Seq2seq Chatbot for Keras
1.0.0
Ce référentiel contient un nouveau modèle génératif de chatbot basé sur la modélisation seq2seq. De plus amples détails sur ce modèle peuvent être trouvés dans la section 3 du document Apprentissage contradictoire de bout en bout pour les agents conversationnels génératifs. Dans le cas d'une publication utilisant des idées ou des morceaux de code de ce référentiel, veuillez citer cet article.
Le modèle entraîné disponible ici utilisait un petit ensemble de données composé d'environ 8 000 paires de contexte (les deux derniers énoncés du dialogue jusqu'au point actuel) et de réponse respective. Les données ont été collectées à partir de dialogues de cours d'anglais en ligne. Ce modèle entraîné peut être affiné à l'aide d'un ensemble de données de domaine fermé pour des applications du monde réel.
Le modèle canonique seq2seq est devenu populaire dans la traduction automatique neuronale, une tâche qui a différentes distributions de probabilité a priori pour les mots appartenant aux séquences d'entrée et de sortie, puisque les énoncés d'entrée et de sortie sont écrits dans des langues différentes. L'architecture présentée ici suppose les mêmes distributions a priori pour les mots d'entrée et de sortie. Par conséquent, il partage une couche d'intégration (intégration de mots pré-entraînés Glove) entre les processus d'encodage et de décodage grâce à l'adoption d'un nouveau modèle. Pour améliorer la sensibilité contextuelle, le vecteur de pensée (c'est-à-dire la sortie de l'encodeur) code les deux derniers énoncés de la conversation jusqu'au point actuel. Pour éviter d'oublier le contexte lors de la génération de la réponse, le vecteur de pensée est concaténé à un vecteur dense qui code la réponse incomplète générée jusqu'au point actuel. Le vecteur résultant est fourni à des couches denses qui prédisent le jeton actuel de la réponse. Voir la section 3.1 de notre article pour un meilleur aperçu des avantages de notre modèle.
L'algorithme itère en incluant le jeton prédit dans la réponse incomplète et en le renvoyant à la couche d'entrée de droite du modèle présenté ci-dessous.
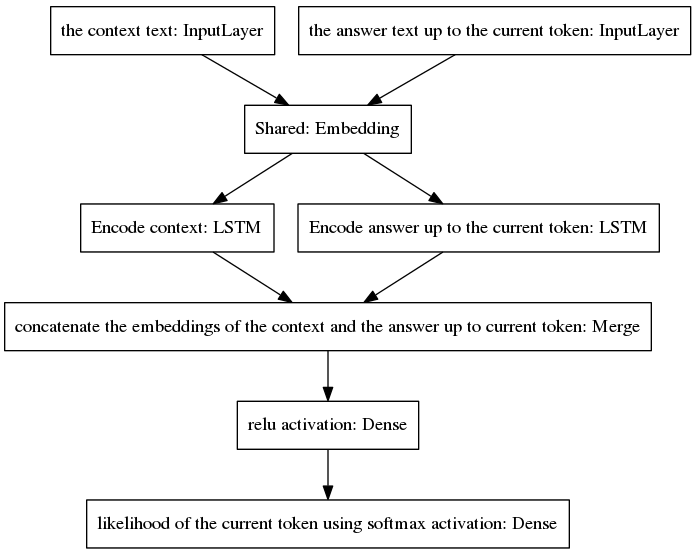
Comme on peut le voir sur la figure ci-dessus, les deux LSTM sont disposés en parallèle, tandis que le seq2seq canonique a les couches récurrentes d'encodeur et de décodeur disposées en série. Les couches récurrentes sont dépliées lors de la rétropropagation dans le temps, ce qui entraîne un grand nombre de fonctions imbriquées et, par conséquent, un risque plus élevé de disparition du gradient, aggravé par la cascade de couches récurrentes du modèle canonique seq2seq, même dans le cas d'architectures fermées. comme les LSTM. Je pense que c'est l'une des raisons pour lesquelles mon modèle se comporte mieux pendant l'entraînement que le seq2seq canonique.
Le pseudocode suivant explique l'algorithme.

La formation de ce nouveau modèle converge en quelques époques. En utilisant notre ensemble de données d'exemples d'entraînement 8K, il n'a fallu que 100 époques pour atteindre une perte d'entropie croisée catégorique de 0,0318, au prix de 139 s/époque fonctionnant dans un GPU GTX980. Les performances de ce modèle entraîné (fourni dans ce référentiel) semblent aussi convaincantes que les performances d'un modèle vanilla seq2seq entraîné sur les ~ 300 000 exemples de formation du Cornell Movie Dialogs Corpus, mais nécessitent beaucoup moins d'efforts de calcul pour s'entraîner.
Pour discuter avec le modèle pré-entraîné :
Téléchargez le fichier python "conversation.py", le fichier de vocabulaire "vocabulary_movie", et les poids nets "my_model_weights20", qui se trouvent ici ;
Exécutez conversation.py.
Pour discuter avec le nouveau modèle formé par notre nouvel algorithme de formation basé sur GAN :
Téléchargez le fichier python "conversation_discriminator.py", le fichier de vocabulaire "vocabulary_movie", et les poids nets "my_model_weights20.h5", "my_model_weights.h5", et "my_model_weights_discriminator.h5", qui se trouvent ici ;
Exécutez conversation_discriminator.py.
Ce modèle a de meilleures performances en utilisant les mêmes données d'entraînement. Le discriminateur du modèle basé sur GAN est utilisé pour sélectionner la meilleure réponse entre deux modèles, l'un formé par le forçage des enseignants et l'autre formé par notre nouvelle méthode de formation de type GAN, dont les détails peuvent être trouvés dans cet article.
Pour entraîner un nouveau modèle ou affiner vos propres données :
Si vous souhaitez vous entraîner à partir de zéro, supprimez le fichier my_model_weights20.h5. Pour affiner vos données, conservez ce fichier ;
Téléchargez le dossier Glove 'glove.6B' et incluez ce dossier dans le répertoire du chatbot (vous pouvez trouver ce dossier ici). Cet algorithme applique l'apprentissage par transfert en utilisant une intégration de mots pré-entraînés, qui est affinée pendant la formation ;
Exécutez split_qa.py pour diviser le contenu de vos données d'entraînement en deux fichiers : « contexte » et « réponses » et get_train_data.py pour stocker les phrases complétées dans les fichiers « Padded_context » et « Padded_answers » ;
Exécutez train_bot.py pour entraîner le chatbot (il est recommandé d'utiliser un GPU, pour ce faire, tapez : THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,exception_verbosity=high python train_bot.py) ;
Nommez vos données d'entraînement comme "data.txt". Ce fichier doit contenir un énoncé de dialogue par ligne. Si votre ensemble de données est volumineux, définissez la variable num_subsets (à la ligne 29 de train_bot.py) sur un nombre plus grand.
Weights_file = 'mon_modèle_weights20.h5' Weights_file_GAN = 'mon_modèle_weights.h5' Weights_file_discrim = 'mon_modèle_weights_discriminator.h5'
Un bon aperçu des implémentations actuelles de modèles conversationnels neuronaux pour différents frameworks (ainsi que quelques résultats) peut être trouvé ici.
Notre modèle peut être appliqué à d'autres tâches PNL, telles que la synthèse de texte, voir par exemple Alternative 2 : Modèle récursif A. Nous encourageons l'application de notre modèle dans d'autres tâches, dans ce cas, nous vous demandons de bien vouloir citer notre travail le plus possible. être visible dans ce document, enregistré en juillet 2017.
Ces codes peuvent s'exécuter dans Ubuntu 14.04.3 LTS, Python 2.7.6, Theano 0.9.0 et Keras 2.0.4. L'utilisation d'une autre configuration peut nécessiter quelques adaptations mineures.


