mage ai
0.9.75
Donnez à votre équipe de données des pouvoirs magiques.
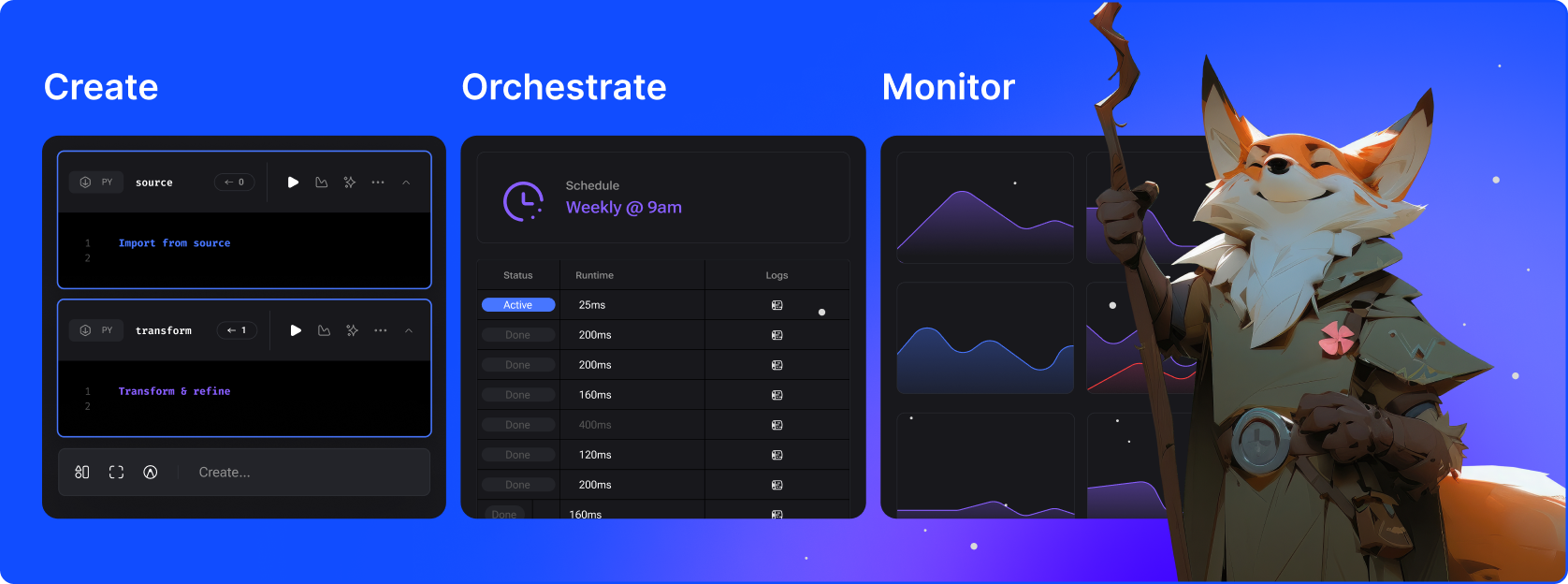
Mage est un framework hybride pour transformer et intégrer des données. Il combine le meilleur des deux mondes : la flexibilité des notebooks avec la rigueur du code modulaire.
Extrayez et synchronisez les données de sources tierces.
Transformez les données avec des pipelines en temps réel et par lots à l'aide de Python, SQL et R.
Chargez des données dans votre entrepôt de données ou votre lac de données à l'aide de nos connecteurs prédéfinis.
Exécutez, surveillez et orchestrez des milliers de pipelines sans perdre le sommeil.
Plus des centaines de fonctionnalités de classe entreprise, des innovations en matière d’infrastructure et des surprises magiques.
 Pour les équipes. Plateforme entièrement gérée pour l'intégration et la transformation des données. Pour les équipes. Plateforme entièrement gérée pour l'intégration et la transformation des données. |  Auto-hébergé. Système pour créer, exécuter et gérer des pipelines de données. Auto-hébergé. Système pour créer, exécuter et gérer des pipelines de données. |
Pour obtenir de la documentation sur le démarrage, le développement et le déploiement en production, consultez le live
Portail de documentation pour les développeurs .
La méthode recommandée pour installer la dernière version de Mage consiste à utiliser Docker avec la commande suivante :
docker pull mageai/mageai:dernier
Vous pouvez également installer Mage en utilisant pip ou conda, bien que cela puisse entraîner des problèmes de dépendance sans l'environnement approprié.
pip installer mage-ai
conda install -c conda-forge mage-ai
Vous cherchez de l'aide ? Le moyen le plus rapide de commencer est de consulter notre documentation ici.
Vous cherchez des exemples rapides ? Ouvrez un projet de démonstration directement dans votre navigateur ou consultez nos guides.
Créez et exécutez un pipeline de données avec notre application de démonstration .
AVERTISSEMENT
La démo en direct est publique pour tout le monde, veuillez ne rien enregistrer de sensible (par exemple mots de passe, secrets, etc.).

Cliquez sur l'image pour lire la vidéo
| Orchestration | Planifiez et gérez les pipelines de données avec observabilité. | |
| Carnet de notes | Éditeur interactif Python, SQL et R pour coder des pipelines de données. | |
| Intégrations de données | Synchronisez les données de sources tierces avec vos destinations internes. | |
| Pipelines de streaming | Ingérez et transformez des données en temps réel. | |
| dette | Créez, exécutez et gérez vos modèles dbt avec Mage. |
Un exemple de pipeline de données défini sur 3 fichiers ➝
Charger les données ➝
@data_loaderdef load_csv_from_file() -> pl.DataFrame:return pl.read_csv('default_repo/titanic.csv')Transformer les données ➝
@transformerdef select_columns_from_df(df : pl.DataFrame, *args) -> pl.DataFrame:return df[['Âge', 'Tarif', 'Survécu']]
Exporter des données ➝
@data_exporterdef export_titanic_data_to_disk(df : pl.DataFrame) -> Aucun :df.to_csv('default_repo/titanic_transformed.csv')

