clearml agent
v1.9.2

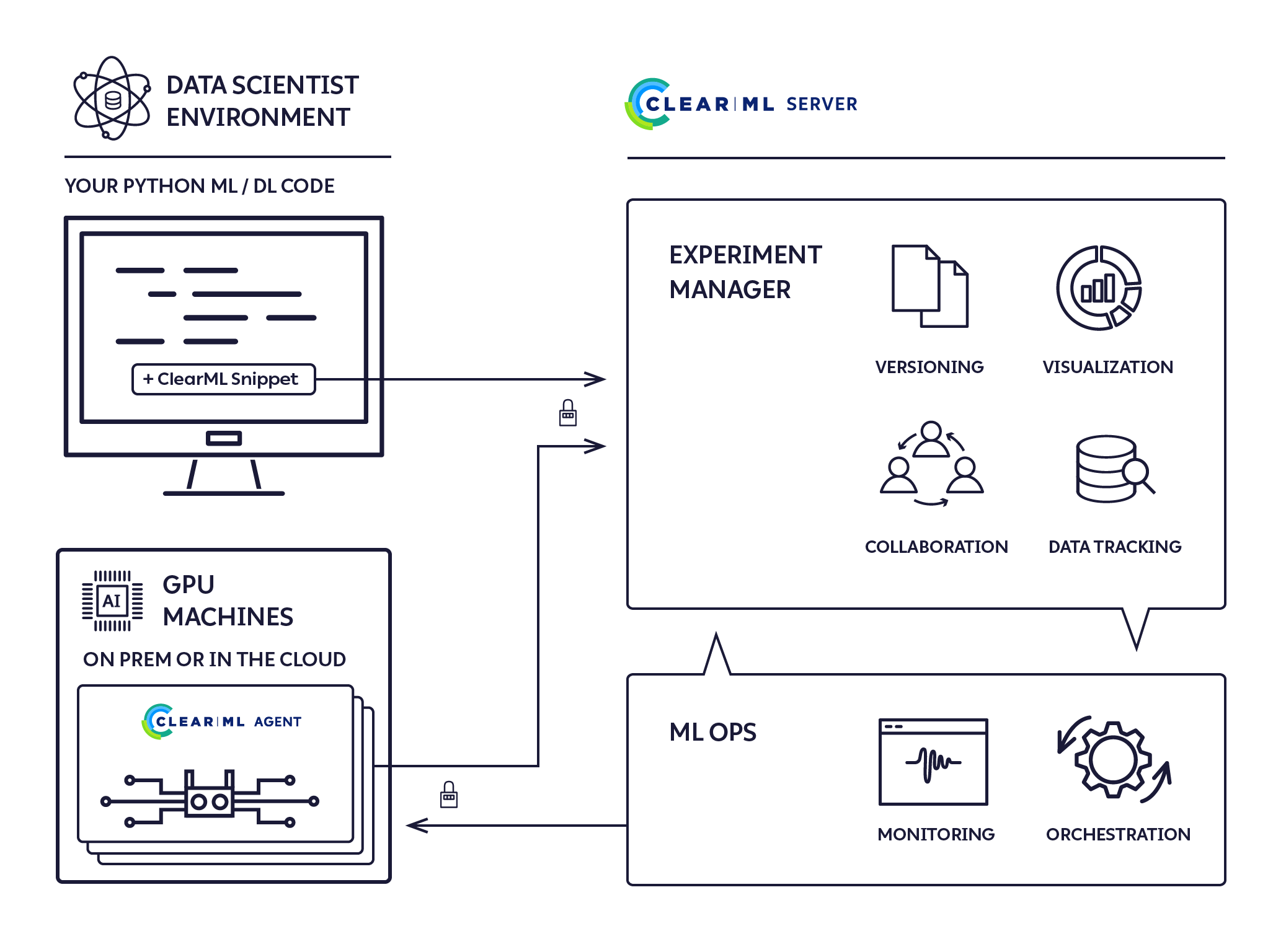
ClearML Agent - MLOps/LLMOps simplifiés
Solution de planification et d'orchestration MLOps/LLMOps prenant en charge Linux, macOS et Windows
? ClearML is open-source - Leave a star to support the project! ?
Il s'agit d'un agent d'exécution sans configuration, sans configuration, fournissant une solution de cluster ML/DL complète.
Automatisation complète en 5 étapes
pip install clearml-agent (installez l'agent ClearML sur n'importe quelle machine GPU : sur site / cloud / ...)"Tous les DevOps Deep/Machine Learning dont votre recherche a besoin, et plus encore... Parce que personne n'a le temps pour ça"
Essayez ClearML maintenant Hébergement auto-hébergé ou gratuit 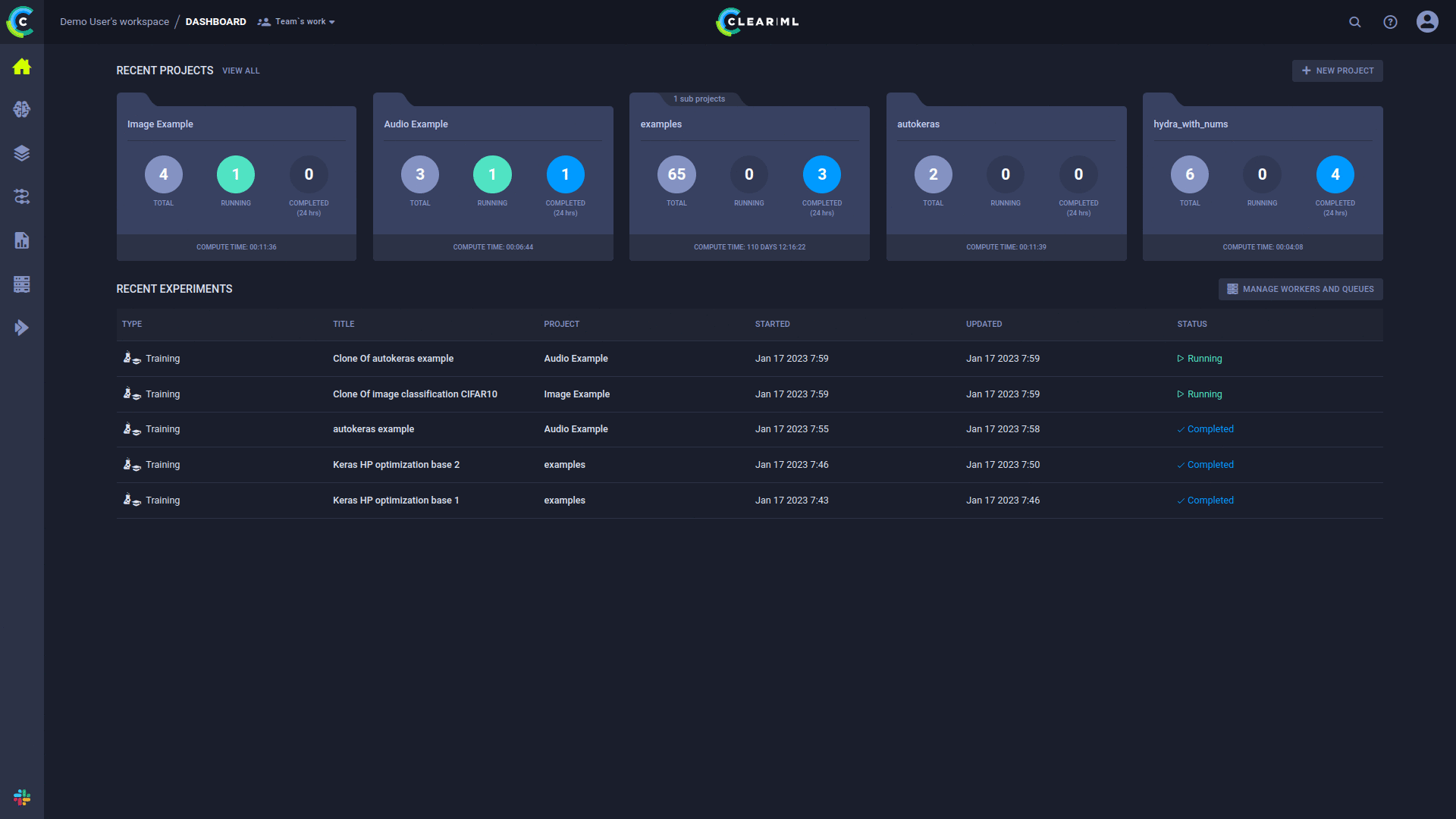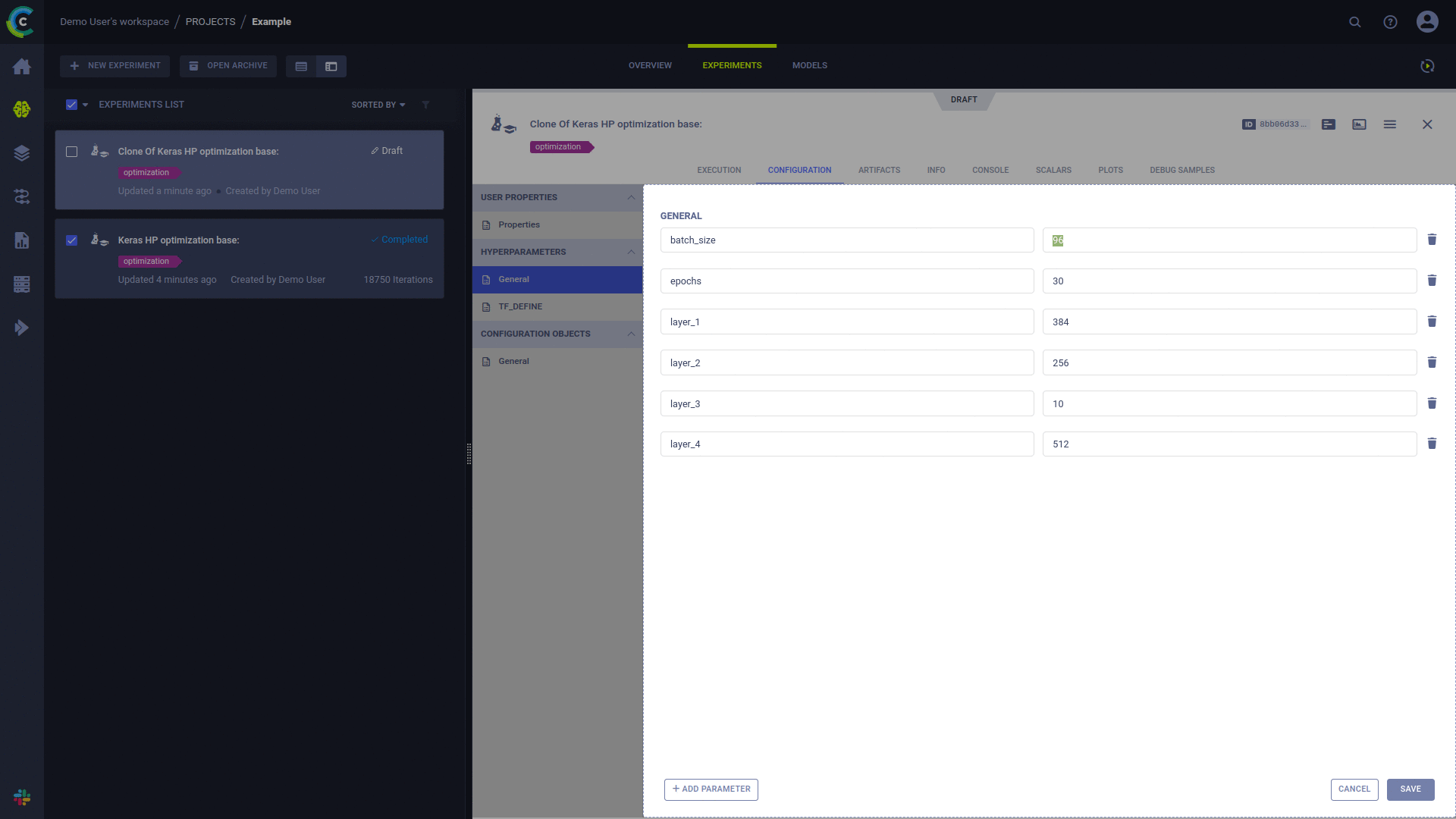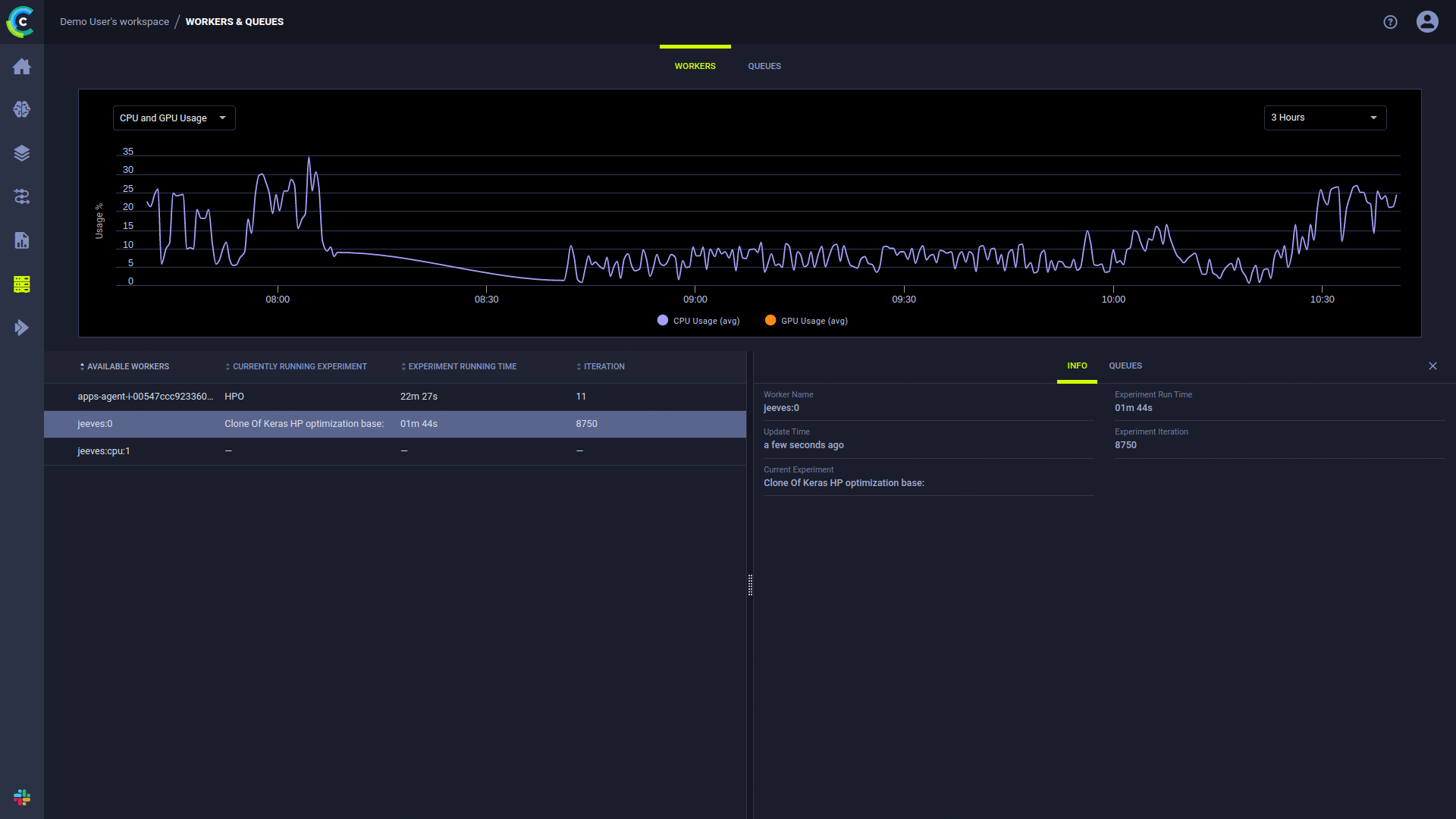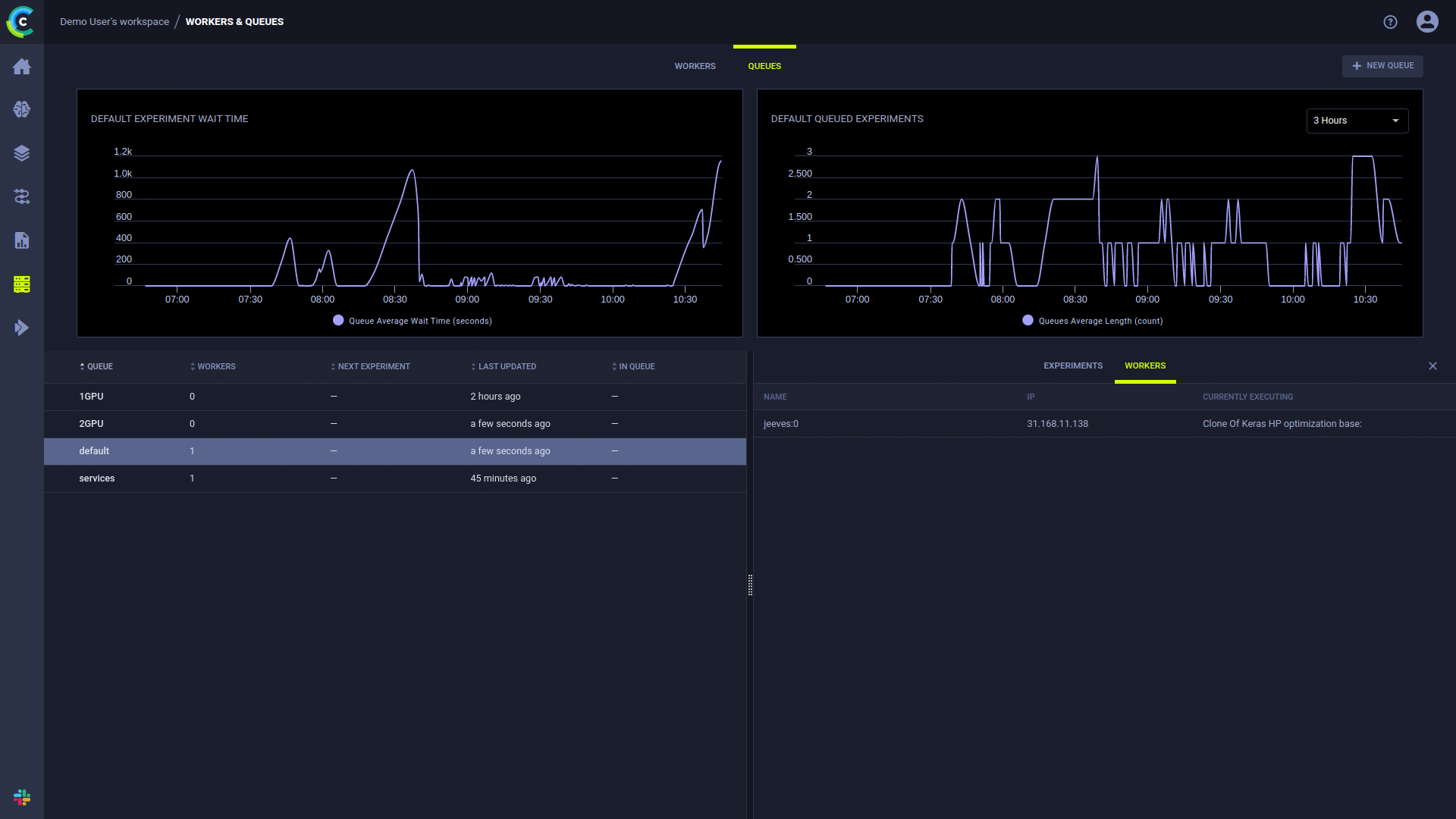
L'agent ClearML a été conçu pour répondre aux besoins DevOps R&D DL/ML :
À l'aide de l'agent ClearML, vous pouvez désormais configurer un cluster dynamique avec *epsilon DevOps
*epsilon - Parce que nous le sommes ? et rien n'est vraiment zéro travail
Nous pensons que Kubernetes est génial, mais ce n'est pas indispensable pour se lancer dans les agents d'exécution à distance et la gestion de cluster. Nous avons conçu clearml-agent pour que vous puissiez exécuter à la fois sur système nu et sur Kubernetes, dans n'importe quelle combinaison adaptée à votre environnement.
Vous pouvez trouver les fichiers Dockerfiles dans le dossier docker et le graphique helm sur https://github.com/allegroai/clearml-helm-charts
Exécutez l'agent en mode Kubernetes Glue et mappez les tâches ClearML directement aux tâches K8 :
Oui! L'intégration Slurm est disponible, consultez la documentation pour plus de détails
HPC à grande échelle en un seul clic
L'agent ClearML est un planificateur de travaux qui écoute les files d'attente de travaux, extrait les travaux, définit les environnements de travail, exécute le travail et surveille sa progression.
Toute expérience « brouillon » peut être programmée pour être exécutée par un agent ClearML.
Une expérience précédemment exécutée peut être mise à l'état « Brouillon » par l'une des deux méthodes suivantes :
L'exécution d'une expérience est planifiée à l'aide de l'action « Mettre en file d'attente » dans le menu contextuel de l'expérience en cliquant avec le bouton droit dans l'interface utilisateur ClearML et en sélectionnant la file d'attente d'exécution.
Voir créer une expérience et la mettre en file d'attente pour son exécution.
Une fois qu'une expérience est mise en file d'attente, elle sera récupérée et exécutée par un agent ClearML surveillant cette file d'attente.
La page Travailleurs et files d'attente de l'interface utilisateur ClearML fournit des informations sur l'exécution continue :
L'agent ClearML exécute des expériences en utilisant le processus suivant :
pip install clearml-agentL'interface complète et les fonctionnalités sont disponibles avec
clearml-agent --help
clearml-agent daemon --helpclearml-agent init Remarque : L'agent ClearML utilise un dossier de cache pour mettre en cache les packages pip, les packages apt et les référentiels clonés. Le dossier de cache par défaut de l'agent ClearML est ~/.clearml .
Voir tous les détails dans votre fichier de configuration à ~/clearml.conf .
Remarque : L' agent ClearML étend le fichier de configuration ClearML ~/clearml.conf . Ils sont conçus pour partager le même fichier de configuration, voir exemple ici
Pour le débogage et l'expérimentation, démarrez l'agent ClearML en mode foreground , où toutes les sorties sont imprimées à l'écran :
clearml-agent daemon --queue default --foreground Pour le mode service réel, toutes les sorties standard seront automatiquement stockées dans un fichier temporaire (pas besoin de canaliser). Remarque : avec l'indicateur --detached , l' agent clearml s'exécutera en arrière-plan
clearml-agent daemon --detached --queue default L'allocation GPU est contrôlée via l'environnement de système d'exploitation standard NVIDIA_VISIBLE_DEVICES ou l'indicateur --gpus (ou désactivée avec --cpu-only ).
Si aucun indicateur n'est défini et que la variable NVIDIA_VISIBLE_DEVICES n'existe pas, tous les GPU seront alloués au clearml-agent .
Si l'indicateur --cpu-only est défini, ou NVIDIA_VISIBLE_DEVICES="none" , aucun GPU ne sera alloué pour le clearml-agent .
Exemple : faites tourner deux agents, un par GPU sur la même machine :
Remarque : avec l'indicateur --detached , l' agent clearml s'exécutera en arrière-plan
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default Exemple : faites tourner deux agents, en les extrayant de la file d'attente dual_gpu dédiée, deux GPU par agent
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu Pour le débogage et l'expérimentation, démarrez l'agent ClearML en mode foreground , où toutes les sorties sont imprimées à l'écran.
clearml-agent daemon --queue default --docker --foreground Pour le mode service réel, toutes les sorties standard seront automatiquement stockées dans un fichier (pas besoin de canaliser). Remarque : avec l'indicateur --detached , l' agent clearml s'exécutera en arrière-plan
clearml-agent daemon --detached --queue default --docker Exemple : faites tourner deux agents, un par GPU sur la même machine, avec le docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 par défaut :
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 Exemple : faites tourner deux agents, en extrayant de la file d'attente dual_gpu dédiée, deux GPU par agent, avec le docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 par défaut :
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04Les files d'attente prioritaires sont également prises en charge, exemple de cas d'utilisation :
File d'attente haute priorité : important_jobs , file d'attente basse priorité : default
clearml-agent daemon --queue important_jobs default L' agent ClearML essaiera d'abord d'extraire les tâches de la file d' important_jobs , et seulement si elle est vide, l'agent tentera d'extraire les tâches de la file d' default .
L'ajout de files d'attente, la gestion de l'ordre des tâches dans une file d'attente et le déplacement des tâches entre les files d'attente sont disponibles à l'aide de l'interface utilisateur Web, voir l'exemple sur notre serveur gratuit.
Pour arrêter un agent ClearML exécuté en arrière-plan, exécutez la même ligne de commande utilisée pour démarrer l'agent avec --stop ajouté. Par exemple, pour arrêter la première des mêmes machines illustrées ci-dessus, des agents GPU uniques :
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stopIntégrez ClearML à votre code
Exécutez le code sur votre machine (Manuellement / PyCharm / Jupyter Notebook)
Pendant l'exécution de votre code, ClearML crée une expérience enregistrant toutes les informations d'exécution nécessaires :
Vous disposez désormais d'un « modèle » de votre expérience avec tout ce qui est requis pour une exécution automatisée.
Dans l'interface utilisateur ClearML, cliquez avec le bouton droit sur l'expérience et sélectionnez « cloner ». Une copie de votre expérience sera créée.
Vous disposez désormais d'un nouveau brouillon de test cloné à partir de votre test d'origine. N'hésitez pas à le modifier.
Planifiez l'exécution de l'expérience nouvellement créée : cliquez avec le bouton droit sur l'expérience et sélectionnez « mettre en file d'attente »
ClearML-Agent Services est un mode spécial de ClearML-Agent qui offre la possibilité de lancer des tâches de longue durée qui devaient auparavant être exécutées sur des machines locales/dédiées. Il permet à un seul agent de lancer plusieurs dockers (tâches) pour différents cas d'utilisation :
Le mode ClearML-Agent Services fera tourner toutes les tâches mises en file d'attente dans la file d'attente spécifiée. Chaque tâche lancée par ClearML-Agent Services sera enregistrée en tant que nouveau nœud dans le système, offrant des capacités de suivi et de transparence. Actuellement, clearml-agent en mode services prend en charge la configuration du processeur uniquement. Le mode services ClearML-Agent peut être lancé avec les agents GPU.
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-onlyRemarque : Il est de la responsabilité de l'utilisateur de s'assurer que les tâches appropriées sont placées dans la file d'attente spécifiée.
L'agent ClearML peut également être utilisé pour implémenter l'orchestration AutoML et les pipelines d'expérimentation en conjonction avec le package ClearML.
Des exemples d’exemples AutoML et Orchestration peuvent être trouvés dans le dossier ClearML example/automation.
Exemples AutoML :
Exemples de pipelines d'expérimentation :
Licence Apache, version 2.0 (voir la LICENCE pour plus d'informations)


