Cours sur le modèle de langage étendu
? Suivez-moi sur X • ? Faire des câlins • Blog • ? GNN pratique
Le cours LLM est divisé en trois parties :
- ? LLM Fundamentals couvre les connaissances essentielles sur les mathématiques, Python et les réseaux de neurones.
- ?? Le scientifique LLM se concentre sur la création des meilleurs LLM possibles en utilisant les dernières techniques.
- ? L'ingénieur LLM se concentre sur la création d'applications basées sur LLM et sur leur déploiement.
Pour une version interactive de ce cours, j'ai créé deux assistants LLM qui répondront aux questions et testeront vos connaissances de manière personnalisée :
- ? HuggingChat Assistant : Version gratuite utilisant Mixtral-8x7B.
- ? Assistant ChatGPT : Nécessite un compte premium.
Carnets
Une liste de cahiers et d'articles liés aux grands modèles de langage.
Outils
| Carnet de notes | Description | Carnet de notes |
|---|
| ? Évaluation automatique LLM | Évaluez automatiquement vos LLM à l'aide de RunPod | |
| ? Kit de fusion paresseux | Fusionnez facilement des modèles à l'aide de MergeKit en un seul clic. | |
| ? ParesseuxAxolotl | Affinez les modèles dans le cloud à l'aide d'Axolotl en un clic. | |
| ⚡Quant automatique | Quantifiez les LLM aux formats GGUF, GPTQ, EXL2, AWQ et HQQ en un clic. | |
| ? Arbre généalogique modèle | Visualisez l’arbre généalogique des modèles fusionnés. | |
| Espace zéro | Créez automatiquement une interface de discussion Gradio à l'aide d'un ZeroGPU gratuit. | |
Réglage fin
| Carnet de notes | Description | Article | Carnet de notes |
|---|
| Affinez Llama 2 avec QLoRA | Guide étape par étape pour affiner le réglage supervisé de Llama 2 dans Google Colab. | Article | |
| Affiner CodeLlama à l'aide d'Axolotl | Guide de bout en bout de l’outil de pointe pour le réglage fin. | Article | |
| Affiner Mistral-7b avec QLoRA | Supervision du réglage fin de Mistral-7b dans un Google Colab gratuit avec TRL. | | |
| Affiner Mistral-7b avec DPO | Boostez les performances des modèles affinés supervisés avec DPO. | Article | |
| Affinez Llama 3 avec ORPO | Un réglage fin moins cher et plus rapide en une seule étape avec ORPO. | Article | |
| Affinez Llama 3.1 avec Unsloth | Mise au point supervisée ultra efficace dans Google Colab. | Article | |
Quantification
| Carnet de notes | Description | Article | Carnet de notes |
|---|
| Introduction à la quantification | Optimisation d'un grand modèle de langage à l'aide de la quantification 8 bits. | Article | |
| Quantification 4 bits à l'aide de GPTQ | Quantifiez vos propres LLM open source pour les exécuter sur du matériel grand public. | Article | |
| Quantification avec GGUF et lama.cpp | Quantisez les modèles Llama 2 avec llama.cpp et téléchargez les versions GGUF sur le HF Hub. | Article | |
| ExLlamaV2 : la bibliothèque la plus rapide pour exécuter des LLM | Quantifiez et exécutez les modèles EXL2 et téléchargez-les sur le HF Hub. | Article | |
Autre
| Carnet de notes | Description | Article | Carnet de notes |
|---|
| Stratégies de décodage dans les grands modèles de langage | Un guide pour la génération de texte, de la recherche de faisceaux à l'échantillonnage de noyaux | Article | |
| Améliorez ChatGPT avec les Knowledge Graphs | Augmentez les réponses de ChatGPT avec des graphiques de connaissances. | Article | |
| Fusionner des LLM avec MergeKit | Créez vos propres modèles facilement, sans GPU ! | Article | |
| Créer des MoE avec MergeKit | Combinez plusieurs experts en un seul frankenMoE | Article | |
| Décensurer tout LLM avec ablitération | Perfectionnement sans reconversion | Article | |
? Fondamentaux du LLM
Cette section présente les connaissances essentielles sur les mathématiques, Python et les réseaux de neurones. Vous ne voudrez peut-être pas commencer ici, mais référez-vous-y si nécessaire.
Basculer la section
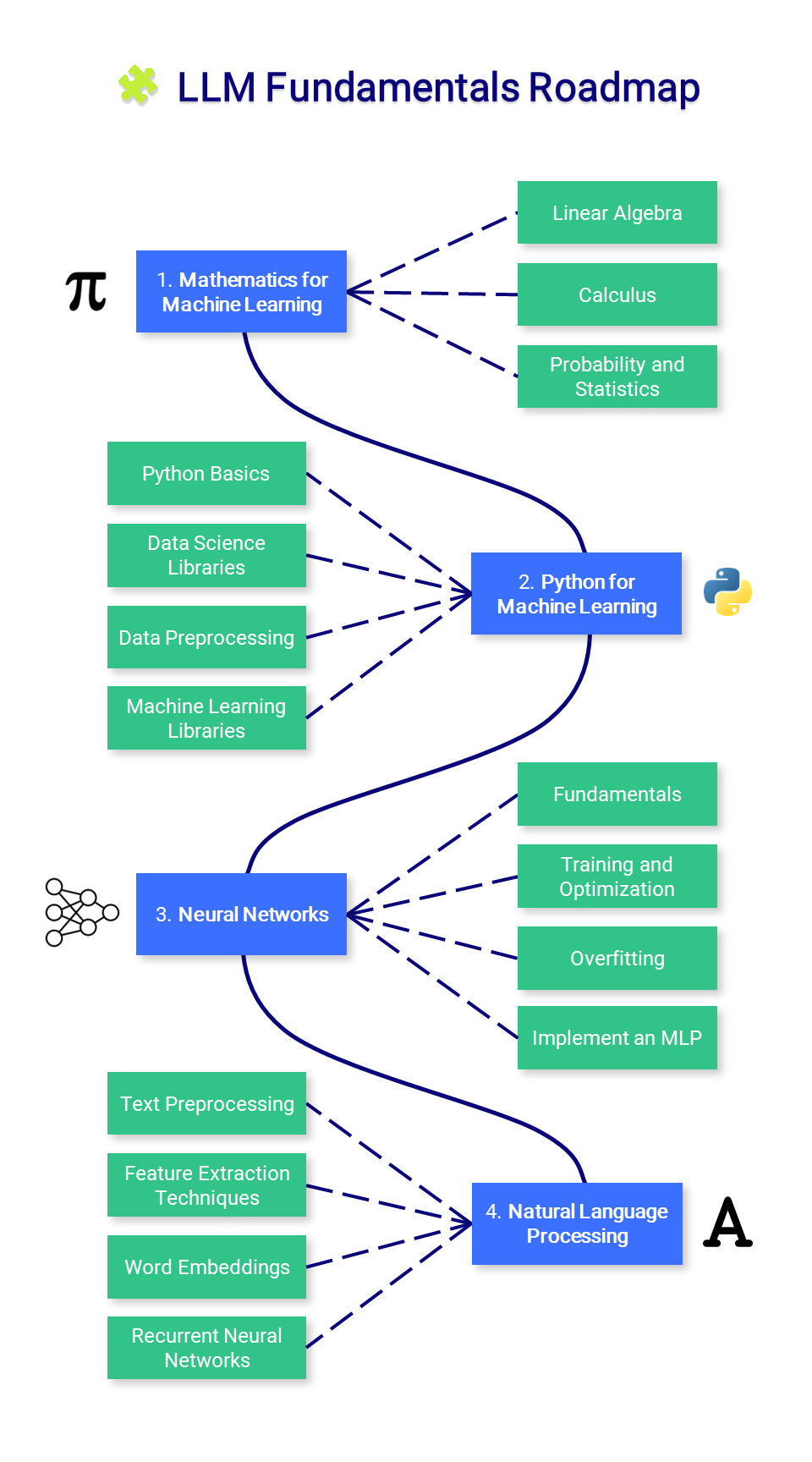
1. Mathématiques pour l'apprentissage automatique
Avant de maîtriser le machine learning, il est important de comprendre les concepts mathématiques fondamentaux qui alimentent ces algorithmes.
- Algèbre linéaire : Ceci est crucial pour comprendre de nombreux algorithmes, notamment ceux utilisés en deep learning. Les concepts clés incluent les vecteurs, les matrices, les déterminants, les valeurs propres et les vecteurs propres, les espaces vectoriels et les transformations linéaires.
- Calcul : De nombreux algorithmes d'apprentissage automatique impliquent l'optimisation de fonctions continues, ce qui nécessite une compréhension des dérivées, des intégrales, des limites et des séries. Le calcul multivarié et le concept de gradients sont également importants.
- Probabilités et statistiques : celles-ci sont cruciales pour comprendre comment les modèles apprennent des données et font des prédictions. Les concepts clés comprennent la théorie des probabilités, les variables aléatoires, les distributions de probabilité, les attentes, la variance, la covariance, la corrélation, les tests d'hypothèses, les intervalles de confiance, l'estimation du maximum de vraisemblance et l'inférence bayésienne.
Ressources:
- 3Blue1Brown - The Essence of Linear Algebra : Série de vidéos qui donnent une intuition géométrique à ces concepts.
- StatQuest avec Josh Starmer - Principes fondamentaux des statistiques : propose des explications simples et claires sur de nombreux concepts statistiques.
- AP Statistics Intuition par Mme Aerin : liste d'articles Medium qui fournissent l'intuition derrière chaque distribution de probabilité.
- Algèbre linéaire immersive : une autre interprétation visuelle de l'algèbre linéaire.
- Khan Academy - Algèbre linéaire : Idéal pour les débutants car il explique les concepts de manière très intuitive.
- Khan Academy - Calcul : Un cours interactif qui couvre toutes les bases du calcul.
- Khan Academy - Probabilités et statistiques : fournit le matériel dans un format facile à comprendre.
2. Python pour l'apprentissage automatique
Python est un langage de programmation puissant et flexible, particulièrement adapté à l'apprentissage automatique, grâce à sa lisibilité, sa cohérence et son écosystème robuste de bibliothèques de science des données.
- Notions de base de Python : la programmation Python nécessite une bonne compréhension de la syntaxe de base, des types de données, de la gestion des erreurs et de la programmation orientée objet.
- Bibliothèques de science des données : cela inclut la familiarité avec NumPy pour les opérations numériques, Pandas pour la manipulation et l'analyse des données, Matplotlib et Seaborn pour la visualisation des données.
- Prétraitement des données : cela implique la mise à l'échelle et la normalisation des fonctionnalités, la gestion des données manquantes, la détection des valeurs aberrantes, le codage des données catégorielles et la division des données en ensembles de formation, de validation et de test.
- Bibliothèques d'apprentissage automatique : la maîtrise de Scikit-learn, une bibliothèque fournissant une large sélection d'algorithmes d'apprentissage supervisé et non supervisé, est essentielle. Il est important de comprendre comment implémenter des algorithmes tels que la régression linéaire, la régression logistique, les arbres de décision, les forêts aléatoires, les k-voisins les plus proches (K-NN) et le clustering K-means. Les techniques de réduction de dimensionnalité telles que PCA et t-SNE sont également utiles pour visualiser des données de grande dimension.
Ressources:
- Real Python : une ressource complète avec des articles et des didacticiels pour les concepts Python débutants et avancés.
- freeCodeCamp - Learn Python : longue vidéo qui fournit une introduction complète à tous les concepts de base de Python.
- Python Data Science Handbook : livre numérique gratuit qui constitue une excellente ressource pour apprendre les pandas, NumPy, Matplotlib et Seaborn.
- freeCodeCamp - Machine Learning for Everybody : Introduction pratique aux différents algorithmes d'apprentissage automatique pour les débutants.
- Udacity - Introduction à l'apprentissage automatique : cours gratuit qui couvre la PCA et plusieurs autres concepts d'apprentissage automatique.
3. Réseaux de neurones
Les réseaux de neurones constituent un élément fondamental de nombreux modèles d’apprentissage automatique, en particulier dans le domaine de l’apprentissage profond. Pour les utiliser efficacement, une compréhension globale de leur conception et de leur mécanique est essentielle.
- Fondamentaux : Cela inclut la compréhension de la structure d'un réseau neuronal tel que les couches, les poids, les biais et les fonctions d'activation (sigmoïde, tanh, ReLU, etc.)
- Formation et optimisation : Familiarisez-vous avec la rétropropagation et les différents types de fonctions de perte, comme l'erreur quadratique moyenne (MSE) et l'entropie croisée. Comprenez divers algorithmes d'optimisation tels que Gradient Descent, Stochastic Gradient Descent, RMSprop et Adam.
- Surajustement : comprenez le concept de surajustement (où un modèle fonctionne bien sur les données d'entraînement mais mal sur les données invisibles) et apprenez diverses techniques de régularisation (abandon, régularisation L1/L2, arrêt anticipé, augmentation des données) pour l'éviter.
- Implémenter un Perceptron multicouche (MLP) : créez un MLP, également connu sous le nom de réseau entièrement connecté, à l'aide de PyTorch.
Ressources:
- 3Blue1Brown - Mais qu'est-ce qu'un réseau de neurones ? : Cette vidéo donne une explication intuitive des réseaux de neurones et de leur fonctionnement interne.
- freeCodeCamp - Deep Learning Crash Course : Cette vidéo présente efficacement tous les concepts les plus importants du deep learning.
- Fast.ai - Practical Deep Learning : cours gratuit conçu pour les personnes ayant une expérience en codage et souhaitant en savoir plus sur l'apprentissage profond.
- Patrick Loeber - Tutoriels PyTorch : Série de vidéos pour les débutants complets pour en savoir plus sur PyTorch.
4. Traitement du langage naturel (NLP)
La PNL est une branche fascinante de l’intelligence artificielle qui comble le fossé entre le langage humain et la compréhension automatique. Du simple traitement de texte à la compréhension des nuances linguistiques, la PNL joue un rôle crucial dans de nombreuses applications telles que la traduction, l'analyse des sentiments, les chatbots et bien plus encore.
- Prétraitement du texte : apprenez diverses étapes de prétraitement du texte telles que la tokenisation (diviser le texte en mots ou en phrases), la radicalisation (réduire les mots à leur forme racine), la lemmatisation (similaire à la radicalisation mais prend en compte le contexte), la suppression des mots vides, etc.
- Techniques d'extraction de fonctionnalités : familiarisez-vous avec les techniques permettant de convertir des données textuelles dans un format pouvant être compris par les algorithmes d'apprentissage automatique. Les méthodes clés incluent le sac de mots (BoW), la fréquence des documents à fréquence inverse (TF-IDF) et les n-grammes.
- Incorporations de mots : les intégrations de mots sont un type de représentation de mots qui permet à des mots ayant des significations similaires d'avoir des représentations similaires. Les méthodes clés incluent Word2Vec, GloVe et FastText.
- Réseaux de neurones récurrents (RNN) : Comprendre le fonctionnement des RNN, un type de réseau de neurones conçu pour fonctionner avec des données de séquence. Explorez les LSTM et les GRU, deux variantes de RNN capables d'apprendre des dépendances à long terme.
Ressources:
- RealPython - NLP avec spaCy en Python : Guide exhaustif sur la bibliothèque spaCy pour les tâches NLP en Python.
- Kaggle - Guide NLP : Quelques cahiers et ressources pour une explication pratique de la PNL en Python.
- Jay Alammar - The Illustration Word2Vec : Une bonne référence pour comprendre la célèbre architecture Word2Vec.
- Jake Tae - PyTorch RNN from Scratch : Implémentation pratique et simple des modèles RNN, LSTM et GRU dans PyTorch.
- le blog de colah - Comprendre les réseaux LSTM : Un article plus théorique sur le réseau LSTM.
?? Le scientifique LLM
Cette section du cours se concentre sur l'apprentissage de la création des meilleurs LLM possibles en utilisant les dernières techniques.
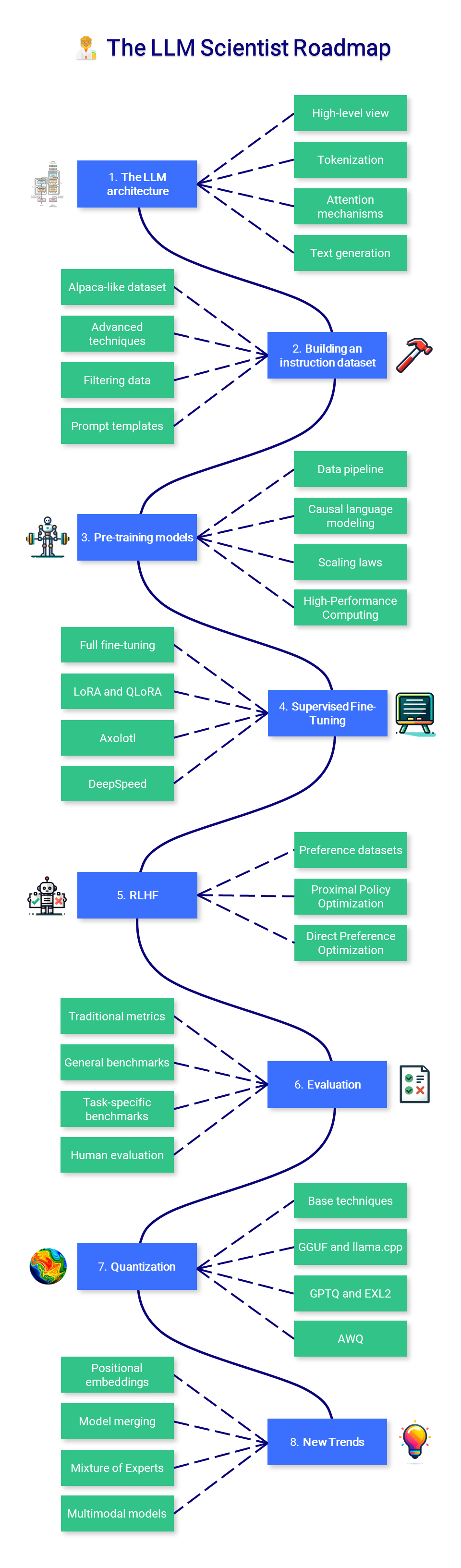
1. L'architecture du LLM
Bien qu'une connaissance approfondie de l'architecture Transformer ne soit pas requise, il est important d'avoir une bonne compréhension de ses entrées (jetons) et sorties (logits). Le mécanisme d’attention vanille est un autre élément crucial à maîtriser, car des versions améliorées de celui-ci seront introduites ultérieurement.
- Vue de haut niveau : revisitez l'architecture du transformateur codeur-décodeur, et plus particulièrement l'architecture GPT du décodeur uniquement, qui est utilisée dans chaque LLM moderne.
- Tokenisation : Comprendre comment convertir des données textuelles brutes dans un format compréhensible par le modèle, ce qui implique de diviser le texte en jetons (généralement des mots ou des sous-mots).
- Mécanismes d'attention : saisissez la théorie derrière les mécanismes d'attention, y compris l'auto-attention et l'attention du produit scalaire à l'échelle, qui permettent au modèle de se concentrer sur différentes parties de l'entrée lors de la production d'une sortie.
- Génération de texte : découvrez les différentes manières dont le modèle peut générer des séquences de sortie. Les stratégies courantes incluent le décodage glouton, la recherche de faisceaux, l'échantillonnage top-k et l'échantillonnage de noyau.
Références :
- The Illustrated Transformer par Jay Alammar : Une explication visuelle et intuitive du modèle Transformer.
- Le GPT-2 illustré par Jay Alammar : Encore plus important que l'article précédent, il se concentre sur l'architecture GPT, qui est très similaire à celle de Llama.
- Introduction visuelle de Transformers par 3Blue1Brown : introduction visuelle simple et facile à comprendre de Transformers
- Visualisation LLM par Brendan Bycroft : Incroyable visualisation 3D de ce qui se passe à l'intérieur d'un LLM.
- nanoGPT par Andrej Karpathy : Une vidéo YouTube de 2 heures pour réimplémenter GPT à partir de zéro (pour les programmeurs).
- Attention? Attention! par Lilian Weng : Présentez le besoin d’attention de manière plus formelle.
- Stratégies de décodage dans les LLM : fournir du code et une introduction visuelle aux différentes stratégies de décodage pour générer du texte.
2. Construire un ensemble de données d'instructions
S'il est facile de trouver des données brutes sur Wikipédia et d'autres sites Web, il est difficile de collecter des paires d'instructions et de réponses dans la nature. Comme dans l’apprentissage automatique traditionnel, la qualité de l’ensemble de données influencera directement la qualité du modèle, c’est pourquoi elle pourrait constituer l’élément le plus important du processus de réglage fin.
- Ensemble de données de type alpaga : générez des données synthétiques à partir de zéro avec l'API OpenAI (GPT). Vous pouvez spécifier des valeurs initiales et des invites système pour créer un ensemble de données diversifié.
- Techniques avancées : Apprenez à améliorer les ensembles de données existants avec Evol-Instruct, à générer des données synthétiques de haute qualité comme dans les articles Orca et phi-1.
- Filtrage des données : techniques traditionnelles impliquant des regex, supprimant les quasi-doublons, se concentrant sur les réponses avec un nombre élevé de jetons, etc.
- Modèles d'invite : il n'existe pas de véritable méthode standard de formatage des instructions et des réponses, c'est pourquoi il est important de connaître les différents modèles de chat, tels que ChatML, Alpaca, etc.
Références :
- Préparation d'un ensemble de données pour le réglage des instructions par Thomas Capelle : Exploration des ensembles de données Alpaca et Alpaca-GPT4 et comment les formater.
- Génération d'un ensemble de données d'instructions cliniques par Solano Todeschini : Tutoriel sur la façon de créer un ensemble de données d'instructions synthétiques à l'aide de GPT-4.
- GPT 3.5 pour la classification des actualités par Kshitiz Sahay : utilisez GPT 3.5 pour créer un ensemble de données d'instructions afin d'affiner Llama 2 pour la classification des actualités.
- Création d'un ensemble de données pour affiner le LLM : bloc-notes contenant quelques techniques pour filtrer un ensemble de données et télécharger le résultat.
- Modèle de discussion par Matthew Carrigan : page de Hugging Face sur les modèles d'invite
3. Modèles de pré-formation
La pré-formation est un processus très long et coûteux, c'est pourquoi ce n'est pas l'objet de ce cours. Il est bon d'avoir un certain niveau de compréhension de ce qui se passe pendant la pré-formation, mais une expérience pratique n'est pas requise.
- Pipeline de données : la pré-formation nécessite d'énormes ensembles de données (par exemple, Llama 2 a été formé sur 2 000 milliards de jetons) qui doivent être filtrés, tokenisés et rassemblés avec un vocabulaire prédéfini.
- Modélisation du langage causal : Découvrez la différence entre la modélisation du langage causal et masqué, ainsi que la fonction de perte utilisée dans ce cas. Pour une pré-formation efficace, apprenez-en davantage sur Megatron-LM ou gpt-neox.
- Lois de mise à l'échelle : les lois de mise à l'échelle décrivent les performances attendues du modèle en fonction de la taille du modèle, de la taille de l'ensemble de données et de la quantité de calcul utilisée pour la formation.
- Calcul haute performance : hors de portée ici, mais davantage de connaissances sur le HPC sont fondamentales si vous envisagez de créer votre propre LLM à partir de zéro (matériel, charge de travail distribuée, etc.).
Références :
- LLMDataHub par Junhao Zhao : liste organisée d'ensembles de données pour la pré-formation, le réglage fin et le RLHF.
- Entraînement d'un modèle de langage causal à partir de zéro par Hugging Face : pré-entraînez un modèle GPT-2 à partir de zéro à l'aide de la bibliothèque de transformateurs.
- TinyLlama de Zhang et al. : Consultez ce projet pour bien comprendre comment un modèle de lama est formé à partir de zéro.
- Modélisation du langage causal par Hugging Face : expliquez la différence entre la modélisation du langage causal et masqué et comment affiner rapidement un modèle DistilGPT-2.
- Les implications sauvages du chinchilla par nostalgebraist : discutez des lois de mise à l'échelle et expliquez ce qu'elles signifient pour les LLM en général.
- BLOOM par BigScience : Page Notion qui décrit comment le modèle BLOOM a été construit, avec de nombreuses informations utiles sur la partie ingénierie et les problèmes rencontrés.
- Journal de bord OPT-175 par Meta : journaux de recherche montrant ce qui n'a pas fonctionné et ce qui s'est bien passé. Utile si vous envisagez de pré-entraîner un très grand modèle de langage (dans ce cas, 175 B de paramètres).
- LLM 360 : un cadre pour les LLM open source avec du code de formation et de préparation des données, des données, des métriques et des modèles.
4. Mise au point supervisée
Les modèles pré-entraînés ne sont formés que sur une tâche de prédiction du prochain jeton, c'est pourquoi ils ne sont pas des assistants utiles. SFT vous permet de les modifier pour répondre aux instructions. De plus, il vous permet d'affiner votre modèle sur n'importe quelle donnée (privée, non vue par GPT-4, etc.) et de l'utiliser sans avoir à payer pour une API comme celle d'OpenAI.
- Affinement complet : Le réglage fin complet fait référence à l'entraînement de tous les paramètres du modèle. Ce n’est pas une technique efficace, mais elle produit des résultats légèrement meilleurs.
- LoRA : Une technique efficace en termes de paramètres (PEFT) basée sur des adaptateurs de bas rang. Au lieu de former tous les paramètres, nous formons uniquement ces adaptateurs.
- QLoRA : Un autre PEFT basé sur LoRA, qui quantifie également les poids du modèle en 4 bits et introduit des optimiseurs paginés pour gérer les pics de mémoire. Combinez-le avec Unsloth pour l'exécuter efficacement sur un bloc-notes Colab gratuit.
- Axolotl : Un outil de réglage fin convivial et puissant qui est utilisé dans de nombreux modèles open source de pointe.
- DeepSpeed : Pré-entraînement et réglage fin efficaces des LLM pour les paramètres multi-GPU et multi-nœuds (implémenté dans Axolotl).
Références :
- Le guide de formation LLM pour novices d'Alpin : aperçu des principaux concepts et paramètres à prendre en compte lors du réglage fin des LLM.
- Informations LoRA par Sebastian Raschka : informations pratiques sur LoRA et comment sélectionner les meilleurs paramètres.
- Affinez votre propre modèle Llama 2 : tutoriel pratique sur la façon d'affiner un modèle Llama 2 à l'aide des bibliothèques Hugging Face.
- Remplissage de grands modèles linguistiques par Benjamin Marie : meilleures pratiques pour compléter des exemples de formation pour les LLM causals
- Guide du débutant sur le réglage fin du LLM : tutoriel sur la façon d'affiner un modèle CodeLlama à l'aide d'Axolotl.
5. Alignement des préférences
Après mise au point supervisée, le RLHF est une étape permettant d'aligner les réponses du LLM avec les attentes humaines. L’idée est d’apprendre les préférences à partir des commentaires humains (ou artificiels), qui peuvent être utilisés pour réduire les préjugés, censurer les modèles ou les faire agir de manière plus utile. Il est plus complexe que SFT et souvent considéré comme facultatif.
- Ensembles de données de préférence : ces ensembles de données contiennent généralement plusieurs réponses avec une sorte de classement, ce qui les rend plus difficiles à produire que les ensembles de données d'instructions.
- Optimisation de la politique proximale : cet algorithme exploite un modèle de récompense qui prédit si un texte donné est bien classé par les humains. Cette prédiction est ensuite utilisée pour optimiser le modèle SFT avec une pénalité basée sur la divergence KL.
- Optimisation directe des préférences : DPO simplifie le processus en le recadrant comme un problème de classification. Il utilise un modèle de référence au lieu d'un modèle de récompense (aucune formation nécessaire) et ne nécessite qu'un seul hyperparamètre, ce qui le rend plus stable et efficace.
Références :
- Distilabel par Argilla : Excellent outil pour créer vos propres ensembles de données. Il a été spécialement conçu pour les ensembles de données de préférences, mais peut également effectuer du SFT.
- Une introduction à la formation des LLM utilisant le RLHF par Ayush Thakur : Expliquez pourquoi le RLHF est souhaitable pour réduire les biais et augmenter les performances dans les LLM.
- Illustration RLHF par Hugging Face : Introduction au RLHF avec formation sur le modèle de récompense et mise au point avec l'apprentissage par renforcement.
- LLM de réglage des préférences par Hugging Face : comparaison des algorithmes DPO, IPO et KTO pour effectuer l'alignement des préférences.
- Formation LLM : RLHF et ses alternatives par Sebastian Rashcka : Aperçu du processus RLHF et des alternatives comme RLAIF.
- Affiner Mistral-7b avec DPO : Tutoriel pour affiner un modèle Mistral-7b avec DPO et reproduire NeuralHermes-2.5.
6. Évaluation
L'évaluation des LLM est une partie sous-évaluée du pipeline, qui prend du temps et est moyennement fiable. Votre tâche en aval doit dicter ce que vous souhaitez évaluer, mais n'oubliez jamais la loi de Goodhart : « Lorsqu'une mesure devient un objectif, elle cesse d'être une bonne mesure. »
- Métriques traditionnelles : les métriques telles que la perplexité et le score BLEU ne sont pas aussi populaires qu'elles l'étaient car elles sont erronées dans la plupart des contextes. Il est toujours important de les comprendre et de savoir quand ils peuvent être appliqués.
- Benchmarks généraux : Basé sur le Language Model Evaluation Harness, l'Open LLM Leaderboard est le principal benchmark pour les LLM à usage général (comme ChatGPT). Il existe d'autres benchmarks populaires comme BigBench, MT-Bench, etc.
- Repères spécifiques à des tâches : les tâches telles que le résumé, la traduction et la réponse aux questions disposent de repères, de mesures et même de sous-domaines (médicaux, financiers, etc.) dédiés, tels que PubMedQA pour la réponse aux questions biomédicales.
- Évaluation humaine : L'évaluation la plus fiable est le taux d'acceptation par les utilisateurs ou les comparaisons faites par les humains. L'enregistrement des commentaires des utilisateurs en plus des traces de discussion (par exemple, en utilisant LangSmith) permet d'identifier les domaines potentiels d'amélioration.
Références :
- Perplexité des modèles de longueur fixe par Hugging Face : Aperçu de la perplexité avec le code pour l'implémenter avec la bibliothèque des transformateurs.
- BLEU à vos risques et périls par Rachael Tatman : Aperçu du score BLEU et de ses nombreux enjeux avec exemples.
- Une enquête sur l'évaluation des LLM par Chang et al. : article complet sur ce qu'il faut évaluer, où évaluer et comment évaluer.
- Chatbot Arena Leaderboard par lmsys : classement Elo des LLM à usage général, basé sur des comparaisons effectuées par des humains.
7. Quantification
La quantification est le processus de conversion des poids (et des activations) d'un modèle en utilisant une précision inférieure. Par exemple, les poids stockés sur 16 bits peuvent être convertis en une représentation sur 4 bits. Cette technique est devenue de plus en plus importante pour réduire les coûts de calcul et de mémoire associés aux LLM.
- Techniques de base : Apprenez les différents niveaux de précision (FP32, FP16, INT8, etc.) et comment effectuer une quantification naïve avec les techniques absmax et point zéro.
- GGUF et llama.cpp : initialement conçus pour fonctionner sur des processeurs, llama.cpp et le format GGUF sont devenus les outils les plus populaires pour exécuter des LLM sur du matériel grand public.
- GPTQ et EXL2 : GPTQ et plus précisément le format EXL2 offrent une vitesse incroyable mais ne peuvent fonctionner que sur des GPU. Les modèles mettent également beaucoup de temps à être quantifiés.
- AWQ : Ce nouveau format est plus précis que GPTQ (perplexité moindre) mais utilise beaucoup plus de VRAM et n'est pas forcément plus rapide.
Références :
- Introduction à la quantification : aperçu de la quantification, de la quantification absmax et du point zéro, et LLM.int8() avec code.
- Quantiser les modèles Llama avec llama.cpp : Tutoriel sur la façon de quantifier un modèle Llama 2 à l'aide de llama.cpp et du format GGUF.
- Quantification LLM 4 bits avec GPTQ : Tutoriel sur la façon de quantifier un LLM à l'aide de l'algorithme GPTQ avec AutoGPTQ.
- ExLlamaV2 : La bibliothèque la plus rapide pour exécuter des LLM : Guide sur la façon de quantifier un modèle Mistral à l'aide du format EXL2 et de l'exécuter avec la bibliothèque ExLlamaV2.
- Comprendre la quantification du poids basée sur l'activation par FriendliAI : aperçu de la technique AWQ et de ses avantages.
8. Nouvelles tendances
- Intégrations positionnelles : découvrez comment les LLM codent les positions, en particulier les schémas de codage de position relative comme RoPE. Implémentez YaRN (multiplie la matrice d'attention par un facteur de température) ou ALiBi (pénalité d'attention basée sur la distance du jeton) pour étendre la longueur du contexte.
- Fusion de modèles : la fusion de modèles entraînés est devenue un moyen populaire de créer des modèles performants sans aucun réglage fin. La bibliothèque mergekit populaire implémente les méthodes de fusion les plus populaires, telles que SLERP, DARE et TIES.
- Mélange d'Experts : Mixtral a repopularisé l'architecture MoE grâce à ses excellentes performances. En parallèle, un type de frankenMoE a émergé dans la communauté OSS en fusionnant des modèles comme Phixtral, qui est une option moins chère et plus performante.
- Modèles multimodaux : ces modèles (comme CLIP, Stable Diffusion ou LLaVA) traitent plusieurs types d'entrées (texte, images, audio, etc.) avec un espace d'intégration unifié, qui débloque des applications puissantes comme la conversion texte-image.
Références :
- Extension du RoPE par EleutherAI : Article qui résume les différentes techniques d'encodage de position.
- Comprendre YaRN par Rajat Chawla : Introduction à YaRN.
- Fusionner des LLM avec mergekit : Tutoriel sur la fusion de modèles à l'aide de mergekit.
- Mélange d'experts expliqué par Hugging Face : guide exhaustif sur les ministères de l'éducation et leur fonctionnement.
- Grands modèles multimodaux par Chip Huyen : aperçu des systèmes multimodaux et de l'histoire récente de ce domaine.
? L'ingénieur LLM
Cette section du cours se concentre sur l'apprentissage de la création d'applications basées sur LLM pouvant être utilisées en production, en mettant l'accent sur l'augmentation des modèles et leur déploiement.
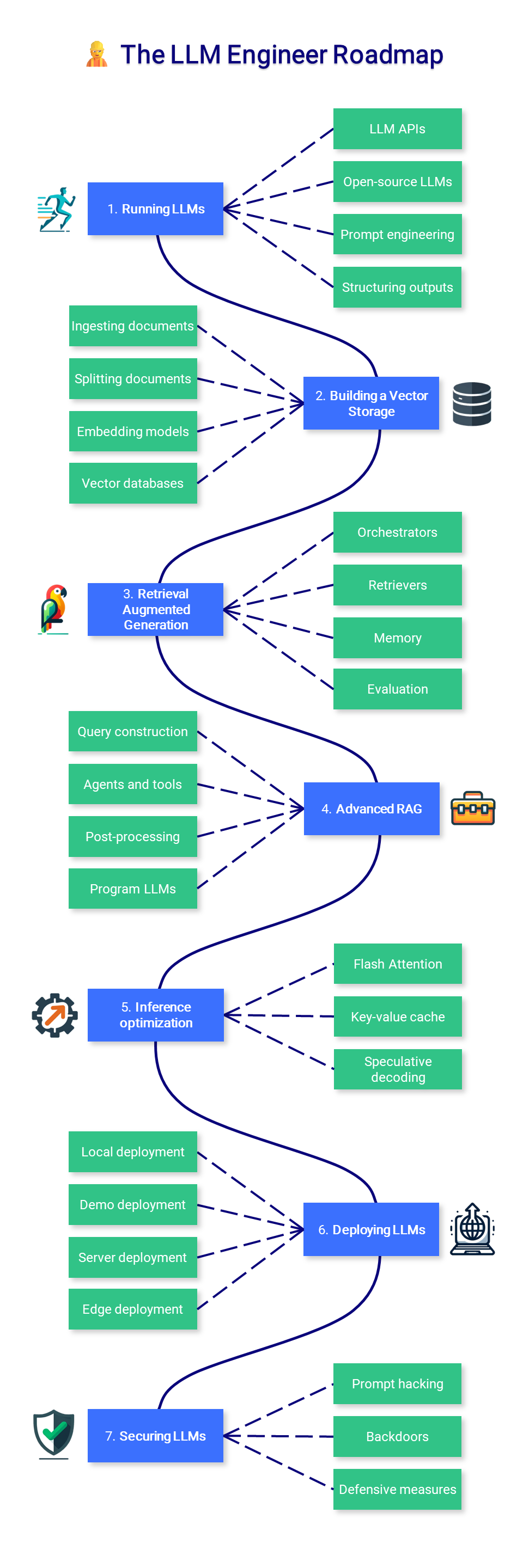
1. Exécuter des LLM
L’exécution de LLM peut être difficile en raison des exigences matérielles élevées. En fonction de votre cas d'utilisation, vous souhaiterez peut-être simplement consommer un modèle via une API (comme GPT-4) ou l'exécuter localement. Dans tous les cas, des techniques d’invite et de guidage supplémentaires peuvent améliorer et limiter le résultat de vos applications.
- API LLM : les API sont un moyen pratique de déployer des LLM. Cet espace est réparti entre des LLM privés (OpenAI, Google, Anthropic, Cohere, etc.) et des LLM open source (OpenRouter, Hugging Face, Together AI, etc.).
- LLM open source : Le Hugging Face Hub est un excellent endroit pour trouver des LLM. Vous pouvez en exécuter directement certains dans Hugging Face Spaces, ou les télécharger et les exécuter localement dans des applications comme LM Studio ou via la CLI avec llama.cpp ou Ollama.
- Ingénierie des invites : les techniques courantes incluent les invites à tir zéro, les invites à quelques tirs, la chaîne de pensée et ReAct. Ils fonctionnent mieux avec des modèles plus grands, mais peuvent être adaptés aux plus petits.
- Sorties structurantes : de nombreuses tâches nécessitent une sortie structurée, comme un modèle strict ou un format JSON. Des bibliothèques comme LMQL, Outlines, Guidance, etc. peuvent être utilisées pour guider la génération et respecter une structure donnée.
Références :
- Exécutez un LLM localement avec LM Studio par Nisha Arya : petit guide sur l'utilisation de LM Studio.
- Guide d'ingénierie rapide par DAIR.AI : liste exhaustive de techniques d'invite avec des exemples
- Outlines - Quickstart : liste des techniques de génération guidée activées par Outlines.
- LMQL - Présentation : Introduction au langage LMQL.
2. Construire un stockage vectoriel
La création d'un stockage vectoriel est la première étape pour créer un pipeline de génération augmentée de récupération (RAG). Les documents sont chargés, divisés et les morceaux pertinents sont utilisés pour produire des représentations vectorielles (incorporations) qui sont stockées pour une utilisation future lors de l'inférence.
- Ingestion de documents : les chargeurs de documents sont des wrappers pratiques qui peuvent gérer de nombreux formats : PDF, JSON, HTML, Markdown, etc. Ils peuvent également récupérer directement les données de certaines bases de données et API (GitHub, Reddit, Google Drive, etc.).
- Fractionnement de documents : les séparateurs de texte divisent les documents en morceaux plus petits et sémantiquement significatifs. Au lieu de diviser le texte après n caractères, il est souvent préférable de le diviser par en-tête ou de manière récursive, avec quelques métadonnées supplémentaires.
- Modèles d'intégration : les modèles d'intégration convertissent le texte en représentations vectorielles. Il permet une compréhension plus profonde et plus nuancée du langage, essentielle pour effectuer une recherche sémantique.
- Bases de données vectorielles : Les bases de données vectorielles (comme Chroma, Pinecone, Milvus, FAISS, Annoy, etc.) sont conçues pour stocker des vecteurs d'intégration. Ils permettent une récupération efficace des données « les plus similaires » à une requête basée sur la similarité vectorielle.
Références :
- LangChain - Séparateurs de texte : Liste des différents séparateurs de texte implémentés dans LangChain.
- Bibliothèque Sentence Transformers : bibliothèque populaire pour l’intégration de modèles.
- Classement MTEB : classement pour l'intégration de modèles.
- Les 5 meilleures bases de données vectorielles par Moez Ali : une comparaison des bases de données vectorielles les meilleures et les plus populaires.
3. Génération augmentée de récupération
Avec RAG, les LLM récupèrent des documents contextuels à partir d'une base de données pour améliorer la précision de leurs réponses. RAG est un moyen populaire d'augmenter les connaissances du modèle sans aucun réglage précis.
- Orchestrateurs : Les orchestrateurs (comme LangChain, LlamaIndex, FastRAG, etc.) sont des frameworks populaires pour connecter vos LLM à des outils, des bases de données, des mémoires, etc. et augmenter leurs capacités.
- Récupérateurs : les instructions utilisateur ne sont pas optimisées pour la récupération. Différentes techniques (par exemple, récupération multi-requêtes, HyDE, etc.) peuvent être appliquées pour les reformuler/développer et améliorer les performances.
- Mémoire : Pour mémoriser les instructions et réponses précédentes, les LLM et les chatbots comme ChatGPT ajoutent cet historique à leur fenêtre contextuelle. Ce tampon peut être amélioré avec une synthèse (par exemple, en utilisant un LLM plus petit), un magasin de vecteurs + RAG, etc.
- Évaluation : Il faut évaluer à la fois les étapes de récupération du document (précision du contexte et rappel) et de génération (fidélité et pertinence des réponses). Cela peut être simplifié avec les outils Ragas et DeepEval.
Références :
- Llamaindex - Concepts de haut niveau : Principaux concepts à connaître lors de la construction de pipelines RAG.
- Pinecone - Augmentation de récupération : aperçu du processus d'augmentation de récupération.
- LangChain - Questions et réponses avec RAG : tutoriel étape par étape pour créer un pipeline RAG typique.
- LangChain - Types de mémoire : Liste des différents types de mémoires avec une utilisation pertinente.
- Pipeline RAG - Métriques : Présentation des principales métriques utilisées pour évaluer les pipelines RAG.
4. RAG avancé
Les applications réelles peuvent nécessiter des pipelines complexes, notamment des bases de données SQL ou graphiques, ainsi que la sélection automatique des outils et API pertinents. Ces techniques avancées peuvent améliorer une solution de base et fournir des fonctionnalités supplémentaires.
- Construction de requêtes : les données structurées stockées dans des bases de données traditionnelles nécessitent un langage de requête spécifique comme SQL, Cypher, les métadonnées, etc. Nous pouvons directement traduire l'instruction utilisateur en requête pour accéder aux données avec la construction de requêtes.
- Agents et outils : Les agents complètent les LLM en sélectionnant automatiquement les outils les plus pertinents pour apporter une réponse. Ces outils peuvent être aussi simples que l'utilisation de Google ou Wikipedia, ou plus complexes comme un interpréteur Python ou Jira.
- Post-traitement : étape finale qui traite les entrées qui alimentent le LLM. Il améliore la pertinence et la diversité des documents récupérés grâce au reclassement, à la fusion RAG et à la classification.
- Programme LLM : des frameworks comme DSPy vous permettent d'optimiser les invites et les pondérations basées sur des évaluations automatisées de manière programmatique.
Références :
- LangChain – Construction de requêtes : article de blog sur les différents types de construction de requêtes.
- LangChain - SQL : Tutoriel sur la façon d'interagir avec les bases de données SQL avec des LLM, impliquant Text-to-SQL et un agent SQL facultatif.
- Pinecone - Agents LLM : Introduction aux agents et outils de différents types.
- Agents autonomes propulsés par LLM par Lilian Weng : article plus théorique sur les agents LLM.
- LangChain - RAG d'OpenAI : aperçu des stratégies RAG utilisées par OpenAI, y compris le post-traitement.
- DSPy en 8 étapes : guide général sur DSPy présentant les modules, les signatures et les optimiseurs.
5. Optimisation de l'inférence
La génération de texte est un processus coûteux qui nécessite du matériel coûteux. En plus de la quantification, diverses techniques ont été proposées pour maximiser le débit et réduire les coûts d'inférence.
- Flash Attention : Optimisation du mécanisme d'attention pour transformer sa complexité de quadratique à linéaire, accélérant à la fois la formation et l'inférence.
- Cache clé-valeur : comprenez le cache clé-valeur et les améliorations introduites dans Multi-Query Attention (MQA) et Grouped-Query Attention (GQA).
- Décodage spéculatif : utilisez un petit modèle pour produire des brouillons qui sont ensuite révisés par un modèle plus grand pour accélérer la génération de texte.
Références :
- Inférence GPU par Hugging Face : expliquez comment optimiser l'inférence sur les GPU.
- Inférence LLM par Databricks : meilleures pratiques pour optimiser l'inférence LLM en production.
- Optimisation des LLM pour la vitesse et la mémoire en serrant le visage : expliquez trois techniques principales pour optimiser la vitesse et la mémoire, à savoir la quantification, l'attention flash et les innovations architecturales.
- Génération assistée par Hugging Face : la version HF du décodage spéculatif, c'est un article de blog intéressant sur la façon dont il fonctionne avec le code pour l'implémenter.
6. Déployer des LLM
Le déploiement de LLM à grande échelle est une prouesse d'ingénierie qui peut nécessiter plusieurs clusters de GPU. Dans d’autres scénarios, les démos et les applications locales peuvent être réalisées avec une complexité bien moindre.
- Déploiement local : la confidentialité est un avantage important des LLM open source par rapport aux LLM privés. Les serveurs LLM locaux (LM Studio, Ollama, oobabooga, kobold.cpp, etc.) capitalisent sur cet avantage pour alimenter les applications locales.
- Déploiement de démonstration : des cadres comme Gradio et Streamlit sont utiles pour prototyper les applications et partager des démos. Vous pouvez également les héberger facilement en ligne, par exemple en utilisant des espaces de visage étreintes.
- Déploiement du serveur : le déploiement des LLMS nécessite un cloud (voir également Skypilot) ou une infrastructure sur prém et exploiter souvent des cadres de génération de texte optimisés comme TGI, VLLM, etc.
- Déploiement de bord : dans des environnements contraints, des cadres haute performance comme MLC LLM et MNN-LLM peuvent déployer LLM dans les navigateurs Web, Android et iOS.
Références :
- Streamlit - Créez une application LLM de base: Tutoriel pour créer une application de base de type ChatGPT en utilisant Streamlit.
- HF LLM Inférence Container: Déployez LLMS sur Amazon SageMaker à l'aide du conteneur d'inférence de Hugging Face.
- Philschmid Blog par Philipp Schmid: Collection d'articles de haute qualité sur le déploiement de LLM à l'aide d'Amazon Sagemaker.
- Optimisation de la force par Hamel Husain: comparaison de TGI, VLLM, Ctranslate2 et MLC en termes de débit et de latence.
7. sécuriser les LLM
En plus des problèmes de sécurité traditionnels associés aux logiciels, les LLM ont des faiblesses uniques en raison de la façon dont ils sont formés et invités.
- Piratage rapide : différentes techniques liées à l'ingénierie rapide, y compris l'injection rapide (instruction supplémentaire pour détourner la réponse du modèle), les données / la fuite d'invite (récupérer ses données / invites d'origine) et le jailbreaking (invite d'artisanat pour contourner les fonctionnalités de sécurité).
- Barginates : les vecteurs d'attaque peuvent cibler les données d'entraînement elle-même, en empoisonnant les données d'entraînement (par exemple, avec de fausses informations) ou en créant des délais (se déclenche secrètes pour modifier le comportement du modèle pendant l'inférence).
- Mesures défensives : La meilleure façon de protéger vos applications LLM est de les tester contre ces vulnérabilités (par exemple, en utilisant une équipe rouge et des chèques comme Garak) et de les observer en production (avec un cadre comme Langfuse).
Références :
- OWASP LLM Top 10 par Hego Wiki: Liste des 10 vulnérabilités les plus critiques vues dans les applications LLM.
- Primer d'injection rapide par Joseph Thacker: Guide court dédié à l'injection rapide pour les ingénieurs.
- Sécurité LLM par @llm_sec: liste approfondie des ressources liées à la sécurité LLM.
- Red Teaming LLMS par Microsoft: Guide sur la façon d'effectuer une équipe rouge avec LLMS.
Remerciements
Cette feuille de route a été inspirée par l'excellente feuille de route DevOps de Milan Milanović et Romano Roth.
Un merci spécial à :
- Thomas Thelen pour me motiver à créer une feuille de route
- André Frade pour sa contribution et son examen du premier projet
- Dino Dunn pour avoir fourni des ressources sur la sécurité LLM
- Magdalena Kuhn pour l'amélioration de la partie "évaluation humaine"
- Ovoverdose pour suggérer la vidéo de 3Blue1Brown sur les transformateurs
Avertissement: je ne suis pas affilié à des sources répertoriées ici.


