Facebook Messenger Bot
1.0.0
Le chatbot FB Messenger que j'ai formé pour parler comme moi. L'article de blog associé.
Pour ce projet, je souhaitais former un modèle Sequence To Sequence sur mes journaux de conversations passés provenant de divers sites de médias sociaux. Vous pouvez en savoir plus sur la motivation derrière cette approche, les détails du modèle ML et le but de chaque script Python dans l'article de blog, mais je souhaite utiliser ce README pour expliquer comment vous pouvez entraîner votre propre chatbot à parler comme vous. .
Pour exécuter ces scripts, vous aurez besoin des bibliothèques suivantes.
Téléchargez et décompressez l'intégralité de ce référentiel depuis GitHub, soit de manière interactive, soit en saisissant ce qui suit dans votre terminal.
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitAccédez au répertoire supérieur du dépôt sur votre machine
cd Facebook-Messenger-BotNotre première tâche consiste à télécharger toutes vos données de conversation à partir de divers sites de réseaux sociaux. Pour moi, j'ai utilisé Facebook, Google Hangouts et LinkedIn. Si vous avez d'autres sites à partir desquels vous obtenez des données, ce n'est pas un problème. Il vous suffira de créer une nouvelle méthode dans createDataset.py.
Données Facebook : Téléchargez vos données à partir d'ici. Une fois téléchargé, vous devriez avoir un fichier assez volumineux appelé messages.htm . Ce sera un fichier assez volumineux (plus de 190 Mo pour moi). Nous allons devoir analyser ce gros fichier et extraire toutes les conversations. Pour ce faire, nous utiliserons cet outil que Dillon Dixon a aimablement mis à disposition en open source. Vous allez installer cet outil en exécutant
pip install fbchat-archive-parserpuis en exécutant :
fbcap ./messages.htm > fbMessages.txtCela vous donnera toutes vos conversations Facebook dans un fichier texte assez unifié. Merci Dillon! Allez-y, puis stockez ce fichier dans votre dossier Facebook-Messenger-Bot.
Données LinkedIn : Téléchargez vos données à partir d'ici. Une fois téléchargé, vous devriez voir un fichier inbox.csv . Nous n'aurons pas besoin de prendre d'autres mesures ici, nous voulons simplement le copier dans notre dossier.
Données Google Hangouts : Téléchargez votre formulaire de données ici. Une fois téléchargé, vous obtiendrez un fichier JSON que nous devrons analyser. Pour ce faire, nous utiliserons cet analyseur trouvé dans ce billet de blog phénoménal. Nous voudrons enregistrer les données dans des fichiers texte, puis copier le dossier dans le nôtre.
À la fin de tout cela, vous devriez avoir une structure de répertoires qui ressemble à ceci. Assurez-vous de renommer les dossiers et les noms de fichiers si les vôtres sont différents.
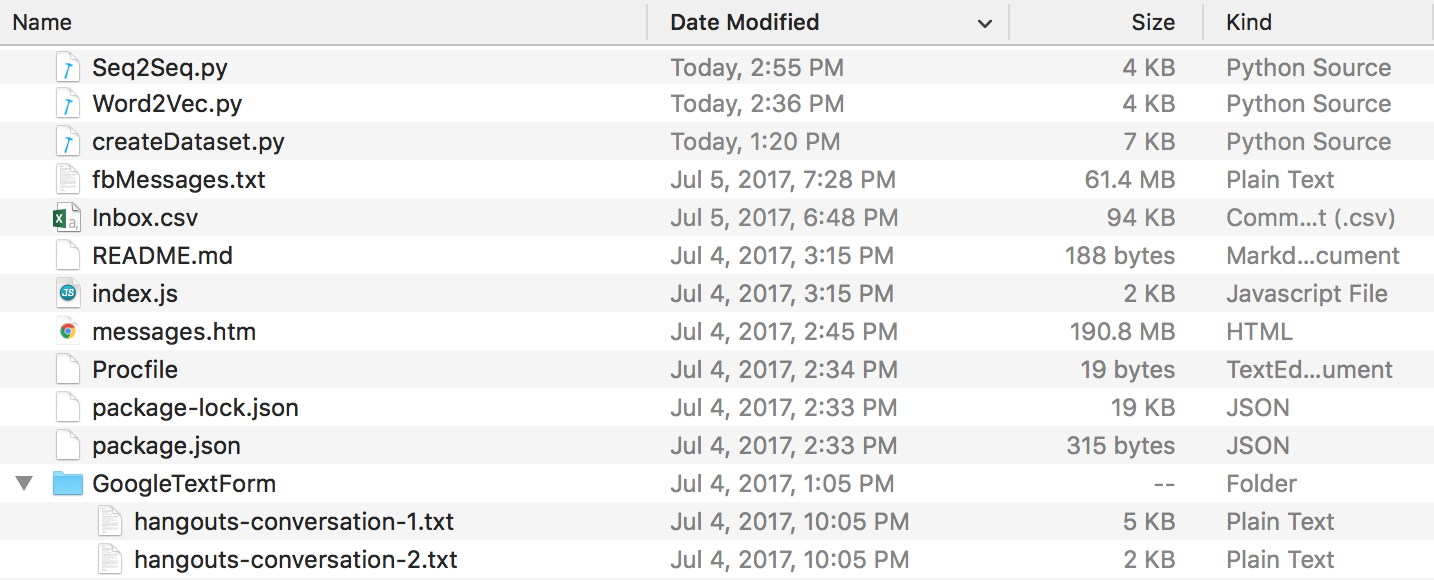
Données Discord : Vous pouvez extraire vos journaux de discussion Discord en utilisant ce génial DiscordChatExporter créé par Tyrrrz. Suivez sa documentation pour extraire les journaux de discussion singuliers souhaités au format .txt (c'est important). Vous pouvez ensuite tous les mettre dans un dossier nommé DiscordChatLogs dans le répertoire du dépôt.
Données WhatsApp : assurez-vous d'avoir un téléphone portable et mettez-le au format de date américain si ce n'est pas déjà fait (cela sera important plus tard lorsque vous analyserez le fichier journal en .csv). Vous ne pouvez pas utiliser WhatsApp Web à cette fin. Ouvrez le chat que vous souhaitez envoyer, appuyez sur le bouton de menu, appuyez sur plus, puis cliquez sur « Chat par e-mail ». Envoyez-vous l'e-mail et téléchargez-le sur votre ordinateur. Cela vous donnera un fichier .txt, pour l'analyser, nous le convertirons en .csv. Pour ce faire, allez sur ce lien et entrez tout le texte dans votre fichier journal. Cliquez sur Exporter, téléchargez le fichier csv et stockez-le simplement dans votre dossier Facebook-Messenger-Bot sous le nom "whatsapp_chats.csv".
REMARQUE : L'analyseur fourni dans le lien ci-dessus semble avoir été supprimé. Si vous disposez toujours d'un fichier .csv au format correct , vous pouvez toujours l'utiliser. Sinon, téléchargez vos journaux de discussion WhatsApp sous forme de fichiers .txt et placez-les tous dans un dossier nommé WhatsAppChatLogs dans le répertoire du dépôt. createDataset.py fonctionnera avec ces fichiers à la place si, et seulement si, il NE trouve PAS de fichier .csv nommé whatsapp_chats.csv .
Si vous utilisez des journaux de discussion .txt , notez que le format attendu est-
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(OU)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
Maintenant que nous avons tous nos journaux de conversations dans un format propre, nous pouvons continuer et créer notre ensemble de données. Dans notre répertoire, exécutons :
python createDataset.pyVous serez ensuite invité à saisir votre nom (afin que le script sache qui rechercher) et pour quels sites de réseaux sociaux vous disposez de données. Ce script créera un fichier nommé conversationDictionary.npy qui est un objet Numpy contenant des paires sous la forme de (FRIENDS_MESSAGE, YOUR RESPONSE). Un fichier nommé conversationData.txt sera également créé. Il s'agit simplement d'un gros fichier texte contenant les données du dictionnaire sous une forme unifiée.
Maintenant que nous avons ces 2 fichiers, nous pouvons commencer à créer nos vecteurs de mots via un modèle Word2Vec. Cette étape est un peu différente des autres. La fonction Tensorflow que nous verrons plus tard (dans seq2seq.py) gère également la partie intégration. Vous pouvez donc soit décider de former vos propres vecteurs, soit demander à la fonction seq2seq de le faire conjointement, ce que j'ai fini par faire. Si vous souhaitez créer vos propres vecteurs de mots via Word2Vec, dites y à l'invite (après avoir exécuté ce qui suit). Si vous ne le faites pas, alors ce n'est pas grave, répondez n et cette fonction créera uniquement le fichier wordList.txt.
python Word2Vec.pySi vous exécutez word2vec.py dans son intégralité, cela créera 4 fichiers différents. Word2VecXTrain.npy et Word2VecYTrain.npy sont les matrices de formation que Word2Vec utilisera. Nous les enregistrons dans notre dossier, au cas où nous aurions besoin d'entraîner à nouveau notre modèle Word2Vec avec différents hyperparamètres. Nous sauvegardons également wordList.txt , qui contient simplement tous les mots uniques de notre corpus. Le dernier fichier enregistré est embeddingMatrix.npy qui est une matrice Numpy contenant tous les vecteurs de mots générés.
Maintenant, nous pouvons créer et entraîner notre modèle Seq2Seq.
python Seq2Seq.pyCela créera 3 fichiers différents ou plus. Seq2SeqXTrain.npy et Seq2SeqYTrain.npy sont les matrices de formation que Seq2Seq utilisera. Encore une fois, nous les sauvegardons juste au cas où nous souhaiterions apporter des modifications à notre architecture de modèle et nous ne voudrions pas recalculer notre ensemble de formation. Le ou les derniers fichiers seront des fichiers .ckpt qui contiennent notre modèle Seq2Seq enregistré. Les modèles seront enregistrés à différentes périodes dans la boucle de formation. Ceux-ci seront utilisés et déployés une fois que nous aurons créé notre chatbot.
Maintenant que nous avons un modèle enregistré, créons maintenant notre chatbot Facebook. Pour ce faire, je vous recommande de suivre ce tutoriel. Vous n'avez pas besoin de lire quoi que ce soit sous la section « Personnaliser ce que dit le bot ». Notre modèle Seq2Seq gérera cette partie. IMPORTANT - Le didacticiel vous demandera de créer un nouveau dossier dans lequel se trouvera le projet Node. Gardez à l'esprit que ce dossier sera différent de notre dossier. Vous pouvez considérer ce dossier comme étant l'endroit où se trouvent notre prétraitement des données et la formation du modèle, tandis que l'autre dossier est strictement réservé à l'application Express (EDIT : je crois que vous pouvez suivre les étapes du didacticiel dans notre dossier et simplement créer le projet Node, Procfile et index.js ici si vous le souhaitez). Le tutoriel lui-même devrait suffire, mais voici un résumé des étapes.
Après avoir suivi correctement les étapes, vous devriez pouvoir envoyer un message au chatbot et obtenir des réponses.
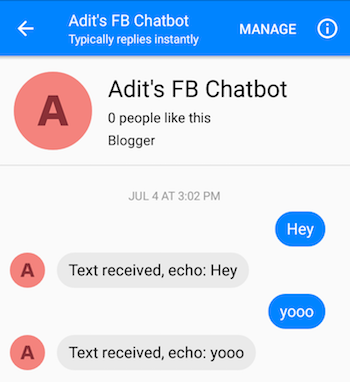
Ah, tu as presque fini ! Maintenant, nous devons créer un serveur Flask sur lequel nous pouvons déployer notre modèle Seq2Seq enregistré. J'ai le code de ce serveur ici. Parlons de la structure générale. Les serveurs Flask ont normalement un fichier .py principal dans lequel vous définissez tous les points de terminaison. Ce sera app.py dans notre cas. Ce sera là que nous chargerons notre modèle. Vous devez créer un dossier appelé « modèles » et le remplir de 4 fichiers (un fichier de point de contrôle, un fichier de données, un fichier d'index et un fichier méta). Ce sont les fichiers créés lorsque vous enregistrez un modèle Tensorflow.

Dans ce fichier app.py, nous voulons créer un itinéraire (/prediction dans mon cas) où l'entrée de l'itinéraire sera introduite dans notre modèle enregistré, et la sortie du décodeur est la chaîne qui est renvoyée. Allez-y et regardez de plus près app.py si c'est encore un peu déroutant. Maintenant que vous disposez de votre app.py et de vos modèles (et d'autres fichiers d'assistance si vous en avez besoin), vous pouvez déployer votre serveur. Nous utiliserons à nouveau Heroku. Il existe de nombreux didacticiels différents sur le déploiement de serveurs Flask sur Heroku, mais j'aime celui-ci en particulier (je n'ai pas besoin des sections Foreman et Logging).
Et voilà. Vous devriez pouvoir envoyer des messages au chatbot et voir des réponses intéressantes qui (espérons-le) vous ressemblent d'une certaine manière.
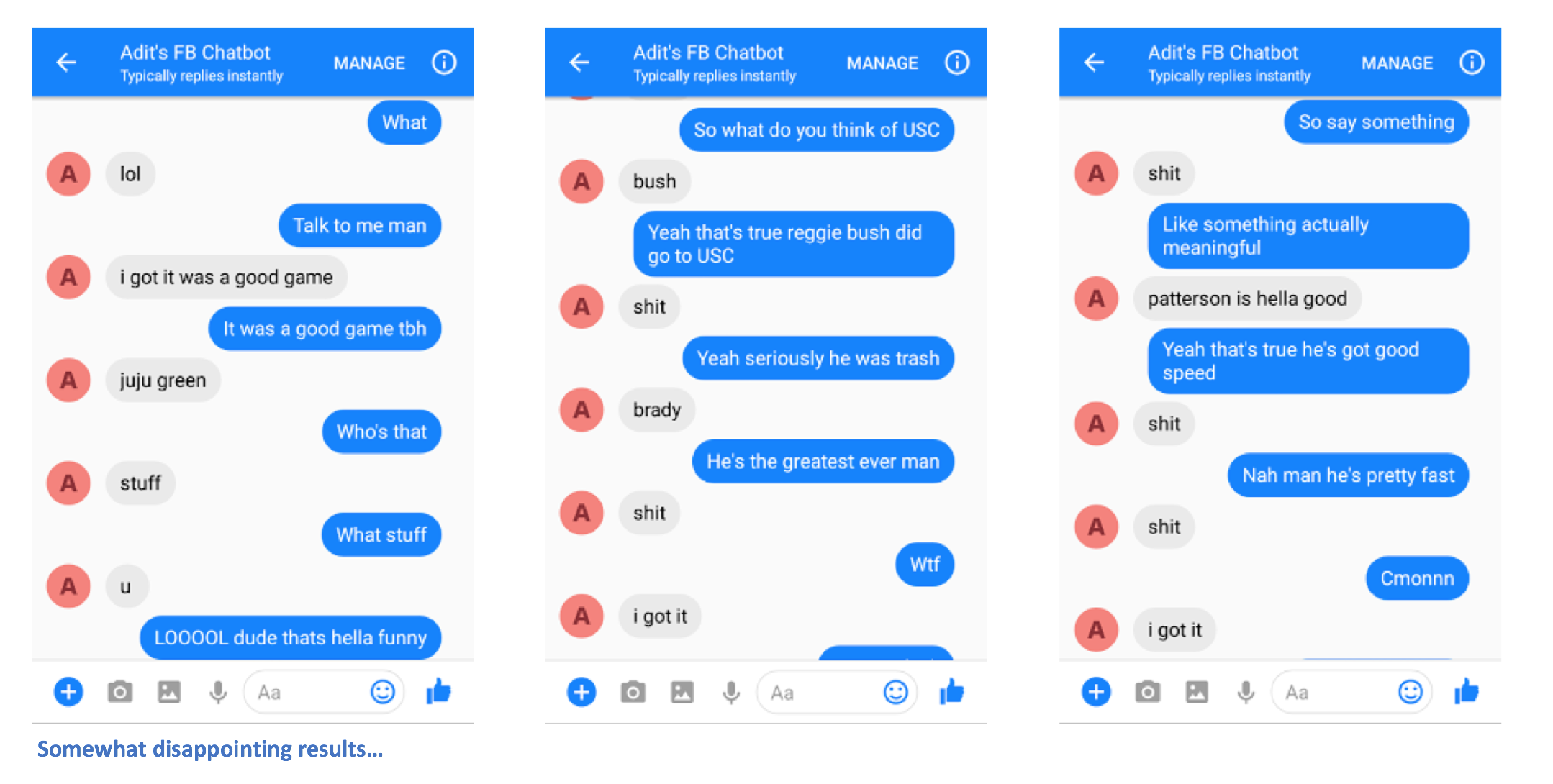
S'il vous plaît laissez-moi savoir si vous rencontrez des problèmes ou si vous avez des suggestions pour améliorer ce README. Si vous pensez qu'une certaine étape n'est pas claire, faites-le-moi savoir et je ferai de mon mieux pour modifier le README et apporter des éclaircissements.


