[Papier] [Page du projet] [Modèle miniFLUX] [Modèle SD3 ⚡️] [démo ?]
Il s'agit du référentiel officiel de Pyramid Flow, une méthode de génération vidéo autorégressive efficace basée sur Flow Matching . En s'entraînant uniquement sur des ensembles de données open source , il peut générer des vidéos de 10 secondes de haute qualité à une résolution de 768p et 24 FPS, et prend naturellement en charge la génération d'image en vidéo.
| 10 s, 768p, 24 ips | 5s, 768p, 24 images par seconde | Image vers vidéo |
|---|---|---|
feux d'artifice.mp4 | bande-annonce.mp4 | dimanche.mp4 |
2024.11.13 Nous publions le point de contrôle miniFLUX 768p (jusqu'à 10 s).
Nous avons changé la structure du modèle de SD3 à un mini FLUX pour résoudre les problèmes de structure humaine. Veuillez essayer notre point de contrôle d'image 1024p, notre point de contrôle vidéo 384p (jusqu'à 5 s) et notre point de contrôle vidéo 768p (jusqu'à 10 s). Le nouveau modèle miniflux montre une grande amélioration de la structure humaine et de la stabilité des mouvements
2024.10.29 ⚡️⚡️⚡️ Nous publions le code de formation pour la VAE, le code de mise au point pour le DiT et de nouveaux points de contrôle de modèle avec la structure FLUX formés à partir de zéro.
2024.10.13 L'inférence multi-GPU et le déchargement du processeur sont pris en charge. Utilisez-le avec moins de 8 Go de mémoire GPU, avec une grande accélération sur plusieurs GPU.
2024.10.11 ??? La démo Hugging Face est disponible. Merci @multimodalart pour le commit !
2024.10.10 Nous publions le rapport technique, la page du projet et le point de contrôle du modèle de Pyramid Flow.
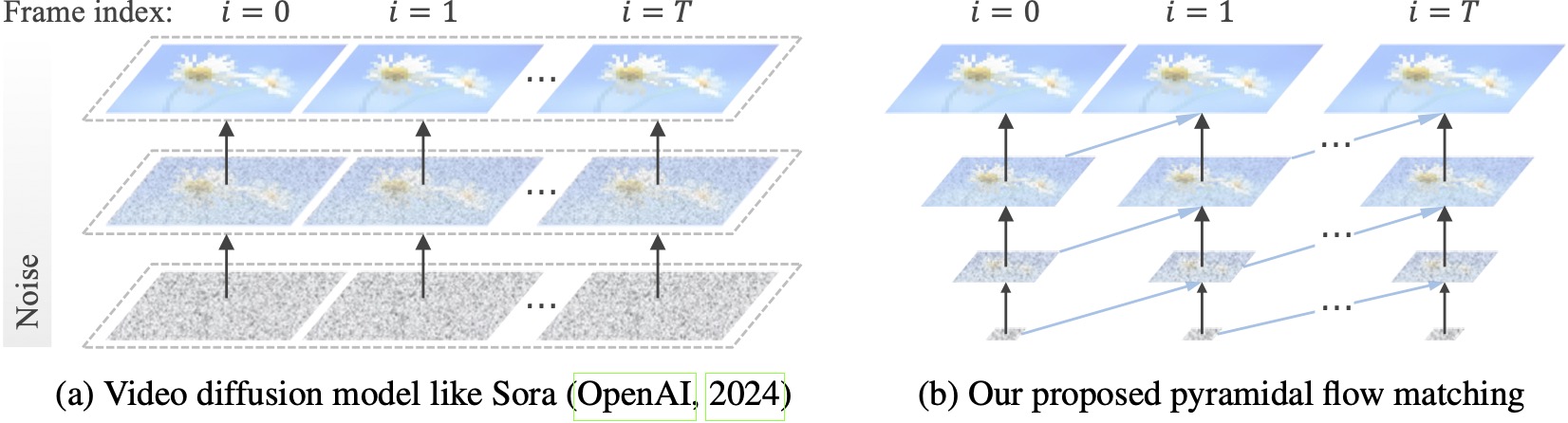
Les modèles de diffusion vidéo existants fonctionnent en pleine résolution, consacrant beaucoup de calculs à des latents très bruitées. En revanche, notre méthode exploite la flexibilité de l'appariement de flux (Lipman et al., 2023 ; Liu et al., 2023 ; Albergo & Vanden-Eijnden, 2023) pour interpoler entre des latents de différentes résolutions et niveaux de bruit, permettant ainsi la génération et la génération simultanées de flux. décompression du contenu visuel avec une meilleure efficacité informatique. L'ensemble du framework est optimisé de bout en bout avec un seul DiT (Peebles & Xie, 2023), générant des vidéos de 10 secondes de haute qualité à une résolution de 768p et 24 FPS en 20,7 000 heures de formation sur le GPU A100.
Nous vous recommandons de configurer l'environnement avec conda. La base de code utilise actuellement Python 3.8.10 et PyTorch 2.1.2 (guide), et nous travaillons activement pour prendre en charge une plus large gamme de versions.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtEnsuite, téléchargez le modèle depuis Huggingface (il existe deux variantes : miniFLUX ou SD3). Les modèles miniFLUX prennent en charge la génération d'images 1024p, 384p et 768p, et les modèles basés sur SD3 prennent en charge la génération vidéo 768p et 384p. Le point de contrôle 384p génère une vidéo de 5 secondes à 24 FPS, tandis que le point de contrôle 768p génère jusqu'à 10 secondes de vidéo à 24 FPS.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )Pour commencer, installez d'abord Gradio, définissez le chemin de votre modèle sur #L36, puis exécutez sur votre ordinateur local :
python app.pyLa démo Gradio sera ouverte dans un navigateur. Merci à @tpc2233 le commit, voir #48 pour plus de détails.
Ou essayez-le sans effort sur Hugging Face Space ? créé par @multimodalart. En raison des limites du GPU, cette démo en ligne ne peut générer que 25 images (exportation à 8FPS ou 24FPS). Dupliquez l'espace pour générer des vidéos plus longues.
Pour essayer rapidement Pyramid Flow sur Google Colab, exécutez le code ci-dessous :
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
Pour utiliser notre modèle, veuillez suivre le code d'inférence dans video_generation_demo.ipynb sur ce lien. Nous vous recommandons fortement d'essayer le dernier miniflux pyramidal publié, qui montre une grande amélioration de la structure humaine et de la stabilité des mouvements. Définissez le paramètre model_name sur pyramid_flux à utiliser. Nous le simplifions davantage dans la procédure suivante en deux étapes. Tout d'abord, chargez le modèle téléchargé :
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()Ensuite, vous pouvez essayer la génération texte-vidéo selon vos propres invites. A noter que la version 384p ne prend désormais en charge que 5 secondes (réglez la température jusqu'à 16) !
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )En tant que modèle autorégressif, notre modèle prend également en charge la génération d'image en vidéo (conditionnée par le texte) :
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )Nous prenons également en charge deux types de déchargement du processeur pour réduire les besoins en mémoire du GPU. Notez qu’ils peuvent sacrifier l’efficacité.
cpu_offloading=True à la fonction de génération permet une inférence avec moins de 12 Go de mémoire GPU. Cette fonctionnalité a été contribuée par @Ednaordinary, voir #23 pour plus de détails.model.enable_sequential_cpu_offload() avant la procédure ci-dessus permet l'inférence avec moins de 8 Go de mémoire GPU. Cette fonctionnalité a été contribuée par @rodjjo, voir #75 pour plus de détails. Grâce à @niw, les utilisateurs d'Apple Silicon (par exemple MacBook Pro avec M2 24 Go) peuvent également essayer notre modèle en utilisant le backend MPS ! Veuillez consulter le numéro 113 pour les détails.
Pour les utilisateurs disposant de plusieurs GPU, nous fournissons un script d'inférence qui utilise le parallélisme de séquence pour économiser de la mémoire sur chaque GPU. Cela apporte également une grande accélération, ne prenant que 2,5 minutes pour générer une vidéo 5s, 768p, 24 ips sur 4 GPU A100 (contre 5,5 minutes sur un seul GPU A100). Exécutez-le sur 2 GPU avec la commande suivante :
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.shIl prend actuellement en charge 2 ou 4 GPU (pour la version SD3), avec plus de configurations disponibles dans le script d'origine. Vous pouvez également lancer une démo Gradio multi-GPU créée par @tpc2233, voir #59 pour plus de détails.
Spoiler : Nous n'avons même pas utilisé le parallélisme de séquence dans la formation, grâce à nos conceptions efficaces de flux pyramidaux.
guidance_scale contrôle la qualité visuelle. Nous suggérons d'utiliser les conseils de [7, 9] pour le point de contrôle 768p lors de la génération texte-vidéo, et 7 pour le point de contrôle 384p.video_guidance_scale contrôle le mouvement. Une valeur plus élevée augmente le degré de dynamique et atténue la dégradation de la génération autorégressive, tandis qu'une valeur plus petite stabilise la vidéo.La configuration matérielle requise pour la formation VAE est d’au moins 8 GPU A100. Veuillez vous référer à ce document. Il s'agit d'un VAE 3D continu de type MAGVIT-v2, qui devrait être assez flexible. N'hésitez pas à construire votre propre modèle génératif vidéo sur cette partie du code de formation VAE.
La configuration matérielle requise pour le réglage fin de DiT est d'au moins 8 GPU A100. Veuillez vous référer à ce document. Nous fournissons des instructions pour les versions autorégressives et non autorégressives de Pyramid Flow. Le premier est plus orienté vers la recherche et le second est plus stable (mais moins efficace sans pyramide temporelle).
Les exemples vidéo suivants sont générés à 5 s, 768p, 24 ips. Pour plus de résultats, veuillez visiter notre page de projet.
tokyo.mp4 | eiffel.mp4 |
vagues.mp4 | rail.mp4 |
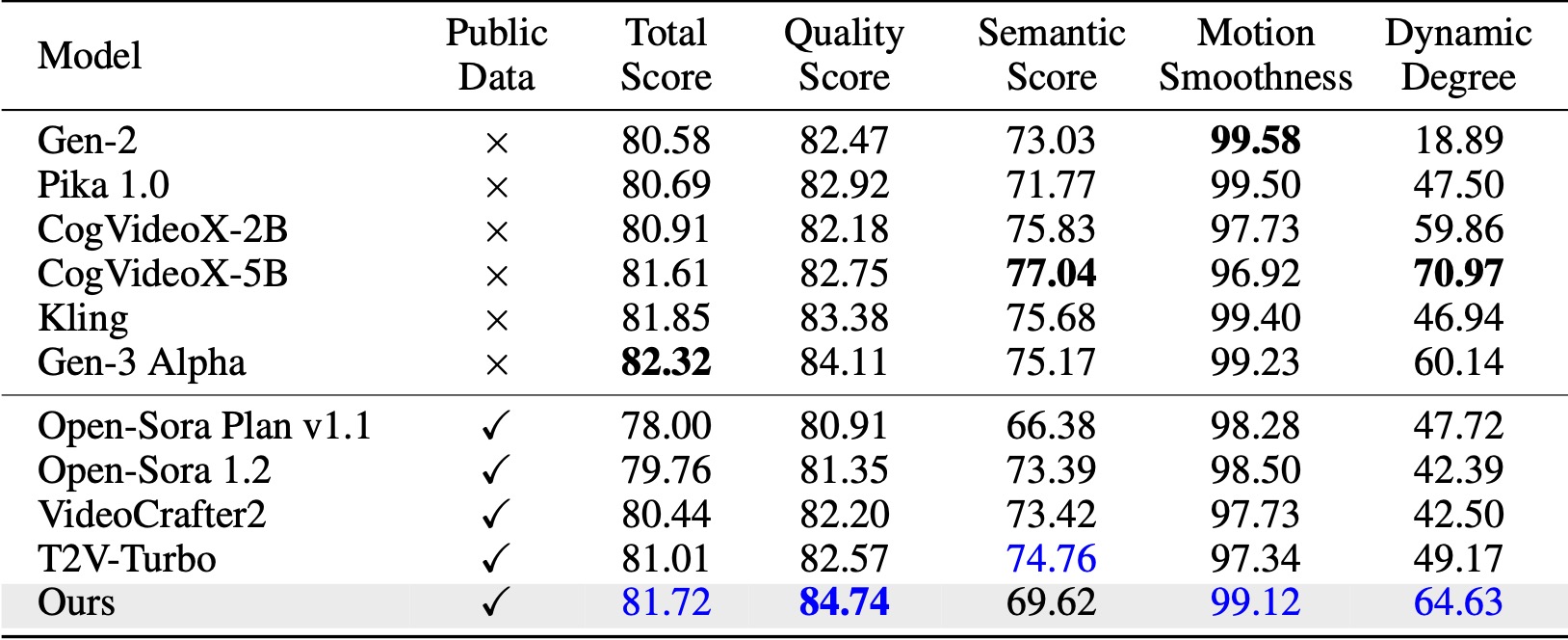
Sur VBench (Huang et al., 2024), notre méthode surpasse toutes les références open source comparées. Même avec uniquement des données vidéo publiques, il atteint des performances comparables à celles des modèles commerciaux comme Kling (Kuaishou, 2024) et Gen-3 Alpha (Runway, 2024), notamment en termes de score de qualité (84,74 contre 84,11 pour Gen-3) et de fluidité des mouvements. .
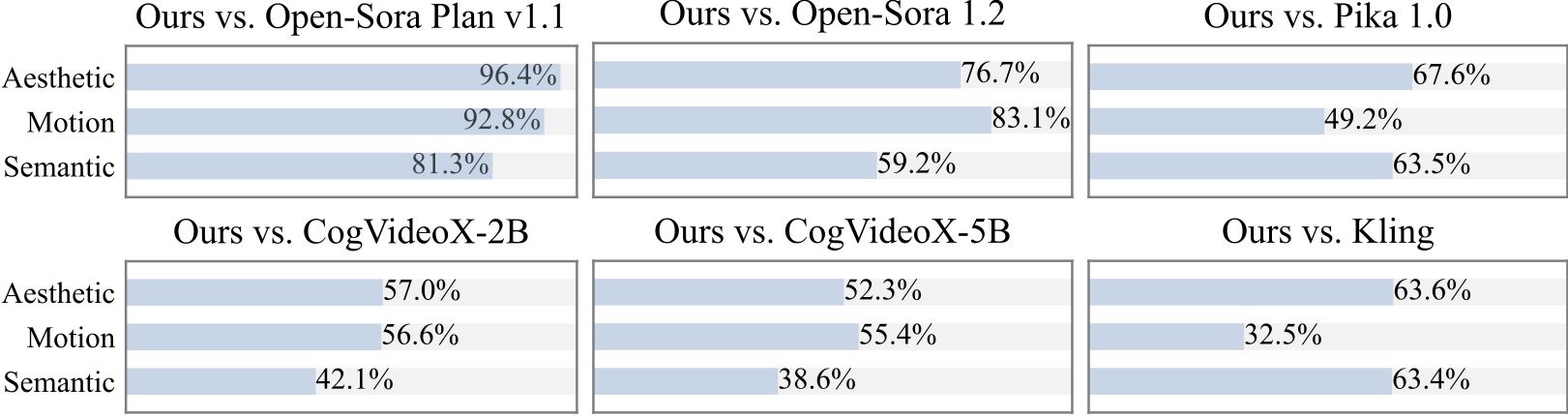
Nous menons une étude utilisateur supplémentaire avec plus de 20 participants. Comme on peut le constater, notre méthode est préférée aux modèles open source tels que Open-Sora et CogVideoX-2B, notamment en termes de fluidité des mouvements.
Nous sommes reconnaissants pour les projets impressionnants suivants lors de la mise en œuvre de Pyramid Flow :
Pensez à donner une étoile à ce référentiel et citez Pyramid Flow dans vos publications si cela aide vos recherches.
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


