ChatLM mini Chinese
1.0.0
Chinois | Anglais
Les grands modèles de langage actuels ont tendance à avoir des paramètres volumineux, et les ordinateurs grand public sont lents à effectuer des inférences simples, sans parler de former un modèle à partir de zéro. L'objectif de ce projet est de former un modèle de langage génératif à partir de zéro, comprenant le nettoyage des données, la formation du tokenizer, la pré-formation du modèle, le réglage fin des instructions SFT, l'optimisation RLHF, etc.
ChatLM-mini-Chinese est un petit modèle de dialogue chinois avec seulement 0,2 Mo de paramètres de modèle (environ 210 M, poids partagés compris). Il peut être pré-entraîné sur une machine avec un minimum de 4 Go de mémoire vidéo ( batch_size=1 , fp16 ou bf16 . ), et le chargement et l'inférence float16 nécessitent au moins 512 Mo de mémoire vidéo.
Huggingface NLP, y compris transformers , accelerate , trl , peft , etc.trainer auto-implémenté prend en charge la pré-formation et le réglage fin du SFT sur une seule machine avec une seule carte ou avec plusieurs cartes sur une seule machine. Il permet de s'arrêter à n'importe quelle position pendant l'entraînement et de poursuivre l'entraînement à n'importe quelle position.Text-to-Text de bout en bout et à la pré-formation à la prédiction sans mask .huggingface tokenizers sentencepiece et de câlins ;batch_size=1, max_len=320 , la pré-formation est prise en charge sur une machine avec au moins 16 Go de mémoire + 4 Go de mémoire vidéo ;trainer auto-implémenté prend en charge un réglage fin des commandes rapides et prend en charge n'importe quel point d'arrêt pour continuer la formation ;sequence to sequence de Huggingface trainer ;peft lora pour l'optimisation des préférences ;Lora adapter peut être fusionné dans le modèle original.Si vous avez besoin d'effectuer une génération améliorée de récupération (RAG) basée sur de petits modèles, vous pouvez vous référer à mon autre projet Phi2-mini-Chinese Pour le code, voir rag_with_langchain.ipynb.
? Dernières mises à jour
Tous les ensembles de données proviennent d'ensembles de données de conversation à un seul cycle publiés sur Internet. Après nettoyage et formatage des données, ils sont enregistrés sous forme de fichiers Parquet. Pour le processus de traitement des données, voir utils/raw_data_process.py . Les principaux ensembles de données comprennent :
Belle_open_source_1M , train_2M_CN et train_3.5M_CN qui ont des réponses courtes, ne contiennent pas de structures de tableaux complexes et de tâches de traduction (pas de liste de vocabulaire anglais), un total de 3,7 millions de lignes, et 3,38 millions de lignes restent après le nettoyage.N premiers mots de l'encyclopédie sont les réponses. En utilisant les données de l'encyclopédie 202309 , 1,19 million d'invites d'entrée et de réponses restent après le nettoyage. Téléchargement wiki : zhwiki, convertissez le fichier bz2 téléchargé en référence wiki.txt : WikiExtractor. Le nombre total d'ensembles de données est de 10,23 millions : ensemble de pré-entraînement texte à texte : 9,3 millions, ensemble d'évaluation : 25 000 (car le décodage est lent, l'ensemble d'évaluation n'est pas trop grand). Ensemble de tests : 900 000. Les ensembles de données de réglage fin SFT et d'optimisation DPO sont présentés ci-dessous.
Modèle T5 (Text-to-Text Transfer Transformer), voir l'article pour plus de détails : Explorer les limites de l'apprentissage par transfert avec un transformateur de texte à texte unifié.
Le code source du modèle provient de huggingface, voir : T5ForConditionalGeneration.
Voir model_config.json pour la configuration du modèle. La T5-base officielle : encoder layer et decoder layer sont toutes deux composées de 12 couches. Dans ce projet, ces deux paramètres sont modifiés en 10 couches.
Paramètres du modèle : 0,2B. Taille de la liste de mots : 29 298, comprenant uniquement le chinois et une petite quantité d’anglais.
matériel:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 Formation Tokenizer : La bibliothèque de formation tokenizer existante présente des problèmes de MOO lorsqu'elle rencontre un corpus volumineux. Par conséquent, le corpus complet est fusionné et construit en fonction de la fréquence des mots selon une méthode similaire à BPE , dont l'exécution prend une demi-journée.
Pré-formation Text-to-Text : un rythme d'apprentissage dynamique de 1e-4 à 5e-3 , et une durée de pré-formation de 8 jours. Perte d'entraînement :
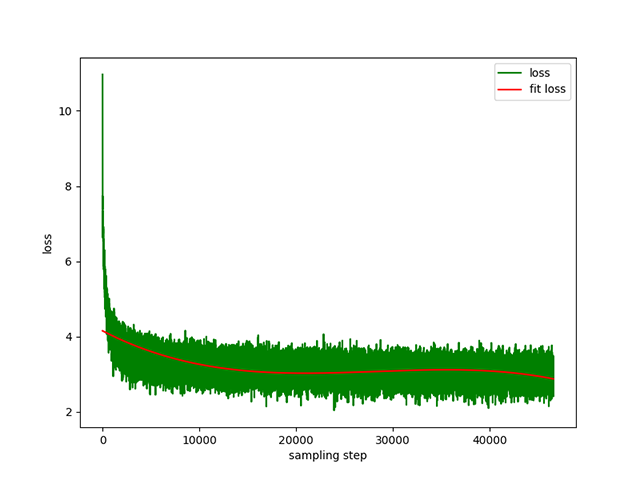
belle (les longueurs des instructions et des réponses sont inférieures à 512), le taux d'apprentissage est un taux d'apprentissage dynamique de 1e-7 à 5e-5 , et le temps de réglage fin est de 2 jours. Perte de réglage fin : 
chosen à l'étape 2 , le lot du modèle SFT generate les invites dans l'ensemble de données et obtient le texte rejected . pour optimiser la préférence complète dpo et apprendre, le taux est le-5 , demi-précision fp16 , un total de 2 epoch , et cela prend 3 heures. perte de dpo : 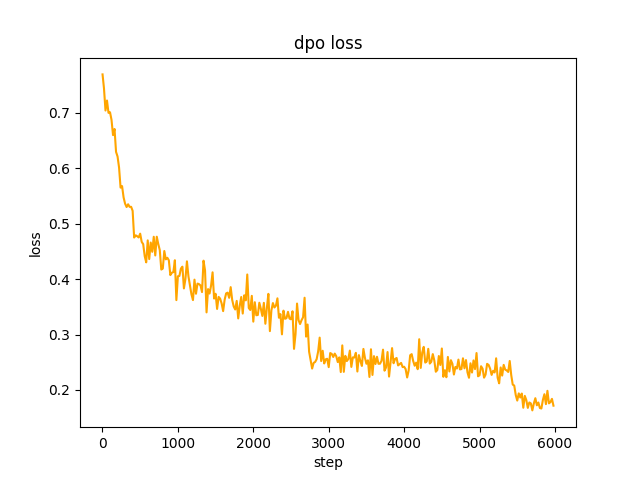
Par défaut, TextIteratorStreamer des huggingface transformers est utilisé pour implémenter le dialogue en streaming, qui ne prend en charge que greedy search . Si vous avez besoin d'autres méthodes de génération telles que beam sample , veuillez modifier le paramètre stream_chat de cli_demo.py sur False . 

Il y a des problèmes : l'ensemble de données de pré-entraînement n'en compte que plus de 9 millions et les paramètres du modèle ne sont que de 0,2 milliard. Il ne peut pas couvrir tous les aspects, et il y aura des situations où la réponse est fausse et le générateur n'a aucun sens.
Si Huggingface ne peut pas être connecté, utilisez modelscope.snapshot_download pour télécharger le fichier modèle depuis modelscope.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
Prudence
Le modèle de ce projet est un modèle TextToText Dans les champs prompt , response et autres des étapes de pré-formation, SFT et RLFH, assurez-vous d'ajouter la marque de fin de séquence [EOS] .
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese Ce projet recommande d'utiliser python 3.10 . Les anciennes versions de Python peuvent ne pas être compatibles avec les bibliothèques tierces dont elles dépendent.
installation du pip :
pip install -r ./requirements.txtSi pip a installé la version CPU de pytorch, vous pouvez installer la version CUDA de pytorch avec la commande suivante :
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118installation conda :
conda install --yes --file ./requirements.txt Utilisez la commande git pour télécharger les poids du modèle et les fichiers de configuration depuis Hugging Face Hub . Vous devez d'abord installer Git LFS, puis exécuter :
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save Vous pouvez également le télécharger manuellement directement depuis l'entrepôt Hugging Face Hub ChatLM-Chinese-0.2B et déplacer le fichier téléchargé vers le répertoire model_save .
Les exigences du corpus doivent être aussi complètes que possible. Il est recommandé d'ajouter plusieurs corpus, tels que des encyclopédies, des codes, des articles, des blogs, des conversations, etc.
Ce projet est principalement basé sur l'encyclopédie wiki chinoise. Comment obtenir le corpus wiki chinois : Adresse de téléchargement du wiki chinois : zhwiki, téléchargez zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 , environ 2,7 Go, convertissez le fichier bz2 téléchargé en référence wiki.txt : WikiExtractor , Utilisez ensuite la bibliothèque OpenCC de python pour le convertir en chinois simplifié, et enfin placez le wiki.simple.txt obtenu dans le répertoire data du répertoire racine du projet. Veuillez fusionner vous-même plusieurs corpus en un seul fichier txt .
Étant donné que le tokenizer de formation consomme beaucoup de mémoire, si votre corpus est très volumineux (le fichier txt fusionné dépasse 2G), il est recommandé d'échantillonner le corpus selon les catégories et les proportions afin de réduire le temps de formation et la consommation de mémoire. La formation d'un fichier txt de 1,7 Go nécessite environ 48 Go de mémoire (estimation, je n'ai que 32 Go, déclenchant fréquemment le swap, ordinateur bloqué pendant une longue période T_T), un processeur de 13 600 000 prend environ 1 heure.
La différence entre char level et byte level est la suivante (veuillez rechercher vous-même des informations sur les différences d'utilisation spécifiques). Le tokenizer entraîne char level par défaut. Si byte level est requis, définissez simplement token_type='byte' dans train_tokenizer.py .
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']Commencer la formation :
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab ou jupyter notebook :
Voir le fichier train.ipynb . Il est recommandé d'utiliser jupyter-lab pour éviter d'envisager la situation où le processus du terminal est tué après la déconnexion du serveur.
Console:
La formation sur la console doit tenir compte du fait que le processus sera interrompu après la déconnexion de la connexion. Il est recommandé d'utiliser l'outil de démon de processus Supervisor ou screen pour établir une session de connexion.
Tout d'abord, configurez accelerate , exécutez la commande suivante et sélectionnez en fonction des invites. Reportez-vous à accelerate.yaml Remarque : DeepSpeed est plus difficile à installer sur Windows .
accelerate config Commencez la formation. Si vous souhaitez utiliser la configuration fournie par le projet, veuillez ajouter le paramètre --config_file ./accelerate.yaml après la commande suivante accelerate launch . La configuration est basée sur la configuration 2xGPU sur une seule machine.
Il existe deux scripts pour la pré-formation. Le formateur implémenté dans ce projet correspond à train.py , et le formateur implémenté par huggingface correspond à pre_train.py . Le formateur implémenté dans ce projet affiche des informations de formation plus belles et facilite la modification des détails de la formation (tels que les fonctions de perte, les enregistrements de journaux, etc.). Tous les points d'arrêt sont pris en charge pour continuer la formation. Le formateur implémenté dans ce projet prend en charge la formation continue après une formation. point d'arrêt à n'importe quelle position. Appuyez sur ctrl+c pour enregistrer les informations sur le point d'arrêt lorsque vous quittez le script.
Une seule machine et une seule carte :
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py Machine unique avec plusieurs cartes : 2 est le nombre de cartes graphiques, veuillez le modifier en fonction de votre situation réelle.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyPoursuivre l'entraînement à partir du point d'arrêt :
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyL'ensemble de données SFT provient entièrement de la contribution du patron de BELLE, merci. Les ensembles de données SFT sont : Generated_chat_0.4M, train_0.5M_CN et train_2M_CN, avec environ 1,37 million de lignes restantes après le nettoyage. Exemple de réglage fin d'un ensemble de données avec la commande sft :
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} Créez votre propre ensemble de données en vous référant à l'exemple de fichier parquet dans le répertoire data . Le format de l'ensemble de données est le suivant : parquet est divisé en deux colonnes, une colonne de texte prompt , qui représente l'invite, et une colonne de texte response . qui représente la sortie attendue du modèle. Pour plus de détails sur le réglage fin, consultez la méthode train sous model/trainer.py . Lorsque is_finetune est défini sur True , le réglage fin sera effectué par défaut pour geler la couche d'intégration et la couche d'encodeur et entraîner uniquement le décodeur. couche. Si vous devez geler d'autres paramètres, veuillez ajuster le code vous-même.
Exécutez le réglage fin de SFT :
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyVoici deux méthodes préférées courantes : PPO et DPO. Veuillez rechercher des articles et des blogs pour des implémentations spécifiques.
Méthode PPO (optimisation des préférences approximatives, optimisation de la politique proximale)
Étape 1 : utilisez l'ensemble de données de réglage fin pour effectuer un réglage fin supervisé (SFT, Supervised Finetuning).
Étape 2 : Utilisez l'ensemble de données de préférence (une invite contient au moins 2 réponses, une réponse souhaitée et une réponse indésirable. Plusieurs réponses peuvent être triées par score, la plus recherchée ayant le score le plus élevé) pour entraîner le modèle de récompense (RM , Modèle de récompense). Vous pouvez utiliser la bibliothèque peft pour créer rapidement le modèle de récompense Lora.
Étape 3 : utilisez RM pour effectuer une formation PPO supervisée sur le modèle SFT afin que le modèle réponde aux préférences.
Utilisez le réglage fin DPO (Direct Preference Optimization) ( ce projet utilise la méthode de réglage fin DPO, qui économise la mémoire vidéo ). Sur la base de l'obtention du modèle SFT, il n'est pas nécessaire de former le modèle de récompense pour obtenir des réponses positives (). choisies) et négatives (rejetées) pour commencer la mise au point. Le texte chosen avec précision provient de l'ensemble de données d'origine alpaca-gpt4-data-zh, et le texte rejected provient de la sortie du modèle après le réglage fin de SFT pour 1 époque. Les deux autres ensembles de données : huozi_rlhf_data_json et rlhf-reward-. single-round-trans_chinese, après fusion d'un total de 80 000 données dpo.
Pour le processus de traitement de l'ensemble de données dpo, voir utils/dpo_data_process.py .
Exemple d'ensemble de données d'optimisation des préférences DPO :
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}Exécuter l'optimisation des préférences :
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py Assurez-vous qu'il y a les fichiers suivants dans le répertoire model_save . Ces fichiers se trouvent dans l'entrepôt Hugging Face Hub ChatLM-Chinese-0.2B :
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
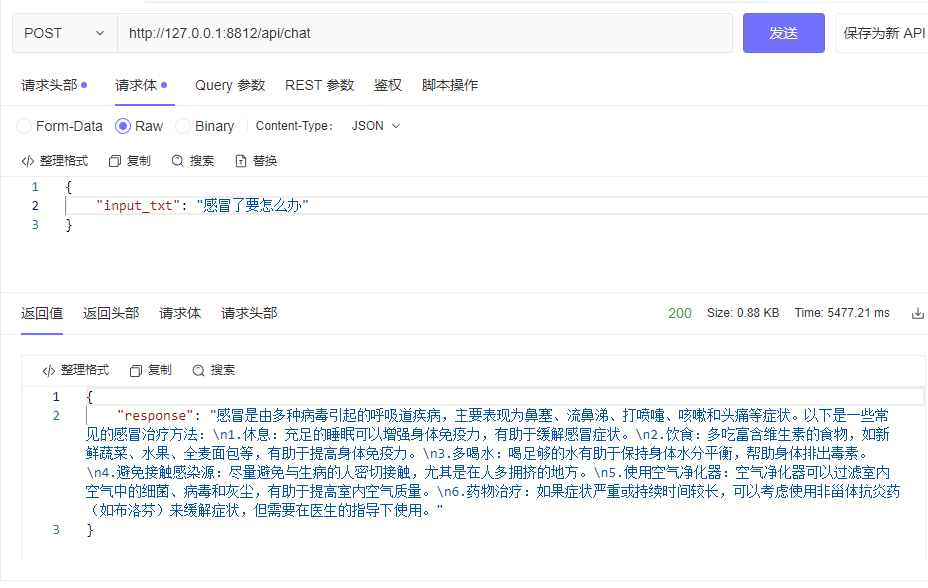
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyExemple d'appel API :
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
Ici, nous prenons les informations du triplet dans le texte comme exemple pour effectuer un réglage fin en aval. Pour connaître la méthode traditionnelle d'extraction de Deep Learning pour cette tâche, consultez l'entrepôt pytorch_IE_model. Extraire tous les triplets dans un morceau de texte, comme la phrase 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮, extraire les triples (写生随笔,作者,张来亮) et (写生随笔,出版社,冶金工业) .
L'ensemble de données d'origine est le suivant : ensemble de données de triple extraction Baidu. Exemple de format d'ensemble de données affinées traitées :
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} Vous pouvez utiliser directement le script sft_train.py pour un réglage fin. Le script finetune_IE_task.ipynb contient le processus de décodage détaillé. L'ensemble de données de formation contient environ 17000 éléments, le taux d'apprentissage 5e-5 et l'époque de formation 5 . Les capacités de dialogue des autres tâches n'ont pas disparu après un réglage fin.

Effet de réglage fin : utilisez l'ensemble de données dev publié百度三元组抽取数据集comme ensemble de test à comparer avec la méthode traditionnelle pytorch_IE_model.
| Modèle | score F1 | Précision P | Rappel R |
|---|---|---|---|
| ChatLM-Chinese-0.2B réglage fin | 0,74 | 0,75 | 0,73 |
| ChatLM-Chinese-0.2B sans pré-formation | 0,51 | 0,53 | 0,49 |
| Méthodes traditionnelles d'apprentissage en profondeur | 0,80 | 0,79 | 80,1 |
Remarque : ChatLM-Chinese-0.2B无预训练signifie initialiser directement des paramètres aléatoires et démarrer la formation avec un taux d'apprentissage de 1e-4 . Les autres paramètres sont cohérents avec un réglage fin.
Le modèle lui-même n'est pas formé à l'aide d'un ensemble de données plus vaste et n'est pas non plus affiné pour les instructions permettant de répondre aux questions à choix multiples. Le score C-Eval est essentiellement un niveau de base et peut être utilisé comme référence si nécessaire. Code d'évaluation C-Eval voir : eval/c_eavl.ipynb
| catégorie | correct | question_count | précision |
|---|---|---|---|
| Sciences humaines | 63 | 257 | 24,51% |
| Autre | 89 | 384 | 23,18% |
| TIGE | 89 | 430 | 20,70% |
| Sciences sociales | 72 | 275 | 26,18% |
Si vous pensez que ce projet vous est utile, merci de le citer.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
Ce projet n'assume aucun risque ni responsabilité découlant des risques liés à la sécurité des données et à l'opinion publique causés par des modèles et des codes open source, ou par tout modèle induit en erreur, abusé, diffusé ou mal exploité.


