gutenberg dialog
1.0.0
Code pour télécharger et créer votre propre version de l'ensemble de données de dialogue Gutenberg. Facilement extensible avec de nouvelles langues. Essayez des chatbots formés dans différentes langues ici : https://ricsinaruto.github.io/chatbot.html.
| Lien de téléchargement | Nombre d'énoncés | Durée moyenne de l'énoncé | Nombre de dialogues | Durée moyenne des dialogues |
|---|---|---|---|---|
| Anglais | 14 773 741 | 22.17 | 2 526 877 | 5,85 |
| Allemand | 226 015 | 24h44 | 43 440 | 5h20 |
| Néerlandais | 129 471 | 24.26 | 23 541 | 5,50 |
| Espagnol | 58 174 | 18.62 | 6 912 | 8.42 |
| italien | 41 388 | 19h47 | 6 664 | 6.21 |
| hongrois | 18 816 | 14.68 | 2 826 | 6,66 |
| portugais | 16 228 | 21h40 | 2 233 | 7.27 |
? Générez votre propre ensemble de données en ajustant les paramètres affectant le compromis taille-qualité de l'ensemble de données
L'interface modulaire facilite l'extension de l'ensemble de données à d'autres langues
? Vous pouvez facilement exclure des livres manuellement lors de la création de l'ensemble de données
Exécutez setup.py qui installe les packages requis.
python setup.py
Le fichier principal doit être appelé depuis la racine du dépôt. La commande ci-dessous exécute le pipeline de création d'ensembles de données pour les langues séparées par des virgules données en argument. Actuellement, l'anglais, l'allemand, le néerlandais, l'espagnol, le portugais, l'italien et le hongrois sont pris en charge.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
Tous les arguments réglables peuvent être vus ci-dessous : 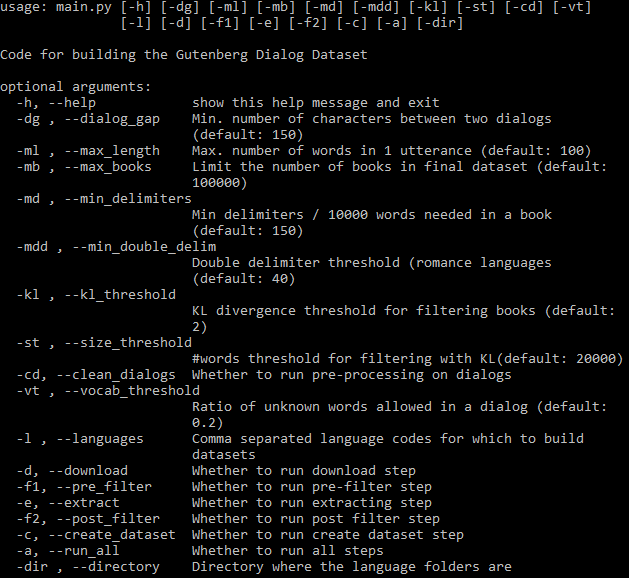
L'indicateur -a contrôle s'il faut exécuter automatiquement l'ensemble du pipeline. Si -a est omis, un sous-ensemble d'étapes doit être spécifié à l'aide d'indicateurs (voir l'aide ci-dessus). Une fois qu'une étape est terminée, sa sortie peut être utilisée dans les étapes suivantes et elle n'est réexécutée que si les paramètres ou le code liés à cette étape sont modifiés. Toutes les étapes s'exécutent séparément pour chaque langue.
Téléchargez des livres pour des langues données.
Remarque : si le téléchargement de tous les livres échoue avec l'erreur « Impossible de télécharger le livre », la cause probable est que le miroir par défaut utilisé par le package Gutenberg est devenu inaccessible. Dans ce cas, il est possible d'utiliser l'un des miroirs alternatifs répertoriés sur https://www.gutenberg.org/MIRRORS.ALL via la variable d'environnement GUTENBERG_MIRROR . Par exemple:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
Le pré-filtrage supprime certains vieux livres et bruits.
Les dialogues sont extraits de livres. Lors de l'extension de l'ensemble de données à de nouvelles langues (voir la section ci-dessous), c'est l'étape qui peut être modifiée, ainsi les étapes précédentes peuvent être ignorées une fois terminées.
Une deuxième étape de filtrage supprimant certaines boîtes de dialogue basées sur le vocabulaire.
Rassembler l'ensemble de données final et le diviser en données d'entraînement/développement/test. La dernière étape crée le fichier author_and_title.txt dans le répertoire de sortie contenant tous les livres (plus les titres et les auteurs) utilisés pour extraire l'ensemble de données final. Les utilisateurs peuvent copier manuellement les lignes de ce fichier vers banni_books.txt correspondant aux livres qui ne doivent pas être autorisés dans l'ensemble de données. Lors des exécutions ultérieures des étapes, les livres de ce fichier ne seront pas pris en compte.
Le code peut être facilement étendu pour traiter d’autres langages. Un fichier nommé <code langue>.py doit être créé dans le dossier langues. Ici, une classe doit être définie nommée le code de langue en majuscules (par exemple En pour l'anglais), avec LANG ou l'une des autres sous-classes comme parent. Avec self.cfg, les paramètres de configuration sont accessibles. A l'intérieur de cette classe, les 3 fonctions ci-dessous doivent être définies. Veuillez consulter it.py pour un exemple.
Statistiques des langues
Cette fonction doit renvoyer un dictionnaire où les clés sont des délimiteurs potentiels. Pour chaque délimiteur, une fonction doit être définie (valeurs dans le dictionnaire), qui prend en entrée une ligne et renvoie un nombre. Ce nombre peut être par exemple le nombre de délimiteurs, un indicateur indiquant s'il y a un délimiteur dans la ligne, etc. Généralement, un nombre pondéré est conseillé, en fonction de l'importance des différents délimiteurs. Les valeurs seront utilisées pour déterminer le délimiteur qui doit être utilisé dans le livre respectif (transmis à la fonction ci-dessous) et pour filtrer les livres qui contiennent un faible nombre de délimiteurs. en.py contient des exemples de délimiteurs multiples.
Cette fonction doit extraire les boîtes de dialogue d'un livre et les ajouter à self.dialogs , qui est une liste de boîtes de dialogue, et chaque boîte de dialogue est une liste d'énoncés consécutifs. paragraphe_list contient le livre sous forme de liste de paragraphes consécutifs. Le délimiteur est le délimiteur le plus courant dans ce fichier et doit être utilisé pour extraire les boîtes de dialogue.
Cette fonction est utilisée pour les boîtes de dialogue de post-traitement (par exemple supprimer certains caractères). Il prend en entrée un énoncé. Veuillez noter que la tokenisation des mots nltk est exécutée automatiquement.
Ce projet est sous licence MIT - voir le fichier LICENSE pour plus de détails.
Veuillez inclure un lien vers ce référentiel si vous utilisez l'un des ensembles de données ou du code dans votre travail et envisagez de citer l'article suivant :
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


