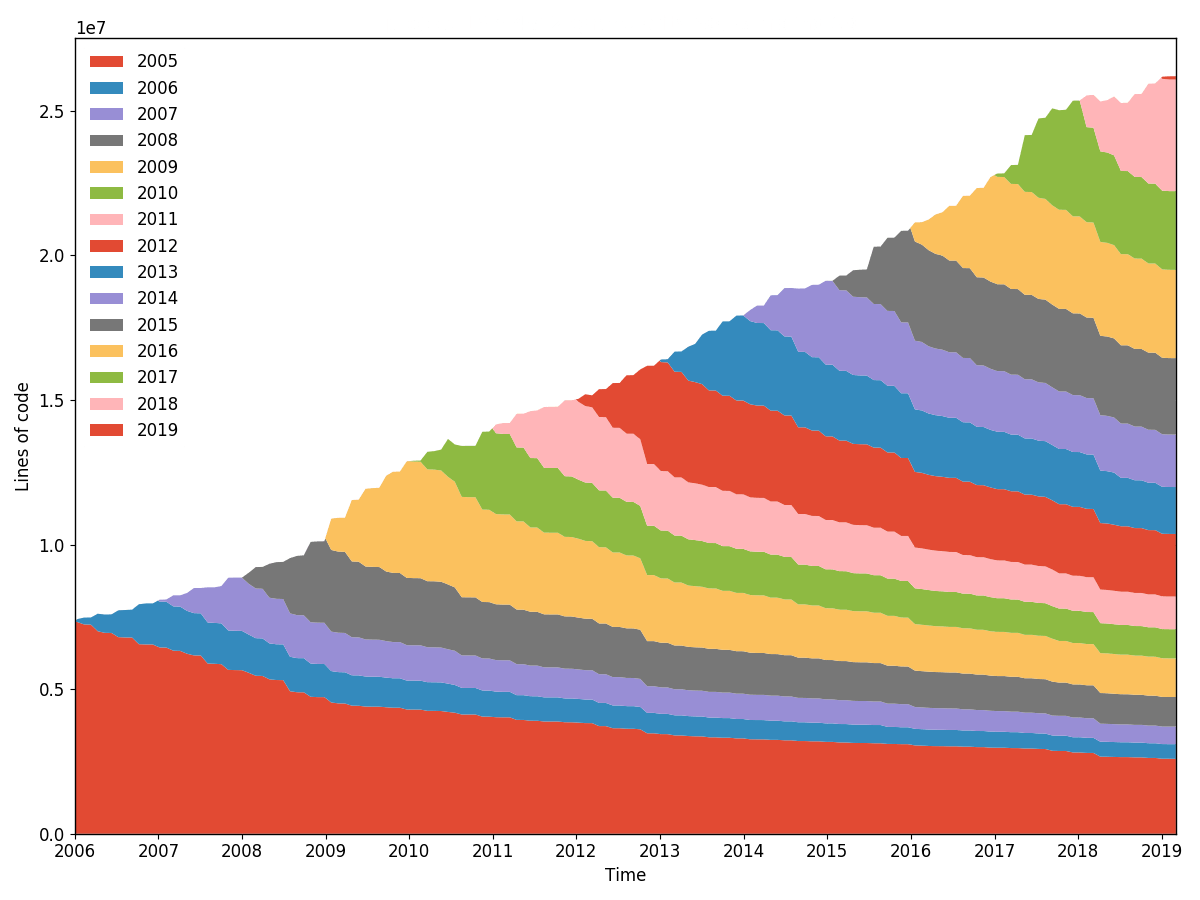
burndown de la ligne torvalds/linux (granularité 30, échantillonnage 30, rééchantillonné par année). Généré avec hercules --burndown --first-parent --pb https://github.com/torvalds/linux | labours -f pb -m burndown-project en 1h 40min.
Récupérez le binaire hercules sur la page des versions. labours est installable depuis PyPi :
pip3 install labours
pip3 est le gestionnaire de packages Python.
Numpy et Scipy peuvent être installés sur Windows en utilisant http://www.lfd.uci.edu/~gohlke/pythonlibs/
Vous aurez besoin de Go (>= v1.11) et protoc .
git clone https://github.com/src-d/hercules && cd hercules
make
pip3 install -e ./python
Il est possible d'exécuter Hercules en tant qu'action GitHub : Hercules sur GitHub Marketplace. Veuillez vous référer à l'exemple de flux de travail qui montre comment configurer.
...sont les bienvenus ! Voir CONTRIBUTION et code de conduite.
Apache2.0
La référence de ligne de commande la plus utile et la plus fiable :
hercules --help
Quelques exemples :
# Use "memory" go-git backend and display the burndown plot. "memory" is the fastest but the repository's git data must fit into RAM.
hercules --burndown https://github.com/go-git/go-git | labours -m burndown-project --resample month
# Use "file system" go-git backend and print some basic information about the repository.
hercules /path/to/cloned/go-git
# Use "file system" go-git backend, cache the cloned repository to /tmp/repo-cache, use Protocol Buffers and display the burndown plot without resampling.
hercules --burndown --pb https://github.com/git/git /tmp/repo-cache | labours -m burndown-project -f pb --resample raw
# Now something fun
# Get the linear history from git rev-list, reverse it
# Pipe to hercules, produce burndown snapshots for every 30 days grouped by 30 days
# Save the raw data to cache.yaml, so that later is possible to labours -i cache.yaml
# Pipe the raw data to labours, set text font size to 16pt, use Agg matplotlib backend and save the plot to output.png
git rev-list HEAD | tac | hercules --commits - --burndown https://github.com/git/git | tee cache.yaml | labours -m burndown-project --font-size 16 --backend Agg --output git.png
labours -i /path/to/yaml permet de lire la sortie d' hercules qui a été enregistrée sur le disque.
Il est possible de stocker le référentiel cloné sur disque. L'analyse ultérieure peut s'exécuter sur le répertoire correspondant au lieu de cloner à partir de zéro :
# First time - cache
hercules https://github.com/git/git /tmp/repo-cache
# Second time - use the cache
hercules --some-analysis /tmp/repo-cache
L'action produit l'artefact nommé hercules_charts . Puisqu'il est actuellement impossible de regrouper plusieurs fichiers dans un seul artefact, tous les graphiques et fichiers du projecteur Tensorflow sont regroupés dans l'archive tar interne. Pour visualiser les intégrations, allez sur projecteur.tensorflow.org, cliquez sur "Charger" et choisissez les deux TSV. Utilisez ensuite UMAP ou T-SNE.
docker run --rm srcd/hercules hercules --burndown --pb https://github.com/git/git | docker run --rm -i -v $(pwd):/io srcd/hercules labours -f pb -m burndown-project -o /io/git_git.png
hercules --burndown
labours -m burndown-project
Statistiques d'avancement des lignes pour l'ensemble du référentiel. Exactement la même chose que ce que fait git-of-theseus mais beaucoup plus rapide. Le blâme est effectué de manière efficace et incrémentielle à l'aide d'un algorithme de suivi d'arborescence RB personnalisé, et seule la date de la dernière modification est enregistrée lors de l'exécution de l'analyse.
Toutes les analyses de burndown dépendent des valeurs de granularité et d'échantillonnage . La granularité est le nombre de jours que comprend chaque bande de la pile. L'échantillonnage est la fréquence à laquelle l'état d'épuisement professionnel est instantané. Plus la valeur est petite, plus le tracé est fluide mais plus le travail est effectué.
Il existe une option pour rééchantillonner les bandes à l'intérieur labours , afin que vous puissiez définir une distribution très précise et la visualiser de différentes manières. En outre, le rééchantillonnage aligne les bandes au-delà des limites périodiques, par exemple des mois ou des années. Les bandes non rééchantillonnées ne sont apparemment pas alignées et démarrent à la date de naissance du projet.
hercules --burndown --burndown-files
labours -m burndown-file
Statistiques de burndown pour chaque fichier du référentiel qui est actif dans la dernière révision.
Remarque : il générera un graphique distinct pour chaque fichier. Vous ne voulez pas l'exécuter sur un référentiel contenant de nombreux fichiers.
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m burndown-person
Statistiques de burndown pour les contributeurs du référentiel. Si --people-dict n'est pas spécifié, les identités sont découvertes par l'algorithme suivant :
Si --people-dict est spécifié, il doit pointer vers un fichier texte avec les identités personnalisées. Le format est le suivant : chaque ligne correspond à un seul développeur, elle contient tous les e-mails et noms correspondants séparés par | . Le cas est ignoré.
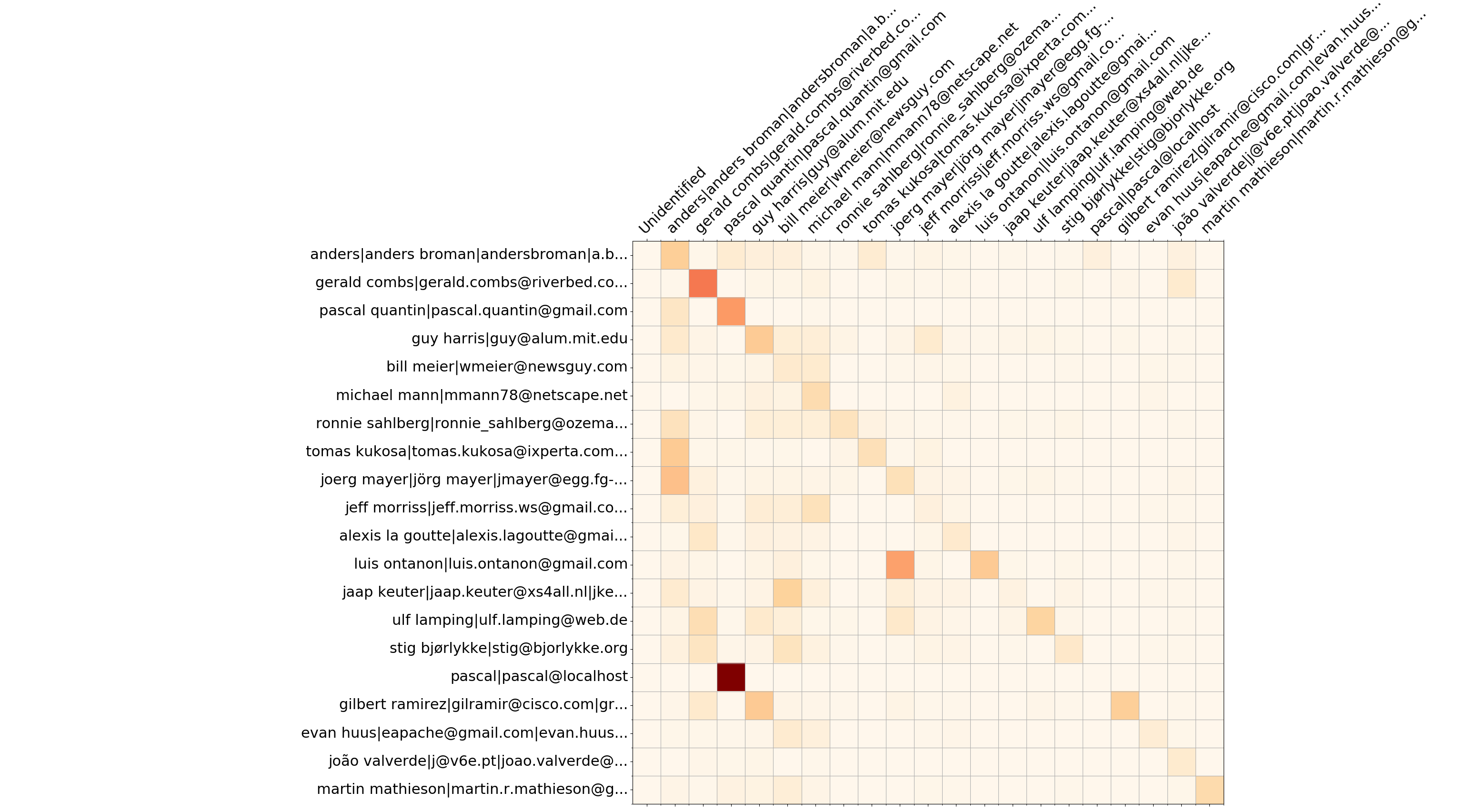
Wireshark top 20 des développeurs - écrase la matrice
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m overwrites-matrix
Outre les informations d'avancement, --burndown-people collecte les statistiques de ligne ajoutées et supprimées par développeur. Ainsi, il est possible de visualiser combien de lignes écrites par le développeur A sont supprimées par le développeur B. Cela indique une collaboration entre les personnes et définit des équipes d'expertise.
Le format est la matrice à N lignes et (N+2) colonnes, où N est le nombre de développeurs.
--people-dict n'est pas spécifié, il vaut toujours 0). La séquence de développeurs est stockée dans le nœud YAML people_sequence .
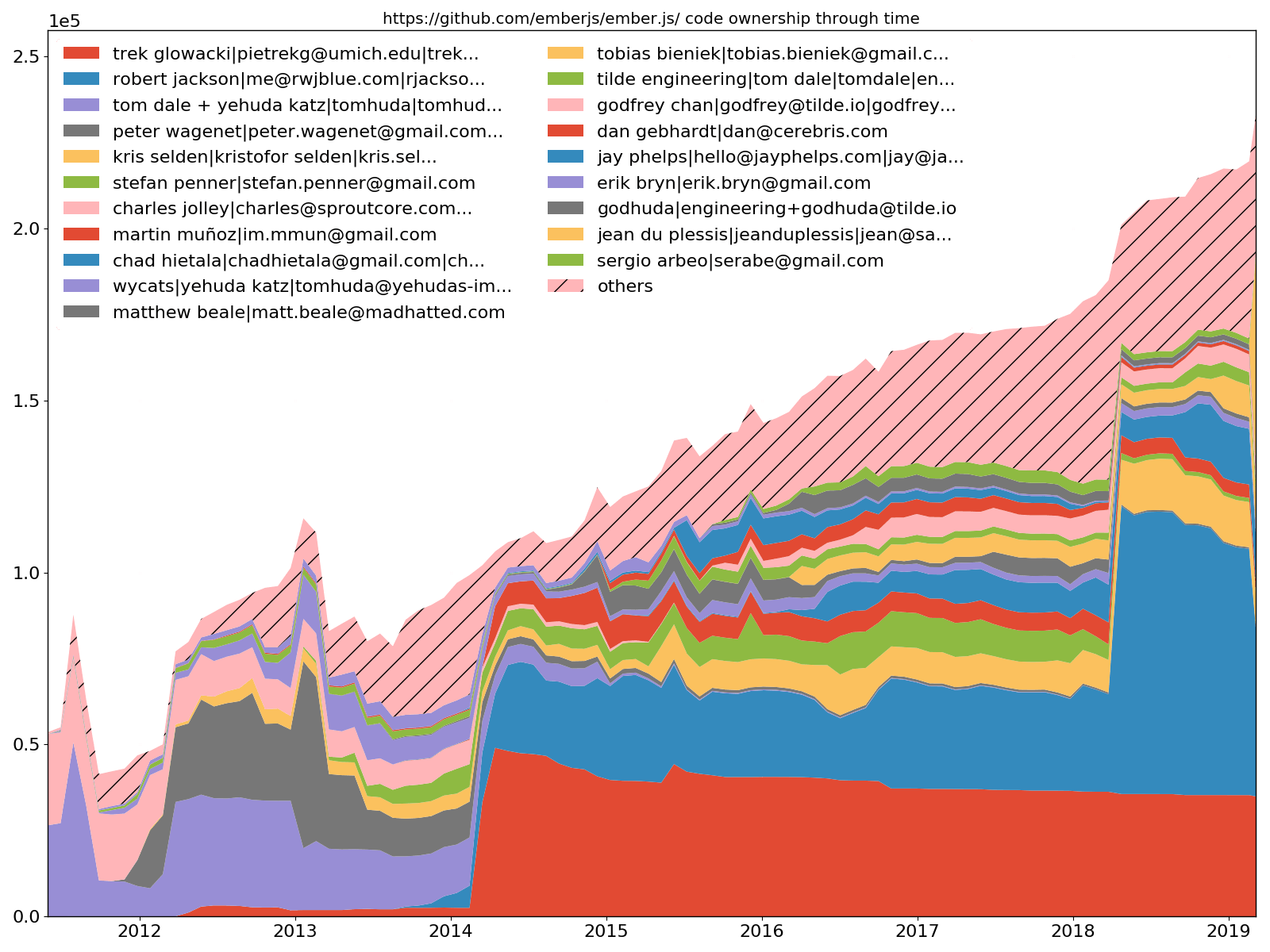
Ember.js top 20 des développeurs - propriété du code
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m ownership
--burndown-people permet également de dessiner le partage de code via un tracé de zone empilée dans le temps. Autrement dit, combien de lignes sont actives aux moments échantillonnés pour chaque développeur identifié.
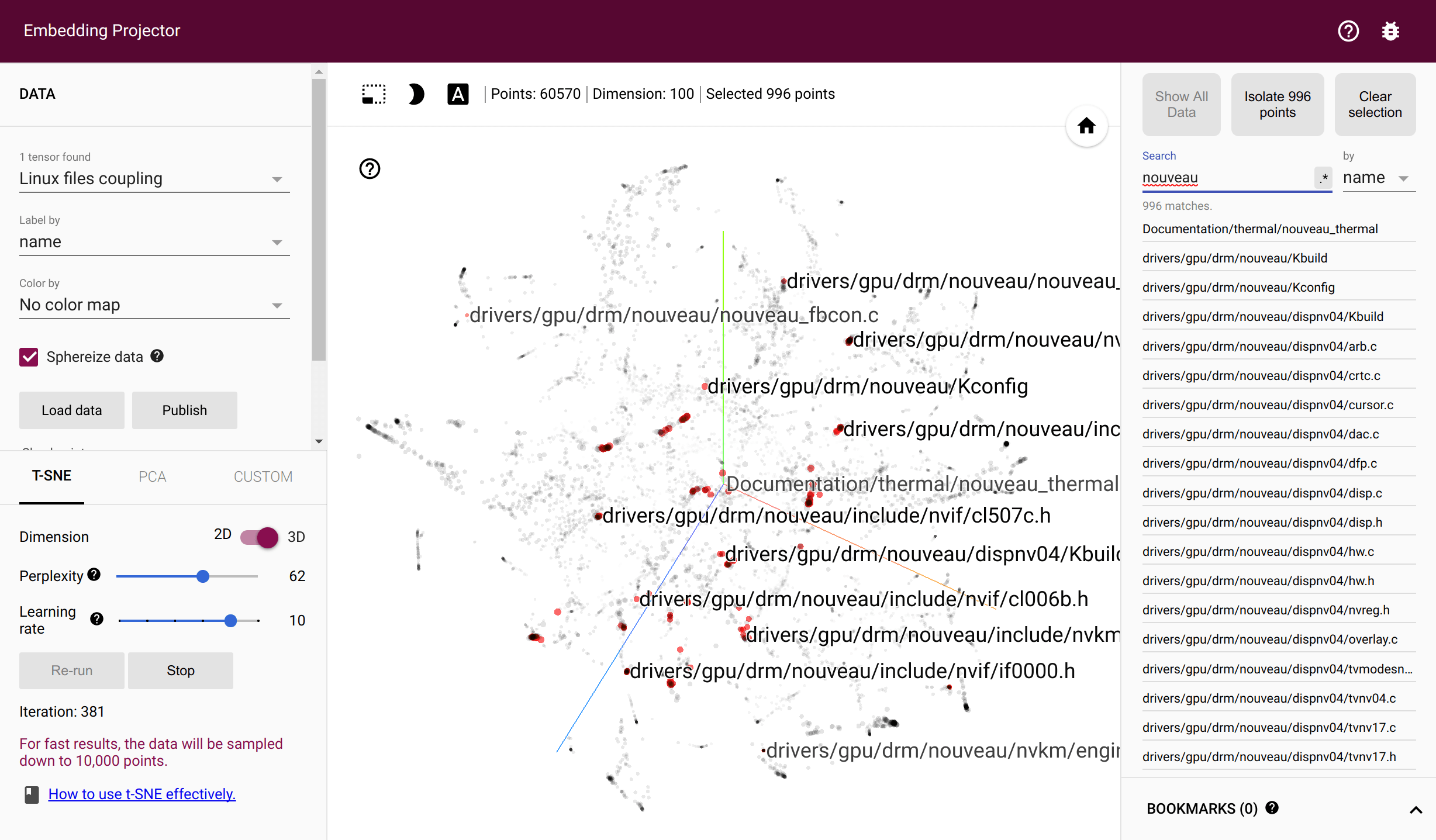
Couplage des fichiers torvalds/linux dans le projecteur Tensorflow
hercules --couples [--people-dict=/path/to/identities]
labours -m couples -o <name> [--couples-tmp-dir=/tmp]
Important : il nécessite l'installation de Tensorflow, veuillez suivre les instructions officielles.
Les fichiers sont couplés s'ils sont modifiés dans le même commit. Les développeurs sont couplés s'ils modifient le même fichier. hercules enregistre le nombre de couples tout au long de l'historique des validations et génère les deux matrices de cooccurrence correspondantes. labours entraînent ensuite des plongements pivotants - des vecteurs denses qui reflètent la probabilité de cooccurrence à travers la distance euclidienne. La formation nécessite une installation Tensorflow fonctionnelle. Les fichiers intermédiaires sont stockés dans le répertoire temporaire du système ou --couples-tmp-dir s'il est spécifié. Les intégrations formées sont écrites dans le répertoire de travail actuel avec le nom dépendant de -o . Le format de sortie est TSV et correspond au projecteur Tensorflow afin que les fichiers et les personnes puissent être visualisés avec t-SNE implémenté dans TF Projecteur.
46 jinja2/compiler.py:visit_Template [FunctionDef]
42 jinja2/compiler.py:visit_For [FunctionDef]
34 jinja2/compiler.py:visit_Output [FunctionDef]
29 jinja2/environment.py:compile [FunctionDef]
27 jinja2/compiler.py:visit_Include [FunctionDef]
22 jinja2/compiler.py:visit_Macro [FunctionDef]
22 jinja2/compiler.py:visit_FromImport [FunctionDef]
21 jinja2/compiler.py:visit_Filter [FunctionDef]
21 jinja2/runtime.py:__call__ [FunctionDef]
20 jinja2/compiler.py:visit_Block [FunctionDef]
Grâce à Babelfish, Hercules est capable de mesurer combien de fois chaque unité structurelle a été modifiée. Par défaut, il examine les fonctions ; reportez-vous au manuel Semantic UAST XPath pour passer à autre chose.
hercules --shotness [--shotness-xpath-*]
labours -m shotness
L'analyse des couples charge automatiquement les données de « shotness » si disponibles.
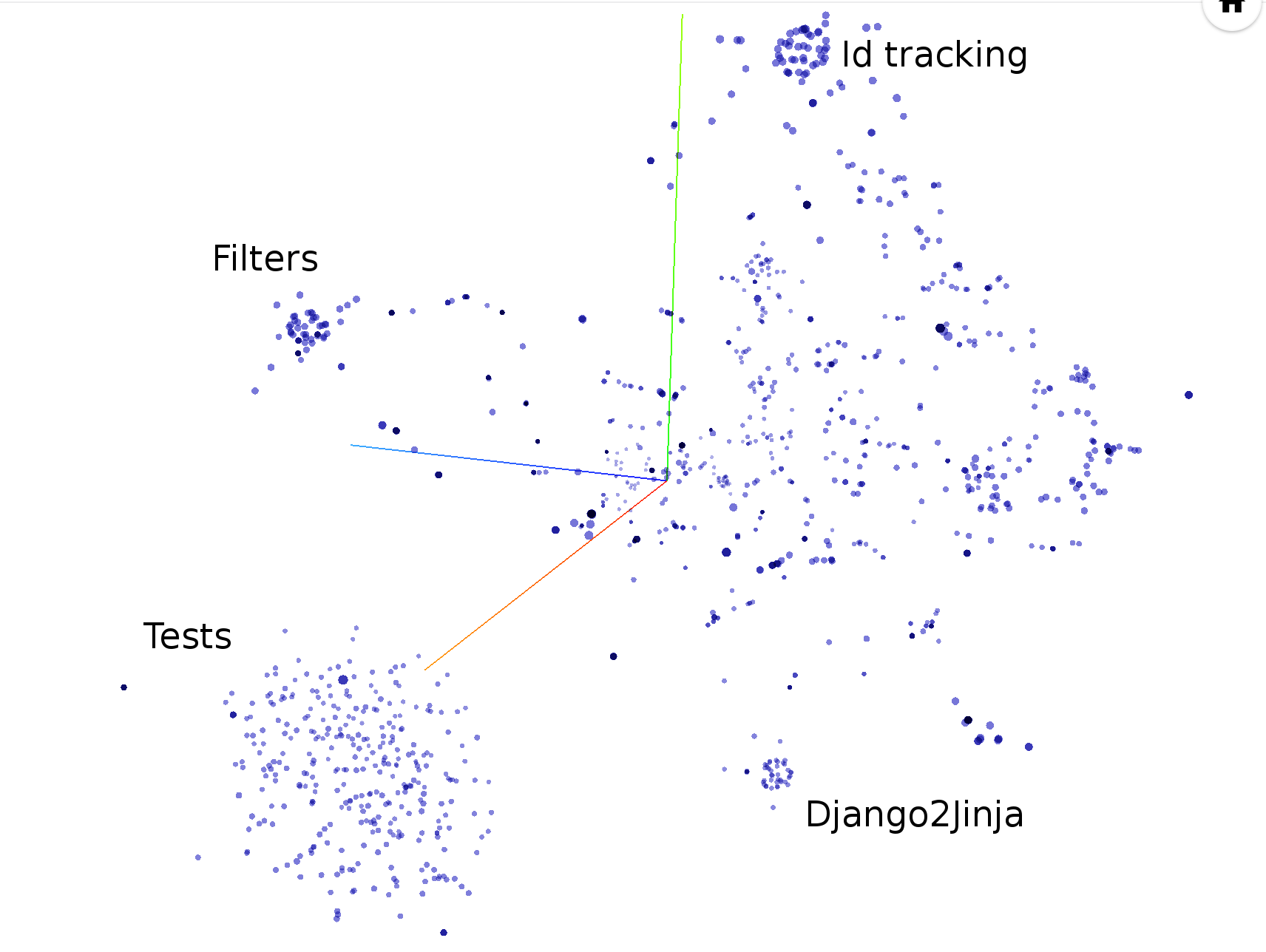
hercules --shotness --pb https://github.com/pallets/jinja | labours -m couples -f pb
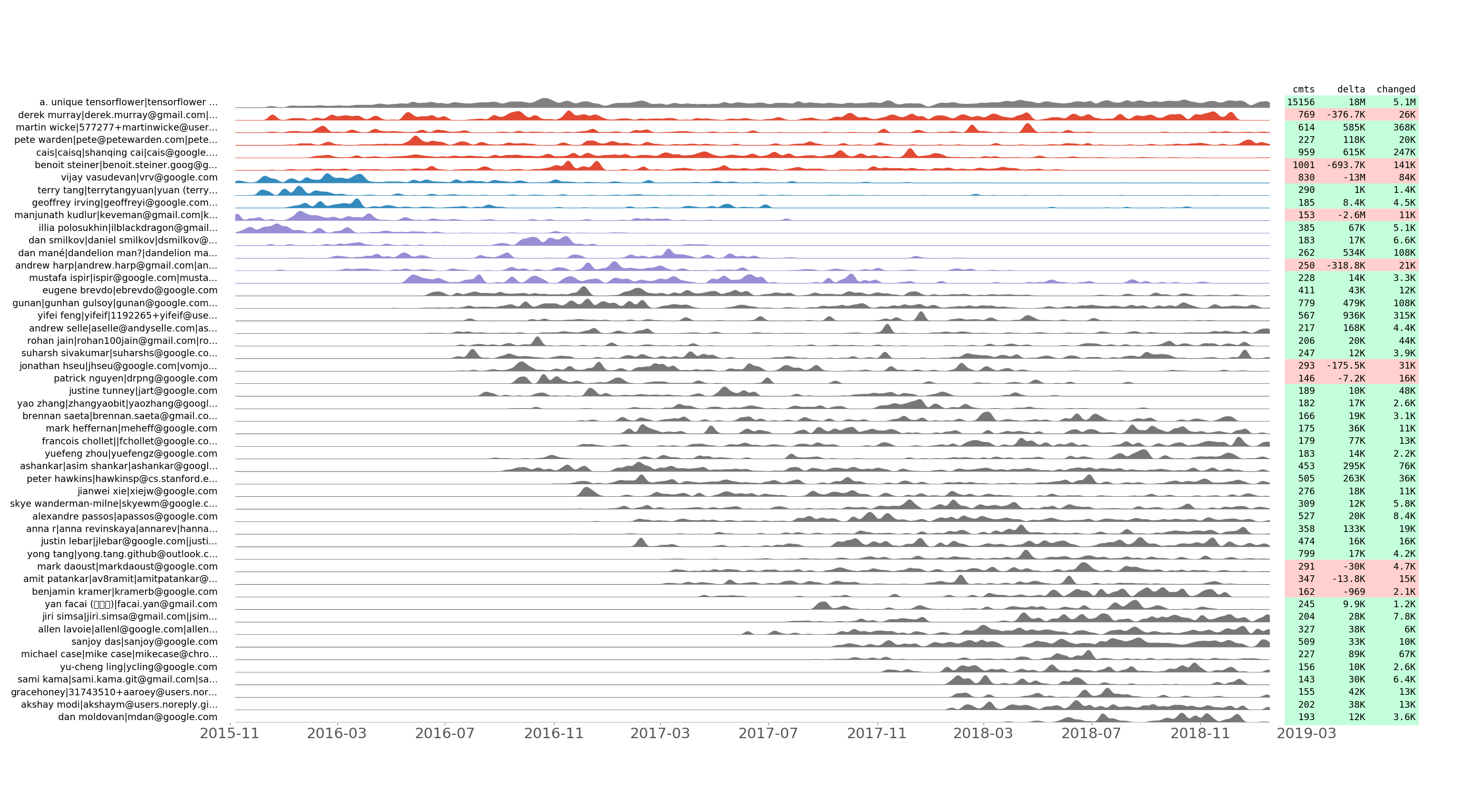
Série de commits alignés tensorflow/tensorflow des 50 meilleurs développeurs par numéro de commit.
hercules --devs [--people-dict=/path/to/identities]
labours -m devs -o <name>
Nous enregistrons le nombre de commits effectués, ainsi que les lignes ajoutées, supprimées et modifiées par jour pour chaque développeur. Nous traçons la série temporelle de validation résultante en utilisant quelques astuces pour montrer le regroupement temporel. En d’autres termes, deux séries de commits adjacentes devraient se ressembler après normalisation.
Cette intrigue permet de découvrir comment l'équipe de développement a évolué au fil du temps. Il montre également des "flashmobs de validation" tels que le Hacktoberfest. Par exemple, voici les informations révélées par le graphique tensorflow/tensorflow ci-dessus :
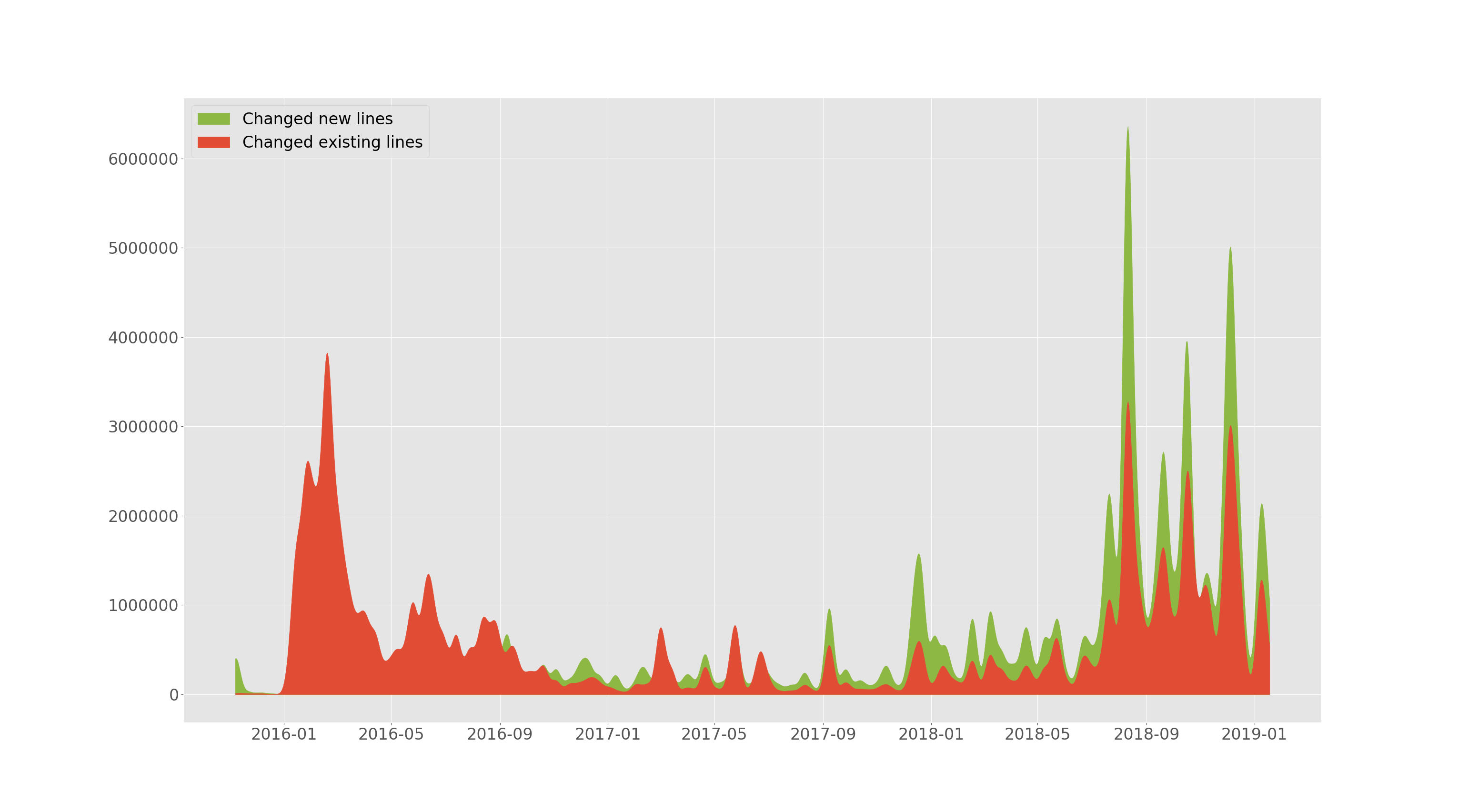
tensorflow/tensorflow ajouté et modifié des lignes au fil du temps.
hercules --devs [--people-dict=/path/to/identities]
labours -m old-vs-new -o <name>
--devs de la section précédente permet de tracer le nombre de lignes ajoutées et le nombre de lignes existantes modifiées (supprimées ou remplacées) au fil du temps. Cette parcelle est lissée.
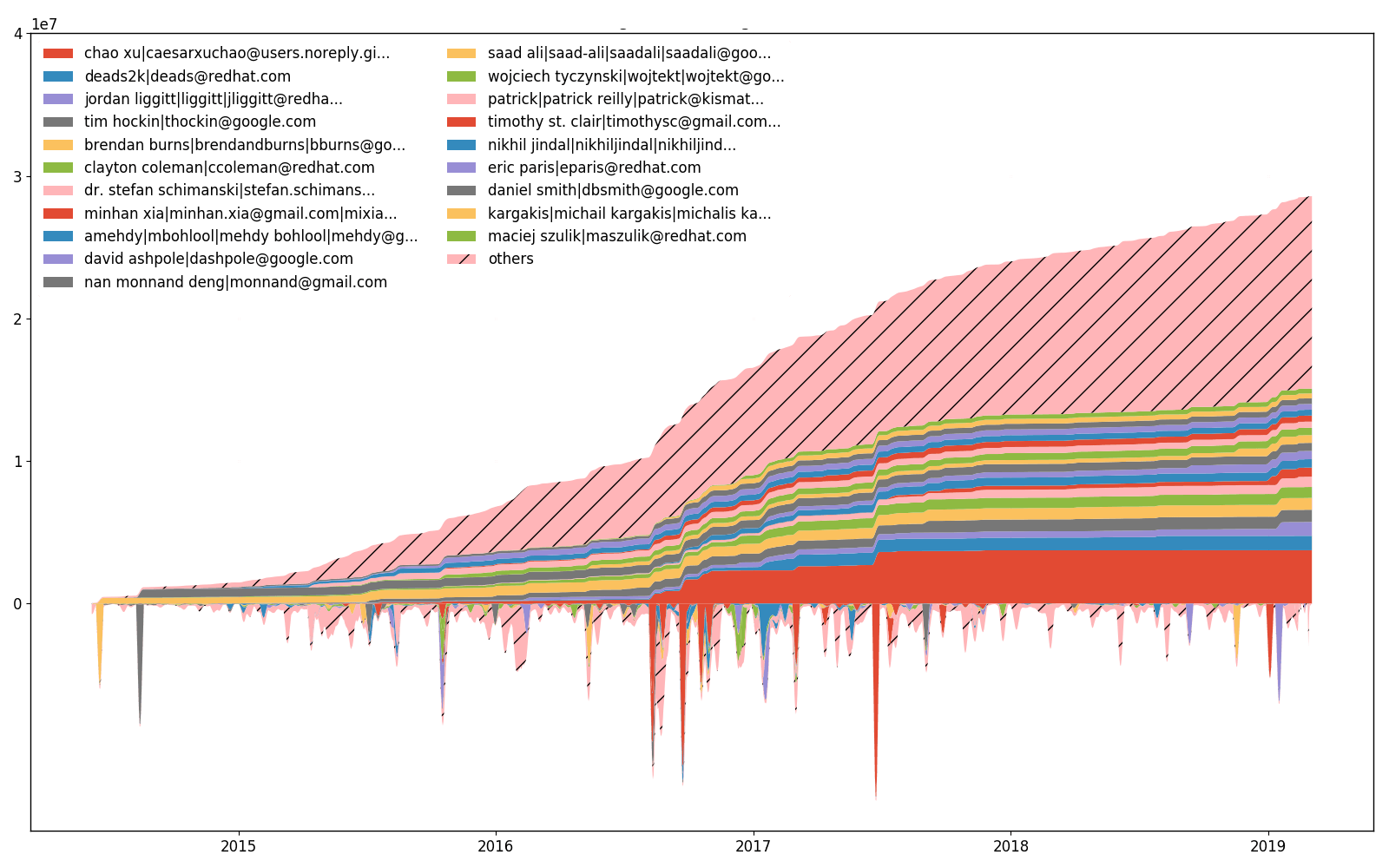
efforts de kubernetes/kubernetes au fil du temps.
hercules --devs [--people-dict=/path/to/identities]
labours -m devs-efforts -o <name>
De plus, --devs permet de tracer le nombre de lignes qui ont été modifiées (ajoutées ou supprimées) par chaque développeur. La partie supérieure de la parcelle est une partie inférieure accumulée (intégrée). Il est impossible d'avoir la même échelle pour les deux parties, donc les valeurs inférieures sont mises à l'échelle et il n'y a donc pas de graduations inférieures sur l'axe Y. Il existe une différence entre la parcelle d'efforts et la parcelle de propriété, bien que les lignes changeantes soient en corrélation avec les lignes de propriété.
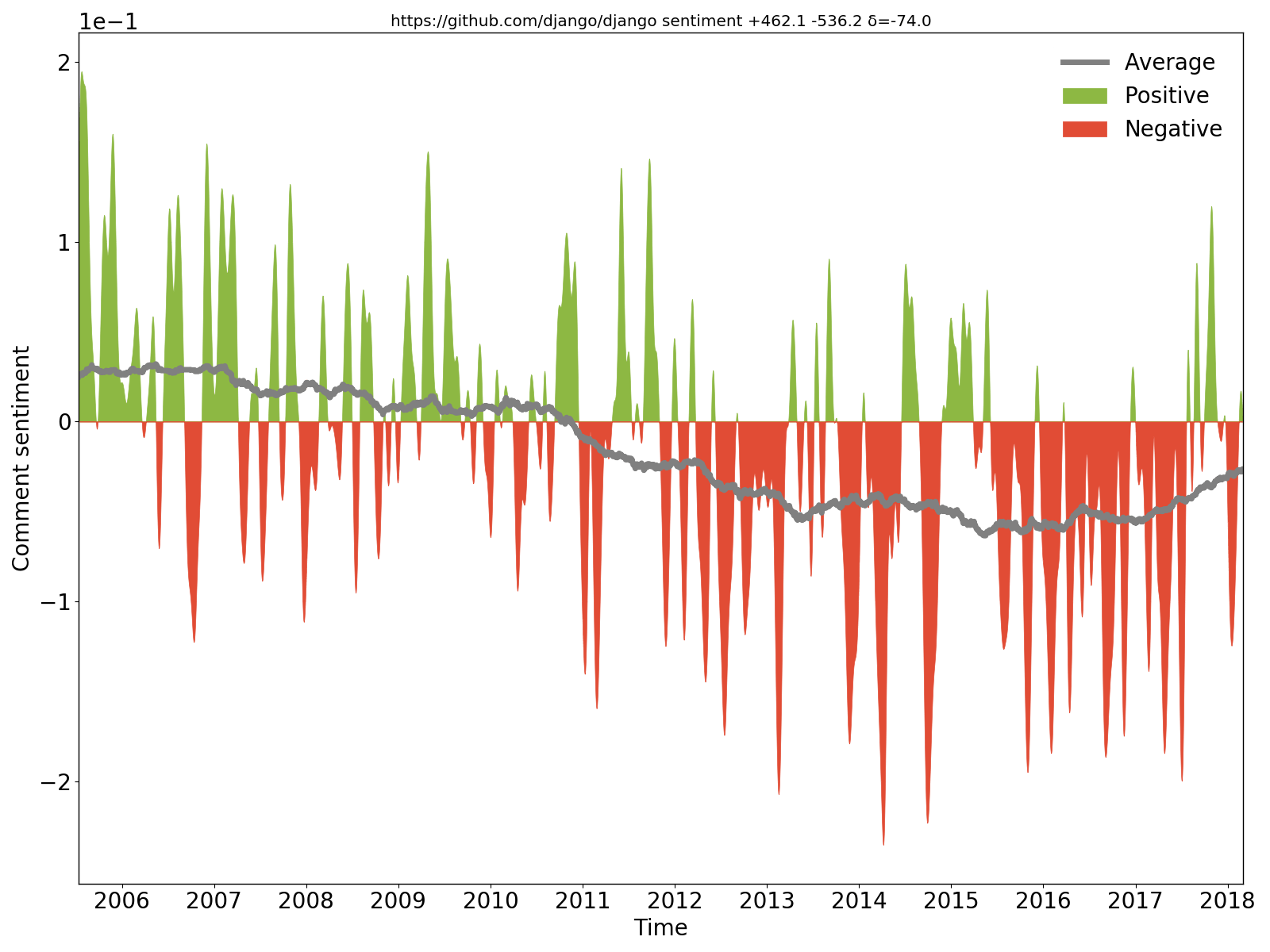
On voit clairement que les commentaires de Django étaient positifs/optimistes au début, mais sont ensuite devenus négatifs/pessimistes.
hercules --sentiment --pb https://github.com/django/django | labours -m sentiment -f pb
Nous extrayons les commentaires nouveaux et modifiés du code source à chaque validation, appliquons le réseau neuronal récurrent de sentiments à usage général BiDiSentiment et traçons les résultats. Nécessite libtensorflow. Par exemple sadly, we need to hide the rect from the documentation finder for now c'est négatif et Theano has a built-in optimization for logsumexp (...) so we can just write the expression directly qui est positive. N'en attendez pas trop - comme cela a été écrit, le modèle de sentiment est à usage général et les commentaires de code ont une nature différente, donc il n'y a pas de magie (pour l'instant).
Hercules doit être construit avec la balise "tensorflow" - ce n'est pas le cas par défaut :
make TAGS=tensorflow
Une telle construction nécessite libtensorflow .
hercules --burndown --burndown-files --burndown-people --couples --shotness --devs [--people-dict=/path/to/identities]
labours -m all
Hercules dispose d'un système de plugins et permet d'exécuter des analyses personnalisées. Voir PLUGINS.md.
hercules combine est la commande qui joint plusieurs résultats d'analyse au format Protocol Buffers.
hercules --burndown --pb https://github.com/go-git/go-git > go-git.pb
hercules --burndown --pb https://github.com/src-d/hercules > hercules.pb
hercules combine go-git.pb hercules.pb | labours -f pb -m burndown-project --resample M
YAML ne prend pas en charge toute la gamme de caractères Unicode et l'analyseur côté labours peut générer des exceptions. Filtrez la sortie d' hercules via fix_yaml_unicode.py pour supprimer ces caractères incriminés.
hercules --burndown --burndown-people https://github.com/... | python3 fix_yaml_unicode.py | labours -m people
Ces options affectent tous les tracés :
labours [--style=white|black] [--backend=] [--size=Y,X]
--style définit le style général de l'intrigue (voir labours --help ). --background change l'arrière-plan de l'intrigue en blanc ou en noir. --backend choisit le backend Matplotlib. --size définit la taille de la figure en pouces. La valeur par défaut est 12,9 .
(obligatoire sous macOS), vous pouvez épingler le backend Matplotlib par défaut avec
echo "backend: TkAgg" > ~/.matplotlib/matplotlibrc
Ces options sont efficaces uniquement dans les graphiques burndown :
labours [--text-size] [--relative]
--text-size modifie la taille de la police, --relative active la mise en page burndown étendue.
Il est possible de sortir toutes les informations nécessaires pour dessiner les tracés au format JSON. Ajoutez simplement .json à la sortie ( -o ) et vous avez terminé. Le format des données n'est pas entièrement spécifié et dépend du code Python qui le génère. Chaque fichier JSON doit contenir "type" qui reflète le type de tracé.
--first-parent comme solution de contournement.hercules pour le noyau Linux en mode "couples" est de 1,5 Go et prend plus d'une heure/180 Go de RAM pour être analysée. Cependant, la plupart des référentiels sont analysés en une minute. Essayez plutôt d'utiliser les tampons de protocole ( hercules --pb et labours -f pb ). # Debian, Ubuntu
apt install libyaml-dev
# macOS
brew install yaml-cpp libyaml
# you might need to re-install pyyaml for changes to make effect
pip uninstall pyyaml
pip --no-cache-dir install pyyaml
Si le référentiel analysé est volumineux et utilise largement le branchement, la collecte de statistiques d'avancement peut échouer avec un MOO. Vous devriez essayer ce qui suit :
--skip-blacklist pour éviter d'analyser les fichiers indésirables. Il est également possible de contraindre le --language .--hibernation-distance 10 --burndown-hibernation-threshold=1000 . Jouez avec ces deux nombres pour commencer à hiberner juste avant le MOO.--burndown-hibernation-disk --burndown-hibernation-dir /path .--first-parent , vous gagnez. src-d/go-git à go-git/go-git . Mettez à niveau la base de code pour qu'elle soit compatible avec la dernière version de Go. 

