nim anywhere
1.0.0

Veuillez rejoindre la chaîne Slack #cdd-nim-anywhere si vous êtes un utilisateur interne, ouvrez un problème si vous êtes externe pour toute question et commentaire.
L'un des principaux avantages de l'utilisation de l'IA pour les entreprises est leur capacité à travailler avec leurs données internes et à en tirer des enseignements. La génération de récupération augmentée (RAG) est l'un des meilleurs moyens d'y parvenir. NVIDIA a développé un ensemble de micro-services appelés micro-services NIM pour aider nos partenaires et clients à créer facilement un pipeline RAG efficace.
NIM Anywhere contient tous les outils nécessaires pour commencer à intégrer des NIM pour RAG. Il s'adapte de manière native aux laboratoires de taille réelle et aux environnements de production. C'est une excellente nouvelle pour créer une architecture RAG et ajouter facilement des NIM selon vos besoins. Si vous n'êtes pas familier avec RAG, il récupère dynamiquement les informations externes pertinentes lors de l'inférence sans modifier le modèle lui-même. Imaginez que vous êtes le responsable technique d'une entreprise disposant d'une base de données locale contenant des informations confidentielles et à jour. Vous ne voulez pas qu'OpenAI accède à vos données, mais vous avez besoin du modèle pour les comprendre afin de répondre avec précision aux questions. La solution consiste à connecter votre modèle de langage à la base de données et à les alimenter avec les informations.
Pour en savoir plus sur les raisons pour lesquelles RAG est une excellente solution pour améliorer la précision et la fiabilité de vos modèles d'IA génératifs, lisez ce blog.
Commencez dès maintenant avec NIM Anywhere grâce aux instructions de démarrage rapide et créez votre première application RAG à l'aide de NIM !
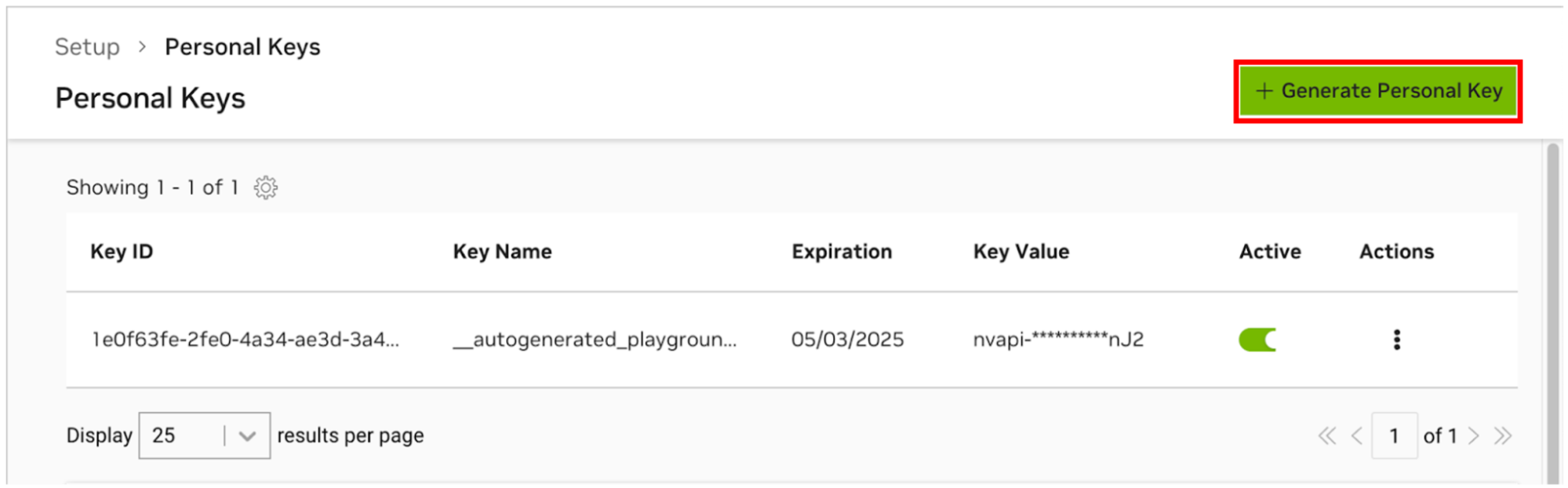
Pour permettre à AI Workbench d'accéder aux ressources cloud de NVIDIA, vous devrez lui fournir une clé personnelle. Ces clés commencent par nvapi- .
Accédez au gestionnaire de clés personnelles NGC. Si vous y êtes invité, créez un nouveau compte et connectez-vous.
CONSEIL Vous pouvez trouver cet outil en vous connectant à ngc.nvidia.com, en développant le menu de votre profil en haut à droite, en sélectionnant Configuration , puis en sélectionnant Générer une clé personnelle .
Sélectionnez Générer une clé personnelle .
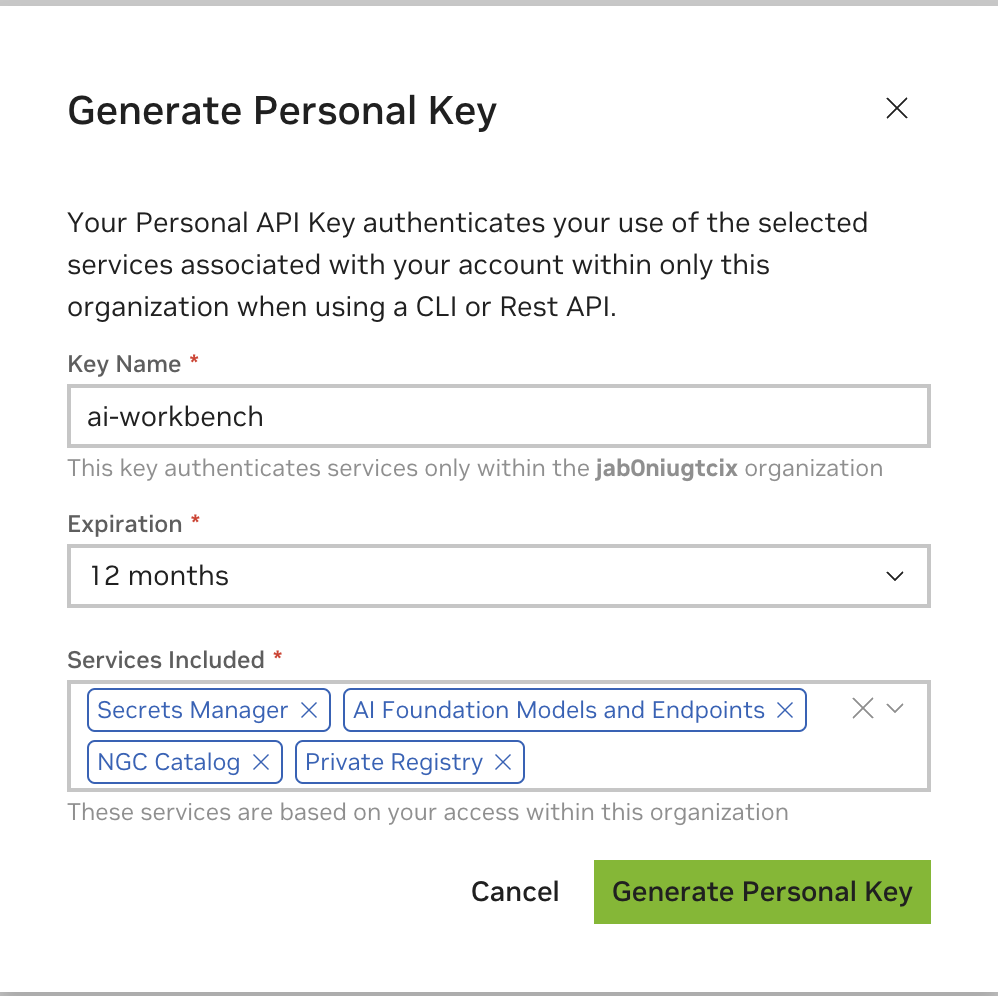
Entrez n'importe quelle valeur comme nom de clé, une expiration de 12 mois convient et sélectionnez tous les services. Appuyez sur Générer une clé personnelle lorsque vous avez terminé.
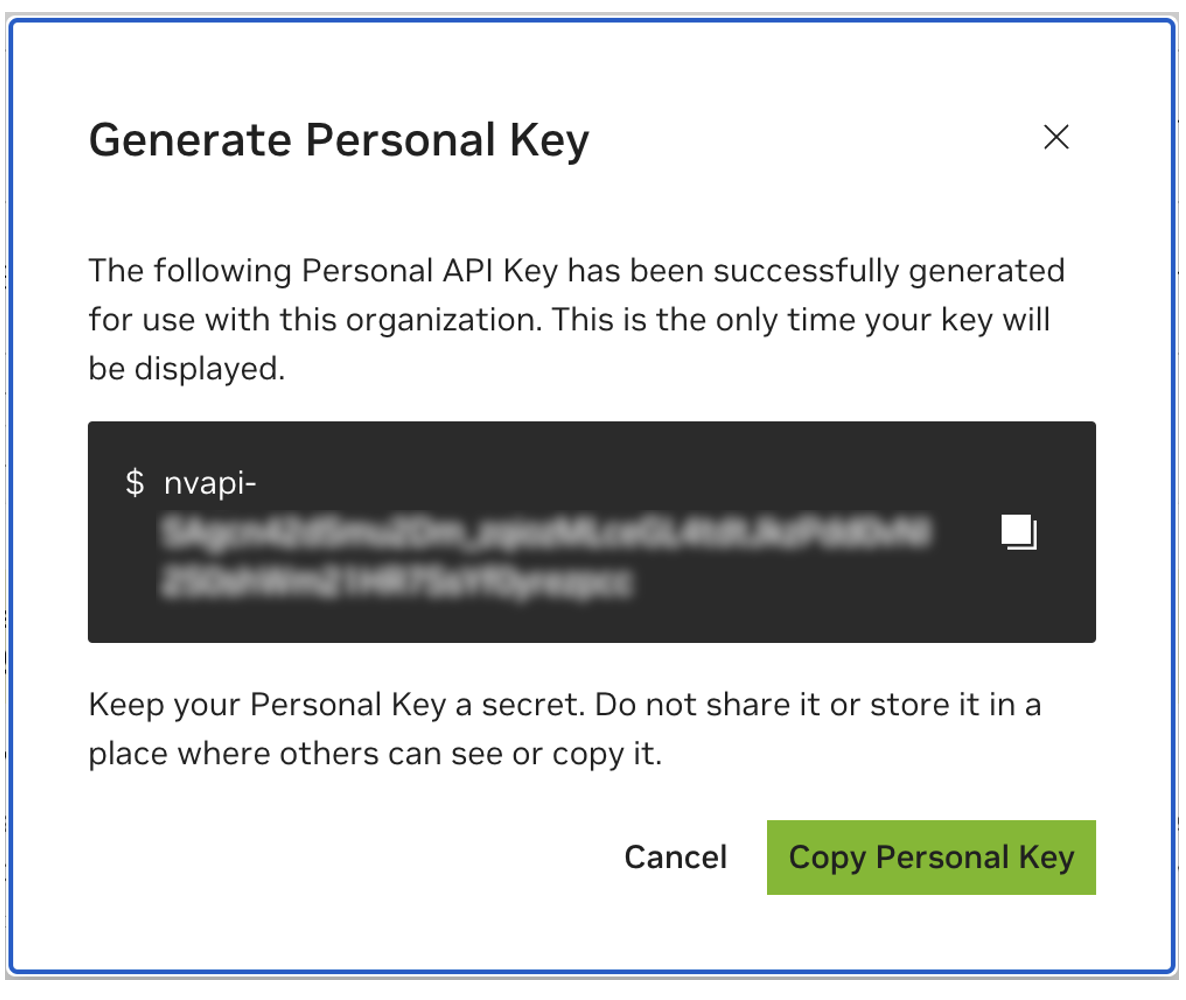
Enregistrez votre clé personnelle pour plus tard. Workbench en aura besoin et il n'y a aucun moyen de le récupérer plus tard. Si la clé est perdue, une nouvelle doit être créée. Protégez cette clé comme s'il s'agissait d'un mot de passe.
Ce projet est conçu pour être utilisé avec NVIDIA AI Workbench. Bien que ce ne soit pas une exigence, l'exécution de cette démo sans AI Workbench nécessitera un travail manuel car l'automatisation et les intégrations préconfigurées peuvent ne pas être disponibles.
Ce guide de démarrage rapide suppose qu'une machine de laboratoire distante est utilisée pour le développement et que la machine locale est un client léger permettant d'accéder à distance à la machine de développement. Cela permet aux ressources de calcul de rester centralisées et aux développeurs d'être plus portables. Notez que la machine du laboratoire distant doit exécuter Ubuntu, mais le client local peut exécuter Windows, MacOS ou Ubuntu. Pour installer ce projet localement uniquement, ignorez simplement l’installation à distance.
organigramme LR
locale
environnement de laboratoire de sous-graphes
machine-de-laboratoire-à-distance
fin
local <-.ssh.-> machine-de-laboratoire distante
Ubuntu est requis si le client local est également utilisé pour le développement. Lorsque vous utilisez un ordinateur de laboratoire distant, il peut s'agir de Windows, MacOS ou Ubuntu.
Pour des instructions complètes, consultez le Guide de l'utilisateur de NVIDIA AI Workbench.
Installer le logiciel prérequis
Téléchargez le programme d'installation de NVIDIA AI Workbench et exécutez-le. Autorisez Windows à permettre au programme d'installation d'apporter des modifications.
Suivez les instructions de l'assistant d'installation. Si vous devez installer WSL2, autorisez Windows à apporter les modifications et redémarrez la machine locale lorsque cela est demandé. Lorsque le système redémarre, le programme d'installation de NVIDIA AI Workbench devrait automatiquement reprendre.
Sélectionnez Docker comme environnement d'exécution de votre conteneur.
Connectez-vous à votre compte GitHub en utilisant l'option Se connecter via GitHub.com .
Entrez les informations de votre auteur git si demandé.
Pour obtenir des instructions complètes, consultez le Guide de l'utilisateur de NVIDIA AI Workbench.
Installer le logiciel prérequis
Téléchargez l'image disque NVIDIA AI Workbench (fichier .dmg ) et ouvrez-la.
Faites glisser AI Workbench dans le dossier Applications et exécutez NVIDIA AI Workbench à partir du lanceur d'applications. 
Sélectionnez Docker comme environnement d'exécution de votre conteneur.
Connectez-vous à votre compte GitHub en utilisant l'option Se connecter via GitHub.com .
Entrez les informations de votre auteur git si demandé.
Pour des instructions complètes, consultez le Guide de l'utilisateur de NVIDIA AI Workbench. Exécutez cette installation en tant qu'utilisateur qui sera l'utilisateur Workbench. N'exécutez pas ces étapes en tant que root .
Installer le logiciel prérequis
Téléchargez le programme d'installation de NVIDIA AI Workbench, rendez-le exécutable, puis exécutez-le. Vous pouvez rendre le fichier exécutable avec la commande suivante :
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench installera les pilotes NVIDIA pour vous (si nécessaire). Vous devrez redémarrer votre ordinateur local une fois les pilotes installés, puis redémarrer l'installation d'AI Workbench en double-cliquant sur l'icône NVIDIA AI Workbench sur votre bureau.
Sélectionnez Docker comme environnement d'exécution de votre conteneur.
Connectez-vous à votre compte GitHub en utilisant l'option Se connecter via GitHub.com .
Entrez les informations de votre auteur git si demandé.
Seul Ubuntu est pris en charge pour les machines distantes.
Pour obtenir des instructions complètes, consultez le Guide de l'utilisateur de NVIDIA AI Workbench. Exécutez cette installation en tant qu'utilisateur qui utilisera Workbench. N'exécutez pas ces étapes en tant que root .
Assurez-vous que l'authentification basée sur la clé SSH est activée de la machine locale vers la machine distante. Si cela n'est pas actuellement activé, les commandes suivantes permettront cela dans la plupart des situations. Modifiez REMOTE_USER et REMOTE-MACHINE pour refléter votre adresse distante.
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINEConnectez-vous en SSH à l'hôte distant. Ensuite, utilisez les commandes suivantes pour télécharger et exécuter le programme d'installation de NVIDIA AI Workbench.
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench installera les pilotes NVIDIA pour vous (si nécessaire). Vous devrez redémarrer votre ordinateur distant une fois les pilotes installés, puis redémarrer l'installation d'AI Workbench en réexécutant les commandes de l'étape précédente.
Sélectionnez Docker comme environnement d'exécution de votre conteneur.
Connectez-vous à votre compte GitHub en utilisant l'option Se connecter via GitHub.com .
Entrez les informations de votre auteur git si demandé.
Une fois l'installation à distance terminée, l'emplacement distant peut être ajouté à l'instance locale d'AI Workbench. Ouvrez l'application AI Workbench, cliquez sur Ajouter un emplacement distant , puis saisissez les informations requises. Une fois terminé, cliquez sur Ajouter un emplacement .
REMOTE-MACHINE .REMOTE_USER ./home/USER/.ssh/id_rsa .Il existe deux manières de télécharger ce projet pour une utilisation locale : le clonage et le forking.
Le clonage de ce référentiel est la méthode recommandée pour commencer. Cela ne permettra pas de modifications locales, mais c'est le plus rapide pour démarrer. Cela permet également d’obtenir le moyen le plus simple d’extraire les mises à jour.
Il est recommandé de créer un fork sur ce référentiel pour le développement, car les modifications pourront être enregistrées. Cependant, pour obtenir des mises à jour, le responsable du fork devra régulièrement extraire le dépôt en amont. Pour travailler à partir d'un fork, suivez les instructions de GitHub, puis référencez l'URL de votre fork personnel dans le reste de cette section.
Ouvrez la fenêtre NVIDIA AI Workbench locale. Dans la liste des emplacements affichés, sélectionnez soit celui distant que vous venez de configurer, soit local si vous comptez travailler localement.
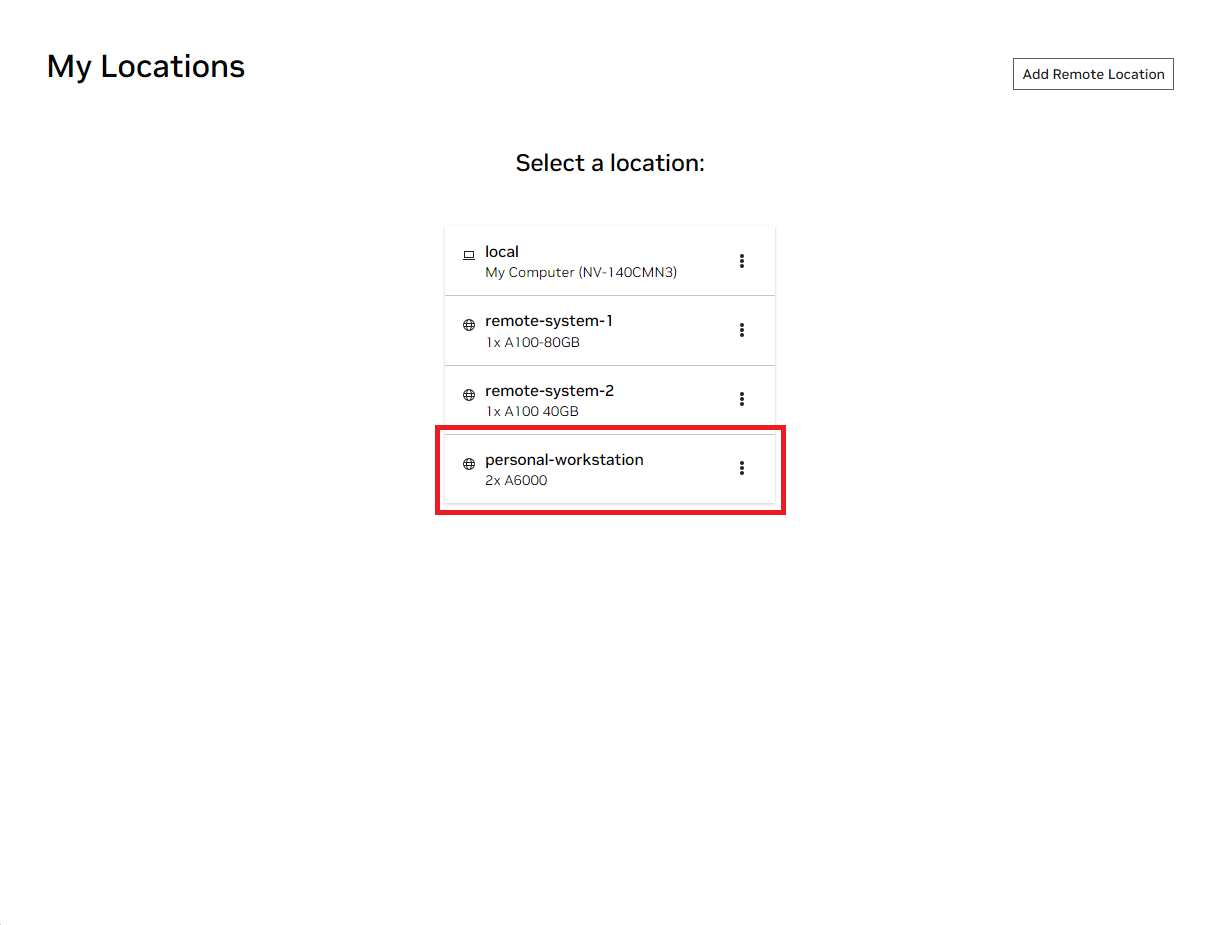
Une fois à l’intérieur de l’emplacement, sélectionnez Clone Project .
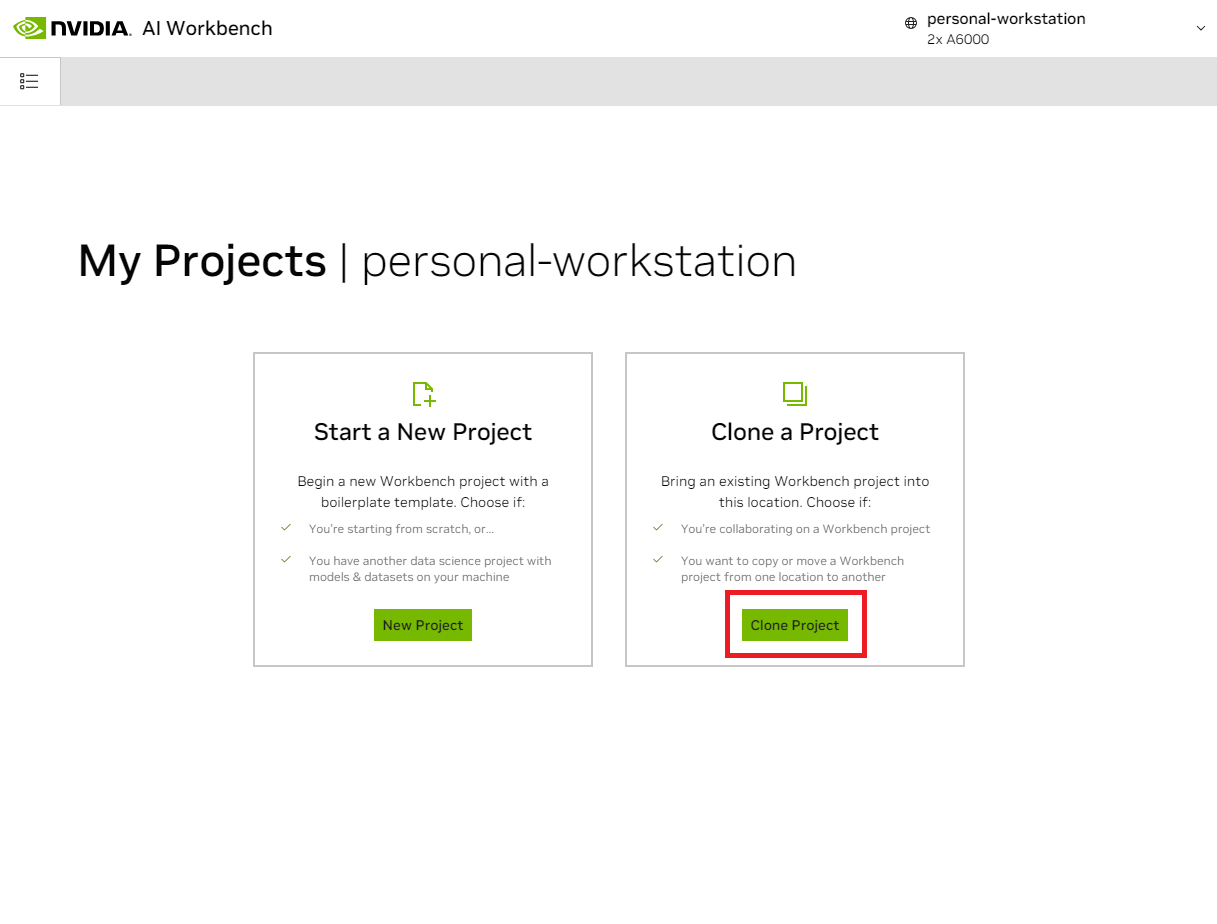
Dans la fenêtre contextuelle « Clone Project », définissez l'URL du référentiel sur https://github.com/NVIDIA/nim-anywhere.git . Vous pouvez laisser le chemin par défaut /home/REMOTE_USER/nvidia-workbench/nim-anywhere.git . Cliquez sur Cloner .`
Vous serez redirigé vers la page du nouveau projet. Workbench démarrera automatiquement l'environnement de développement. Vous pouvez visualiser la progression en temps réel en développant la sortie en bas de la fenêtre.
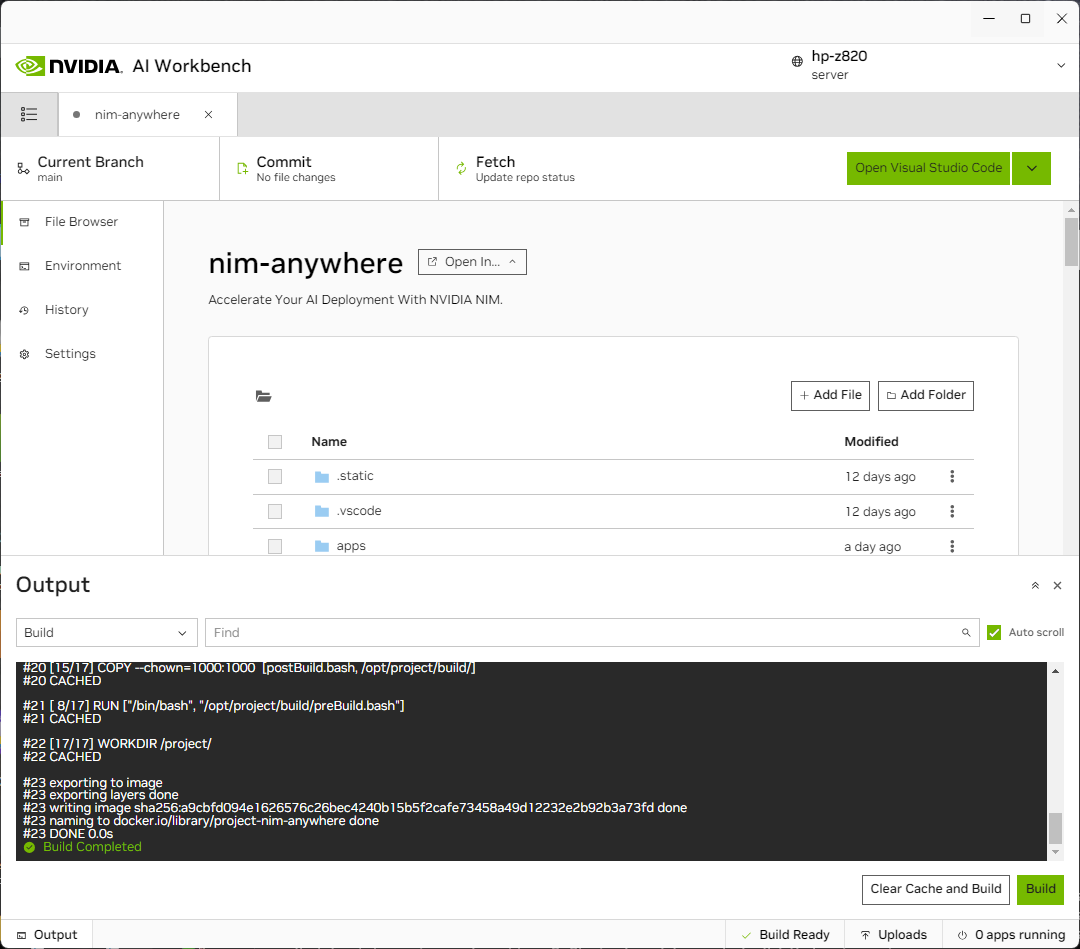
Le projet doit être configuré pour fonctionner avec les ressources de la machine locale.
Avant la première exécution, une configuration spécifique au projet doit être fournie. La configuration du projet s'effectue à l'aide de l'onglet Environnement du panneau de gauche.
Faites défiler jusqu'à la section Variables et recherchez l'entrée NGC_HOME . Il doit être défini sur quelque chose comme ~/.cache/nvidia-nims . La valeur ici est utilisée par Workbench. Ce même emplacement apparaît également dans la section Mounts qui monte ce répertoire dans le conteneur.
Faites défiler jusqu'à la section Secrets et recherchez l'entrée NGC_API_KEY . Appuyez sur Configurer et fournissez la clé personnelle pour NGC telle que générée précédemment.
Faites défiler jusqu'à la section Montures . Ici, il y a deux montures à configurer.
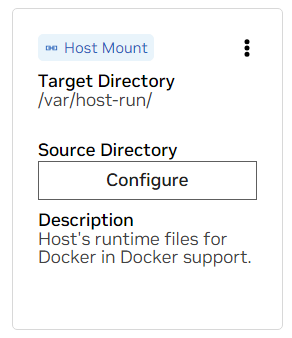
un. Recherchez le support pour /var/host-run. Ceci est utilisé pour permettre à l'environnement de développement d'accéder au démon Docker de l'hôte dans un modèle appelé Docker hors de Docker. Appuyez sur Configurer et fournissez le répertoire /var/run .
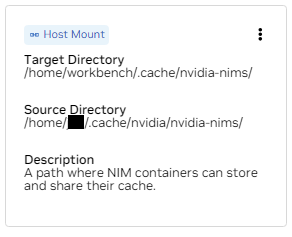
b. Recherchez le support pour /home/workbench/.cache/nvidia-nims. Ce montage est utilisé comme cache d'exécution pour les NIM où ils peuvent mettre en cache les fichiers de modèle. Le partage de ce cache avec l'hôte réduit l'utilisation du disque et la bande passante du réseau.
Si vous ne disposez pas déjà d'un cache nim ou si vous n'êtes pas sûr, utilisez les commandes suivantes pour en créer un dans /home/USER/.cache/nvidia-nims .
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nimsUne reconstruction aura lieu après la modification de ces paramètres.
Une fois la construction terminée avec un message Build Ready , toutes les applications seront mises à votre disposition.
Même les chaînes LLM les plus basiques dépendent de quelques microservices supplémentaires. Celles-ci peuvent être ignorées lors du développement d’alternatives en mémoire, mais des modifications du code sont alors nécessaires pour passer en production. Heureusement, Workbench gère ces microservices supplémentaires pour les environnements de développement.
CONSEIL : Pour chaque application, la sortie de débogage peut être surveillée dans l'interface utilisateur en cliquant sur le lien Sortie dans le coin inférieur gauche, en sélectionnant le menu déroulant et en choisissant l'application qui vous intéresse.
Toutes les applications regroupées dans cet espace de travail peuvent être contrôlées en accédant à Environment > Applications .
Tout d’abord, activez Milvus Vector DB et Redis . Milvus est utilisé comme base de connaissances non structurée et Redis est utilisé pour stocker les historiques de conversations.
Une fois ces services démarrés, le Chain Server peut être démarré en toute sécurité. Celui-ci contient le code LangChain personnalisé pour exécuter notre chaîne de raisonnement. Par défaut, il utilisera Milvus et Redis locaux, mais utilisera ai.nvidia.com pour l'inférence de modèle LLM et Embedding.
[FACULTATIF] : Ensuite, démarrez le LLM NIM . Au premier démarrage du LLM NIM, le téléchargement de l'image et des modèles optimisés prendra un certain temps.
un. Lors d'un démarrage long, pour confirmer le démarrage du LLM NIM, la progression peut être observée en affichant les journaux à l'aide du volet Sortie en bas à gauche de l'interface utilisateur.
b. Si les journaux indiquent une erreur d'authentification, cela signifie que le NGC_API_KEY fourni n'a pas accès aux NIM. Veuillez vérifier qu'il a été généré correctement et dans une organisation NGC bénéficiant du support ou d'un essai de NVIDIA AI Enterprise.
c. Si les journaux semblent bloqués sur ..........: Pull complete . ..........: Verifying complete , ou ..........: Download complete ; tout cela est une sortie normale de Docker indiquant que les différentes couches de l'image du conteneur ont été téléchargées.
d. Tout autre échec ici doit être résolu.
Une fois le Chain Server opérationnel, l’ interface de discussion peut être démarrée. Le démarrage de l'interface l'ouvrira automatiquement dans une fenêtre de navigateur.
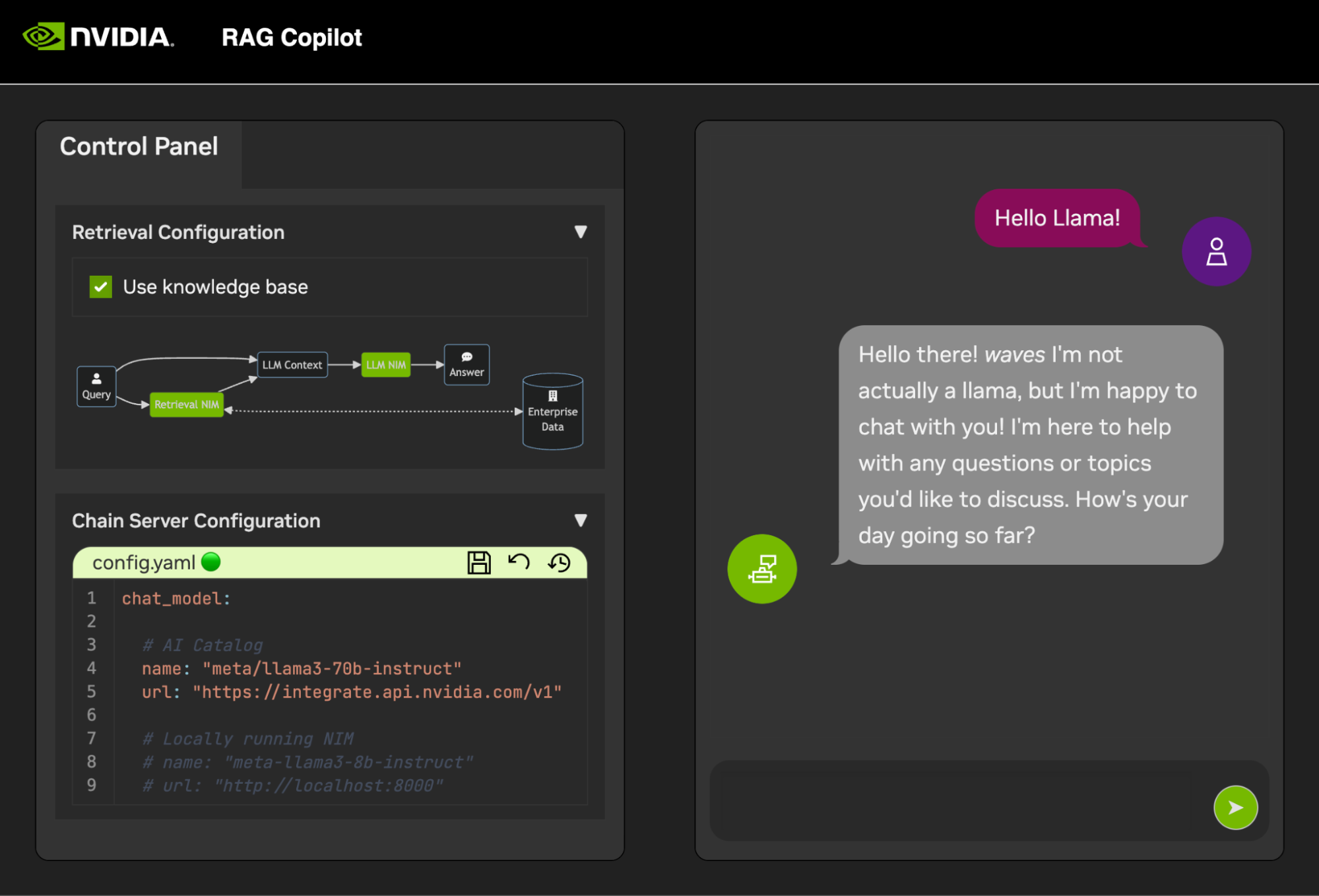
Pour commencer à développer des démos, un exemple d'ensemble de données est fourni avec un bloc-notes Jupyter montrant comment les données sont ingérées dans une base de données vectorielle.
Pour importer de la documentation PDF dans la base de données vectorielle, ouvrez Jupyter à l'aide du lanceur d'applications dans AI Workbench.
Utilisez le Jupyter Notebook sur code/upload-pdfs.ipynb pour ingérer l'ensemble de données par défaut. Si vous utilisez l’ensemble de données par défaut, aucune modification n’est nécessaire.
Si vous utilisez un ensemble de données personnalisé, téléchargez-le dans le répertoire data/ de Jupyter et modifiez le notebook fourni si nécessaire.
Ce projet contient des applications pour quelques services de démonstration ainsi que des intégrations avec des services externes. Tout cela est orchestré par NVIDIA AI Workbench.
Les services de démonstration se trouvent tous dans le dossier code . Le niveau racine du dossier de code contient quelques blocs-notes interactifs destinés à des analyses techniques approfondies. Chain Server est un exemple d'application utilisant des NIM avec LangChain. (Notez que Chain Server vous donne ici la possibilité d'expérimenter avec et sans RAG). Le dossier Chat Frontend contient un serveur d'interface utilisateur interactif pour exercer le serveur de chaîne. Enfin, des exemples de cahiers sont fournis dans le répertoire d'évaluation pour démontrer la notation et la validation de la récupération.
carte mentale
racine((AI Workbench))
Services de démonstration
Serveur de chaîne<br />LangChain + NIM
Frontend<br />Interface utilisateur de démonstration interactive
Évaluation<br />Valider les résultats
Carnets<br />Utilisation avancée
Intégrations
Redis Historique des conversations
Base de données de vecteurs Milvus
LLM NIM</br>LLM optimisés
Le Chain Server peut être configuré avec un fichier de configuration ou des variables d'environnement.
Par défaut, l'application recherchera un fichier de configuration dans tous les emplacements suivants. Si plusieurs fichiers de configuration sont trouvés, les valeurs des fichiers inférieurs dans la liste seront prioritaires.
Un chemin de fichier de configuration supplémentaire peut être spécifié via une variable d'environnement nommée APP_CONFIG . La valeur de ce fichier aura priorité sur tous les emplacements de fichiers par défaut.
export APP_CONFIG=/etc/my_config.yaml La configuration peut également être définie à l'aide de variables d'environnement. Les noms de variables seront au format : APP_FIELD__SUB_FIELD Les valeurs spécifiées comme variables d'environnement auront priorité sur toutes les valeurs des fichiers.
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
L'interface de chat propose également quelques options de configuration. Ils peuvent être paramétrés de la même manière que le serveur de chaîne.
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
Tous les commentaires et contributions à ce projet sont les bienvenus. Lorsque vous apportez des modifications à ce projet, que ce soit pour un usage personnel ou pour contribuer, il est recommandé de travailler sur un fork sur ce projet. Une fois les modifications terminées sur le fork, une demande de fusion doit être ouverte.
Ce projet a été configuré avec des Linters qui ont été optimisés pour aider le code à rester cohérent sans être trop fastidieux. Nous utilisons les Linters suivants :
L'environnement VSCode intégré est configuré pour exécuter le linting et la vérification en temps réel.
Pour exécuter manuellement le peluchage effectué par les pipelines CI, exécutez /project/code/tools/lint.sh . Des tests individuels peuvent être exécutés en les spécifiant par leur nom : /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] . L'exécution de l'outil lint en mode correctif corrigera automatiquement ce qu'il peut en exécutant Black, en mettant à jour le README et en effaçant la sortie des cellules sur tous les ordinateurs portables Jupyter.
L'interface a été conçue dans le but de minimiser le développement HTML et Javascript requis. Un Shell d'application de marque et de style est fourni et a été créé avec du HTML, du Javascript et du CSS Vanilla. Il est conçu pour être facile à personnaliser, mais il ne devrait jamais être obligatoire. Les composants interactifs du frontend sont tous créés dans Gradio et montés dans le shell de l'application à l'aide d'iframe.
En haut du shell de l’application se trouve un menu répertoriant les vues disponibles. Chaque vue peut avoir sa propre mise en page composée d'une ou de quelques pages.
Les pages contiennent les composants interactifs d'une démo. Le code des pages se trouve dans le répertoire code/frontend/pages . Pour créer une nouvelle page :
__init__.py dans le nouveau répertoire qui utilise Gradio pour définir l'interface utilisateur. La disposition des Gradio Blocks doit être définie dans une variable appelée page .chat pour un exemple.code/frontend/pages/__init__.py , importez la nouvelle page et ajoutez la nouvelle page à la liste __all__ .REMARQUE : La création d'une nouvelle page ne l'ajoutera pas au frontend. Il doit être ajouté à une vue pour apparaître sur le Frontend.
La vue se compose d'une ou de quelques pages et doit fonctionner indépendamment les unes des autres. Les vues sont toutes définies dans le module code/frontend/server.py . Toutes les vues déclarées seront automatiquement ajoutées à la barre de menu du Frontend et rendues disponibles dans l'interface utilisateur.
Pour définir une nouvelle vue, modifiez la liste nommée views . Il s'agit d'une liste d'objets View . L'ordre des objets définira leur ordre dans le menu Frontend. La première vue définie sera la vue par défaut.
Les objets de vue décrivent le nom et la disposition de la vue. Ils peuvent être déclarés comme suit :
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
) Toutes les déclarations de page, View.left ou View.right , sont facultatives. S'ils ne sont pas déclarés, alors les iframes associées dans la mise en page Web seront masquées. Les autres iframes s'agrandiront pour combler les lacunes. Les diagrammes suivants montrent les différentes dispositions.
bêta-bloc
colonnes 1
menu["barre de menu"]
bloc
colonnes 2
gauche droite
fin
bêta-bloc
colonnes 1
menu["barre de menu"]
bloc
colonnes 1
gauche:1
fin
L'interface contient quelques actifs de marque qui peuvent être personnalisés pour différents cas d'utilisation.
Le frontend contient un logo en haut à gauche de la page. Pour modifier le logo, un SVG du logo souhaité est requis. Le shell de l'application peut ensuite être facilement modifié pour utiliser le nouveau SVG en modifiant le fichier code/frontend/_assets/index.html . Il existe un seul div avec un identifiant de logo . Cette boîte contient un seul SVG. Mettez-le à jour avec la définition SVG souhaitée.
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > Le style de l'App Shell est défini dans code/frontend/_static/css/style.css . Les couleurs de ce fichier peuvent être modifiées en toute sécurité.
Le style des différentes pages est défini dans code/frontend/pages/*/*.css . Ces fichiers peuvent également nécessiter des modifications pour les jeux de couleurs personnalisés.
Le thème Gradio est défini dans le fichier code/frontend/_assets/theme.json . Les couleurs de ce fichier peuvent être modifiées en toute sécurité selon la marque souhaitée. D'autres styles de ce fichier peuvent également être modifiés, mais cela peut entraîner des modifications importantes du frontend. La documentation Gradio contient plus d'informations sur les thèmes Gradio.
REMARQUE : Il s'agit d'un sujet avancé dont la plupart des développeurs n'auront jamais besoin.
Parfois, il peut être nécessaire d'avoir plusieurs pages dans une vue qui communiquent entre elles. À cette fin, le framework de messagerie postMessage de Javascript est utilisé. Tout message approuvé publié sur le shell de l'application sera transmis à chaque iframe où les pages pourront gérer le message comme vous le souhaitez. La page control utilise cette fonctionnalité pour modifier la configuration de la page chat .
Ce qui suit publiera un message sur le shell de l'application ( window.top ). Le message contiendra un dictionnaire avec la clé use_kb et une valeur true. En utilisant Gradio, ce Javascript peut être exécuté par n'importe quel événement Gradio.
window . top . postMessage ( { "use_kb" : true } , '*' ) ; Ce message sera automatiquement envoyé à toutes les pages par le shell de l'application. L’exemple de code suivant consommera le message sur une autre page. Ce code s'exécutera de manière asynchrone lorsqu'un événement message est reçu. Si le message est fiable, un composant Gradio avec l' elem_id de use_kb sera mis à jour avec la valeur spécifiée dans le message. De cette manière, la valeur d'un composant Gradio peut être dupliquée sur plusieurs pages.
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; Le README est rendu automatiquement ; les modifications directes seront écrasées. Afin de modifier le README, vous devrez éditer les fichiers de chaque section séparément. Tous ces fichiers seront combinés et le README sera automatiquement généré. Vous pouvez trouver tous les fichiers associés dans le dossier docs .
La documentation est écrite dans Github Flavored Markdown, puis restituée dans un fichier Markdown final par Pandoc. Les détails de ce processus sont définis dans le Makefile. L'ordre des fichiers générés est défini dans docs/_TOC.md . La documentation peut être prévisualisée dans la fenêtre du navigateur de fichiers Workbench.
Le fichier d'en-tête est le premier fichier utilisé pour compiler la documentation. Ce fichier peut être trouvé sur docs/_HEADER.md . Le contenu de ce fichier sera écrit textuellement, sans aucune manipulation, dans le README avant toute autre chose.
Le fichier récapitulatif contient une description rapide et un graphique décrivant ce projet. Le contenu de ce fichier sera ajouté au README immédiatement après l'en-tête et juste avant la table des matières. Ce fichier est traité par Pandoc pour intégrer des images avant d'écrire dans le README.
Le fichier le plus important pour la documentation est le fichier de table des matières à l' docs/_TOC.md . Ce fichier définit une liste de fichiers qui doivent être concaténés afin de générer le manuel README final. Les fichiers doivent figurer sur cette liste pour être inclus.
Enregistrez tout le contenu statique, y compris les images, dans le dossier _static . Cela aidera à l’organisation.
Il peut être utile d’avoir des documents qui se mettent à jour et s’écrivent eux-mêmes. Pour créer un document dynamique, créez simplement un fichier exécutable qui écrit le document au format Markdown sur la sortie standard. Pendant la construction, si une entrée du fichier de table des matières est exécutable, elle sera exécutée et sa sortie standard sera utilisée à sa place.
Lorsqu'une validation liée à la documentation est poussée, une action GitHub restituera la documentation. Toute modification apportée au fichier README sera automatiquement validée.
La plupart de la configuration de l'environnement de développement s'effectue avec des variables d'environnement. Pour apporter des modifications permanentes aux variables d'environnement, modifiez variables.env ou utilisez l'interface utilisateur de Workbench.
Ce projet utilise un environnement Python sur /usr/bin/python3 et les dépendances sont gérées avec pip . Étant donné que tout le développement est effectué dans un conteneur, toute modification apportée à l'environnement Python sera éphémère. Pour installer définitivement un package Python, ajoutez-le au fichier requirements.txt ou utilisez l'interface utilisateur de Workbench.
L'environnement de développement est basé sur Ubuntu 22.04. L'utilisateur principal dispose d'un accès sudo sans mot de passe, mais toutes les modifications apportées au système seront éphémères. Pour apporter des modifications permanentes aux packages installés, ajoutez-les au fichier [ apt.txt ]. Pour apporter d'autres modifications au système d'exploitation telles que la manipulation de fichiers, l'ajout de variables d'environnement, etc. ; utilisez les fichiers postBuild.bash et preBuild.bash .
Il est généralement recommandé de mettre à jour les dépendances tous les mois pour garantir qu'aucun CVE n'est exposé via des dépendances mal utilisées. Le processus suivant peut être utilisé pour corriger ce projet. Il est recommandé d'exécuter les tests de régression après le correctif pour garantir que rien n'a été interrompu dans la mise à jour.
/project/code/tools/bump.sh ./project/code/tools/audit.sh . Ce script imprimera un rapport de tous les packages Python dans un état d'avertissement et de tous les packages dans un état d'erreur. Tout ce qui se trouve dans un état d'erreur doit être résolu car il comportera des CVE actifs et des vulnérabilités connues.

