RLAIF V
1.0.0

Aligner les MLLM grâce aux commentaires de l'IA open source pour la fiabilité du Super GPT-4V
Chine | Anglais
[2024.11.26] Nous soutenons la formation LoRA maintenant !
[2024.05.28] Notre article est désormais accessible sur arXiv !
[2024.05.20] Notre ensemble de données RLAIF-V est utilisé pour la formation de MiniCPM-Llama3-V 2.5, qui représente le premier MLLM de niveau GPT-4V côté extrémité !
[20.05.2024] Nous open-source le code, les poids (7B, 12B) et les données de RLAIF-V !
Nous présentons RLAIF-V, un nouveau cadre qui aligne les MLLM dans un paradigme entièrement open source pour la fiabilité du super GPT-4V. RLAIF-V exploite au maximum les commentaires open source sous deux angles clés, notamment des données de retour de haute qualité et un algorithme d'apprentissage par retour d'information en ligne. Les fonctionnalités notables de RLAIF-V incluent :
Super fiabilité GPT-4V via des commentaires open source . En apprenant des commentaires de l'IA open source, RLAIF-V 12B atteint une fiabilité super GPT-4V dans les tâches génératives et discriminatives.
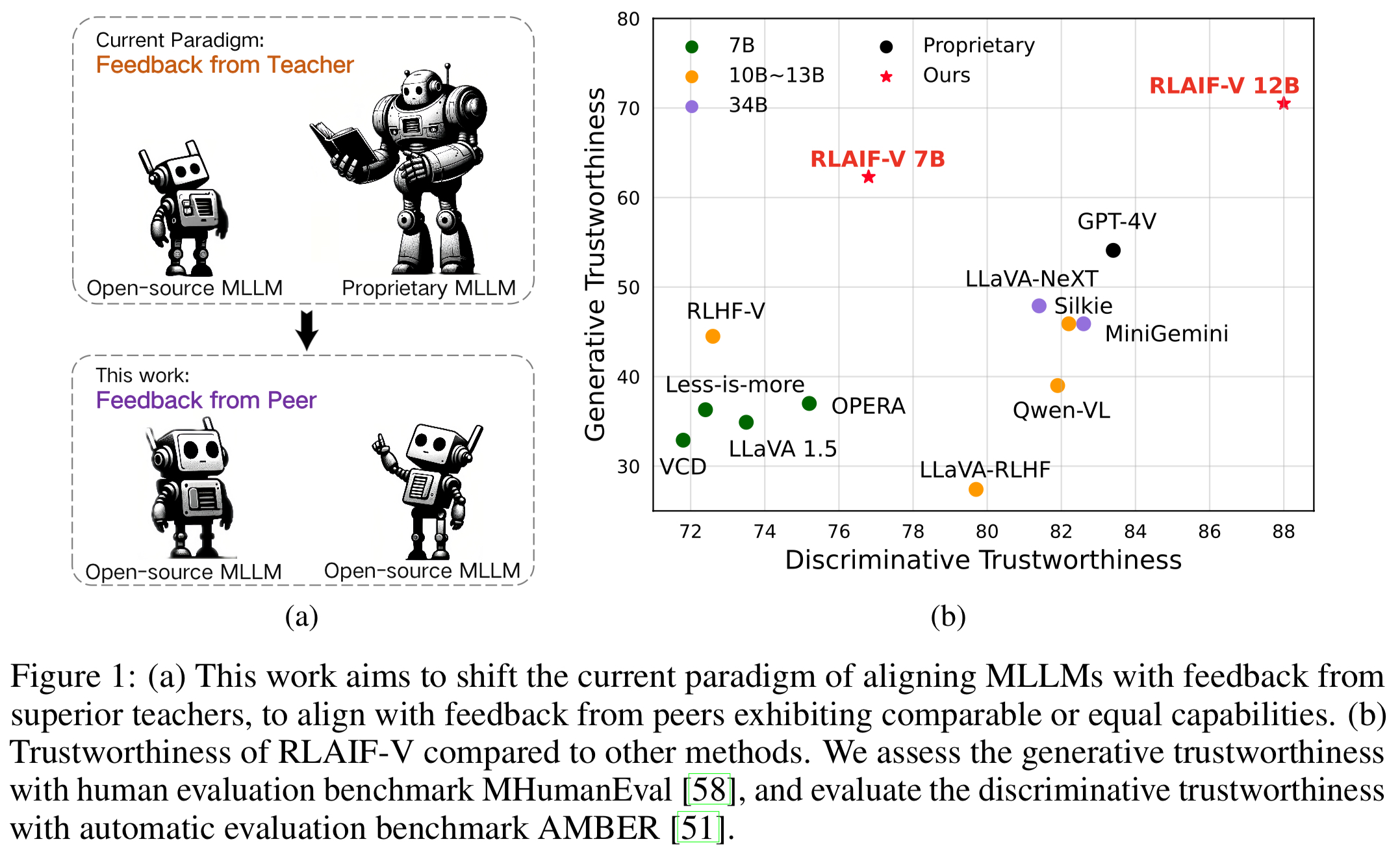
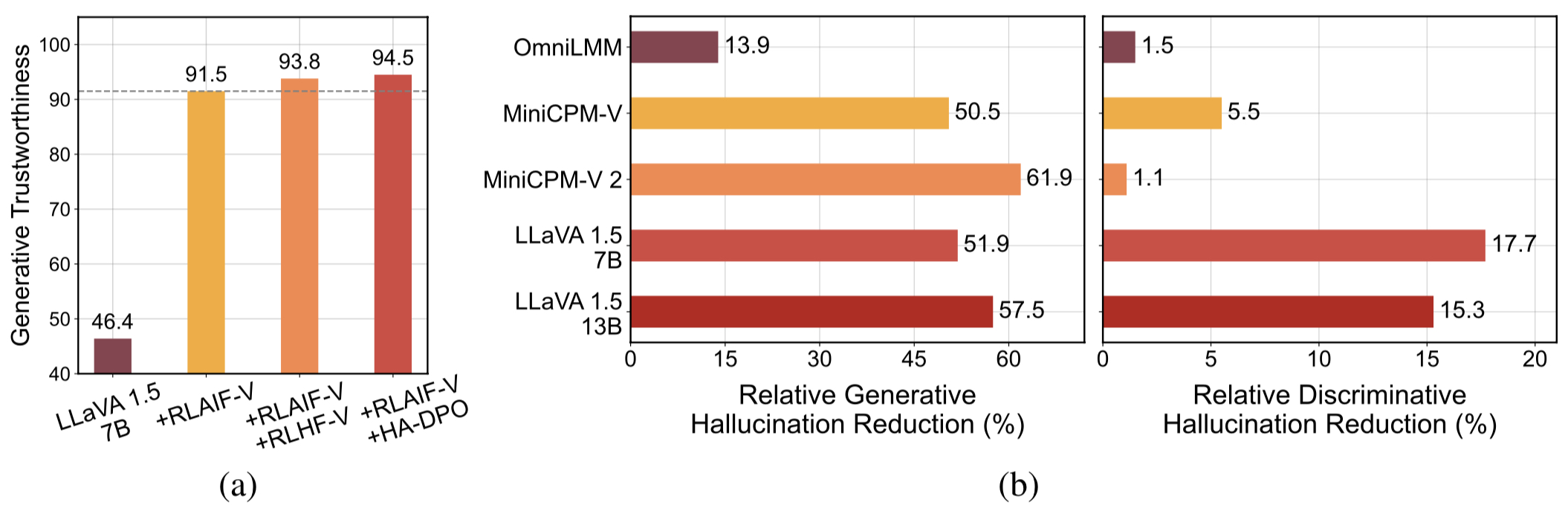
Données de rétroaction généralisables de haute qualité . Les données de rétroaction utilisées par RLAIF-V réduisent efficacement les hallucinations de différents MLLM .
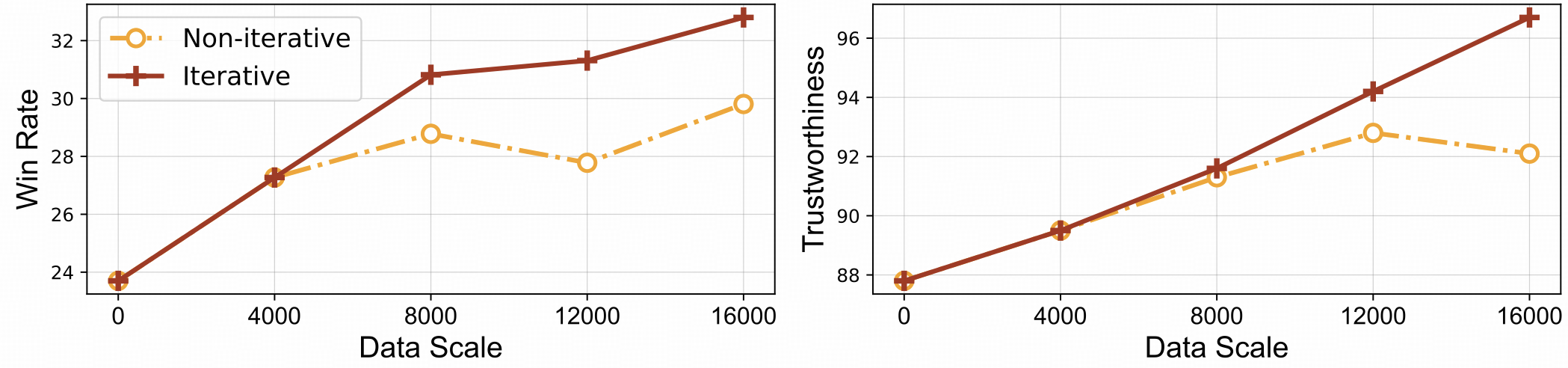
⚡️ Apprentissage efficace par feedback avec alignement itératif. RLAIF-V présente à la fois une meilleure efficacité d'apprentissage et des performances plus élevées par rapport à l'approche non itérative.
Ensemble de données
Installer
Poids du modèle
Inférence
Génération de données
Former
Évaluation
Objet HalBench
Banc MMHal
RefoMB
Citation
Nous présentons l'ensemble de données RLAIF-V, qui est un ensemble de données de préférences généré par l'IA couvrant un large éventail de tâches et de domaines. Ces ensembles de données de préférences multimodales open source contiennent 83 132 paires de comparaison de haute qualité . L'ensemble de données contient les paires de préférences générées dans chaque itération de formation de différents modèles, notamment LLaVA 1.5 7B, OmniLMM 12B et MiniCPM-V.
Clonez ce référentiel et accédez au dossier RLAIF-V
clone git https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
Installer le package
conda create -n rlaifv python=3.10 -y conda activer rlaifv pip install -e .
Installer le modèle spaCy requis
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip install en_core_web_trf-3.7.3.tar.gz
| Modèle | Description | Télécharger |
|---|---|---|
| RLAIF-V 7B | La variante la plus fiable sur LLaVA 1.5 | ? |
| RLAIF-V 12B | Basé sur OmniLMM-12B, atteignant une fiabilité super GPT-4V. | ? |
Nous fournissons un exemple simple pour montrer comment utiliser RLAIF-V.
from chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # or 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "Décrivez en détail les personnes dans l'image."inputs = {"image": image_path, "question": msgs}answer = chat_model.chat(entrées)imprimer(réponse)Vous pouvez également exécuter cet exemple en exécutant le script suivant :
python chat.py

Question:
Pourquoi la voiture sur la photo s’est-elle arrêtée ?
Résultats attendus :
Sur la photo, une voiture s'est arrêtée sur la route en raison de la présence d'un mouton sur la chaussée. La voiture s'est probablement arrêtée pour permettre aux moutons de s'écarter en toute sécurité ou d'éviter tout accident potentiel avec l'animal. Cette situation met en évidence l’importance d’être prudent et attentif au volant, particulièrement dans les zones où les animaux peuvent se déplacer à proximité des routes.
Configuration de l'environnement
Nous fournissons le modèle OmniLMM 12B et le modèle MiniCPM-Llama3-V 2.5 pour la génération de commentaires. Si vous souhaitez utiliser le MiniCPM-Llama3-V 2.5 pour donner des commentaires, veuillez configurer son environnement d'inférence conformément aux instructions du référentiel MiniCPM-V GitHub.
Veuillez télécharger nos modèles Llama3 8B affinés : modèle divisé et modèle de transformation de questions, et stockez-les respectivement dans le dossier ./models/llama3_split et le dossier ./models/llama3_changeq .
Commentaires sur le modèle OmniLMM 12B
Le script suivant montre l'utilisation du modèle LLaVA-v1.5-7b pour générer des réponses de candidats et du modèle OmniLMM 12B pour fournir des commentaires.
mkdir ./résultats bash ./script/data_gen/run_data_pipeline_llava15_omni.sh
Commentaires sur le modèle MiniCPM-Llama3-V 2.5
Le script suivant montre l'utilisation du modèle LLaVA-v1.5-7b pour générer des réponses candidates et du modèle MiniCPM-Llama3-V 2.5 pour fournir des commentaires. Tout d'abord, remplacez minicpmv_python dans ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh par le chemin Python de l'environnement MiniCPM-V que vous avez créé.
mkdir ./résultats bash ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
Préparer les données (facultatif)
Si vous pouvez accéder à l'ensemble de données Huggingface, vous pouvez ignorer cette étape, nous téléchargerons automatiquement l'ensemble de données RLAIF-V.
Si vous avez déjà téléchargé l'ensemble de données, vous pouvez remplacer « openbmb/RLAIF-V-Dataset » par le chemin de votre ensemble de données ici, à la ligne 38.
Entraînement
Ici, nous fournissons un script de formation pour entraîner le modèle en 1 itération . Le paramètre max_step doit être ajusté en fonction de la quantité de vos données.
Un réglage entièrement fin
Exécutez la commande suivante pour commencer le réglage complet.
bash ./script/train/llava15_train.sh
LoRA
Exécutez la commande suivante pour démarrer la formation Lora.
pip installer peft bash ./script/train/llava15_train_lora.sh
Alignement itératif
Pour reproduire le processus de formation itératif dans le document, vous devez effectuer les étapes suivantes 4 fois :
S1. Génération de données.
Suivez les instructions de génération de données pour générer des paires de préférences pour le modèle de base. Convertissez le fichier jsonl généré en parquet Huggingface.
S2. Modifier la configuration de la formation.
Dans le code de l'ensemble de données, remplacez ici 'openbmb/RLAIF-V-Dataset' par votre chemin de données.
Dans le script de formation, remplacez --data_dir par un nouveau répertoire, remplacez --model_name_or_path par le chemin du modèle de base, définissez --max_step sur le nombre d'étapes pour 4 époques, définissez --save_steps sur le nombre d'étapes pour 1/4 d'époque. .
S3. Suivez une formation DPO.
Exécutez le script de formation pour entraîner le modèle de base.
S4. Choisissez le modèle de base pour la prochaine itération.
Évaluez chaque point de contrôle sur Object HalBench et MMHal Bench, choisissez le point de contrôle le plus performant comme modèle de base lors de la prochaine itération.
Préparer les annotations COCO2014
L'évaluation d'Object HalBench s'appuie sur les annotations de légende et de segmentation de l'ensemble de données COCO2014. Veuillez d'abord télécharger l'ensemble de données COCO2014 à partir du site officiel de l'ensemble de données COCO.
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip décompresser annotations_trainval2014.zip
Inférence, évaluation et résumé
Veuillez remplacer {YOUR_OPENAI_API_KEY} par une clé API OpenAI valide.
Remarque : L'évaluation est basée sur gpt-3.5-turbo-0613 .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}Préparer les données MMHal
Veuillez télécharger les données d'évaluation MMHal ici et enregistrer le fichier dans eval/data .
Exécutez le script suivant pour générer pour MMHal Bench :
Remarque : L'évaluation est basée sur gpt-4-1106-preview .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}Préparation
Pour utiliser l'évaluation GPT-4, veuillez d'abord exécuter pip install openai==0.28 pour installer le package openai. Ensuite, modifiez openai.base et openai.api_key dans eval/gpt4.py dans vos propres paramètres.
Les données d'évaluation pour l'ensemble de développement peuvent être trouvées sur eval/data/RefoMB_dev.jsonl . Vous devez télécharger chaque image à partir de la clé image_url dans chaque ligne.
Évaluation de la note globale
Enregistrez votre modèle de réponse dans answer du fichier de données d'entrée eval/data/RefoMB_dev.jsonl , par exemple :
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}Exécutez le script suivant pour évaluer le résultat de votre modèle :
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
Évaluation du score d'hallucination
Après avoir évalué le score global, un fichier de résultats d'évaluation sera créé avec le nom A-GPT-4V_B-${model_name}.json . Utiliser ce fichier de résultats d'évaluation pour calculer le score d'hallucination comme suit :
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_resultRemarque : Pour une meilleure stabilité, nous vous recommandons d'évaluer plus de 3 fois et d'utiliser le score moyen comme score final du modèle.
Avis d'utilisation et de licence : les données, le code et le point de contrôle sont destinés et concédés sous licence à un usage de recherche uniquement. Ils sont également limités aux utilisations qui suivent le contrat de licence de LLaMA, Vicuna et Chat GPT. L'ensemble de données est CC BY NC 4.0 (autorisant uniquement une utilisation non commerciale) et les modèles formés à l'aide de l'ensemble de données ne doivent pas être utilisés en dehors des fins de recherche.
RLHF-V : la base de code sur laquelle nous avons construit.
LLaVA : le modèle d'instruction et le modèle d'étiqueteuse de RLAIF-V-7B.
MiniCPM-V : le modèle d'instruction et le modèle d'étiqueteuse du RLAIF-V-12B.
Si vous trouvez notre modèle/code/données/article utile, pensez à citer nos articles et à nous mettre en vedette ️!
@article{yu2023rlhf, title={Rlhf-v : Vers des mllms dignes de confiance via l'alignement des comportements à partir de commentaires humains correctionnels précis}, author={Yu, Tianyu et Yao, Yuan et Zhang, Haoye et He, Taiwen et Han, Yifeng et Cui, Ganqu et Hu, Jinyi et Liu, Zhiyuan et Zheng, Hai-Tao et Sun, Maosong et autres}, journal={préimpression arXiv arXiv:2312.00849}, year={2023}}@article{yu2024rlaifv, title={RLAIF-V : Aligner les MLLM via les commentaires de l'IA Open Source pour la fiabilité du Super GPT-4V}, author={Yu, Tianyu et Zhang, Haoye et Yao, Yuan et Dang, Yunkai et Chen, Da et Lu, Xiaoman et Cui, Ganqu et He, Taiwen et Liu, Zhiyuan et Chua, Tat-Seng et Sun, Maosong}, journal={arXiv preprint arXiv:2405.17220}, année={2024},
} 

