MiniGPT 3D
1.0.0
Yuan Tang Xu Han Xianzhi Li* Qiao Yu Yixue Hao Long Hu Min Chen
Université des sciences et technologies de Huazhong Université de technologie de Chine du Sud
ACM MM 2024
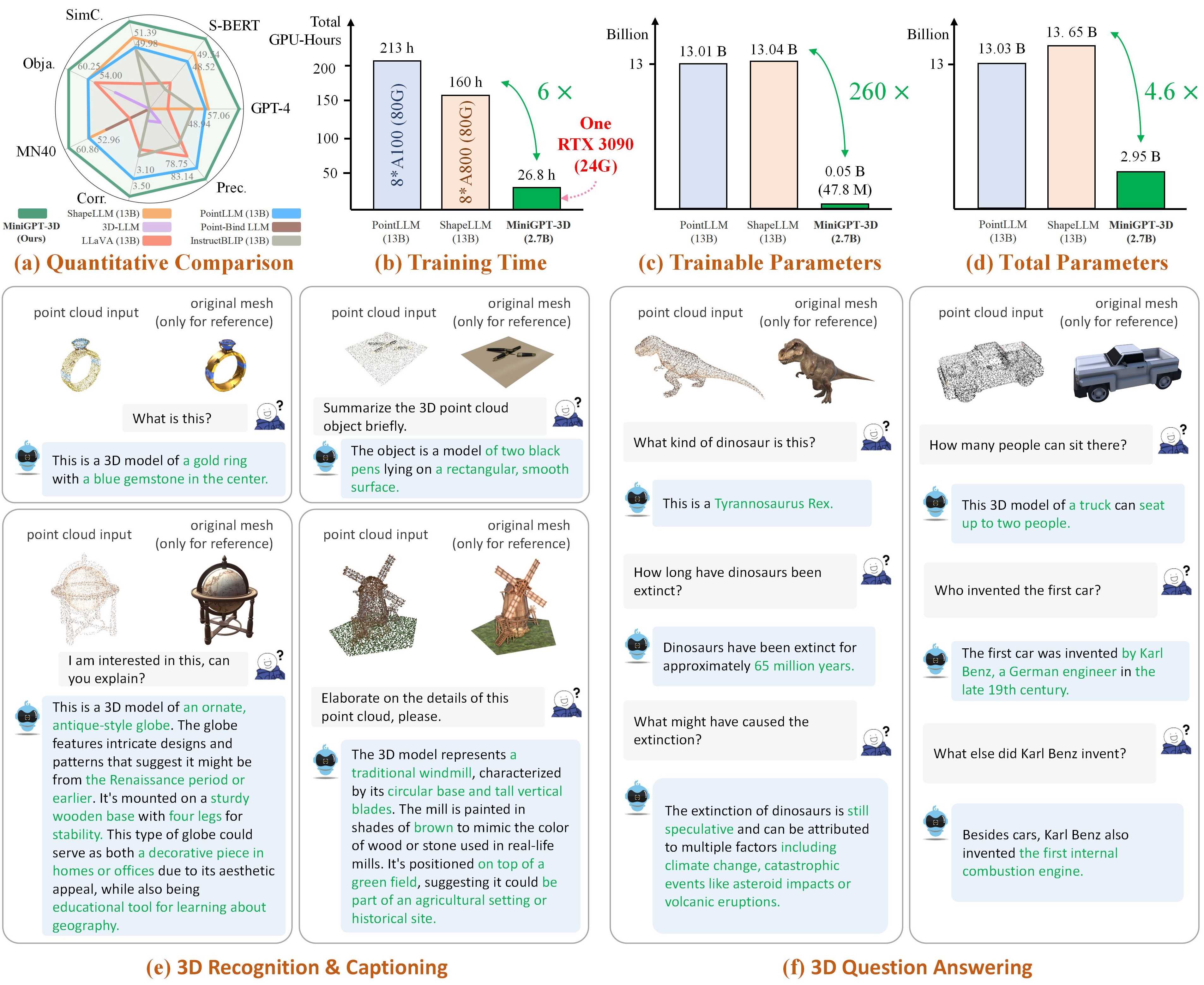

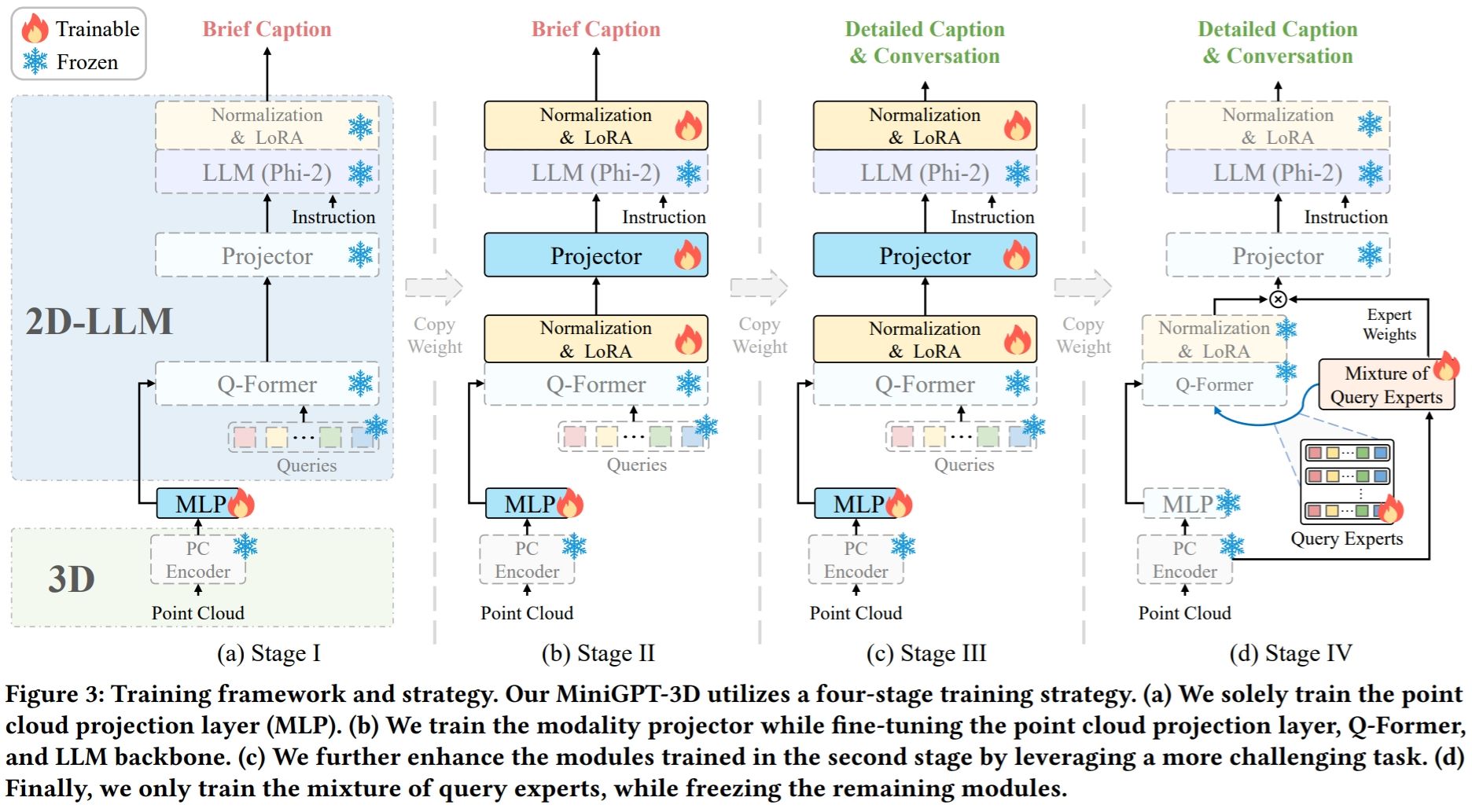
Remarque : MiniGPT-3D fait le premier pas vers un 3D-LLM efficace , nous espérons que MiniGPT-3D pourra apporter de nouvelles informations à cette communauté.
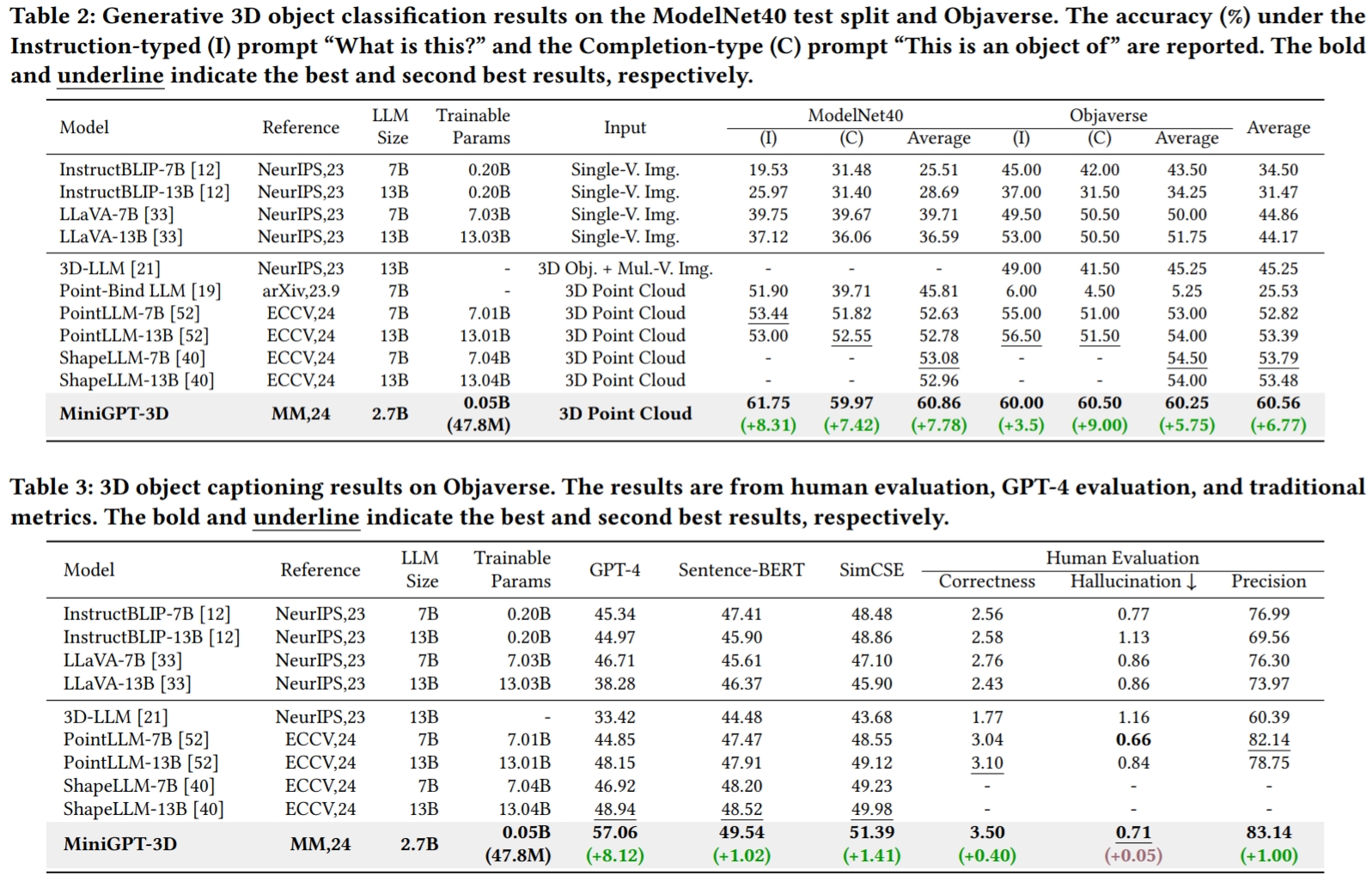
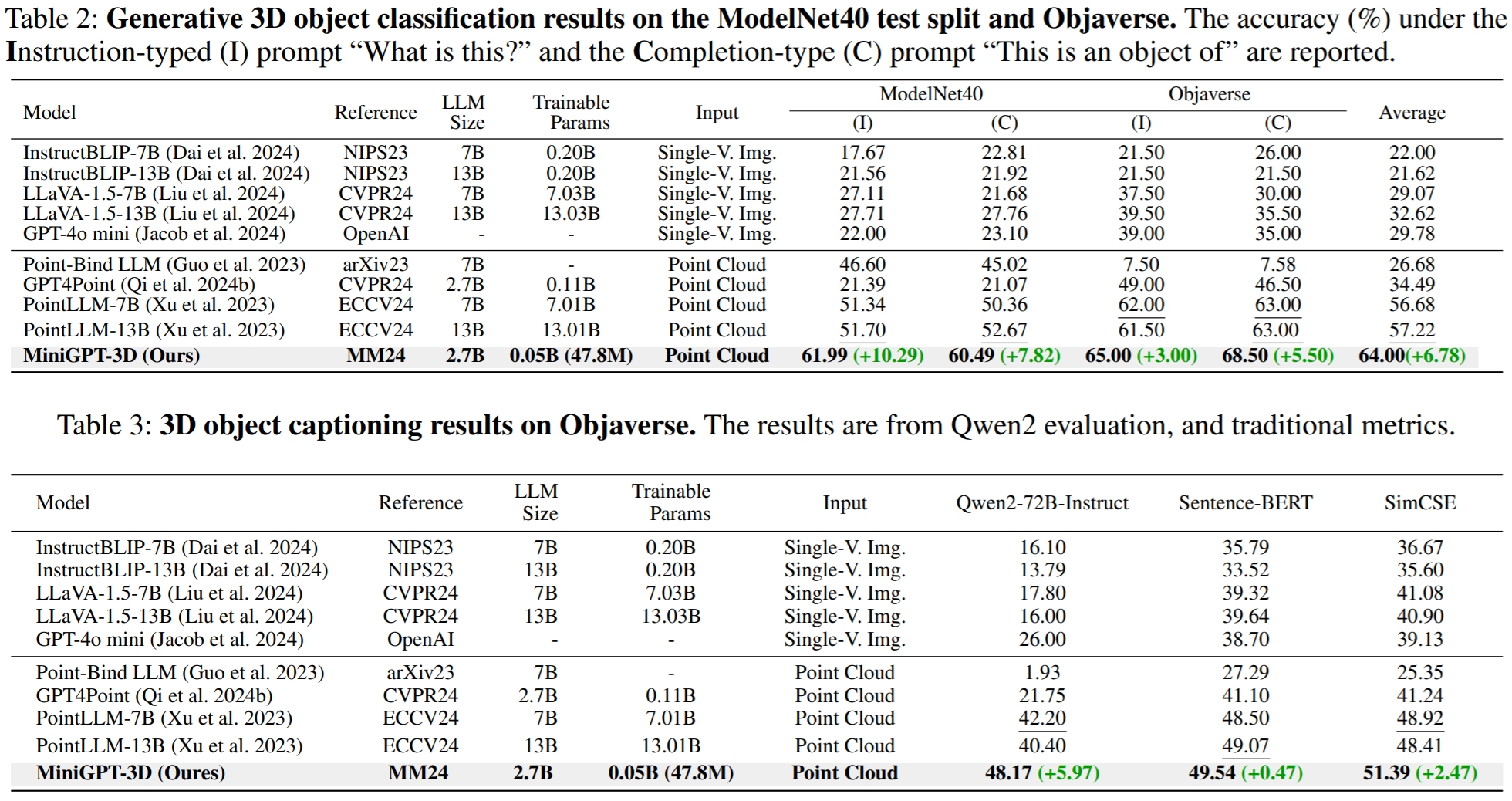
Les résultats font référence à GreenPLM.

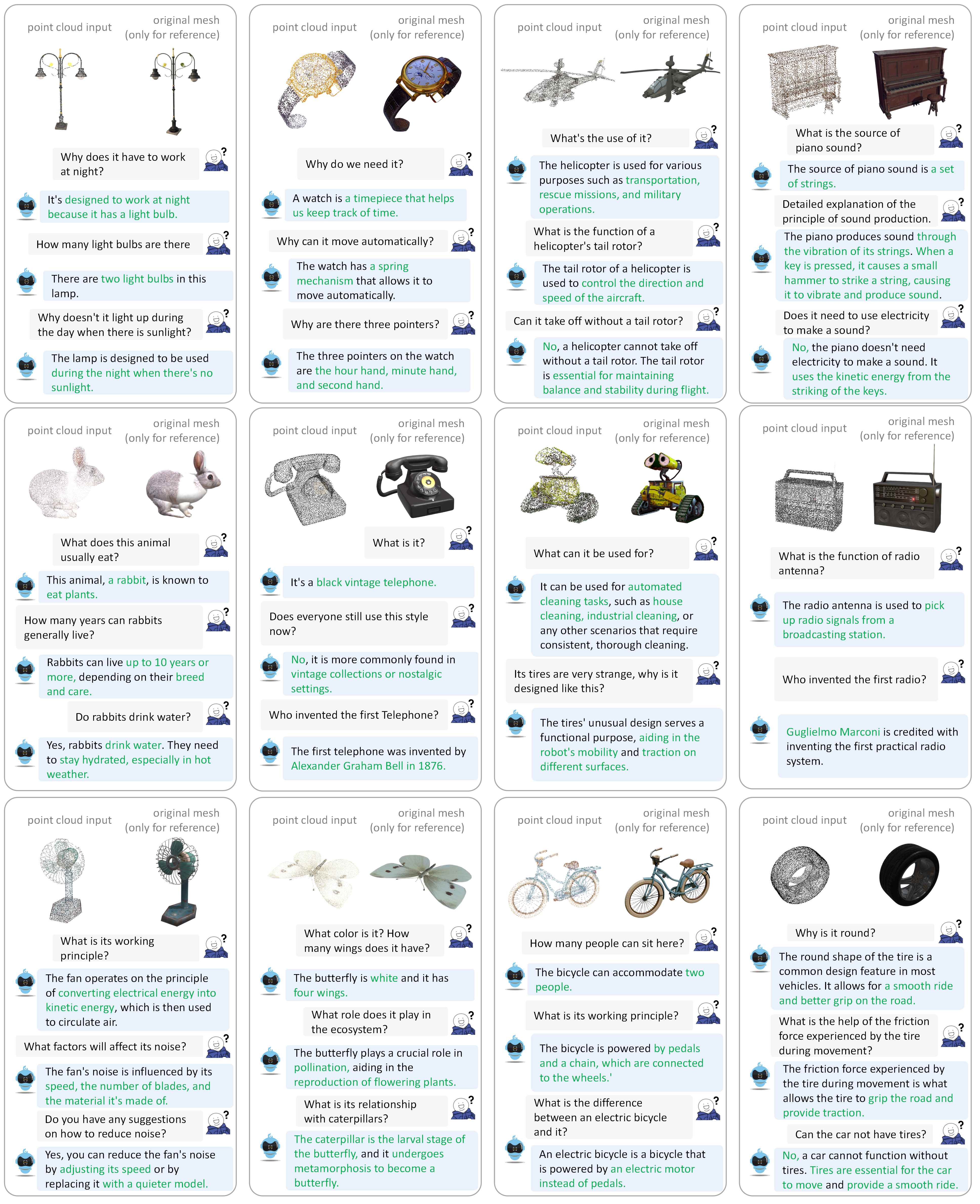
Veuillez vous référer à notre article pour plus d’exemples de dialogue.
Nous testons nos codes dans l'environnement suivant :
Pour commencer :
Clonez ce référentiel.
git clone https://github.com/TangYuan96/MiniGPT-3D.git
cd MiniGPT-3DInstaller des packages
Par défaut, vous avez installé conda.
conda env create -f environment.yml
conda activate minigpt_3d
bash env_install.sh8192_npy contenant 660 000 fichiers de nuages de points nommés {Objaverse_ID}_8192.npy . Chaque fichier est un tableau numpy avec des dimensions (8192, 6), où les trois premières dimensions sont xyz et les trois dernières dimensions sont rgb dans la plage [0, 1]. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gz8192_npy vers le dossier ./data/objaverse_data ../data/anno_data .modelnet40_test_8192pts_fps.dat vers le dossier ./data/modelnet40_data .Enfin, la structure globale du répertoire de données doit être :
MiniGPT-3D/data
|-- anno_data
| |-- PointLLM_brief_description_660K.json
| |-- PointLLM_brief_description_660K_filtered.json
| |-- PointLLM_brief_description_val_200_GT.json
| |-- PointLLM_complex_instruction_70K.json
| |-- object_ids_660K.txt
| `-- val_object_ids_3000.txt
|-- modelnet40_data
| |-- modelnet40_test_8192pts_fps.dat
|-- objaverse_data
| |-- 00000054c36d44a2a483bdbff31d8edf_8192.npy
| |-- 00001ec0d78549e1b8c2083a06105c29_8192.npy
| .......
Nous trions les poids de modèle requis par MiniGPT-3D pendant la formation et l'inférence.
params_weight vers le dossier du projet MiniGPT-3D .Enfin, la structure globale du répertoire de données doit être :
MiniGPT-3D
|-- params_weight
| |-- MiniGPT_3D_stage_3 # Our MiniGPT-3D stage III weight, needed to verify the results of paper
| |-- MiniGPT_3D_stage_4 # Our MiniGPT-3D stage IV weight, Needed to verify the results of paper
| |-- Phi_2 # LLM weight
| |-- TinyGPT_V_stage_3 # 2D-LLM weights including loRA & Norm of LLM and projector
| |-- all-mpnet-base-v2 # Used in the caption traditional evaluation
| |-- bert-base-uncased # Used in initialize Q-former
| |-- pc_encoder # point cloud encoder
| `-- sup-simcse-roberta-large # Used in the caption traditional evaluation
|-- train_configs
| `-- MiniGPT_3D
| .......
Vous pouvez exécuter la commande suivante pour démarrer une démo de conversation Gradio locale :
python UI_demo.py --cfg-path ./eval_configs/MiniGPT_3D_conv_UI_demo.yaml --gpu-id 0 Ensuite, copiez le lien http://127.0.0.1:7860/ dans votre navigateur, vous pouvez saisir l'identifiant d'objet Objaverse pris en charge (660 000 objets) ou télécharger un fichier objet (.ply ou .npy) pour parler avec notre MiniGPT-3D. .
Exemple : saisissez l'ID de l'objet : 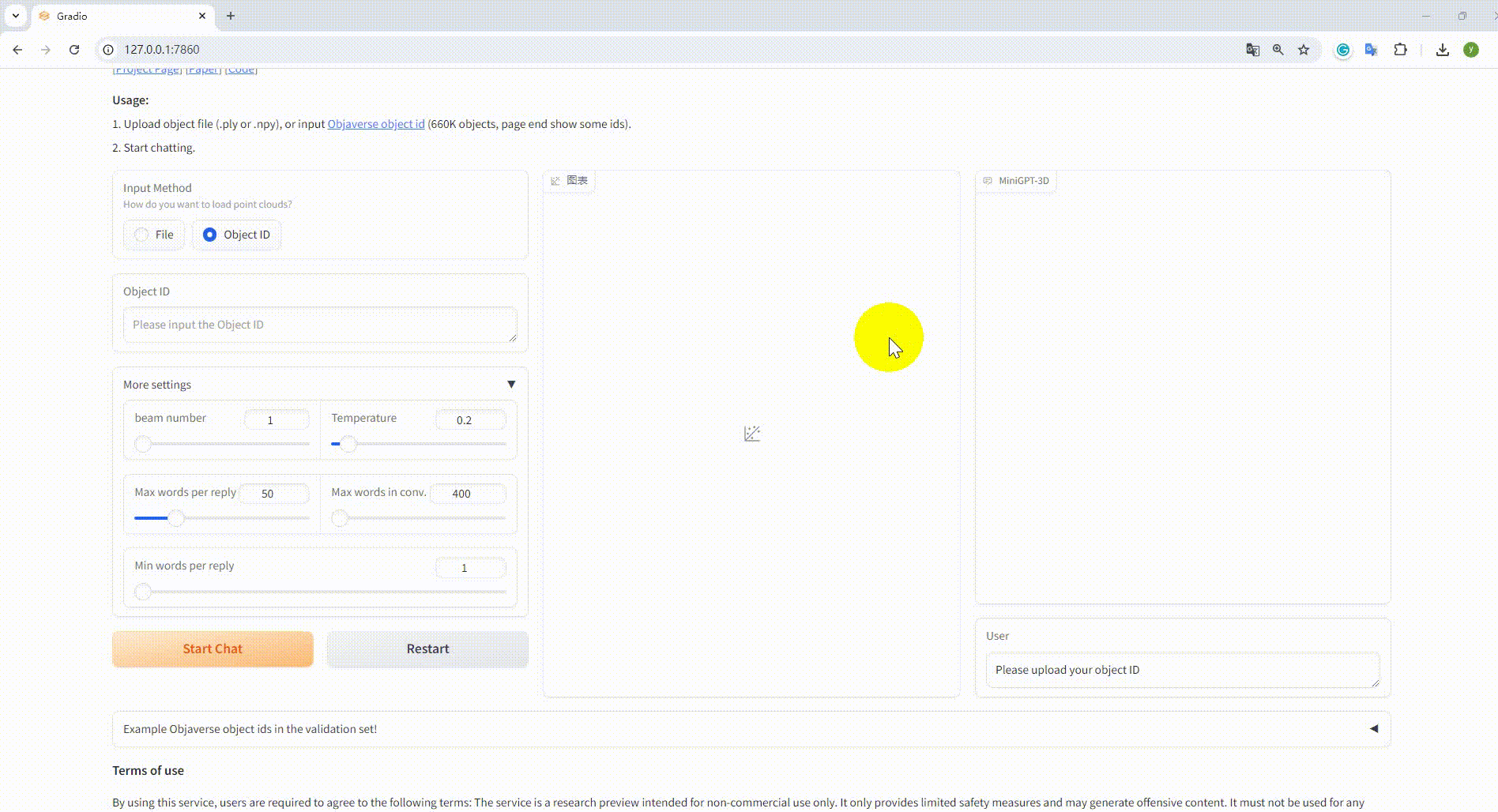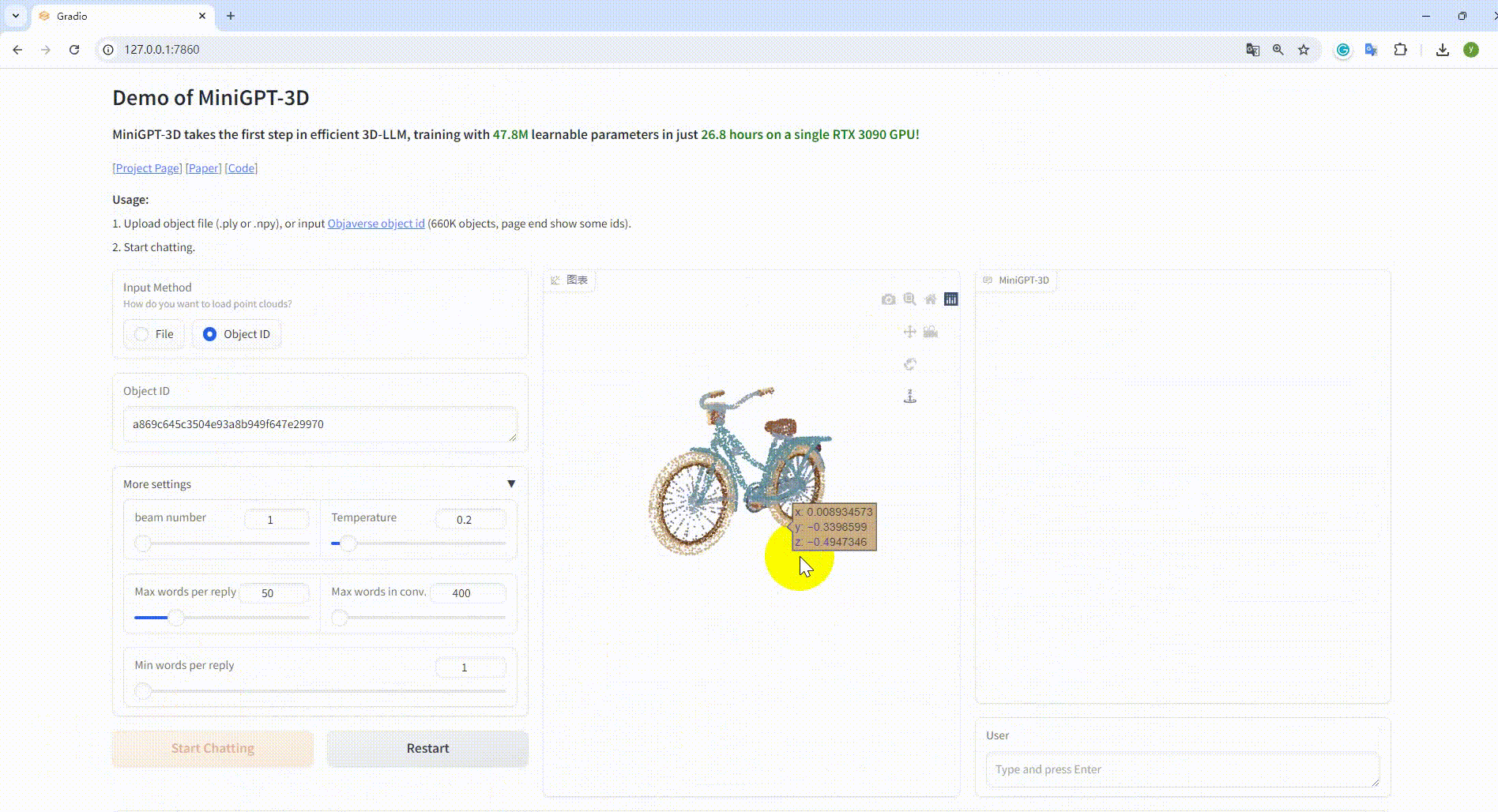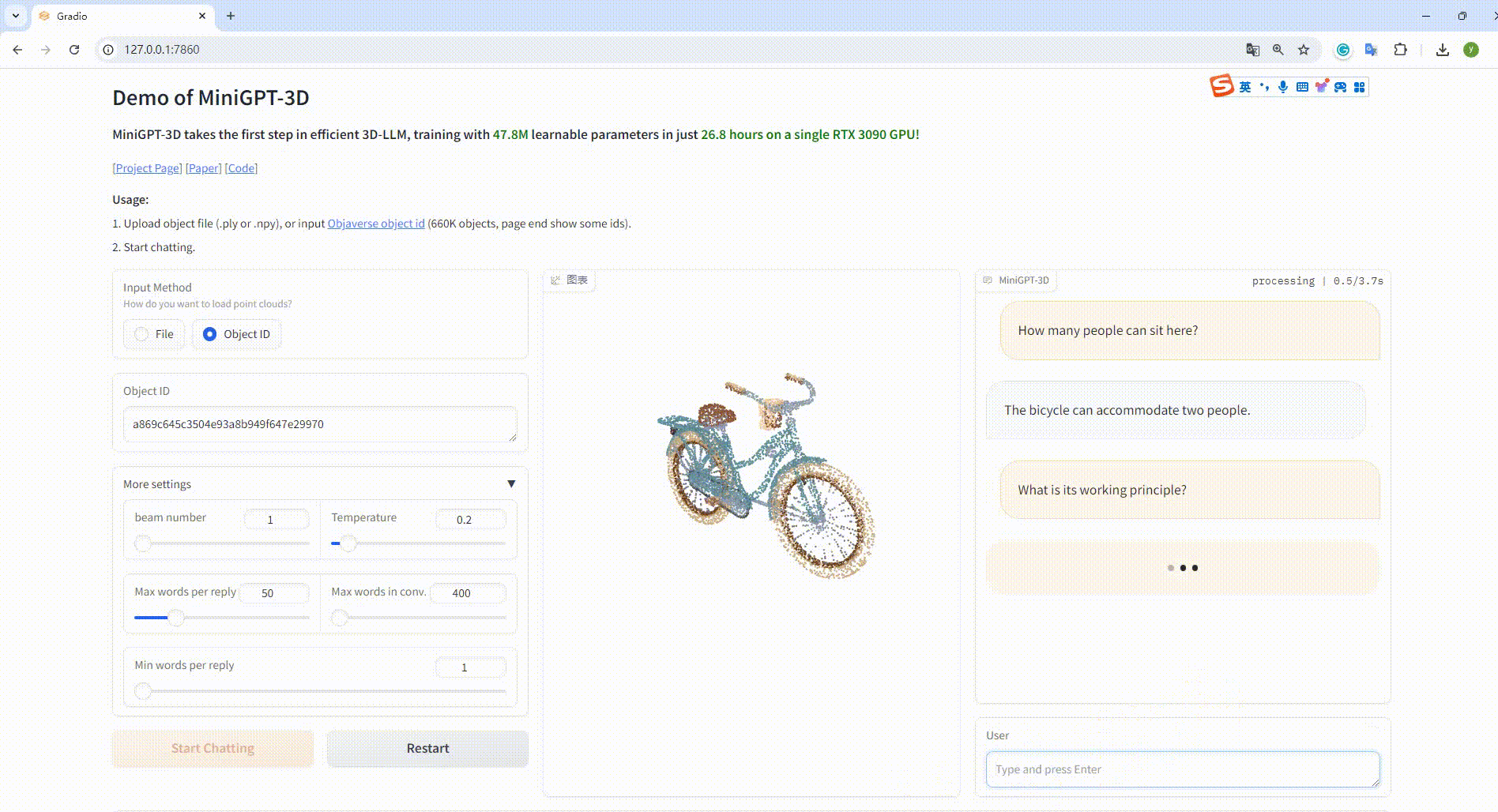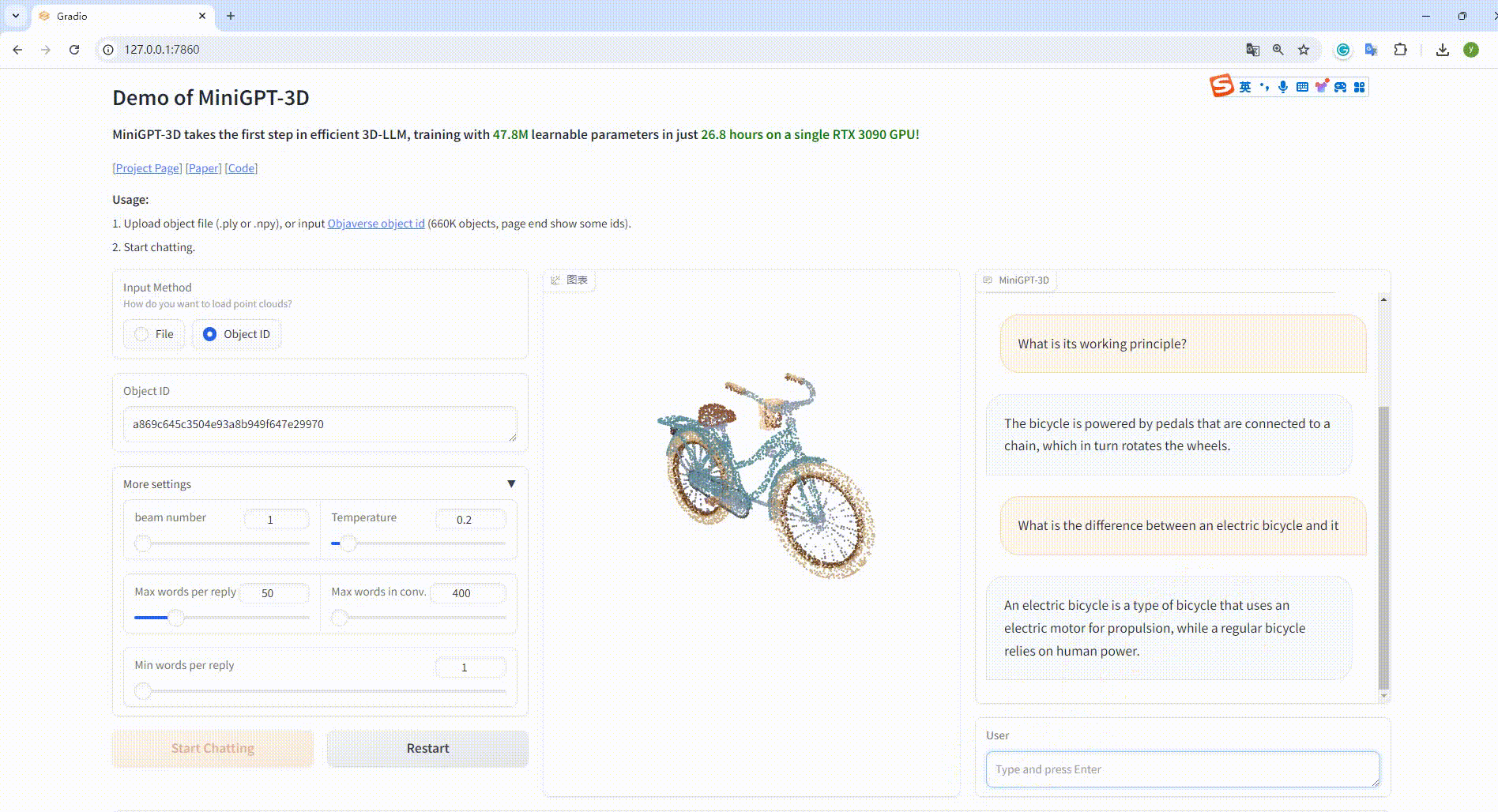
Exemple : Téléchargez le fichier objet : 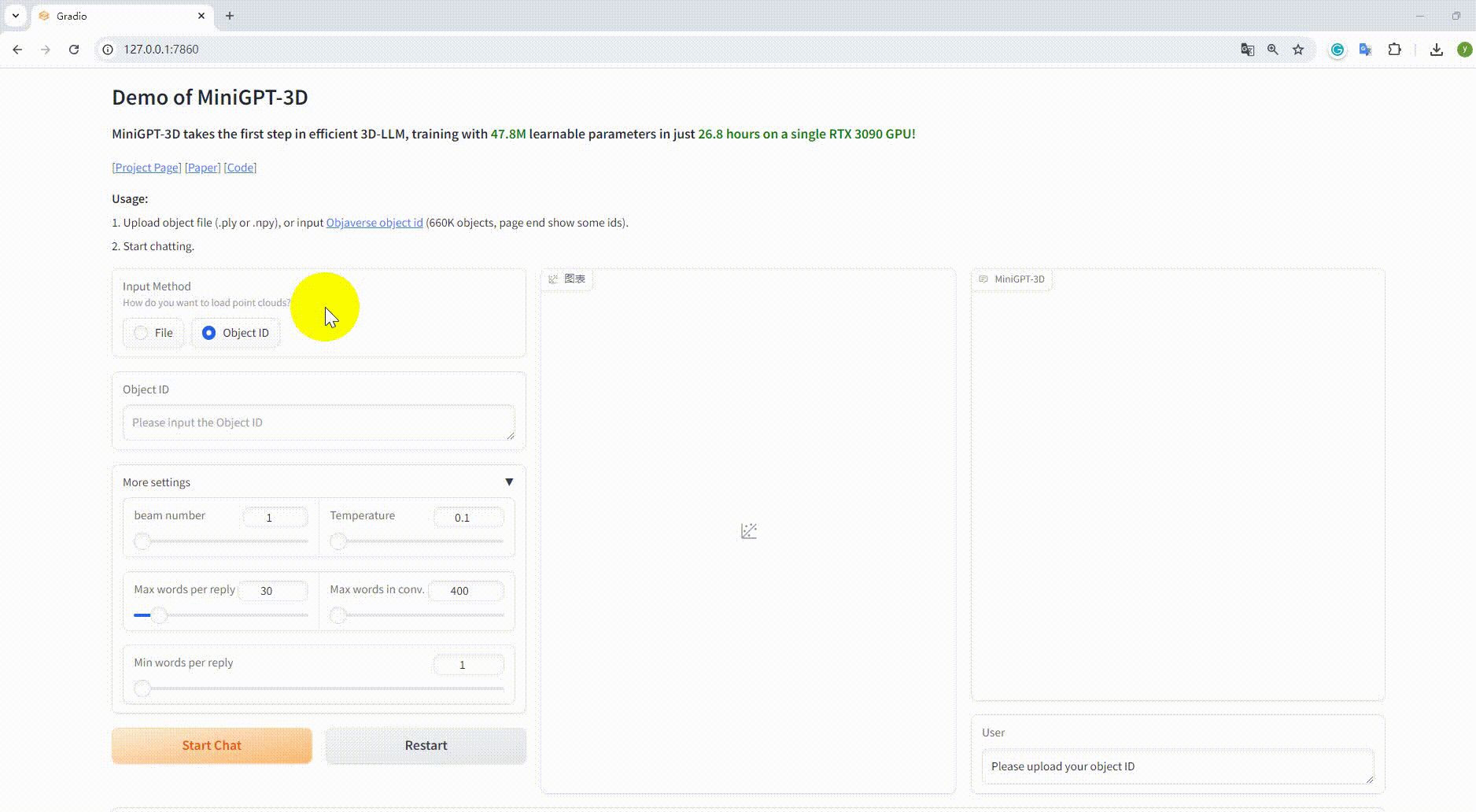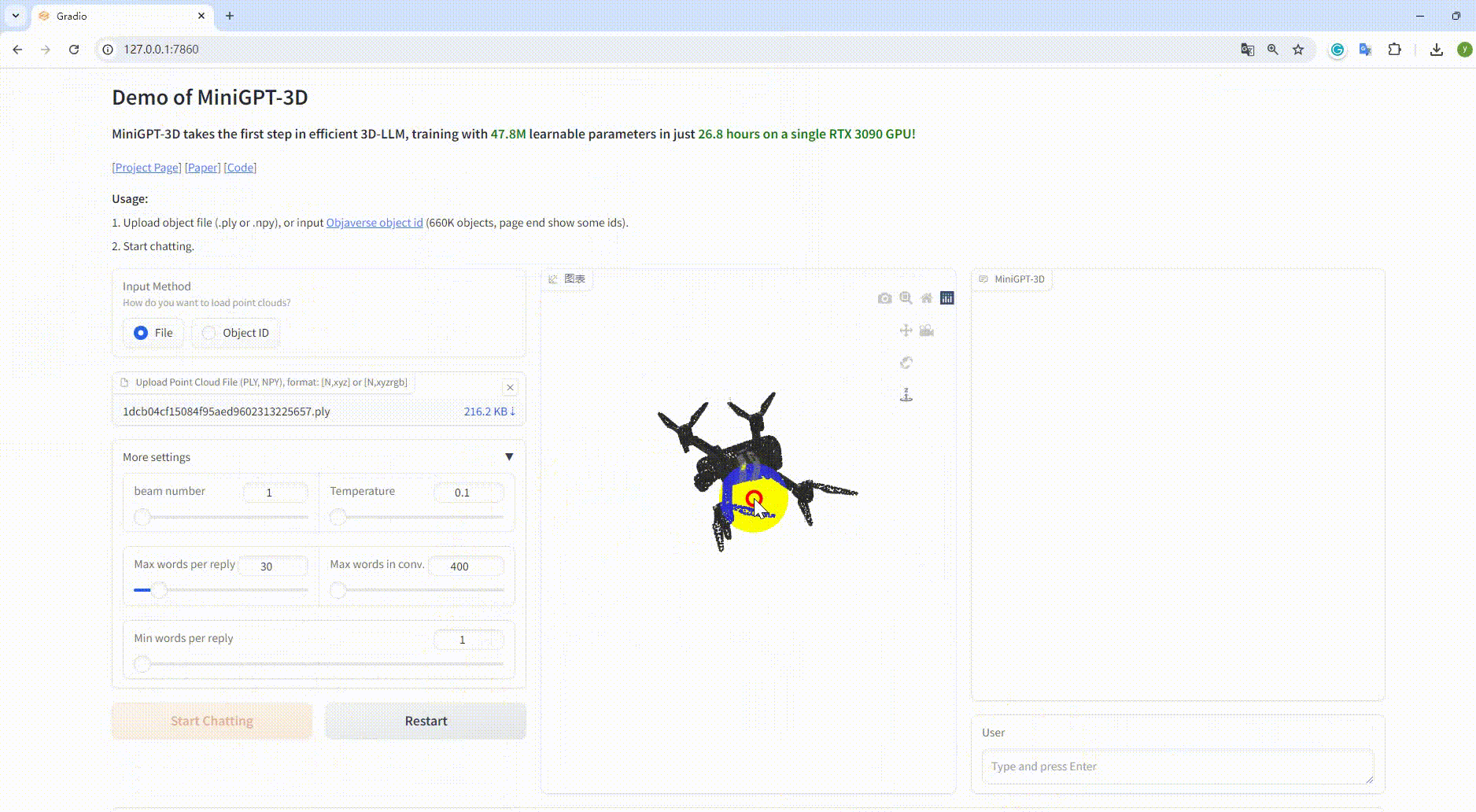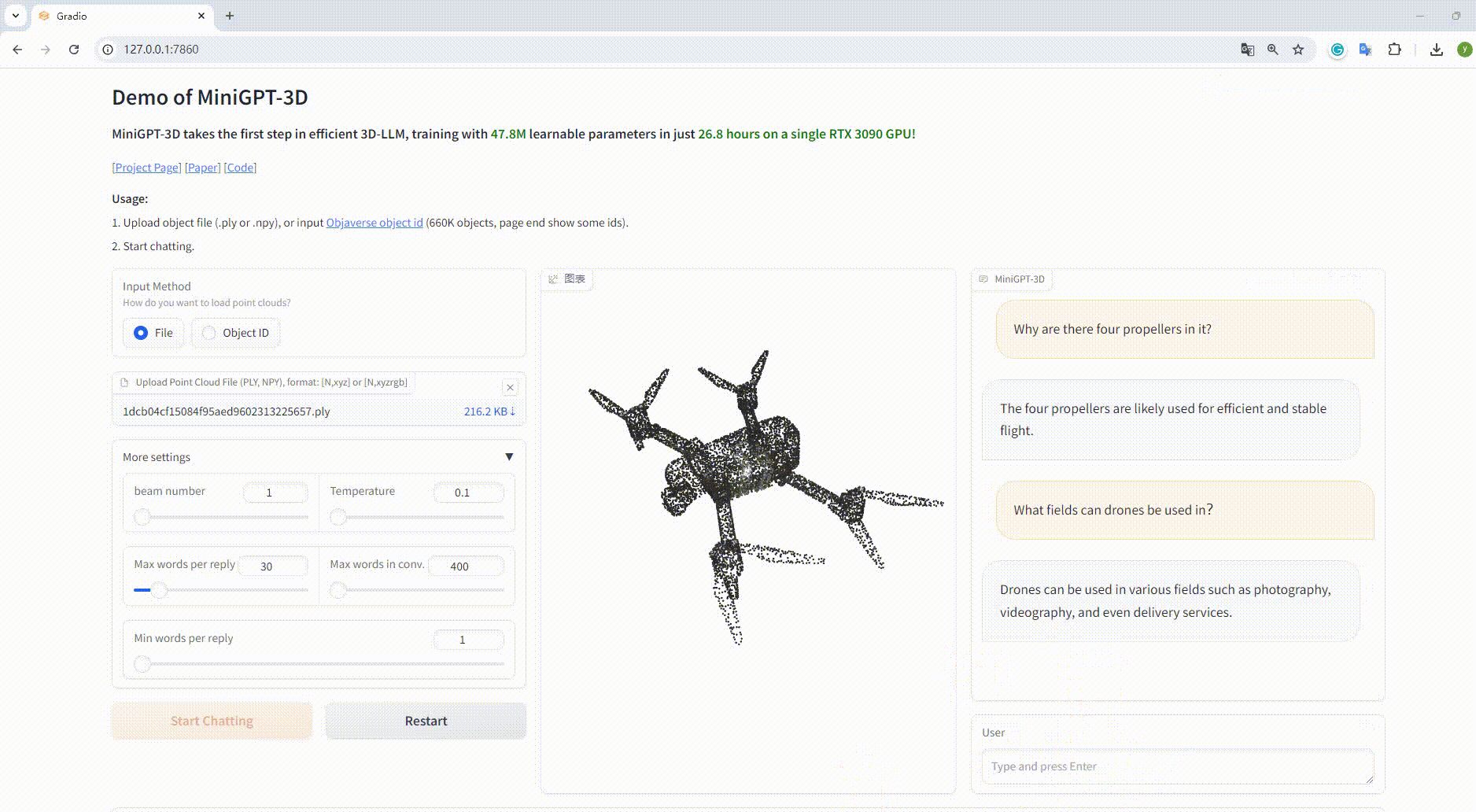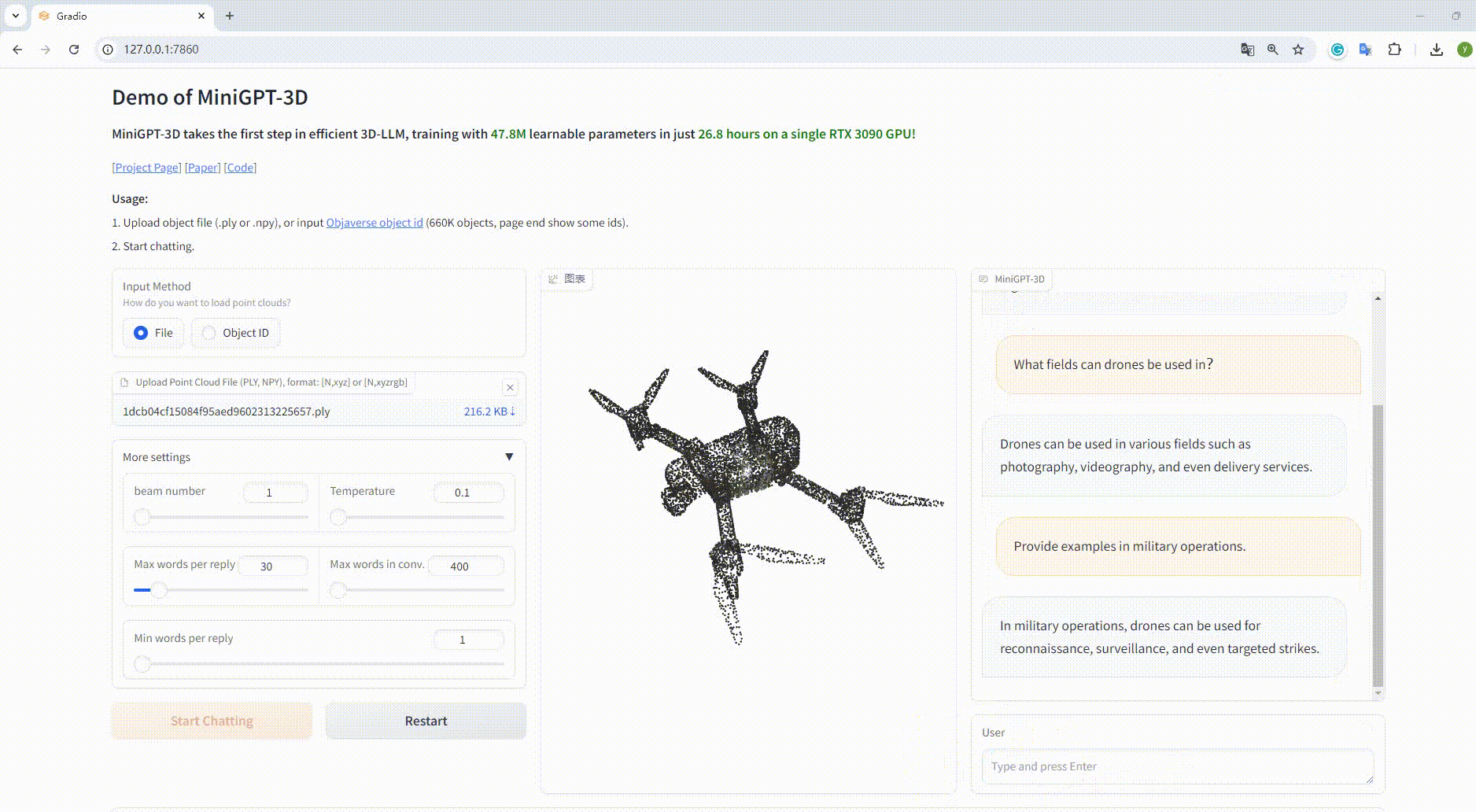
Si vous souhaitez utiliser le chemin de sortie par défaut de chaque étape, vous pouvez ignorer les étapes suivantes.
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_1.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_2.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_3.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_4.yaml
Si vous souhaitez simplement vérifier les résultats de notre article, vous pouvez ignorer les étapes suivantes :
Réglez le chemin de sortie de l'étape III ici, sur la ligne 8.
Définissez le chemin de sortie de l'étape IV ici, sur la ligne 9.
Afficher le résultat de la classification du vocabulaire ouvert sur l'objaverse
# Prompt 0:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type classification --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 0 # Prompt 1:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type classification --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 1Afficher le résultat de la classification zéro tir rapproché sur ModelNet40
# Prompt 0:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_modelnet_cls.py --out_path ./output/test --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 0 # Prompt 1:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_modelnet_cls.py --out_path ./output/test --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 1Afficher le résultat du sous-titrage de l'objet sur l'objaverse
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type captioning --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 2Dans GreenPLM, nous avons remarqué que les LLM proches GPT-3.5 et GPT-4 présentent deux inconvénients majeurs : des versions d'API incohérentes et des coûts d'évaluation élevés (~ 35 CNY ou 5 USD par évaluation) . Par exemple, le modèle GPT-3.5-turbo-0613 utilisé dans PointLLM et notre MiniGPT-3D n'est plus maintenu, ce qui rend difficile la réplication des résultats .
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt0.json --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt1.json --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/ModelNet_classification_prompt0.json --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/ModelNet_classification_prompt1.json --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.json --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15Dans GreenPLM, nous proposons de nouveaux tests de classification et de légende d'objets 3D utilisant Qwen2-72B-Instruct open source de niveau GPT-4 pour rendre les évaluations rentables et les résultats reproductibles de manière cohérente .
export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt0.json
--eval_type open-free-form-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt1.json
--eval_type open-free-form-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/ModelNet_classification_prompt0.json
--eval_type modelnet-close-set-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/ModelNet_classification_prompt1.json
--eval_type modelnet-close-set-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.json
--eval_type object-captioning
--model_type qwen2-72b-instruct
--parallel --num_workers 4Pour la tâche de sous-titrage d'objet, exécutez la commande suivante pour évaluer les sorties du modèle avec les métriques traditionnelles Sentence-BERT et SimCSE.
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/traditional_evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.jsonRéglez le chemin de sortie du Stage III ici sur la ligne 8.
Définissez le chemin de sortie de l'étape IV ici sur la ligne 9.
Vous pouvez exécuter la commande suivante pour démarrer une démo de conversation Gradio locale :
python UI_demo.py --cfg-path ./eval_configs/MiniGPT_3D_conv_UI_demo.yaml --gpu-id 0Si vous trouvez notre travail utile, pensez à citer :
@article { tang2024minigpt ,
title = { MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors } ,
author = { Tang, Yuan and Han, Xu and Li, Xianzhi and Yu, Qiao and Hao, Yixue and Hu, Long and Chen, Min } ,
journal = { arXiv preprint arXiv:2405.01413 } ,
year = { 2024 }
}
Ce travail est sous la licence internationale Creative Commons Attribution-Pas d’Utilisation Commerciale-Partage dans les mêmes conditions 4.0.
Ensemble, rendons le LLM pour la 3D génial !
Nous tenons à remercier les auteurs de PointLLM, TinyGPT-V, MiniGPT-4 et Octavius pour leurs excellents travaux et dépôts.


