Un outil pour l'extension de thésaurus utilisant les méthodes de propagation d'étiquettes. À partir d'un corpus de textes et d'un thésaurus existant, il génère des suggestions pour étendre les ensembles de synonymes existants. Cet outil a été développé dans le cadre du mémoire de maîtrise « Propagation d'étiquettes pour l'extension du thésaurus du droit fiscal » à la Chaire « Ingénierie logicielle pour les systèmes d'information d'entreprise (sebis) », Université technique de Munich (TUM).
Résumé de thèse. Avec l’essor de la numérisation, la recherche d’informations doit faire face à des quantités croissantes de contenu numérisé. Les fournisseurs de contenu juridique investissent beaucoup d’argent dans la création d’ontologies spécifiques à un domaine, telles que des thésaurus, afin de récupérer un nombre considérablement accru de documents pertinents. Depuis 2002, de nombreuses méthodes de propagation d'étiquettes ont été développées, par exemple pour identifier des groupes de nœuds similaires dans des graphes. La propagation d'étiquettes est une famille d'algorithmes d'apprentissage automatique semi-supervisés basés sur des graphiques. Dans cette thèse, nous testerons l’adéquation des méthodes de propagation d’étiquettes pour étendre un thésaurus du domaine du droit fiscal. Le graphe sur lequel s'opère la propagation des étiquettes est un graphe de similarité construit à partir d'incorporations de mots. Nous couvrons le processus de bout en bout et menons plusieurs études de paramètres pour comprendre l'impact de certains hyper-paramètres sur la performance globale. Les résultats sont ensuite évalués dans des études manuelles et comparés à une approche de base.
L'outil a été implémenté à l'aide de l'architecture de tuyaux et de filtres suivante :
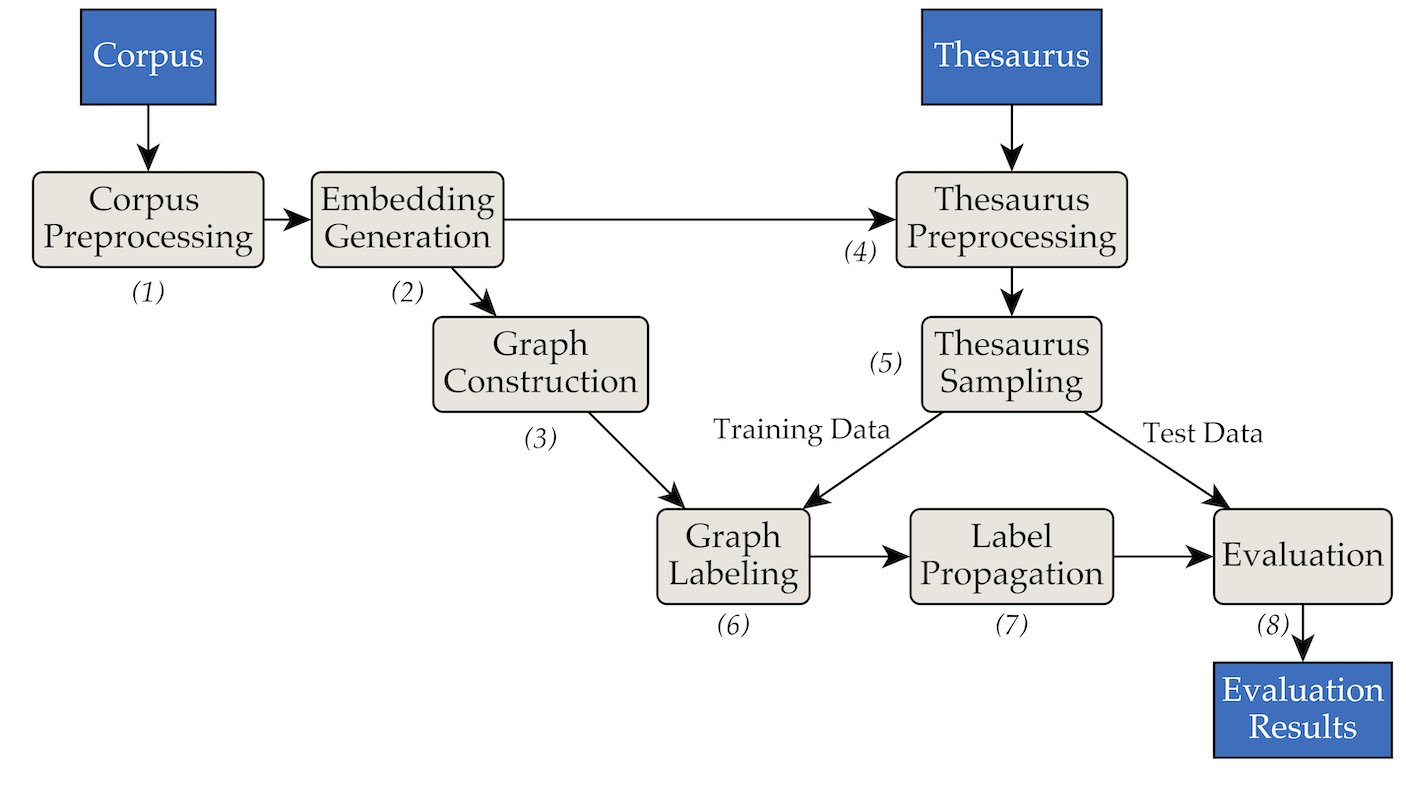
pipenv (Guide d'installation).pipenv install . data/RW40jsons et le thésaurus dans data/german_relat_pretty-20180605.json . Voir phase1.py et phase4.py pour plus d'informations sur les formats de fichiers attendus.output/<PHASE_FOLDER>/<DATE> . Les plus importants sont 08_propagation_evaluation et XX_runs . Dans 08_propagation_evaluation , les statistiques d'évaluation sont stockées sous stats.json avec un tableau contenant les prédictions, la formation et l'ensemble de tests ( main.txt , dans les autres scripts le plus souvent appelés df_evaluation ). Dans XX_runs , le journal d'une exécution est stocké. Si plusieurs exécutions ont été déclenchées via multi_runs.py (chacune avec un ensemble d'entraînement/test différent), les statistiques combinées de toutes les exécutions individuelles sont également stockées sous all_stats.json . Via purew2v_parameter_studies.py, la ligne de base du vecteur synset que nous avons introduite dans notre thèse peut être exécutée. Cela nécessite un ensemble d’intégrations de mots et une ou plusieurs divisions de formation/test de thésaurus. Voir sample_commands.md pour un exemple.
Dans ipynbs , nous avons fourni quelques exemples de blocs-notes Jupyter qui ont été utilisés pour générer (a) des statistiques, (b) des diagrammes et (c) les fichiers Excel pour les évaluations manuelles. Vous pouvez les explorer en exécutant pipenv shell , puis en démarrant Jupyter avec jupyter notebook .
main.py ou multi_run.py .

