Candle est un framework ML minimaliste pour Rust axé sur les performances (y compris la prise en charge du GPU) et la facilité d'utilisation. Essayez nos démos en ligne : chuchoter, LLaMA2, T5, yolo, Segment Anything.
Assurez-vous que candle-core est correctement installé comme décrit dans Installation .
Voyons comment exécuter une simple multiplication matricielle. Écrivez ce qui suit dans votre fichier myapp/src/main.rs :
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run doit afficher un tenseur de forme Tensor[[2, 4], f32] .
Après avoir installé candle avec le support Cuda, définissez simplement l' device sur GPU :
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;Pour des exemples plus avancés, veuillez consulter la section suivante.
Ces démos en ligne s'exécutent entièrement dans votre navigateur :
Nous fournissons également quelques exemples basés sur la ligne de commande utilisant des modèles de pointe :
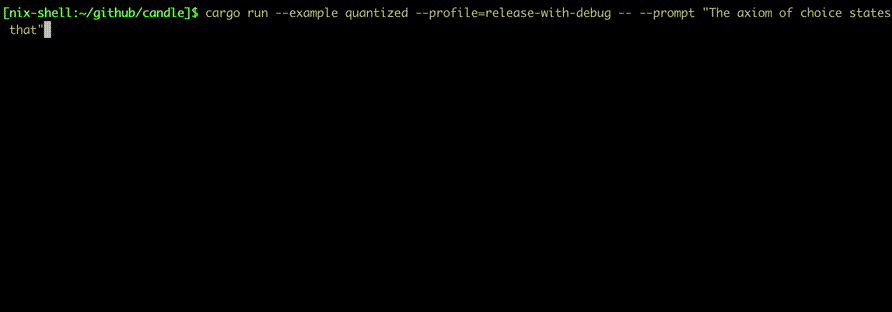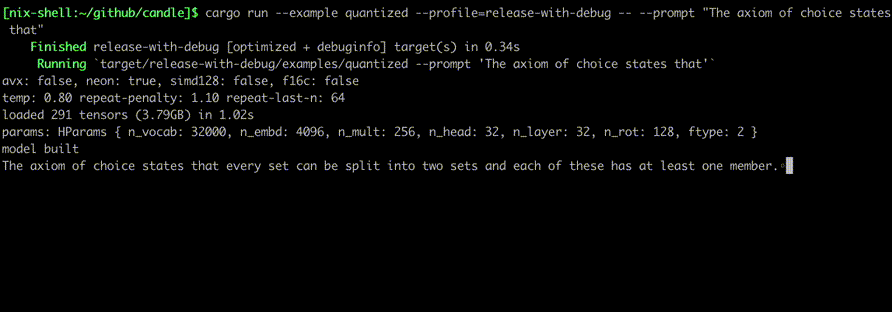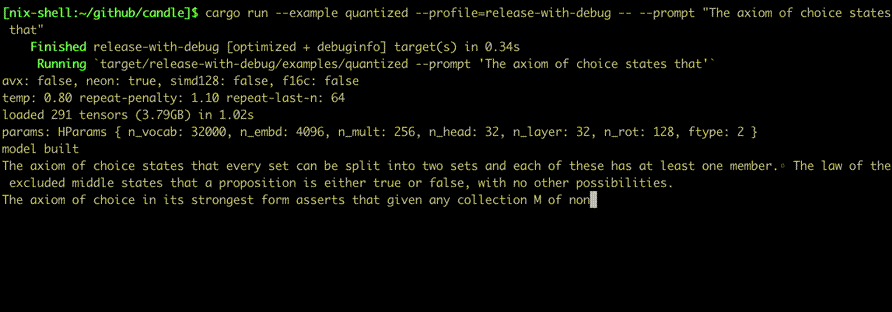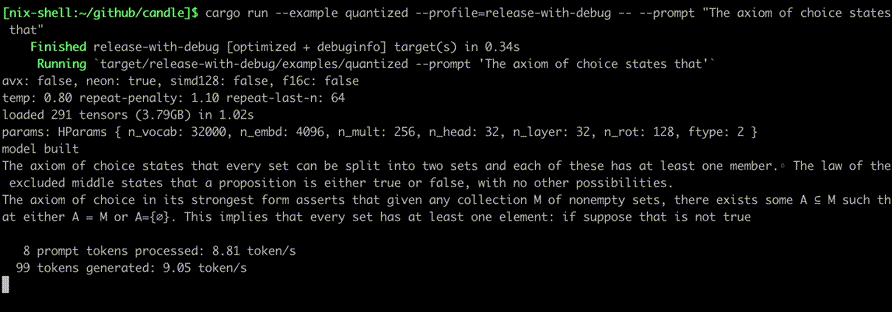





Exécutez-les à l'aide de commandes telles que :
cargo run --example quantized --release
Pour utiliser CUDA, ajoutez --features cuda à l'exemple de ligne de commande. Si cuDNN est installé, utilisez --features cudnn pour encore plus d'accélérations.
Il existe également quelques exemples de wasm pour murmure et lama2.c. Vous pouvez soit les construire avec trunk , soit les essayer en ligne : Whisper, Llama2, T5, Phi-1.5 et Phi-2, Segment Anything Model.
Pour LLaMA2, exécutez la commande suivante pour récupérer les fichiers de poids et démarrer un serveur de test :
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081Et puis rendez-vous sur http://localhost:8081/.
candle-tutorial : Un tutoriel très détaillé montrant comment convertir un modèle PyTorch en Candle.candle-lora : Implémentation LoRA efficace et ergonomique pour Candle. candle-lora aoptimisers : une collection d'optimiseurs comprenant SGD avec momentum, AdaGrad, AdaDelta, AdaMax, NAdam, RAdam et RMSprop.candle-vllm : Plateforme efficace d'inférence et de service de LLM locaux, y compris un serveur API compatible OpenAI.candle-ext : Une bibliothèque d'extensions pour Candle qui fournit des fonctions PyTorch non actuellement disponibles dans Candle.candle-coursera-ml : Implémentation d'algorithmes ML du cours de spécialisation en apprentissage automatique de Coursera.kalosm : un méta-framework multimodal dans Rust pour l'interface avec des modèles locaux pré-entraînés avec prise en charge de la génération contrôlée, des échantillonneurs personnalisés, des bases de données vectorielles en mémoire, de la transcription audio, etc.candle-sampling : Techniques d'échantillonnage pour Candle.gpt-from-scratch-rs : Un portage du didacticiel Let's build GPT d'Andrej Karpathy sur YouTube présentant l'API Candle sur un problème de jouet.candle-einops : Une implémentation pure rust de la bibliothèque python einops.atoma-infer : une bibliothèque Rust pour une inférence rapide à grande échelle, tirant parti de FlashAttention2 pour un calcul d'attention efficace, PagedAttention pour une gestion efficace de la mémoire cache KV et de la prise en charge multi-GPU. Il est compatible avec l’API OpenAI.Si vous avez un ajout à cette liste, veuillez soumettre une pull request.
Aide-mémoire :
| Utiliser PyTorch | Utiliser une bougie | |
|---|---|---|
| Création | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| Création | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| Indexage | tensor[:, :4] | tensor.i((.., ..4))? |
| Opérations | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| Opérations | a.matmul(b) | a.matmul(&b)? |
| Arithmétique | a + b | &a + &b |
| Appareil | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| Type D | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| Économie | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| Chargement | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
TensorL'objectif principal de Candle est de rendre possible l'inférence sans serveur . Les frameworks d'apprentissage automatique complets comme PyTorch sont très volumineux, ce qui ralentit la création d'instances sur un cluster. Candle permet le déploiement de binaires légers.
Deuxièmement, Candle vous permet de supprimer Python des charges de travail de production. La surcharge de Python peut sérieusement nuire aux performances, et le GIL est une source notoire de maux de tête.
Enfin, Rust est cool ! Une grande partie de l’écosystème HF dispose déjà de caisses Rust, comme des dispositifs de sécurité et des tokeniseurs.
dfdx est une formidable caisse, avec des formes incluses dans les types. Cela évite bien des maux de tête en obligeant le compilateur à se plaindre dès le départ des incompatibilités de forme. Cependant, nous avons constaté que certaines fonctionnalités nécessitent toujours des tâches nocturnes et que l'écriture de code peut être un peu intimidante pour les experts non-rouilleurs.
Nous exploitons et contribuons à d'autres caisses principales pour l'exécution, donc j'espère que les deux caisses pourront bénéficier l'une de l'autre.
burn est une caisse générale qui peut exploiter plusieurs backends afin que vous puissiez choisir le meilleur moteur pour votre charge de travail.
tch-rs Liaisons à la bibliothèque torch dans Rust. Extrêmement polyvalents, mais ils intègrent toute la bibliothèque de torches dans le runtime. Le principal contributeur de tch-rs est également impliqué dans le développement de candle .
Si vous obtenez des symboles manquants lors de la compilation de binaires/tests à l'aide des fonctionnalités mkl ou d'accélération, par exemple pour mkl, vous obtenez :
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
ou pour accélérer :
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
Cela est probablement dû à un indicateur d'éditeur de liens manquant qui était nécessaire pour activer la bibliothèque mkl. Vous pouvez essayer d'ajouter ce qui suit pour mkl en haut de votre binaire :
extern crate intel_mkl_src ;ou pour accélérer :
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
Cela est probablement dû au fait que vous n'êtes pas autorisé à utiliser le modèle LLaMA-v2. Pour résoudre ce problème, vous devez vous inscrire sur le hub huggingface, accepter les conditions du modèle LLaMA-v2 et configurer votre jeton d'authentification. Voir le numéro 350 pour plus de détails.
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
cutlass est fourni en tant que sous-module git, vous souhaiterez peut-être exécuter la commande suivante pour l'enregistrer correctement.
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
Il s'agit d'un bug dans gcc-11 déclenché par le compilateur Cuda. Pour résoudre ce problème, installez une version différente de gcc prise en charge - par exemple gcc-10, et spécifiez le chemin d'accès au compilateur dans la variable d'environnement NVCC_CCBIN.
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
Assurez-vous de lier toutes les bibliothèques natives qui pourraient être situées en dehors de la cible d'un projet. Par exemple, pour exécuter des tests mdbook, vous devez exécuter :
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
Cela peut être dû au chargement des modèles depuis /mnt/c , plus de détails sur stackoverflow.
Vous pouvez définir RUST_BACKTRACE=1 pour qu'il fournisse des traces lorsqu'une erreur de bougie est générée.
Si vous rencontrez une erreur comme celle-ci called Result::unwrap() on an value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } sous Windows. Pour corriger, copiez et renommez ces 3 fichiers (assurez-vous qu'ils sont dans le chemin). Les chemins dépendent de votre version de cuda. c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


